







现在有一些网站的文章数据是写在JSON数据里面的,然后网页上的文章数据存储在<script></script>标签里面,现在用PHP 的file_get_content函数获取了整个网页上的字符串数据,如何截取出<script></script>内部的JSON数据呢?
用正则表达式去非常正确的想法,正则表达式的用法有3种:
- 正则匹配;
- 正则替换;
- 正则分割;
这里用到的是正则匹配,下面是从网上找到的、经过验证的正确性的代码:
<?php
//获取开始字符串和结尾字符串之间的部分
$subject = "[i=s] \u672c\u5e16\u6700\u540e\u7531 areyouok \u4e8e 2016-3-5 15:12 \u7f16\u8f91 [\/i]\n\n[attach]41[\/attach][attach]10[\/attach]\u592a\u9633\u5149\uff0c\u91d1\u4eae\u4eae\uff0c\u96c4\u9e21\u9ad8\u9ad8\u5531\r\n";
$pattern = '#\[attach](.*?)\[\\\/attach]#i';
$items = preg_match_all($pattern, $subject, $matches);
echo "<pre>";
var_dump($matches);
echo "</pre>";
?>运行效果的截图如下所示:
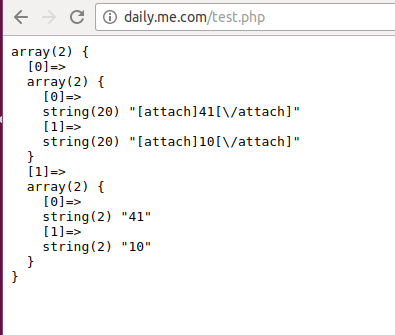
说明一点,由于网页上的<script></script>肯定是有很多对的,上面的正则处理表达式考虑到了多种情况的。将多对标签内部的字符串都截取了下来保存在字符串中的。















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









