







一.流的分类
1.java.io包中的类对应两类流,一类流直接从指定的位置(如磁盘文件或内存区域)读或写,这类流称为结点流(node stream),其它的流则称为过滤器(filters)。过滤器输入流往往是以其它输入流作为它的输入源,经过过滤或处理后再以新的输入流的形式提供给用户,过滤器输出流的原理也类似。
2.Java的常用输入、输出流
java.io包中的stream类根据它们操作对象的类型是字符还是字节可分为两大类:字符流和字节流。
2.1Java的字节流:
InputStream是所有字节输入流的祖先,而OutputStream是所有字节输出流的祖先
2.2Java的字符流:
Reader是所有读取字符串输入流的祖先,而writer是所有输出字符串的祖先。
结合开始所说的输入/输出流 ,出现了个一小框架。

JAVA字节流:
FileInputStream和FileOutputStream
这两个类属于结点流,第一个类的源端和第二个类的目的端都是磁盘文件,它们的构造方法允许通过文件的路径名来构造相应的流。
FileInputStream infile = new FileInputStream("myfile.dat");
FileOutputStream outfile = new FileOutputStream("results.dat");要注意的是:构造FileInputStream,,对应的文件必须存在并且是可读的,而构造FileOutputStream时,如输出文件已存在,则必须是可覆盖的。
BufferedInputStream和BufferedOutputStream:
它们是过滤器流,其作用是提高输入输出的效率,对于FileInputStream当调用read()方法(每次读取一个字节)时都要从硬盘中获取数据,对性能有一定影响,所以就需要使用缓冲流:从自己内存中的字节数组中读取数据,默认一次读8192个字节
DataInputStream和DataOutputStream:
这两个类创建的对象分别被称为数据输入流和数据输出流。这是很有用的两个流,它们允许程序按与机器无关的风格读写Java数据。所以比较适合于网络上的数据传输。这两个流也是过滤器流,常以其它流如InputStream或OutputStream作为它们的输入或输出。这两种流失对流的扩展,可以更加方便的读取int,long,字符等类型的数据,比如:DataOutputStram:中增加了writeInt()/writeDouble()/writeUTF()方法
public class Main {
public static void main(String[] args) throws IOException {
String file="a.txt";
DataOutputStream dos=new DataOutputStream(new FileOutputStream(file));
dos.writeInt(10);
dos.writeLong(10l);
dos.writeUTF("中国");//采用UTF-8编码写入
dos.writeChars("中国");//采用utf-16be方式写入
dos.close();
}
}RandomAccessFile的基本介绍和操作:
RandomAccessFile是Java提供的对文件内容的访问,既可以读文件,也可以写文件,并且可以随机访问文件,即可以访问文件的任意位置,它在访问文件时会有一个文件指针,在访问过程中会向后移动
File demo=new File("demo");
if(demo.exists()){
demo.mkdir();//如果文件夹不存在则创建
}
File file=new File(demo,"a.txt");//以demo为目录创建a.txt文件
if(file.exists()){
file.createNewFile();//如果文件不存在则创建新的文件
}
RandomAccessFile raf=new RandomAccessFile(file,"rw");//rw是文件模式中的可读写模式
System.out.println(raf.getFilePointer());//得到指针的位置为0
raf.write('A');//写入'A'的后八位(每次只写一个字节),指针后移一位
int i=15;
raf.write(i>>>24);//写入高八位
raf.write(i>>>16);.....每次写一个字节,要写四次
raf.writeInt(i);//直接写入一个int类型数据
String s="中国";
byte[] gbk=s.getBytes("gbk");
raf.write(gbk);
raf.seek(0);//读文件 ,必须把指针移到头部
byte[] buf=new byte[(int)raf.length()];//一次性读取,把文件中的内容都读到字节数组中去
raf.read();
System.out.println(Arrays.toString(buf));Java的字符流:
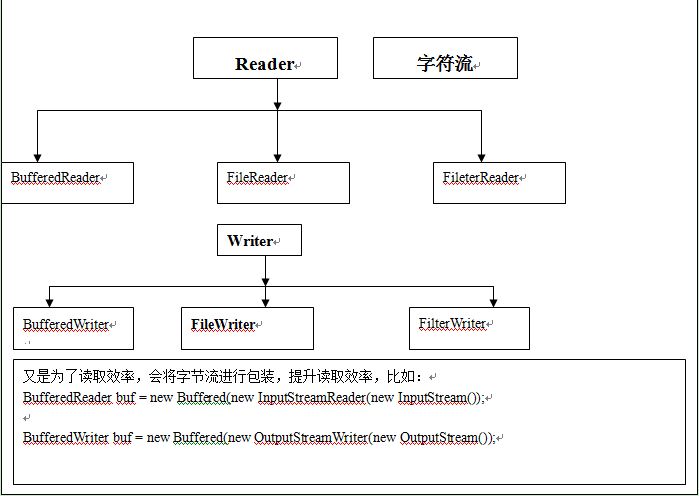
字符流主要是用来处理字符的,Java采用16位的Unicode来表示字符串和字符,对应的字符流按输入和输出分别称为Reader和writer(一次处理一个字符,字符的底层仍然是基本的字节序列)
FileReader和FileWriter:
FileReader(读文件类):其直接父类就是InputStreamReader类
FileReader a=new FileReader("C:\\Users\\admin\\Desktop\1.txt");//注意:不能修改编码集,即使用默认编码集FileWriter:其直接父类为OutputStreamWriter类
FileWriter a=new FileWrite("C:\\Users\\admin\\Desktop\1.txt",true);//加true参数表示在第二次写入文件时是追加内容InputStreamReader和OutputStreamWriter:
1.将字节流转化为字符流(解码):
FileInputStream f==new FileInputStream("D:\\test.txt");;
InputStreamReader f1=f1=new InputStreamReader(f,"UTF-8");//设置字符编码为UTF-8,默认项目的编码为gbk
//读取数据(一个字符一个字符的读取):
int c;
while((c=f1.read())!=-1){
System.out.println((char)c);
}
//批量读取(放入buffer这个字符数组,从0开始放置,最多放buffer.length个,返回的是读到的字符个数):
char[] buffer=new char[8*1024];
while((c==f1.read(buffer,0,buffer.length))!=-1){
String s=new String(buffer,0,c);
}2.将字符流转化为字节流(编码):
FileOutputStream fos=new FileOutputStream("D:\\test.txt");
OutputStreamWriter osw=new OutputStreamWriter(fos,"UTF-8");BufferedReader和BufferedWriter:
这两个类对应的流使用了缓冲,能大大提高输入输出的效率,这两个也是过滤器流,常用来对InputStreamReader和OutputStreamWriter进行处理,如:
public class Echo {
public static void main(String[] args) throws IOException{
BufferedReader in =new BufferedReader(new InputStreamReader(System.in));
BufferedWriter bw=new BufferedWriter(mew FileOutputStream("d:\\test.txt"));
String s;
while((s = in.readLine()).length() != 0){
System.out.println(s);//一次读一行,并不能识别换行
bw.write(s);
bw.newLine();//换行操作
bw.flush();//注意一定要添加这行代码,才能写入缓冲区中
}
bf.close();
bw.close();
} BuffferedReader和BufferedWriter之mark()(方法标记流中的当前位置,调用reset()将重新定位流)的使用:
public class Test{
public static void main(String[] args) throws IOException{
FileReader fr=new FileReader("D:\\test.txt");
BufferedReader br=new BufferedReader(fr,1000);//1000为缓冲区大小
br.mark(1000);//参数要不小于缓冲区大小,字符流需要设置,而字节流的mark会默认在起始位置
第一种方式读取:
int c=0;
c=br.read();
while(c!=-1){
System.out.println((char)c);
c=br.read();
}
第二种方式读取:
br.reset();//再读一次需要重置
String str=br.readLine();
while(str!=null) {
System.out.println(str);
str=br.readLine();
}
}//注意关闭流最好在finally中进行
}Java序列化和反序列化问题
transient和ArrayList源码解析:
private transient int age;//该元素不会进行jvm的默认序列化,但也可以自己完成这个元素的序列化
ObjectOutputStream s;
s.defaultWriteObject();//把jvm默认能序列化的元素进行序列化操作
s.writeInt(age);//自己完成age的序列化
ObjectInputStream s;
s.defaultReadObject();//把jvm中默认能进行反序列化的元素进行反序列化
this.age=s.readInt();//自己完成age的反序列化操作通过对ArrayList源码列表的分析可以知道,ArrayList中会对其中的有效元素进行序列化和反序列化以提高性能
序列化中子父类构造函数问题:
在序列化中若父类是实现了序列化接口,子类可以不用实现序列化接口,可以直接进行序列化,子类在序列化过程中会递归的调用父类的构造方法
注意:对子类对象进行反序列化操作时,如果其父类没有实现序列化接口,那么其父类的构造函数会被显示调用,否则就不会调用















 425
425











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









