







我们知道搜索引擎接收搜索请求的第一步,就是对要查询的内容做做分词,Elasticsearch 2.3.3像其他搜索引擎一样,默认的标准分词器(standard)并不适合中文, 我们常用的中文分词插件是IK Analysis 分词器。本文,我们就介绍IK Analysis分词插件的安装。
在未安装IK分词之前,我们看一下使用standard分词的效果,
启动之前安装好的ES,在浏览器的地址栏中输入下面的代码
http://192.168.133.134:9200/hotel/_analyze?analyzer=standard&text=58码农,我帮码农,我们为程序员的匠心精神服务!我们看到分词的效果如下:
{
"tokens": [
{
"token": "58",
"start_offset": 0,
"end_offset": 2,
"type": "<NUM>",
"position": 0
},
{
"token": "码",
"start_offset": 2,
"end_offset": 3,
"type": "<IDEOGRAPHIC>",
"position": 1
},
{
"token": "农",
"start_offset": 3,
"end_offset": 4,
"type": "<IDEOGRAPHIC>",
"position": 2
},
{
"token": "我",
"start_offset": 5,
"end_offset": 6,
"type": "<IDEOGRAPHIC>",
"position": 3
},
{
"token": "帮",
"start_offset": 6,
"end_offset": 7,
"type": "<IDEOGRAPHIC>",
"position": 4
},
{
"token": "码",
"start_offset": 7,
"end_offset": 8,
"type": "<IDEOGRAPHIC>",
"position": 5
},
{
"token": "农",
"start_offset": 8,
"end_offset": 9,
"type": "<IDEOGRAPHIC>",
"position": 6
},
{
"token": "我",
"start_offset": 10,
"end_offset": 11,
"type": "<IDEOGRAPHIC>",
"position": 7
},
{
"token": "们",
"start_offset": 11,
"end_offset": 12,
"type": "<IDEOGRAPHIC>",
"position": 8
},
{
"token": "为",
"start_offset": 12,
"end_offset": 13,
"type": "<IDEOGRAPHIC>",
"position": 9
},
{
"token": "程",
"start_offset": 13,
"end_offset": 14,
"type": "<IDEOGRAPHIC>",
"position": 10
},
{
"token": "序",
"start_offset": 14,
"end_offset": 15,
"type": "<IDEOGRAPHIC>",
"position": 11
},
{
"token": "员",
"start_offset": 15,
"end_offset": 16,
"type": "<IDEOGRAPHIC>",
"position": 12
},
{
"token": "的",
"start_offset": 16,
"end_offset": 17,
"type": "<IDEOGRAPHIC>",
"position": 13
},
{
"token": "匠",
"start_offset": 17,
"end_offset": 18,
"type": "<IDEOGRAPHIC>",
"position": 14
},
{
"token": "心",
"start_offset": 18,
"end_offset": 19,
"type": "<IDEOGRAPHIC>",
"position": 15
},
{
"token": "精",
"start_offset": 19,
"end_offset": 20,
"type": "<IDEOGRAPHIC>",
"position": 16
},
{
"token": "神",
"start_offset": 20,
"end_offset": 21,
"type": "<IDEOGRAPHIC>",
"position": 17
},
{
"token": "服",
"start_offset": 21,
"end_offset": 22,
"type": "<IDEOGRAPHIC>",
"position": 18
},
{
"token": "务",
"start_offset": 22,
"end_offset": 23,
"type": "<IDEOGRAPHIC>",
"position": 19
}
]
}我们看到基本上是逐个字符的分词,并没有把一些词语分在一起。我们最后在安装完IK分词以后再看一下效果。
IK Analysis 分词插件的安装其实很简单,但是由于大多数情况下需要采用源码的方式安装,导致很多朋友安装失败。接下来,我就把安装源码安装的方式描述一下。
一、 Maven安装
IK Analysis 是基于JAVA编写的,我们采用源码安装的话,需要安装maven环境。那我们先来介绍一下maven环境的安装。
1. 获取maven包。
wget http://mirror.bit.edu.cn/apache/maven/maven-3/3.3.9/binaries/apache-maven-3.3.9-bin.tar.gz获取安装包,我把maven放在了/usr/local 目录下面。

2. 解压
tar -xvf apache-maven-3.3.9-bin.tar.gz![]()
3. 设置环境变量
vi /etc/profile然后再文件的末尾粘贴上下面三个变量。
MAVEN_HOME=/usr/local/apache-maven-3.3.9
export MAVEN_HOME
export PATH=${PATH}:${MAVEN_HOME}/bin
保存完成后,刷新环境变量
source /etc/profile4. 验证
mvn -version
看到这些内容,表示maven安装成功。
二、 安装git
采用yum安装即可
yum install git三、下载ik源码
git clone https://github.com/medcl/elasticsearch-analysis-ik我把他放到了/usr/es/ik这个目录下面

四、编译并打包
这个过程会下载许多依赖的包。所以会耽误一些时间。执行的命令如下:
进入elasticsearch-analysis-ik 目录,然后执行下面的命令
mvn clean
执行清除命令以后,在执行编译命令,这个命令需要的时间更多。
mvn compile最后执行打包命令
mvn package
打包完成以后,我们可以再target目录看到打好的包。

五、复制并解压elasticsearch-analysis-ik-1.9.3.zip
执行下面的命令即可
unzip /usr/es/ik/elasticsearch-analysis-ik/target/releases/elasticsearch-analysis-ik-1.9.3.zip -d /usr/es/plugins/ik解压完成后,我们可以再/usr/es/plugins/ik中看到我们解压的文件。

六、重新启动
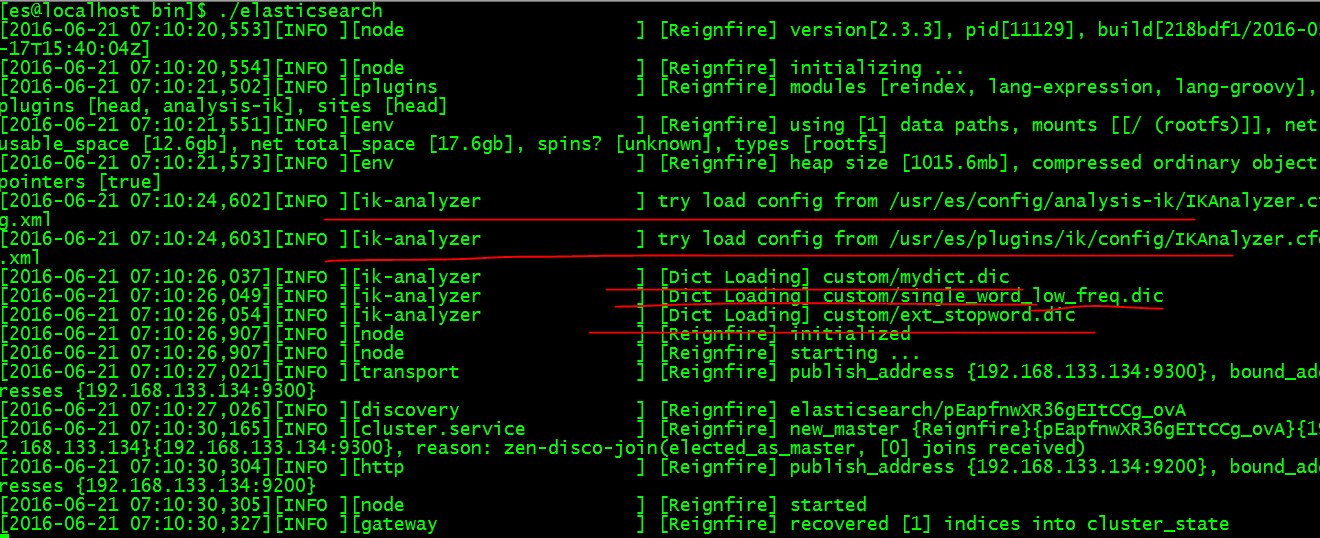
我们看到标红线的内容即时导入了IK分词。我们来试一下分词的效果。
在浏览器器的地址栏中输入下面的内容:
http://192.168.133.134:9200/hotel/_analyze?analyzer=ik&text=58码农,我帮码农,我们为程序员的匠心精神服务!跟前面的对比一下,仅仅是采用的分词不一样,前面采用的是standard,而本次我们采用的是ik,我们可以看到结果是下面的样子。
{
"tokens": [
{
"token": "58",
"start_offset": 0,
"end_offset": 2,
"type": "ARABIC",
"position": 0
},
{
"token": "码",
"start_offset": 2,
"end_offset": 3,
"type": "COUNT",
"position": 1
},
{
"token": "农",
"start_offset": 3,
"end_offset": 4,
"type": "CN_WORD",
"position": 2
},
{
"token": "我",
"start_offset": 5,
"end_offset": 6,
"type": "CN_CHAR",
"position": 3
},
{
"token": "帮",
"start_offset": 6,
"end_offset": 7,
"type": "CN_CHAR",
"position": 4
},
{
"token": "码",
"start_offset": 7,
"end_offset": 8,
"type": "CN_CHAR",
"position": 5
},
{
"token": "农",
"start_offset": 8,
"end_offset": 9,
"type": "CN_WORD",
"position": 6
},
{
"token": "我们",
"start_offset": 10,
"end_offset": 12,
"type": "CN_WORD",
"position": 7
},
{
"token": "为",
"start_offset": 12,
"end_offset": 13,
"type": "CN_CHAR",
"position": 8
},
{
"token": "程序员",
"start_offset": 13,
"end_offset": 16,
"type": "CN_WORD",
"position": 9
},
{
"token": "程序",
"start_offset": 13,
"end_offset": 15,
"type": "CN_WORD",
"position": 10
},
{
"token": "序",
"start_offset": 14,
"end_offset": 15,
"type": "CN_WORD",
"position": 11
},
{
"token": "员",
"start_offset": 15,
"end_offset": 16,
"type": "CN_CHAR",
"position": 12
},
{
"token": "匠心",
"start_offset": 17,
"end_offset": 19,
"type": "CN_WORD",
"position": 13
},
{
"token": "匠",
"start_offset": 17,
"end_offset": 18,
"type": "CN_WORD",
"position": 14
},
{
"token": "心",
"start_offset": 18,
"end_offset": 19,
"type": "CN_CHAR",
"position": 15
},
{
"token": "精神",
"start_offset": 19,
"end_offset": 21,
"type": "CN_WORD",
"position": 16
},
{
"token": "服务",
"start_offset": 21,
"end_offset": 23,
"type": "CN_WORD",
"position": 17
}
]
}我们看到的结果是:程序员、程序、精神、服务被作为词分出来了。这就是我们本文介绍的IK分词的安装。
那么,我们想一下,如何把“58码农”作为一个词能够分出来呢?大家可以观看 数航学院的在线视频进行学习(免费) 同时加群可以咨询ES相关问题
另外,关于IK分词的其他内容,大家也可以看一下这篇介绍(英文):https://github.com/medcl/elasticsearch-analysis-ik
















 4084
4084

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









