







1.集群模式提交Topology流程分析
1)提交代码到nimbus
storm jar . . .首先这个命令会把jar文件上传到nimnus所在的机器上。也就是说,无论这个命令是在主节点nimbus上执行的,或者是在其他的supervisor节点上执行的,都是首先上传到nimbus那台机上上。我们可以通过$STORM_HOME/logs/nimbus.log日志文件中的内容来查看。
2016-01-27 23:43:14 b.s.d.nimbus [INFO] Uploading file from client to /data/storm/nimbus/inbox/stormjar-20e3fcfc-6233-4b71-9ebb-1fe4963a7276.jar
2016-01-27 23:43:14 b.s.d.nimbus [INFO] Finished uploading file from client: /data/storm/nimbus/inbox/stormjar-20e3fcfc-6233-4b71-9ebb-1fe4963a7276.jar实际上意思就是将我们的wordcountapp的jar文件wordcountapp-0.0.1-SNAPSHOT-jar-with-dependencies.jar上传到了/data/storm/nimbus/inbox/目录下,并且将jar文件的名称改成了stormjar-20e3fcfc-6233-4b71-9ebb-1fe4963a7276.jar
我们安装storm时配置,storm运行时存储数据目录
storm.local.dir: "/data/storm"2)nimbus分配执行线程
当jar文件上传完成之后,storm首先会检查这个Topology的配置信息,例如需要几个worker来运行。然后storm会查询集群中可用slot(等价于worker)的数量。因为Topology需要运行在worker上,而且一个worker只能运行一个Topology,所以Storm必须先要查询那些worker事空闲的,以便将Topology分配到这些空闲的worker上。这段分析我们还可以通过分析nimbus.log的日志文件进行查看。
#检查Topology的配置信息
2016-01-27 23:43:14 b.s.d.nimbus [INFO] Received topology submission for wordcountapp with conf {"topology.max.task.parallelism" nil, "topology.acker.executors" nil, "topology.kryo.register"
nil, "topology.kryo.decorators" (), "topology.name" "wordcountapp", "storm.id" "wordcountapp-1-1453909394", "topology.debug" false, "fileName" "words.txt"}
2016-01-27 23:43:14 b.s.d.nimbus [INFO] Activating wordcountapp: wordcountapp-1-1453909394
#检查集群中可用的Slots,等价于worker
2016-01-27 23:43:14 b.s.s.EvenScheduler [INFO] Available slots: (["c612a070-af7d-4335-b034-08ae33269f3a" 6703] ["c612a070-af7d-4335-b034-08ae33269f3a" 6702] ["c612a070-af7d-4335-b034-08ae3326
9f3a" 6701] ["c612a070-af7d-4335-b034-08ae33269f3a" 6700])3)执行线程下载代码
分配到任务的supervisor从nimbus上下载Topology的jar文件,因为Topology的jar文件还在nimbus所在的机器上,所以supervisor必须从nimbus上来下载这些jar文件到本地,然后才能运行。我们可以看一下supervisor.log
#supervisor从nimbus机器上下载Topology的jar文件
2016-01-27 23:43:14 b.s.d.supervisor [INFO] Downloading code for storm id wordcountapp-1-1453909394 from /data/storm/nimbus/stormdist/wordcountapp-1-1453909394
#将下载的文件存储到/data/storm/nimbus/stormdist/wordcountapp-1-1453909394
2016-01-27 23:43:14 b.s.d.supervisor [INFO] Finished downloading code for storm id wordcountapp-1-1453909394 from /data/storm/nimbus/stormdist/wordcountapp-1-1453909394
#启动Topology
2016-01-27 23:43:14 b.s.d.supervisor [INFO] Launching worker with assignment #backtype.storm.daemon.supervisor.LocalAssignment{:storm-id "wordcountapp-1-1453909394", :executors ([3 3] [4 4] [
2 2] [1 1])} for this supervisor c612a070-af7d-4335-b034-08ae33269f3a on port 6703 with id c1cb4fc0-1906-48bf-be5e-e1b29229c89a........省略部分日志........./data/storm/supervisor/stormdist/wordcountapp-1-1453909394/stormjar.jar' 'backtype.storm.daemon.worker' 'wordcountapp-1-1453909394' 'c612a070-af7d-4335-b034-08ae33269f3a' '6703' 'c1cb4fc0-1906-48bf-be5e-e1b29229c89a'2.storm的grouping策略和并发度
1)拓扑运行在单个worker上
我们了解到storm集群遵循一般集群的master/slaver结构,nimbus负责调度监控,supervisor负责任务执行,每个supervisor代表一个主机,在这个主机上可以有多个worker(默认4个),而每个worker中有可以有多个线程(Executer)来运行。Executer就是Topology运行的最小单元。
TopologyBuilder builder = new TopologyBuilder();
builder.setSpout("word-reader", new WordReader(),3);
builder.setBolt("word-normalizer", new WordNormalizer(),3).shuffleGrouping("word-reader");
builder.setBolt("word-counter", new WordCounter()).fieldsGrouping("word-normalizer", new Fields("word"));
StormTopology topology = builder.createTopology();Storm默认就会给这个Topology分配1个Worker,在这个Worker启动7个线程,3个用来运行WordReader,3个线程用来运行WordNormalizer,1个线程用来运行WordCounter。
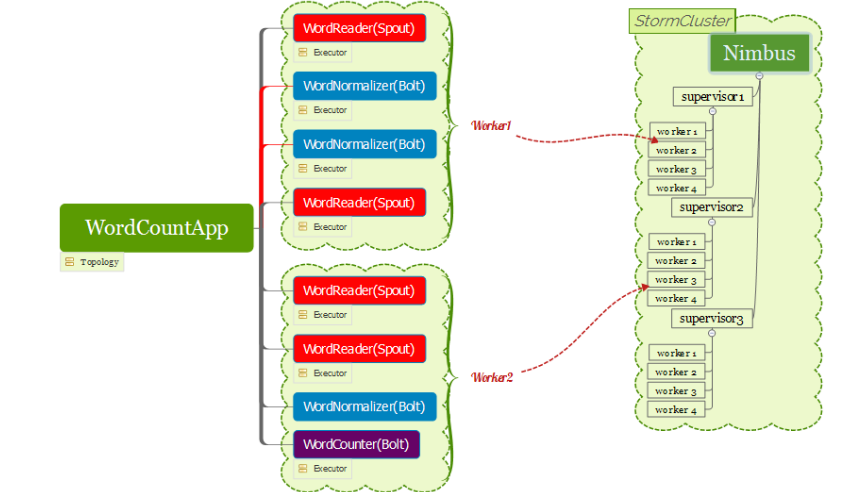
2)拓扑运行在多个worker上
一个Topology也可以运行在多个worker上,下图例子是有一个拓扑运行在两个worker上,其中一个worker上面运行2个WordReader,2个WordNormalizer。而另一个worker上面运行2个WordReader和1个WordNormalizer以及1个WordCounter。
3.Grouping策略介绍
1)随机分组
Shuffle Grouping: 随机分组, 随机派发stream里面的tuple, 保证每个bolt接收到的tuple数目相同。轮询,平均分配。
2)按字段分组
Fields Grouping:按字段分组, 比如按userid来分组, 具有同样userid的tuple会被分到相同的Bolts, 而不同的userid则会被分配到不同的Bolts。
3)广播分组
All Grouping: 广播发送, 对于每一个tuple, 所有的Bolts都会收到。
4)全局分组
Global Grouping: 全局分组, 这个tuple被分配到storm中的一个bolt的其中一个task。再具体一点就是分配给id值最低的那个task。
5)不分组
Non Grouping: 不分组, 这个分组的意思是说stream不关心到底谁会收到它的tuple。目前这种分组和Shuffle grouping是一样的效果,不平均分配。
6)直接分组
Direct Grouping: 直接分组, 这是一种比较特别的分组方法,用这种分组意味着消息的发送者举鼎由消息接收者的哪个task处理这个消息。 只有被声明为Direct Stream的消息流可以声明这种分组方法。而且这种消息tuple必须使用emitDirect方法来发射。消息处理者可以通过TopologyContext来或者处理它的消息的taskid(OutputCollector.emit方法也会返回taskid)
4.消息可靠性
Storm 能够保证每一个由 Spout 发送的消息都能够得到完整地处理。
1)消息完整性处理
一个从 spout 中发送出的 tuple 会产生上千个基于它创建的 tuples。如果当该tuple产生的上千个tuples都处理完成时,称该spout得到完整性验证。
比如我们计算单词个数的例子中,我们从文件中读取一行字符串就会产生一个tuple,然后该字符串会被发送出去进而解析成多个单词的tuple,然后每个单词的tuple又会产生一个计数的tuple。只有当所有单词tuple和计数tuple都处理完成之后,该从文件中读取的字符串的tuple才算完整性处理。
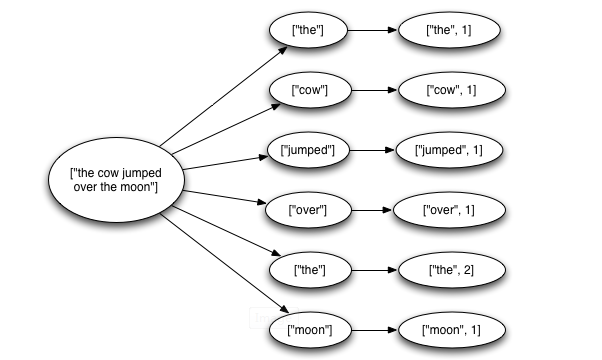
我们可以根据storm中tuple的生命周期来帮助我们理解:
public interface ISpout extends Serializable {
void open(Map conf, TopologyContext context, SpoutOutputCollector collector);
void close();
void nextTuple();
void ack(Object msgId);
void fail(Object msgId);
}首先,通过调用 Spout 的 nextTuple 方法,Storm 向 Spout 请求一个 tuple。Spout 会使用 open 方法中提供的SpoutOutputCollector 向它的一个输出数据流中发送一个 tuple。在发送 tuple 的时候,Spout 会提供一个 “消息 id”,这个 id 会在后续过程中用于识别 tuple。
消息从spout中发送出去时调用this.collector.emit(new Values(str),msgId);方法。
这里在消息向下传递的过程中经过bolt时需要调用:
//bolt中的execute(Tuple input)处理代码
collector.emit(input,new Values(word));
//而不是
collector.emit(new Values(word));也就是说如果要把bolt中tuple算作spout的完整性,就需要把tuple传递下去,然后在该bolt中调用方法:
//bolt中的execute(Tuple input)处理代码
collector.ack(input);当所有由该发送出去的tuple产生的子孙tuples被处理完成且都调用了collector.ack(input)方法就会回调spout中 的ack(Object msgId) 方法证明该spout发出去的tuple被处理成功。
当有其中bolt处理消息时调用了collector.fail(input)方法,则表明子tuple中有没有被成功处理的消息存在,就会导致spout中调用fail(Object msgId)方法。
注意:如果在向下传递的过程中bolt没有传递tuple,也就是没有调用emit(input,new Values(word))则无法验证消息“完整性处理”。如果在向下传递的过程中没有调用collector.ack(input)或者collector.fail(input)也无法进行消息的“完整性处理”。















 315
315











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









