







 本文介绍了Linux内核中的块设备驱动程序,包括分层结构:块设备驱动、通用块层、IO调度层和映射层。详细阐述了请求队列、gendisk结构体、电梯算法以及VFS的作用。同时提到了块设备驱动实例的编写和可用的内核示例源码。
本文介绍了Linux内核中的块设备驱动程序,包括分层结构:块设备驱动、通用块层、IO调度层和映射层。详细阐述了请求队列、gendisk结构体、电梯算法以及VFS的作用。同时提到了块设备驱动实例的编写和可用的内核示例源码。

块设备驱动程序的分层结构
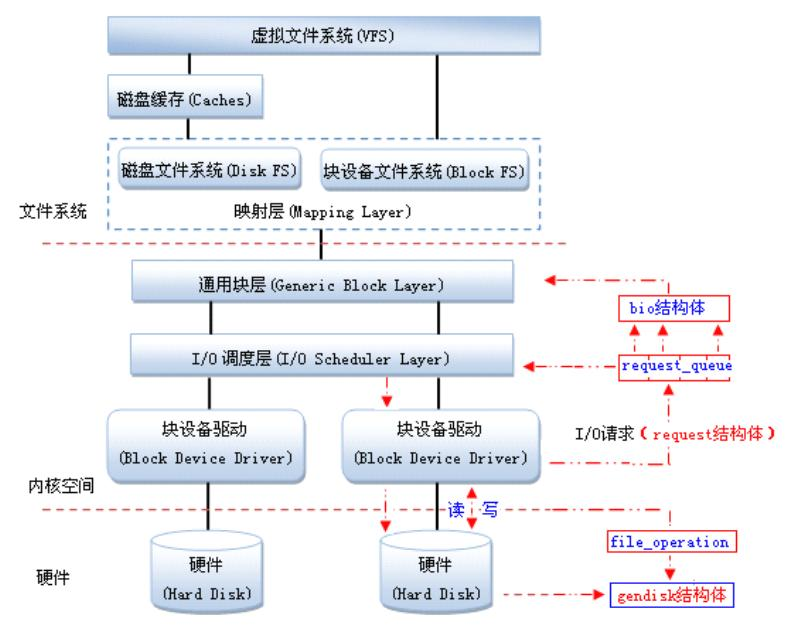
块设备驱动:在Linux中,驱动对块设备的输入或输出(I/O)操作,都会向块设备发出一个请求,在驱动中用request结构体描述。但对于一些磁盘设备而言请求的速度很慢,这时候内核就提供一种队列的机制把这些I/O请求添加到队列中(即:请求队列),在驱动中用request_queue结构体描述。在向块设备提交这些请求前内核会先执行请求的合并和排序预操作,以提高访问的效率,然后再由内核中的I/O调度程序子系统来负责提交 I/O 请求,调度程序将磁盘资源分配给系统中所有挂起的块 I/O 请求,其工作是管理块设备的请求队列,决定队列中的请求的排列顺序以及什么时候派发请求到设备。
通用块层(Generic Block Layer):负责维持一个I/O请求在上层文件系统与底层物理磁盘之间的关系。在通用块层中,通常用一个bio结构体来对应一个I/O请求。
Linux提供了一个gendisk数据结构体,用来表示一个独立的磁盘设备或分区,用于对底层物理磁盘进行访问。在gendisk中有一个类似字符设备中file_operations的硬件操作结构指针,是block_device_operations结构体。
IO调度层:当多个请求提交给块设备时,执行效率依赖于请求的顺序。如果所有的请求是同一个方向(如:写数据),执行效率是最大的。内核在调用块设备驱动程序例程处理请求之前,先收集I/O请求并将请求排序,然后,将连续扇区操作的多个请求进行合并以提高执行效率(内核算法会自己做,不用你管),对I/O请求排序的算法称为电梯算法(elevator algorithm)。电梯算法在I/O调度层完成。内核提供了不同类型的电梯算法,电梯算法有
- noop(实现简单的FIFO,基本的直接合并与排序)
- anticipatory(延迟I/O请求,进行临界区的优化排序)
- Deadline(针对anticipatory缺点进行改善,降低延迟时间)
- Cfq(均匀分配I/O带宽,公平机制)
映射层(Mapping Layer):起映射作用,将文件访问映射为设备的访问。
VFS:对各种文件系统进行统一封装,为用户程序访问文件提供统一的接口,包含ext2,FAT,NFS,设备文件。
磁盘缓存(Caches):将访问频率很高的文件放入其中。
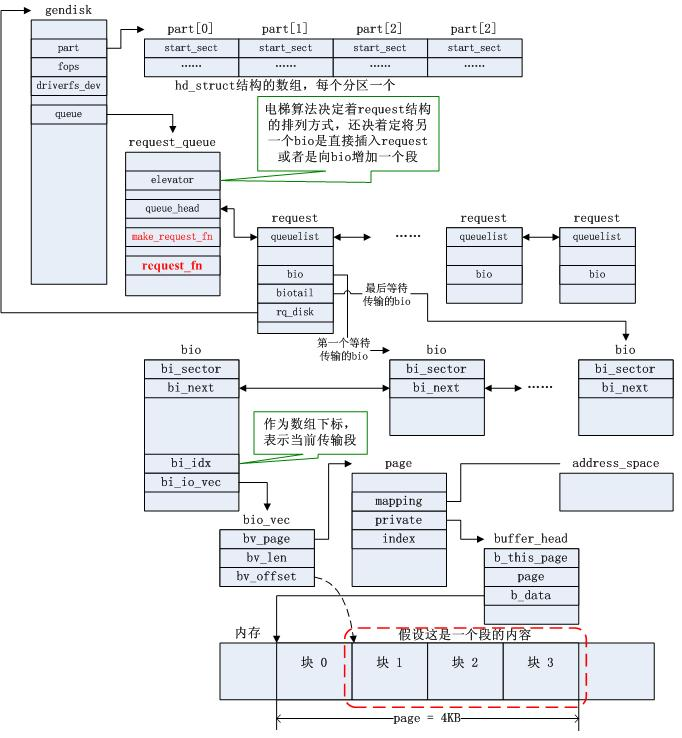
块设备驱动内核数据结构关系图

块设备驱动实例
/*
* Sample disk driver, from the beginning.
*/
#include <linux/module.h>
#include <linux/moduleparam.h>
#include <linux/init.h>
#include <linux/sched.h>
#include <linux/kernel.h> /* printk() */
#include <linux/slab.h> /* kmalloc() */
#include <linux/fs.h> /* everything... */
#include <linux/errno.h> /* error codes */
#include <linux/types.h> /* size_t */
#include <linux/fcntl.h> /* O_ACCMODE */
#include <linux/hdreg.h> /* HDIO_GETGEO */
#include <linux/kdev_t.h>
#include <linux/vmalloc.h>
#include <linux/genhd.h>
#include <linux/blk-mq.h>
#include <linux/buffer_head.h> /* invalidate_bdev */
#include <linux/bio.h>
#ifndef BLK_STS_OK
typedef int blk_status_t;
#define BLK_STS_OK 0
#define OLDER_KERNEL 1
#endif
#ifndef BLK_STS_IOERR
#define BLK_STS_IOERR 10
#endif
#ifndef SECTOR_SHIFT
#define SECTOR_SHIFT 9
#endif
/* FIXME: implement these macros in kernel mainline */
#define size_to_sectors(size) ((size) >> SECTOR_SHIFT)
#define sectors_to_size(size) ((size) << SECTOR_SHIFT)
MODULE_LICENSE("Dual BSD/GPL");
static int sbull_major;
module_param(sbull_major, int, 0);
static int logical_block_size = 512;
module_param(logical_block_size, int, 0);
static char* disk_size = "256M";
module_param(disk_size, charp, 0);
static int ndevices = 1;
module_param(ndevices, int, 0);
static bool debug = false;
module_param(debug, bool, false);
/*
* The different "request modes" we can use.
*/
enum {
RM_SIMPLE = 0, /* The extra-simple request function */
RM_FULL = 1, /* The full-blown version */
RM_NOQUEUE = 2, /* Use make_request */
};
/*
* Minor number and partition management.
*/
#define SBULL_MINORS 16
/*
* We can tweak our hardware sector size, but the kernel talks to us
* in terms of small sectors, always.
*/
#define KERNEL_SECTOR_SIZE 512
/*
* The internal representation of our device.
*/
struct sbull_dev {
int size; /* Device size in sectors */
u8 *data; /* The data array */
spinlock_t lock; /* For mutual exclusion */
struct request_queue *queue; /* The device request queue */
struct gendisk *gd; /* The gendisk structure */
struct blk_mq_tag_set tag_set;
};
static struct sbull_dev *Devices;
/* Handle an I/O request */
static blk_status_t sbull_transfer(struct sbull_dev *dev, unsigned long sector,
unsigned long nsect, char *buffer, int op)
{
unsigned long offset = sectors_to_size(sector);
unsigned long nbytes = sectors_to_size(nsect);
if ((offset + nbytes) > dev->size) {
pr_notice("Beyond-end write (%ld %ld)\n", offset, nbytes);
return BLK_STS_IOERR;
}
if (debug)
pr_info("%s: %s, sector: %ld, nsectors: %ld, offset: %ld,"
" nbytes: %ld",
dev->gd->disk_name,
op == REQ_OP_WRITE ? "WRITE" : "READ", sector, nsect,
offset, nbytes);
/* will be only REQ_OP_READ or REQ_OP_WRITE */
if (op == REQ_OP_WRITE)
memcpy(dev->data + offset, buffer, nbytes);
else
memcpy(buffer, dev->data + offset, nbytes);
return BLK_STS_OK;
}
static blk_status_t sbull_queue_rq(struct blk_mq_hw_ctx *hctx,
const struct blk_mq_queue_data *bd)
{
struct request *req = bd->rq;
struct sbull_dev *dev = req->rq_disk->private_data;
int op = req_op(req);
blk_status_t ret;
blk_mq_start_request(req);
spin_lock(&dev->lock);
if (op != REQ_OP_READ && op != REQ_OP_WRITE) {
pr_notice("Skip non-fs request\n");
blk_mq_end_request(req, BLK_STS_IOERR);
spin_unlock(&dev->lock);
return BLK_STS_IOERR;
}
ret = sbull_transfer(dev, blk_rq_pos(req),
blk_rq_cur_sectors(req),
bio_data(req->bio), op);
blk_mq_end_request(req, ret);
spin_unlock(&dev->lock);
return ret;
}
/*
* The device operations structure.
*/
static const struct block_device_operations sbull_ops = {
.owner = THIS_MODULE,
};
static const struct blk_mq_ops sbull_mq_ops = {
.queue_rq = sbull_queue_rq,
};
static struct request_queue *create_req_queue(struct blk_mq_tag_set *set)
{
struct request_queue *q;
#ifndef OLDER_KERNEL
q = blk_mq_init_sq_queue(set, &sbull_mq_ops,
2, BLK_MQ_F_SHOULD_MERGE | BLK_MQ_F_BLOCKING);
#else
int ret;
memset(set, 0, sizeof(*set));
set->ops = &sbull_mq_ops;
set->nr_hw_queues = 1;
/*set->nr_maps = 1;*/
set->queue_depth = 2;
set->numa_node = NUMA_NO_NODE;
set->flags = BLK_MQ_F_SHOULD_MERGE | BLK_MQ_F_BLOCKING;
ret = blk_mq_alloc_tag_set(set);
if (ret)
return ERR_PTR(ret);
q = blk_mq_init_queue(set);
if (IS_ERR(q)) {
blk_mq_free_tag_set(set);
return q;
}
#endif
return q;
}
/*
* Set up our internal device.
*/
static void setup_device(struct sbull_dev *dev, int which)
{
long long sbull_size = memparse(disk_size, NULL);
memset(dev, 0, sizeof(struct sbull_dev));
dev->size = sbull_size;
dev->data = vzalloc(dev->size);
if (dev->data == NULL) {
pr_notice("vmalloc failure.\n");
return;
}
spin_lock_init(&dev->lock);
dev->queue = create_req_queue(&dev->tag_set);
if (IS_ERR(dev->queue))
goto out_vfree;
blk_queue_logical_block_size(dev->queue, logical_block_size);
dev->queue->queuedata = dev;
/*
* And the gendisk structure.
*/
dev->gd = alloc_disk(SBULL_MINORS);
if (!dev->gd) {
pr_notice("alloc_disk failure\n");
goto out_vfree;
}
dev->gd->major = sbull_major;
dev->gd->first_minor = which*SBULL_MINORS;
dev->gd->fops = &sbull_ops;
dev->gd->queue = dev->queue;
dev->gd->private_data = dev;
snprintf(dev->gd->disk_name, 32, "sbull%c", which + 'a');
set_capacity(dev->gd, size_to_sectors(sbull_size));
add_disk(dev->gd);
return;
out_vfree:
if (dev->data)
vfree(dev->data);
}
static int __init sbull_init(void)
{
int i;
/*
* Get registered.
*/
sbull_major = register_blkdev(sbull_major, "sbull");
if (sbull_major <= 0) {
pr_warn("sbull: unable to get major number\n");
return -EBUSY;
}
/*
* Allocate the device array, and initialize each one.
*/
Devices = kmalloc(ndevices * sizeof(struct sbull_dev), GFP_KERNEL);
if (Devices == NULL)
goto out_unregister;
for (i = 0; i < ndevices; i++)
setup_device(Devices + i, i);
return 0;
out_unregister:
unregister_blkdev(sbull_major, "sbull");
return -ENOMEM;
}
static void sbull_exit(void)
{
int i;
for (i = 0; i < ndevices; i++) {
struct sbull_dev *dev = Devices + i;
if (dev->gd) {
del_gendisk(dev->gd);
put_disk(dev->gd);
}
if (dev->queue)
blk_cleanup_queue(dev->queue);
if (dev->data)
vfree(dev->data);
}
unregister_blkdev(sbull_major, "sbull");
kfree(Devices);
}
module_init(sbull_init);
module_exit(sbull_exit);可以编写Makefile:
obj-m += sbull.o
CURRENT_PATH:=$(shell pwd)
LINUX_KERNEL:=$(shell uname -r)
LINUX_KERNEL_PATH:=/usr/src/kernels/$(LINUX_KERNEL)
all:
make -C $(LINUX_KERNEL_PATH) M=$(CURRENT_PATH) modules
clean:
make -C $(LINUX_KERNEL_PATH) M=$(CURRENT_PATH) clean
或者直接使用linux内核中提供的/drivers/block/brd.c
/*
* Ram backed block device driver.
*
* Copyright (C) 2007 Nick Piggin
* Copyright (C) 2007 Novell Inc.
*
* Parts derived from drivers/block/rd.c, and drivers/block/loop.c, copyright
* of their respective owners.
*/
#include <linux/init.h>
#include <linux/initrd.h>
#include <linux/module.h>
#include <linux/moduleparam.h>
#include <linux/major.h>
#include <linux/blkdev.h>
#include <linux/bio.h>
#include <linux/highmem.h>
#include <linux/mutex.h>
#include <linux/radix-tree.h>
#include <linux/fs.h>
#include <linux/slab.h>
#include <linux/backing-dev.h>
#include <linux/uaccess.h>
#define PAGE_SECTORS_SHIFT (PAGE_SHIFT - SECTOR_SHIFT)
#define PAGE_SECTORS (1 << PAGE_SECTORS_SHIFT)
static int ramdisk_major;
/*
* Each block ramdisk device has a radix_tree brd_pages of pages that stores
* the pages containing the block device's contents. A brd page's ->index is
* its offset in PAGE_SIZE units. This is similar to, but in no way connected
* with, the kernel's pagecache or buffer cache (which sit above our block
* device).
*/
struct brd_device {
int brd_number;
struct request_queue *brd_queue;
struct gendisk *brd_disk;
struct list_head brd_list;
/*
* Backing store of pages and lock to protect it. This is the contents
* of the block device.
*/
spinlock_t brd_lock;
struct radix_tree_root brd_pages;
};
/*
* Look up and return a brd's page for a given sector.
*/
static struct page *brd_lookup_page(struct brd_device *brd, sector_t sector)
{
pgoff_t idx;
struct page *page;
/*
* The page lifetime is protected by the fact that we have opened the
* device node -- brd pages will never be deleted under us, so we
* don't need any further locking or refcounting.
*
* This is strictly true for the radix-tree nodes as well (ie. we
* don't actually need the rcu_read_lock()), however that is not a
* documented feature of the radix-tree API so it is better to be
* safe here (we don't have total exclusion from radix tree updates
* here, only deletes).
*/
rcu_read_lock();
idx = sector >> PAGE_SECTORS_SHIFT; /* sector to page index */
page = radix_tree_lookup(&brd->brd_pages, idx);
rcu_read_unlock();
BUG_ON(page && page->index != idx);
return page;
}
/*
* Look up and return a brd's page for a given sector.
* If one does not exist, allocate an empty page, and insert that. Then
* return it.
*/
static struct page *brd_insert_page(struct brd_device *brd, sector_t sector)
{
pgoff_t idx;
struct page *page;
gfp_t gfp_flags;
page = brd_lookup_page(brd, sector);
if (page)
return page;
/*
* Must use NOIO because we don't want to recurse back into the
* block or filesystem layers from page reclaim.
*/
gfp_flags = GFP_NOIO | __GFP_ZERO | __GFP_HIGHMEM;
page = alloc_page(gfp_flags);
if (!page)
return NULL;
if (radix_tree_preload(GFP_NOIO)) {
__free_page(page);
return NULL;
}
spin_lock(&brd->brd_lock);
idx = sector >> PAGE_SECTORS_SHIFT;
page->index = idx;
if (radix_tree_insert(&brd->brd_pages, idx, page)) {
__free_page(page);
page = radix_tree_lookup(&brd->brd_pages, idx);
BUG_ON(!page);
BUG_ON(page->index != idx);
}
spin_unlock(&brd->brd_lock);
radix_tree_preload_end();
return page;
}
/*
* Free all backing store pages and radix tree. This must only be called when
* there are no other users of the device.
*/
#define FREE_BATCH 16
static void brd_free_pages(struct brd_device *brd)
{
unsigned long pos = 0;
struct page *pages[FREE_BATCH];
int nr_pages;
do {
int i;
nr_pages = radix_tree_gang_lookup(&brd->brd_pages,
(void **)pages, pos, FREE_BATCH);
for (i = 0; i < nr_pages; i++) {
void *ret;
BUG_ON(pages[i]->index < pos);
pos = pages[i]->index;
ret = radix_tree_delete(&brd->brd_pages, pos);
BUG_ON(!ret || ret != pages[i]);
__free_page(pages[i]);
}
pos++;
/*
* This assumes radix_tree_gang_lookup always returns as
* many pages as possible. If the radix-tree code changes,
* so will this have to.
*/
} while (nr_pages == FREE_BATCH);
}
/*
* copy_to_brd_setup must be called before copy_to_brd. It may sleep.
*/
static int copy_to_brd_setup(struct brd_device *brd, sector_t sector, size_t n)
{
unsigned int offset = (sector & (PAGE_SECTORS-1)) << SECTOR_SHIFT;
size_t copy;
copy = min_t(size_t, n, PAGE_SIZE - offset);
if (!brd_insert_page(brd, sector))
return -ENOSPC;
if (copy < n) {
sector += copy >> SECTOR_SHIFT;
if (!brd_insert_page(brd, sector))
return -ENOSPC;
}
return 0;
}
/*
* Copy n bytes from src to the brd starting at sector. Does not sleep.
*/
static void copy_to_brd(struct brd_device *brd, const void *src,
sector_t sector, size_t n)
{
struct page *page;
void *dst;
unsigned int offset = (sector & (PAGE_SECTORS-1)) << SECTOR_SHIFT;
size_t copy;
pr_info("copy_to_ramdisk: sector: %d,size: %d\n",(int)sector,(int)n);
copy = min_t(size_t, n, PAGE_SIZE - offset);
page = brd_lookup_page(brd, sector);
BUG_ON(!page);
dst = kmap_atomic(page);
memcpy(dst + offset, src, copy);
kunmap_atomic(dst);
if (copy < n) {
src += copy;
sector += copy >> SECTOR_SHIFT;
copy = n - copy;
page = brd_lookup_page(brd, sector);
BUG_ON(!page);
dst = kmap_atomic(page);
memcpy(dst, src, copy);
kunmap_atomic(dst);
}
}
/*
* Copy n bytes to dst from the brd starting at sector. Does not sleep.
*/
static void copy_from_brd(void *dst, struct brd_device *brd,
sector_t sector, size_t n)
{
struct page *page;
void *src;
unsigned int offset = (sector & (PAGE_SECTORS-1)) << SECTOR_SHIFT;
size_t copy;
pr_info("copy_from_ramdisk: sector: %d,size: %d\n",(int)sector,(int)n);
copy = min_t(size_t, n, PAGE_SIZE - offset);
page = brd_lookup_page(brd, sector);
if (page) {
src = kmap_atomic(page);
memcpy(dst, src + offset, copy);
kunmap_atomic(src);
} else
memset(dst, 0, copy);
if (copy < n) {
dst += copy;
sector += copy >> SECTOR_SHIFT;
copy = n - copy;
page = brd_lookup_page(brd, sector);
if (page) {
src = kmap_atomic(page);
memcpy(dst, src, copy);
kunmap_atomic(src);
} else
memset(dst, 0, copy);
}
}
/*
* Process a single bvec of a bio.
*/
static int brd_do_bvec(struct brd_device *brd, struct page *page,
unsigned int len, unsigned int off, unsigned int op,
sector_t sector)
{
void *mem;
int err = 0;
if (op_is_write(op)) {
err = copy_to_brd_setup(brd, sector, len);
if (err)
goto out;
}
mem = kmap_atomic(page);
if (!op_is_write(op)) {
copy_from_brd(mem + off, brd, sector, len);
flush_dcache_page(page);
} else {
flush_dcache_page(page);
copy_to_brd(brd, mem + off, sector, len);
}
kunmap_atomic(mem);
out:
return err;
}
static blk_qc_t brd_make_request(struct request_queue *q, struct bio *bio)
{
struct brd_device *brd = bio->bi_disk->private_data;
struct bio_vec bvec;
sector_t sector;
struct bvec_iter iter;
sector = bio->bi_iter.bi_sector;
if (bio_end_sector(bio) > get_capacity(bio->bi_disk))
goto io_error;
bio_for_each_segment(bvec, bio, iter) {
unsigned int len = bvec.bv_len;
int err;
err = brd_do_bvec(brd, bvec.bv_page, len, bvec.bv_offset,
bio_op(bio), sector);
if (err)
goto io_error;
sector += len >> SECTOR_SHIFT;
}
bio_endio(bio);
return BLK_QC_T_NONE;
io_error:
bio_io_error(bio);
return BLK_QC_T_NONE;
}
static int brd_rw_page(struct block_device *bdev, sector_t sector,
struct page *page, unsigned int op)
{
struct brd_device *brd = bdev->bd_disk->private_data;
int err;
if (PageTransHuge(page))
return -ENOTSUPP;
err  最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 525
525

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









