







- 错误:
UnicodeDecodeError: 'utf-8' codec can't decode byte 0xf6 in position 894: invalid start byte- 指向位置:
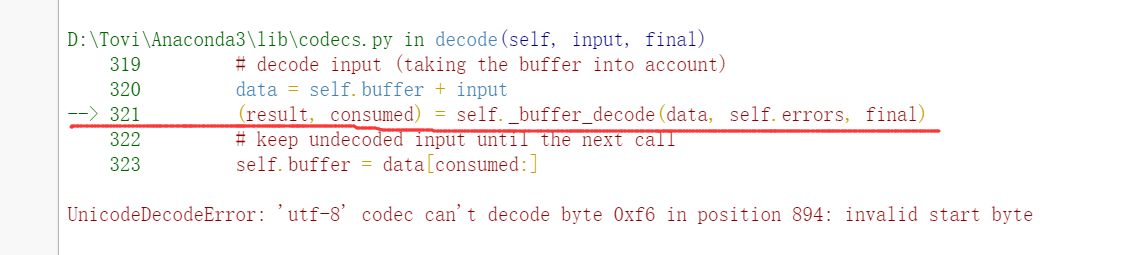
- 原因:
data = open(filepath, 'rt', encoding='utf-8')- 解决办法:读取文件时加error属性
data = open(filepath, 'rt', encoding='utf-8',errors='replace')主要原因:所读取的文件中有乱码,多是从网页爬取,而形成的乱码字符
过程:
开始以为是编码问题,定位到编码问题,其实是方向错误。
对于编码问题的解释太多了:
参考:http://pycoders-weekly-chinese.readthedocs.io/en/latest/issue5/unipain.html(通俗的方式说明编码问题的由来和多种解决方式)
参考:http://www.tuicool.com/articles/6RNv22y(只是解决问题型)
python2中解决方法 参考:http://www.cnblogs.com/zhaoyl/p/3770340.html
在前面加上以下代码即可
import sys reload(sys) # Python2.5 初始化后会删除 sys.setdefaultencoding 这个方法,我们需要重新载入 sys.setdefaultencoding('utf-8')而在Python3中:如果在控制台中运行,就遇到了如下的UnicodeEncodeError:
1.原因 #参考了http://www.tuicool.com/articles/nEjiEv
首先,代码中的html.text会自动将获取的内容解析为unicode (与html.content不同。两者区别就是html.content的类型是bytes,而html.text类型是str,bytes通过解码(decode)可以得到st r,str通过编码(encode)得到bytes) html.text这种字符串如果要输出应当用utf-8来编码。而cmd中,(对于多数中国人所用的是中文的系统)默认字符编码是gbk
从而导致此种现象:python要将utf-8编码的字符串,在gbk的cmd的中打印出来。于是出现了编码错误
2.解决方法 原文中在贴了含有真正解决方法的网页的网址,
http://www.crifan.com/summary_python_2_x_common_string_encode_decode_error_reason_and_solution/
我最终办法就是使用Pycharm这个IDE来运行查看结果,中文部分就能正常显示了。
至于如何在cmd上解决print的问题我仍然不知道如何解决。
写入文件时引发的UnicodeEncodeError:
参考:https://segmentfault.com/a/1190000004269037
在测试过程中多次出现在写入文件时报告错误“UnicodeEncodeError: 'ascii' codec can't encode character '\u56de' in position 0: ordinal not in range(128)”,这是由于我们在抓取网页的时候采用的是UTF-8编码,而存储时没有指定编码,在存储到文件的过程中就会报错。
解决办法为:在读取文件时加入指定UTF-8编码的选项
f = open('content.txt','a',encoding='UTF-8')另外需要注意的是使用requests获取到网页之后同样要指定编码
html = requests.get(url) html = re.sub(r'charset=(/w*)', 'charset=UTF-8', html.text)另外:关于编码问题
参考:以下网址(几乎包含了能遇到的问题,作者善于总结,并一一讲述问题和解决思路)
http://www.crifan.com/summary_python_2_x_common_string_encode_decode_error_reason_and_solution/(找我自己的笔记本)
总结 2017.05.10:
1. 如果遇到编码问题,首先,是否添加encoding属性;其次,“文件编码”与“读取编码”是否一致;最后,是否需要进行专门的编码转换。
2. 就读取文件本身来说,可进行模式设置,即回归官网
- Built-in Functions¶ 内置函数中寻找open function
open(file, mode='r', buffering=-1, encoding=None, errors=None, newline=None, closefd=True, opener=None)
Character Meaning 'r'open for reading (default) 'w'open for writing, truncating the file first 'x'open for exclusive creation, failing if the file already exists 'a'open for writing, appending to the end of the file if it exists 'b'binary mode 't'text mode (default) '+'open a disk file for updating (reading and writing) 'U'universal newlines mode (deprecated) Error Handlers¶ 主要涉及以下三种方法 当然还有其他,需要的时候去看
Value Meaning 'strict'Raise UnicodeError(or a subclass); this is the default. Implemented instrict_errors().'ignore'Ignore the malformed data and continue without further notice. Implemented in ignore_errors().The following error handlers are only applicable to text encodings:
Value Meaning 'replace'Replace with a suitable replacement marker; Python will use the official U+FFFDREPLACEMENT CHARACTER for the built-in codecs on decoding, and ‘?’ on encoding. Implemented inreplace_errors().3. 着手解决文本本身的问题,不要让其出现乱码。如原文本来自网络爬虫(导致编码问题)。
请尊重劳动成果:https://my.oschina.net/u/1462678/blog/896898















 6299
6299

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









