






【节选自《流畅的Python》第16章-协程】
一、综述
字典为动词“to yield”给出了两个释义:产出和让步。对于 Python 生成器中的 yield 来说,这两个含义都成立。
yield item 这行代码会产出一个值,提供给 next(...) 的调用方;
此外,还会作出让步,暂停执行生成器,让调用方继续工作,直到需要使用另一个值时再调用next()。调用方会从生成器中拉取值。
从句法上看,协程与生成器类似,都是定义体中包含 yield 关键字的函数。
可是,在协程中,yield 通常出现在表达式的右边(例如,datum = yield),可以产出值,也可以不产出——
如果 yield关键字后面没有表达式,那么生成器产出 None。
协程可能会从调用方接收数据,不过调用方把数据提供给协程使用的是 .send(datum) 方法,而不是 next(...) 函数。通常,调用方会把值推送给协程。
yield 关键字甚至还可以不接收或传出数据。
不管数据如何流动,yield 都是一种流程控制工具,使用它可以实现协作式多任务:协程可以把控制器让步给中心调度程序,从而激活其他的协程。
从根本上把 yield 视作控制流程的方式,这样就好理解协程了。
二、协程最简单的使用演示
def simple_coroutine(): print('-> coroutine started.') x = yield print('-> coroutine received:', x) my_coro = simple_coroutine() print(my_coro) #generator object next(my_coro) print(my_coro.send(42))
结果如下:

1、协程使用生成器函数定义:定义体中有 yield 关键字。
2、yield 在表达式中使用;如果协程只需从客户那里接收数据,那么产出的值是 None——这个值是隐式指定的,因为 yield 关键字右边没有表达式。
3、与创建生成器的方式一样,调用函数得到生成器对象。
4、首先要调用 next(...) 函数,因为生成器还没启动,没在 yield 语句处暂停,所以一开始无法发送数据。
5、调用这个方法后,协程定义体中的 yield 表达式会计算出 42;现在,协程会恢复,一直运行到下一个 yield 表达式,或者终止。
6、最后,控制权流动到协程定义体的末尾,导致生成器像往常一样抛出 StopIteration 异常。
三、协程可以身处四个状态
当前状态可以使用inspect.getgeneratorstate(...) 函数确定,该函数会返回下述字符串中的一个。
1、'GEN_CREATED' 等待开始执行。
2、'GEN_RUNNING' 解释器正在执行。
注意:只有在多线程应用中才能看到这个状态。此外,生成器对象在自己身上调用getgeneratorstate 函数也行,不过这样做没什么用。
3、'GEN_SUSPENDED' 在 yield 表达式处暂停。
4、'GEN_CLOSED' 执行结束。
因为 send 方法的参数会成为暂停的 yield 表达式的值,所以,仅当协程处于暂停状态时才能调用 send 方法,例如 my_coro.send(42)。
不过,如果协程还没激活(即,状态是 'GEN_CREATED'),情况就不同了。
因此,始终要调用 next(my_coro) 激活协程——也可以调用my_coro.send(None),效果一样。
如果创建协程对象后立即把 None 之外的值发给它,会出现下述错误:
my_coro = simple_coroutine()
my_coro.send(23)

注意错误消息,它表述得相当清楚。最先调用 next(my_coro) 函数这一步通常称为“预激”(prime)协程。
(即,让协程向前执行到第一个 yield 表达式,准备好作为活跃的协程使用)
下面举个产出多个值的例子,以便更好地理解协程的行为:
from inspect import getgeneratorstate def simple_coro2(a): print('-> Started: a=', a) b = yield a print('-> Received: b=', b) c = yield a + b print('-> Received: c=', c) my_coro2 = simple_coro2(14) state = getgeneratorstate(my_coro2) print(state) # GEN_CREATED next(my_coro2) # -> Started: a= 14 state = getgeneratorstate(my_coro2) print(state) # GET_SUSPENDED my_coro2.send(28) # -> Received: b= 28 my_coro2.send(99) # -> Received: c= 99 # Traceback (most recent call last): # File "<stdin>", line 1, in <module> # StopIteration state = getgeneratorstate(my_coro2) print(state) # GEN_CLOSED
1、首先inspect.getgeneratorstate 函数指明,处于 GEN_CREATED 状态(即协程未启动)。
2、向前执行协程到第一个 yield 表达式,打印 -> Started: a = 14消息,然后产出(yield)a 的值,并且暂停,等待为 b 赋值。
3、getgeneratorstate 函数指明,处于 GEN_SUSPENDED 状态(即协程在 yield 表达式处暂停)。
4、把数字 28 发给暂停的协程;计算 yield 表达式,得到 28,然后把那个数绑定给 b,打印 -> Received: b = 28 消息,
然后产出(yield) a + b 的值(42),并且协程暂停,等待为 c 赋值。
5、把数字 99 发给暂停的协程;计算 yield 表达式,得到 99,然后把那个数绑定给 c,打印 -> Received: c = 99 消息,
然后协程终止,导致生成器对象抛出 StopIteration 异常。
6、最后getgeneratorstate 函数指明,处于 GEN_CLOSED 状态(即协程执行结束)。
关键的一点是,协程在 yield 关键字所在的位置暂停执行。前面说过,在赋值语句中,= 右边的代码在赋值之前执行。
因此,对于 b =yield a 这行代码来说,等到客户端代码再激活协程时才会设定 b 的值。
这种行为要花点时间才能习惯,不过一定要理解,这样才能弄懂异步编程中 yield 的作用(后文探讨)。
simple_coro2 协程的执行过程分为 3 个阶段,如下图所示。
1、调用 next(my_coro2),打印第一个消息,然后执行 yield a,产出数字 14。
2、调用 my_coro2.send(28),把 28 赋值给 b,打印第二个消息,然后执行 yield a + b,产出数字 42。
3、调用 my_coro2.send(99),把 99 赋值给 c,打印第三个消息,协程终止。
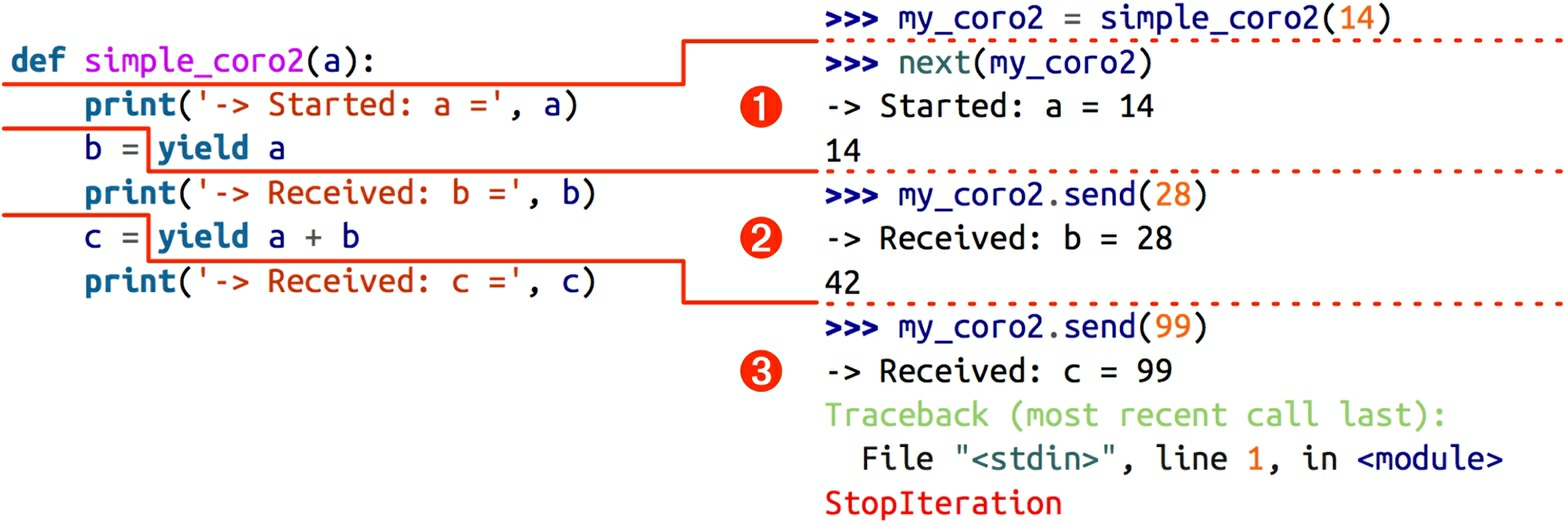
注意,各个阶段都在yield 表达式中结束,而且下一个阶段都从那一行代码开始,然后再把 yield 表达式的值赋给变量!
四、示例:使用协程计算平均值
def averager(): total = 0.0 count = 0 average = None while True: term = yield average total += term count += 1 average = total / count
1、这个无限循环表明,只要调用方不断把值发给这个协程,它就会一直接收值,然后生成结果。
仅当调用方在协程上调用 .close() 方法,或者没有对协程的引用而被垃圾回收程序回收时,这个协程才会终止。
2、这里的 yield 表达式用于暂停执行协程,把结果发给调用方;还用于接收调用方后面发给协程的值,恢复无限循环。
使用协程的好处是,total 和 count 声明为局部变量即可,无需使用实例属性或闭包在多次调用之间保持上下文。
使用averager协程:
coro_avg = averager() next(coro_avg) avg = coro_avg.send(10) print(avg) #10.0 avg = coro_avg.send(30) print(avg) #20.0 avg = coro_avg.send(5) print(avg) #15.0
1、创建协程对象。
2、调用 next 函数,预激协程。
3、计算平均值:多次调用 .send(...) 方法,产出当前的平均值。
在上述示例中,调用 next(coro_avg) 函数后,协程会向前执行到 yield 表达式,产出 average 变量的初始值——None,因此不会出现在控制台中。
此时,协程在 yield 表达式处暂停,等到调用方发送值。
coro_avg.send(10) 那一行发送一个值,激活协程,把发送的值赋给 term,并更新 total、count 和 average 三个变量的值,
然后开始 while 循环的下一次迭代,产出 average 变量的值,等待下一次为 term 变量赋值。
五、预激协程的装饰器
如果不预激,那么协程没什么用。调用 my_coro.send(x) 之前,记住一定要调用 next(my_coro)。
为了简化协程的用法,有时会使用一个预激装饰器。
示例:预激协程的装饰器
from functools import wraps def coroutine(func): '''装饰器:向前执行到第一个`yield`表达式,预激`func`''' @wraps(func) def primer(*args, **kwargs): #1 gen = func(*args, **kwargs) #2 next(gen) #3 return gen #4 return primer
1、简单说下装饰器,假如有个名为 decorate 的装饰器:
@decorate def target(): print('running target()')
上述代码的效果与下述写法一样:
def target(): print('running target()')
target = decorate(target)
所以示例中把被装饰的生成器函数替换成这里的 primer 函数;调用 primer 函数时,返回预激后的生成器。
2、调用被装饰的函数,获取生成器对象。
3、预激生成器。
4、返回生成器。
下面展示 @coroutine 装饰器的用法:
""" 用于计算移动平均值的协程 >>> coro_avg = averager() #1 >>> from inspect import getgeneratorstate >>> getgeneratorstate(coro_avg) #2 'GEN_SUSPENDED' >>> coro_avg.send(10) #3 10.0 >>> coro_avg.send(30) 20.0 >>> coro_avg.send(5) 15.0 """
from coroutil import coroutine #4 @coroutine #5 def averager(): #6 total = 0.0 count = 0 average = None while True: term = yield average total += term
1、调用 averager() 函数创建一个生成器对象,在 coroutine 装饰器的 primer 函数中已经预激了这个生成器。
2、getgeneratorstate 函数指明,处于 GEN_SUSPENDED 状态,因此这个协程已经准备好,可以接收值了。
3、可以立即开始把值发给 coro_avg——这正是 coroutine 装饰器的目的。
4、导入 coroutine 装饰器。
5、把装饰器应用到 averager 函数上。
6、函数的定义体
使用 yield from 句法(参见 16.7 节)调用协程时,会自动预激,因此与示例中的 @coroutine 等装饰器不兼容。
Python 3.4 标准库里的 asyncio.coroutine 装饰器不会预激协程,因此能兼容 yield from 句法。
六、终止协程和异常处理
协程中未处理的异常会向上冒泡,传给 next 函数或 send 方法的调用方(即触发协程的对象)。
示例:未处理的异常会导致协程终止
>>> from coroaverager1 import averager >>> coro_avg = averager() >>> coro_avg.send(40) # ➊ 40.0 >>> coro_avg.send(50) 45.0 >>> coro_avg.send('spam') # ➋ Traceback (most recent call last): ... TypeError: unsupported operand type(s) for +=: 'float' and 'str' >>> coro_avg.send(60) # ➌ Traceback (most recent call last): File "<stdin>", line 1, in <module> StopIteration
1、使用 @coroutine 装饰器装饰的 averager 协程,可以立即开始发送值。
2、发送的值不是数字,导致协程内部有异常抛出。
3、由于在协程内没有处理异常,协程会终止。如果试图重新激活协程,会抛出 StopIteration 异常。
出错的原因是,发送给协程的 'spam' 值不能加到 total 变量上。
示例暗示了终止协程的一种方式:发送某个哨符值,让协程退出。
从 Python 2.5 开始,客户代码可以在生成器对象上调用两个方法,显式地把异常发给协程。
这两个方法是 throw 和 close。
generator.throw(exc_type[, exc_value[, traceback]])
致使生成器在暂停的 yield 表达式处抛出指定的异常。如果生成器处理了抛出的异常,代码会向前执行到下一个 yield 表达式,而产出的值会成为调用generator.throw 方法得到的返回值。如果生成器没有处理抛出的异常,异常会向上冒泡,传到调用方的上下文中。
generator.close()
致使生成器在暂停的 yield 表达式处抛出 GeneratorExit 异常。如果生成器没有处理这个异常,或者抛出了 StopIteration 异常(通常是指运行到结尾),调用方不会报错。如果收到 GeneratorExit 异常,生成器一定不能产出值,否则解释器会抛出 RuntimeError 异常。生成器抛出的其他异常会向上冒泡,传给调用方。
下面举例说明如何使用 close 和 throw 方法控制协程。
示例:学习在协程中处理异常的测试代码
class DemoException(Exception): """为这次演示定义的异常类型""" def demo_exc_handling(): print('-> coroutine started.') while True: try: x = yield except DemoException: #1 print('*** DemoException handled. Continuing...') else: #2 print('-> coroutine received: {!r}'.format(x)) raise RuntimeError('This line should never run.') #3
1、特别处理 DemoException 异常。
2、如果没有异常,那么显示接收到的值。
3、这一行永远不会执行,因为只有未处理的异常才会中止那个无限循环,而一旦出现未处理的异常,协程会立即终止。
实验1 :激活和关闭 demo_exc_handling,没有异常
exc_coro = demo_exc_handling() next(exc_coro) # -> coroutine started. exc_coro.send(11) # -> coroutine received: 11 exc_coro.send(22) # -> coroutine received: 22 exc_coro.close() from inspect import getgeneratorstate print(getgeneratorstate(exc_coro)) # GEN_CLOSED
如果把 DemoException 异常传入 demo_exc_handling 协程,它会处理,然后继续运行,如下面的 示例2 所示。
实验2 :把 DemoException 异常传入 demo_exc_handling 不会导致协程中止
exc_coro = demo_exc_handling() next(exc_coro) # -> coroutine started. exc_coro.send(11) # -> coroutine received: 11 exc_coro.throw(DemoException) # *** DemoException handled. Continuing... from inspect import getgeneratorstate print(getgeneratorstate(exc_coro)) # GEN_SUSPENDED
但是,如果传入协程的异常没有处理,协程会停止,即状态变成'GEN_CLOSED'。
实验3 :如果无法处理传入的异常,协程会终止
exc_coro = demo_exc_handling() next(exc_coro) # -> coroutine started. exc_coro.send(11) # -> coroutine received: 11 exc_coro.throw(ZeroDivisionError) # Traceback (most recent call last)...ZeroDivisionError from inspect import getgeneratorstate print(getgeneratorstate(exc_coro)) # 由于上面异常导致程序终止,但状态是GEN_CLOSED
如果不管协程如何结束都想做些清理工作,要把协程定义体中相关的代码放入 try/finally 块中。
实验4:使用 try/finally 块在协程终止时执行操作
def demo_exc_handling(): print('-> coroutine started.') try: while True: try: x = yield except DemoException: print('*** DemoException handled. Continuing...') else: print('-> coroutine received: {!r}'.format(x)) finally: print('-> coroutine ending')
Python 3.3 引入 yield from 结构的主要原因之一与把异常传入嵌套的协程有关。另一个原因是让协程更方便地返回值。
七、让协程返回值
下面的示例是 averager 协程的不同版本,这一版会返回结果。为了说明如何返回值,每次激活协程时不会产出移动平均值。
这么做是为了强调某些协程不会产出值,而是在最后返回一个值(通常是某种累计值)。
示例中的 averager 协程返回的结果是一个 namedtuple,两个字段分别是项数(count)和平均值(average)。
我本可以只返回平均值,但是返回一个元组可以获得累积数据的另一个重要信息——项数。
示例:定义一个求平均值的协程,让它返回一个结果
from collections import namedtuple Result = namedtuple('Result', 'count average') def averager(): total = 0.0 count = 0 average = None while True: term = yield if term is None: break #1 total += term count += 1 average = total / count return Result(count, average) #2
1、为了返回值,协程必须正常终止;因此,这一版 averager 中有个条件判断,以便退出累计循环。
2、返回一个 namedtuple,包含 count 和 average 两个字段。在 Python 3.3 之前,如果生成器返回值,解释器会报句法错误。
示例:如何使用新版averager ()
coro_avg = averager() next(coro_avg) coro_avg.send(10) #1 coro_avg.send(30) coro_avg.send(6.5) coro_avg.send(None) #2
Traceback (most recent call last):
File "...", line 24, in <module>
coro_avg.send(None)
StopIteration: Result(count=3, average=15.5)
1、这一版不产出值。
2、发送 None 会终止循环,导致协程结束,返回结果。一如既往,生成器对象会抛出StopIteration 异常。
异常对象的 value 属性保存着返回的值。
注意:return 表达式的值会偷偷传给调用方,赋值给 StopIteration 异常的一个属性。
这样做有点不合常理,但是能保留生成器对象的常规行为——耗尽时抛出StopIteration 异常。
示例:捕获 StopIteration 异常,获取 averager 返回的值
coro_avg = averager() next(coro_avg) coro_avg.send(10) #1 coro_avg.send(30) coro_avg.send(6.5) try: coro_avg.send(None) except StopIteration as exc: result = exc.value print(result)
获取协程的返回值虽然要绕个圈子,但这是 PEP 380 定义的方式,当我们意识到这一点之后就说得通了:yield from 结构会在内部自动捕获 StopIteration 异常。
这种处理方式与 for 循环处理 StopIteration 异常的方式一样:循环机制使用用户易于理解的方式处理异常。
对 yield from 结构来说,解释器不仅会捕获 StopIteration 异常,还会把value 属性的值变成 yield from 表达式的值(=号 左边的)。
可惜,我们无法在控制台中使用交互的方式测试这种行为,因为在函数外部使用 yield from(以及 yield)会导致句法出错。
八、使用yield from
首先要知道,yield from 是全新的语言结构。它的作用比 yield 多很多,因此人们认为继续使用那个关键字多少会引起误解。
在其他语言中,类似的结构使用 await 关键字,这个名称好多了,因为它传达了至关重要的一点:
在生成器 gen 中使用 yield from subgen() 时,subgen 会获得控制权,把产出的值传给 gen 的调用方,即调用方可以直接控制 subgen。与此同时,gen 会阻塞,等待 subgen 终止。
该书前面内容说过,yield from 可用于简化 for 循环中的 yield 表达式。例如:
def gen(): for c in 'AB': yield c for i in range(1, 3): yield i li = [n for n in gen()] print(li)
输出: ['A', 'B', 1, 2]
可以改写为:
def gen(): yield from 'AB' yield from range(1, 3) li = [n for n in gen()] print(li)
输出: ['A', 'B', 1, 2]
示例:使用 yield from 链接可迭代的对象
def chain(*iterables): for it in iterables: yield from it s = 'ABC' t = tuple(range(3)) li = list(chain(s, t)) print(li) # ['A', 'B', 'C', 0, 1, 2]
注意: s(字符串)和t(元祖)都是可迭代的对象,生成器也是可迭代的对象!
在 Beazley 与 Jones 的《Python Cookbook(第 3 版)中文版》一书中,“4.14 扁平化处理套型的序列”一节有个稍微复杂(不过更有用)的 yield from 示例:
# Example of flattening a nested sequence using subgenerators from collections import Iterable def flatten(items, ignore_types=(str, bytes)): for x in items: if isinstance(x, Iterable) and not isinstance(x, ignore_types): yield from flatten(x) else: yield x items = [1, 2, [3, 4, [5, 6], 7], 8] # Produces 1 2 3 4 5 6 7 8 for x in flatten(items): print(x) items = ['Dave', 'Paula', ['Thomas', 'Lewis']] for x in flatten(items): print(x)
yield from x 表达式对 x 对象所做的第一件事是,调用 iter(x),从中获取迭代器。因此,x 可以是任何可迭代的对象。
可是,如果 yield from 结构唯一的作用是替代产出值的嵌套 for 循环,这个结构很有可能不会添加到 Python 语言中。
yield from 结构的本质作用无法通过简单的可迭代对象说明,而要发散思维,使用嵌套的生成器。
因此,引入 yield from 结构的 PEP 380 才起了“Syntax for Delegating to a Subgenerator”(“把职责委托给子生成器的句法”)这个标题。
yield from 的主要功能是打开双向通道,把最外层的调用方与最内层的子生成器连接起来,这样二者可以直接发送和产出值,还可以直接传入异常,而不用在位于中间的协程中添加大量处理异常的样板代码。有了这个结构,协程可以通过以前不可能的方式委托职责。
若想使用 yield from 结构,就要大幅改动代码。为了说明需要改动的部分,PEP 380 使用了一些专门的术语。
1、委派生成器: 包含 yield from <iterable> 表达式的生成器函数。
2、子生成器: 从 yield from 表达式中 <iterable> 部分获取的生成器。
这就是 PEP 380 的标题(“Syntax for Delegating to a Subgenerator”)中所说的“子生成器”(subgenerator)。
3、调用方:PEP 380 使用“调用方”这个术语指代调用委派生成器的客户端代码。在不同的语境中,我会使用“客户端”代替“调用方”,以此与委派生成器(也是调用方,因为它调用了子生成器)区分开。
示例:使用 yield from 计算平均值并输出统计报告
# BEGIN YIELD_FROM_AVERAGER from collections import namedtuple Result = namedtuple('Result', 'count average') # the subgenerator def averager(): # <1> total = 0.0 count = 0 average = None while True: term = yield # <2> if term is None: # <3> break total += term count += 1 average = total/count return Result(count, average) # <4> # the delegating generator def grouper(results, key): # <5> while True: # <6> results[key] = yield from averager() # <7> # the client code, a.k.a. the caller def main(data): # <8> results = {} for key, values in data.items(): group = grouper(results, key) # <9> next(group) # <10> for value in values: group.send(value) # <11> group.send(None) # important! <12> # print(results) # uncomment to debug report(results) # output report def report(results): for key, result in sorted(results.items()): group, unit = key.split(';') print('{:2} {:5} averaging {:.2f}{}'.format( result.count, group, result.average, unit)) data = { 'girls;kg': [40.9, 38.5, 44.3, 42.2, 45.2, 41.7, 44.5, 38.0, 40.6, 44.5], 'girls;m': [1.6, 1.51, 1.4, 1.3, 1.41, 1.39, 1.33, 1.46, 1.45, 1.43], 'boys;kg': [39.0, 40.8, 43.2, 40.8, 43.1, 38.6, 41.4, 40.6, 36.3], 'boys;m': [1.38, 1.5, 1.32, 1.25, 1.37, 1.48, 1.25, 1.49, 1.46], } if __name__ == '__main__': main(data) # END YIELD_FROM_AVERAGER
程序输出:
9 boys averaging 40.42kg 9 boys averaging 1.39m 10 girls averaging 42.04kg 10 girls averaging 1.43m
1、作为子生成器使用;
2、main函数中客户代码发送的各个值绑定到这里的term变量上;
3、至关重要的终止条件,如果不这么做,使用yield from调用这个协程的生成器会永远阻塞;
4、返回的Result会成为grouper函数中yield from表达式的值(=号左边的);
5、grouper是委派生成器;
6、这个循环每次迭代时会新建一个averager实例;每个实例都是作为协程使用的生成器对象;
7、grouper发送的每个值都会经由yield from处理,通过管道传给averager实例。averager实例运行完毕后,返回的值绑定到result[key]上。
while循环会不断创建averager实例,处理更多的值。
8、main函数是客户端代码,用PE380的术语来说,是“调用方”,是驱动一切的函数。
9、group 是调用 grouper 函数得到的生成器对象,传给 grouper 函数的第一个参数是results,用于收集结果;第二个参数是某个键。group 作为协程使用。
10、预激 group 协程。
11、把各个 value 传给 grouper。传入的值最终到达 averager 函数中 term = yield 那一行;grouper 永远不知道传入的值是什么。
12、把 None 传入 grouper,导致当前的 averager 实例终止,也让 grouper 继续运行,再创建一个 averager 实例,处理下一组值。
注释——“重要!”,强调这行代码(group.send(None))至关重要:终止当前的 averager 实例,开始执行下一个。
如果注释掉那一行,这个脚本不会输出任何报告。此时,把 main 函数靠近末尾的print(results) 那行的注释去掉,你会发现,results 字典是空的。
下图将示例中各个相关的部分标识出来了:
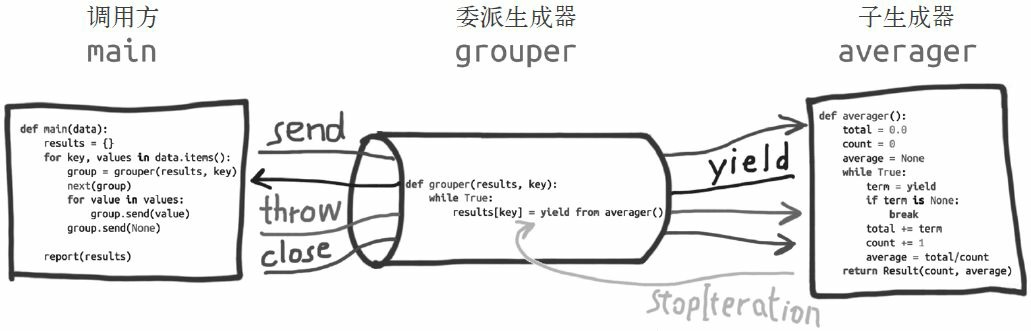
委派生成器在 yield from 表达式处暂停时,调用方可以直接把数据发给子生成器,子生成器再把产出的值发给调用方。
子生成器返回之后,解释器会抛出StopIteration 异常,并把返回值附加到异常对象上,此时委派生成器会恢复
下面简要说明示例的运作方式,还会说明把 main 函数中调用 group.send(None)那一行代码(带有“重要!”注释的那一行)去掉会发生什么事。
1、外层 for 循环每次迭代会新建一个 grouper 实例,赋值给 group 变量;group 是委派生成器。
2、调用 next(group),预激委派生成器 grouper,此时进入 while True 循环,调用子生成器 averager 后,在 yield from 表达式处暂停。
3、内层 for 循环调用 group.send(value),直接把值传给子生成器 averager。同时,当前的 grouper 实例(group)在 yield from 表达式处暂停。
4、内层循环结束后,group 实例依旧在 yield from 表达式处暂停,因此,grouper函数定义体中为 results[key] 赋值的语句还没有执行。
5、如果外层 for 循环的末尾没有 group.send(None),那么 averager 子生成器永远不会终止,委派生成器 group 永远不会再次激活,因此永远不会为 results[key]赋值。
6、外层 for 循环重新迭代时会新建一个 grouper 实例,然后绑定到 group 变量上。前一个 grouper 实例(以及它创建的尚未终止的 averager 子生成器实例)被垃圾回收程序回收。
这个试验想表明的关键一点是,如果子生成器不终止,委派生成器会在yield from 表达式处永远暂停。如果是这样,程序不会向前执行,因为 yield from(与 yield 一样)把控制权转交给客户代码(即,委派生成器的调用方)了。显然,肯定有任务无法完成。
示例展示了 yield from 结构最简单的用法,只有一个委派生成器和一个子生成器。因为委派生成器相当于管道,所以可以把任意数量个委派生成器连接在一起:一个委派生成器使用 yield from 调用一个子生成器,而那个子生成器本身也是委派生成器,使用 yield from 调用另一个子生成器,以此类推。最终,这个链条要以一个只使用 yield表达式的简单生成器结束;不过,也能以任何可迭代的对象结束,如示例所示。
任何 yield from 链条都必须由客户驱动,在最外层委派生成器上调用 next(...) 函数或 .send(...) 方法。可以隐式调用,例如使用 for 循环。
下面综述 PEP 380 对 yield from 结构的正式说明。
九、yield from的意义
PEP380 草稿中有这样一段话:“把迭代器当作生成器使用,相当于把子生成器的定义体内联在 yield from 表达式中。此外,子生成器可以执行 return 语句,返回一个值,而返回的值会成为 yield from 表达式的值。”
PEP 380 中已经没有这段宽慰人心的话,因为没有涵盖所有极端情况。
批准后的 PEP 380 在“Proposal”一节(https://www.python.org/dev/peps/pep-0380/#proposal)分六点说明了 yield from 的行为。这里,我几乎原封不动地引述,不过把有歧义的“迭代器”一词都换成了“子生成器”,还做了进一步说明。上一节的示例阐明了下述四点。
1、子生成器产出的值都直接传给委派生成器的调用方(即客户端代码)。
2、使用 send() 方法发给委派生成器的值都直接传给子生成器。如果发送的值是None,那么会调用子生成器的 __next__() 方法。如果发送的值不是 None,那么会调用子生成器的 send() 方法。如果调用的方法抛出 StopIteration 异常,那么委派生成器恢复运行。任何其他异常都会向上冒泡,传给委派生成器。
3、生成器退出时,生成器(或子生成器)中的 return expr 表达式会触发StopIteration(expr) 异常抛出。
4、yield from 表达式的值是子生成器终止时传给 StopIteration 异常的第一个参数。
yield from的另外两个特性与异常和终止有关:
1、传入委派生成器的异常,除了 GeneratorExit 之外都传给子生成器的 throw() 方法。如果调用 throw() 方法时抛出 StopIteration 异常,委派生成器恢复运行。StopIteration 之外的异常会向上冒泡,传给委派生成器。
2、如果把 GeneratorExit 异常传入委派生成器,或者在委派生成器上调用 close() 方法,那么在子生成器上调用 close() 方法,如果它有的话。如果调用 close() 方法导致异常抛出,那么异常会向上冒泡,传给委派生成器;否则,委派生成器抛出GeneratorExit 异常。
yield from 的具体语义很难理解,尤其是处理异常的那两点。若想仔细研究,最好将其简化,只涵盖 yield from 最基本且最常见的用法。
假设 yield from 出现在委派生成器中。客户端代码驱动着委派生成器,而委派生成器驱动着子生成器。那么,为了简化涉及到的逻辑,我们假设客户端没有在委派生成器上调用.throw(...) 或.close() 方法。此外,我们还假设子生成器不会抛出异常,而是一直运行到终止,让解释器抛出 StopIteration 异常。下面来看一下在这个简化的美满世界中,yield from 是如何运作的。
请看示例,那里列出的代码是委派生成器的定义体中下面这一行代码的扩充:
RESULT = yield from EXPR
示例:简化的伪代码,等效于委派生成器中的 RESULT = yield from EXPR语句(这里针对的是最简单的情况:不支持 .throw(...) 和 .close() 方法,而且只处理 StopIteration 异常)
_i = iter(EXPR) #1 try: _y = next(_i) #2 except StopIteration as _e: _r = _e.value #3 else: while 1: #4 _s = yield _y #5 try: _y = _i.send(_s) #6 except StopIteration as _e: #7 _r = _e.value break RESULT = _r
1、EXPR可以是任何可迭代的对象,因为获取迭代器_i(这是子生成器)使用的是iter()函数;
2、预激子生成器,结果保存在_y中,作为产出的第一个值;
3、如果抛出StopIteration异常,获取异常对象的value属性,赋值给_r——这是最简单情况下的返回值(RESULT)
4、运行这个循环时,委派生成器会阻塞,只作为调用方和子生成器之间的通道;
5、产出子生成器当前产出的元素;等待调用方发送_s中保存的值。注意,这个代码清单中只有这一个yield表达式;
6、尝试让子生成器向前执行,转发调用方发送的_s;
7、如果子生成器抛出StopIteration异常,获取value属性的值,赋值给_r,然后退出循环,让委派生成器恢复运行;
8、返回的结果是(RESULT)是_r,即整个yield from表达式的值。
在这段简化的伪代码中,我保留了 PEP 380 中那段伪代码使用的变量名称。这些变量是:
_i(迭代器)
子生成器
_y(产出的值)
子生成器产出的值
_r(结果)
最终的结果(即子生成器运行结束后 yield from 表达式的值)
_s(发送的值)
调用方发给委派生成器的值,这个值会转发给子生成器
_e(异常)
异常对象(在这段简化的伪代码中始终是 StopIteration 实例)
除了没有处理 .throw(...) 和 .close() 方法之外,这段简化的伪代码还在子生成器上调用 .send(...) 方法,以此达到客户调用next() 函数或 .send(...) 方法的目的。首次阅读时不要担心这些细微的差别。前面说过,即使 yield from 结构只做上一节示例展示的事情,也依旧能正常运行。
但是,现实情况要复杂一些,因为要处理客户对 .throw(...) 和 .close() 方法的调用,而这两个方法执行的操作必须传入子生成器。此外,子生成器可能只是纯粹的迭代器,不支持 .throw(...) 和 .close() 方法,因此 yield from 结构的逻辑必须处理这种情况。如果子生成器实现了这两个方法,而在子生成器内部,这两个方法都会触发异常抛出,这种情况也必须由 yield from 机制处理。调用方可能会无缘无故地让子生成器自己抛出异常,实现 yield from 结构时也必须处理这种情况。最后,为了优化,如果调用方调用 next(...) 函数或 .send(None) 方法,都要转交职责,在子生成器上调用next(...) 函数;仅当调用方发送的值不是 None 时,才使用子生成器的 .send(...) 方法。
为了方便对比,下面列出 PEP 380 中扩充 yield from 表达式的完整伪代码,而且加上了带标号的注解。下面示例中的代码是一字不差复制过来的,只有标注是我自己加的。
再次说明,示例中的代码是委派生成器的定义体中下面这一个语句的扩充:
RESULT = yield from EXPR
示例 :伪代码,等效于委派生成器中的 RESULT = yield from EXPR 语句
_i = iter(EXPR) #1 try: _y = next(_i) #2 except StopIteration as _e: _r = _e.value #3 else: while 1: #4 try: _s = yield _y #5 except GeneratorExit as _e: #6 try: _m = _i.close except AttributeError: pass else: _m() raise _e except BaseException as _e: #7 _x = sys.exc_info() try: _m = _i.throw except AttributeError: raise _e else: #8 try: _y = _m(*_x) except StopIteration as _e: _r = _e.value break else: #9 try: #10 if _s is None: #11 _y = next(_i) else: _y = _i.send(_s) except StopIteration as _e: #12 _r = _e.value break RESULT = _r #13
1、 EXPR 可以是任何可迭代的对象,因为获取迭代器 _i(这是子生成器)使用的是iter() 函数。
2、预激子生成器;结果保存在 _y 中,作为产出的第一个值。
3、如果抛出 StopIteration 异常,获取异常对象的 value 属性,赋值给 _r——这是最简单情况下的返回值(RESULT)。
4、运行这个循环时,委派生成器会阻塞,只作为调用方和子生成器之间的通道。
5、产出子生成器当前产出的元素;等待调用方发送 _s 中保存的值。这个代码清单中只有这一个 yield 表达式。
6、这一部分用于关闭委派生成器和子生成器。因为子生成器可以是任何可迭代的对象,所以可能没有 close 方法。
7、这一部分处理调用方通过 .throw(...) 方法传入的异常。同样,子生成器可以是迭代器,从而没有 throw 方法可调用——这种情况会导致委派生成器抛出异常。
8、如果子生成器有 throw 方法,调用它并传入调用方发来的异常。子生成器可能会处理传入的异常(然后继续循环);可能抛出 StopIteration 异常(从中获取结果,赋值给_r,循环结束);还可能不处理,而是抛出相同的或不同的异常,向上冒泡,传给委派生成器。
9、如果产出值时没有异常……
10、尝试让子生成器向前执行……
11、如果调用方最后发送的值是 None,在子生成器上调用 next 函数,否则调用 send 方法。
12、如果子生成器抛出 StopIteration 异常,获取 value 属性的值,赋值给 _r,然后退出循环,让委派生成器恢复运行。
13、返回的结果(RESULT)是 _r,即整个 yield from 表达式的值。
这段 yield from 伪代码的大多数逻辑通过六个 try/except 块实现,而且嵌套了四层,因此有点难以阅读。此外,用到的其他流程控制关键字有一个 while、一个 if 和一个yield。找到 while 循环、yield 表达式以及 next(...) 函数和 .send(...) 方法调用,这些代码有助于对 yield from 结构的运作方式有个整体的了解。
就在示例所列伪代码的顶部,有行代码(标号❷)揭示了一个重要的细节:要预激子生成器。 这表明,用于自动预激的装饰器与 yield from 结构不兼容。
仔细研究扩充的伪代码可能没什么用——这与你的学习方式有关。显然,分析真正使用yield from 结构的代码要比深入研究实现这一结构的伪代码更有好处。不过,我见过的yield from 示例几乎都使用 asyncio 模块做异步编程,因此要有有效的事件循环才能运行。
下面分析一个使用协程的经典案例:仿真编程。这个案例没有展示 yield from 结构的用法,但是揭示了如何使用协程在单个线程中管理并发活动。
十、使用案例:使用协程做离散事件仿真
协程是 asyncio 包的基础构建。通过仿真系统能说明如何使用协程代替线程实现并发的活动,而且对理解asyncio 包有极大的帮助。
1、离散事件仿真简介
离散事件仿真(Discrete Event Simulation,DES)是一种把系统建模成一系列事件的仿真类型。在离散事件仿真中,仿真“钟”向前推进的量不是固定的,而是直接推进到下一个事件模型的模拟时间。假如我们抽象模拟出租车的运营过程,其中一个事件是乘客上车,下一个事件则是乘客下车。不管乘客坐了 5 分钟还是 50 分钟,一旦乘客下车,仿真钟就会更新,指向此次运营的结束时间。使用离散事件仿真可以在不到一秒钟的时间内模拟一年的出租车运营过程。这与连续仿真不同,连续仿真的仿真钟以固定的量(通常很小)不断向前推进。
显然,回合制游戏就是离散事件仿真的例子:游戏的状态只在玩家操作时变化,而且一旦玩家决定下一步怎么走了,仿真钟就会冻结。而实时游戏则是连续仿真,仿真钟一直在运行,游戏的状态在一秒钟之内更新很多次,因此反应慢的玩家特别吃亏。这两种仿真类型都能使用多线程或在单个线程中使用面向事件的编程技术(例如事件循环驱动的回调或协程)实现。可以说,为了实现连续仿真,在多个线程中处理实时并行的操作更自然。而协程恰好为实现离散事件仿真提供了合理的抽象。
在仿真领域,进程这个术语指代模型中某个实体的活动,与操作系统中的进程无关。仿真系统中的一个进程可以使用操作系统中的一个进程实现,但是通常会使用一个线程或一个协程实现。
2、出租车队运营仿真
仿真程序 taxi_sim.py 会创建几辆出租车,每辆车会拉几个乘客,然后回家。出租车首先驶离车库,四处徘徊,寻找乘客;拉到乘客后,行程开始;乘客下车后,继续四处徘徊。四处徘徊和行程所用的时间使用指数分布生成。为了让显示的信息更加整洁,时间使用取整的分钟数,不过这个仿真程序也能使用浮点数表示耗时。 每辆出租车每次的状态变化都是一个事件。下图 是运行这个程序的输出示例。

图 1:运行 taxi_sim.py 创建 3 辆出租车的输出示例。-s 3 参数设置随机数生成器的种子,这样在调试和演示时可以重复运行程序,输出相同的结果。不同颜色的箭头表示不同出租车的行程.
图中最值得注意的一件事是,3 辆出租车的行程是交叉进行的。那些箭头是我加上的,为的是让你看清各辆出租车的行程:箭头从乘客上车时开始,到乘客下车后结束。有了箭头,能直观地看出如何使用协程管理并发的活动。
图中还有几件事值得注意。
1、出租车每隔 5 分钟从车库中出发。
2、0 号出租车 2 分钟后拉到乘客(time=2),1 号出租车 3 分钟后拉到乘客(time=8),2 号出租车 5 分钟后拉到乘客(time=15)。
3、0 号出租车拉了两个乘客(紫色箭头):第一个乘客从 time=2 时上车,到 time=18时下车;第二个乘客从 time=28 时上车,到 time=65 时下车——这是此次仿真中最长的行程。
4、1 号出租车拉了四个乘客(绿色箭头),在 time=110 时回家。
5、2 号出租车拉了六个乘客(红色箭头),在 time=109 时回家。这辆车最后一次行程从 time=97 时开始,只持续了一分钟。
6、1 号出租车的第一次行程从 time=8 时开始,在这个过程中 2 号出租车离开了车库(time=10),而且完成了两次行程(那两个短的红色箭头)。
7、在此次运行示例中,所有排定的事件都在默认的仿真时间内(180 分钟)完成;最后一次事件发生在 time=110 时。
本章只会列出taxi_sim.py中与协程相关的部分。真正重要的函数只有两个:taxi_process(一个协程),以及执行仿真主循环的 Simulator.run方法。
示例 16-20 是 taxi_process 函数的代码。这个协程用到了别处定义的两个对象:compute_delay 函数,返回单位为分钟的时间间隔;Event 类,一个namedtuple,定义方式如下:
Event = collections.namedtuple('Event', 'time proc action')
在 Event 实例中,time 字段是事件发生时的仿真时间,proc 字段是出租车进程实例的编号,action 字段是描述活动的字符串。
下面逐行分析示例 16-20 中的 taxi_process 函数。
示例 16-20 taxi_sim.py:taxi_process 协程,实现各辆出租车的活动
def taxi_process(ident, trips, start_time=0): #1 """每次改变状态时创建事件,把控制权让给仿真器""" time = yield Event(start_time, ident, 'leave garage') #2 for i in range(trips): #3 time = yield Event(time, ident, 'pick up passenger') #4 time = yield Event(time, ident, 'drop off passenger') #5 yield Event(time, ident, 'going home') #6 # 出租车进程结束 #7
1、每辆出租车调用一次 taxi_process 函数,创建一个生成器对象,表示各辆出租车的运营过程。ident 是出租车的编号(如上述运行示例中的 0、1、2);trips 是出租车回家之前的行程数量;start_time 是出租车离开车库的时间。
2、产出的第一个 Event 是 'leave garage'。执行到这一行时,协程会暂停,让仿真主循环着手处理排定的下一个事件。需要重新激活这个进程时,主循环会发送(使用 send方法)当前的仿真时间,赋值给 time。
3、每次行程都会执行一遍这个代码块。
4、产出一个 Event 实例,表示拉到乘客了。协程在这里暂停。需要重新激活这个协程时,主循环会发送(使用 send 方法)当前的时间。
5、产出一个 Event 实例,表示乘客下车了。协程在这里暂停,等待主循环发送时间,然后重新激活。
6、指定的行程数量完成后,for 循环结束,最后产出 'going home' 事件。此时,协程最后一次暂停。仿真主循环发送时间后,协程重新激活;不过,这里没有把产出的值赋值给变量,因为用不到了。
7、协程执行到最后时,生成器对象抛出 StopIteration 异常。
为了实例化 Simulator 类,taxi_sim.py 脚本的 main 函数构建了一个 taxis 字典,如下所示:
taxis = {i: taxi_process(i, (i + 1) * 2, i * DEPARTURE_INTERVAL)
for i in range(num_taxis)}
sim = Simulator(taxis)
DEPARTURE_INTERVAL 的值是 5;如果 num_taxis 的值与前面的运行示例一样也是 3,这三行代码的作用与下述代码一样:
taxis = {0: taxi_process(ident=0, trips=2, start_time=0),
1: taxi_process(ident=1, trips=4, start_time=5),
2: taxi_process(ident=2, trips=6, start_time=10)}
sim = Simulator(taxis)
因此,taxis 字典的值是三个参数不同的生成器对象。例如,1 号出租车从start_time=5 时开始,寻找四个乘客。构建 Simulator 实例只需这个字典参数。Simulator.__init__ 方法如示例 16-22 所示。Simulator 类的主要数据结构如下。
self.events
PriorityQueue 对象,保存 Event 实例。元素可以放进(使用 put 方法)PriorityQueue 对象中,然后按 item[0](即 Event 对象的 time 属性)依序取出(使用 get 方法)。
self.procs
一个字典,把出租车的编号映射到仿真过程中激活的进程(表示出租车的生成器对象)。这个属性会绑定前面所示的 taxis 字典副本。
示例 16-22 taxi_sim.py:Simulator 类的初始化方法
class Simulator: def __init__(self, procs_map): self.events = queue.PriorityQueue() #1 self.procs = dict(procs_map) #2
1、保存排定事件的 PriorityQueue 对象,按时间正向排序。
2、获取的 procs_map 参数是一个字典(或其他映射),可是又从中构建一个字典,创建本地副本,因为在仿真过程中,出租车回家后会从 self.procs 属性中移除,而我们不想修改用户传入的对象。
优先队列是离散事件仿真系统的基础构件:创建事件的顺序不定,放入这种队列之后,可以按照各个事件排定的时间顺序取出。例如,可能会把下面两个事件放入优先队列:
Event(time=14, proc=0, action='pick up passenger') Event(time=11, proc=1, action='pick up passenger')
这两个事件的意思是,0 号出租车 14 分钟后拉到第一个乘客,而 1 号出租车(time=10时出发)1 分钟后(time=11)拉到乘客。如果这两个事件在队列中,主循环从优先队列中获取的第一个事件将是 Event(time=11, proc=1, action='pick uppassenger')。
下面分析这个仿真系统的主算法——Simulator.run 方法。在 main 函数中,实例化Simulator 类之后立即就调用了这个方法,如下所示:
sim = Simulator(taxis)
sim.run(end_time)
Simulator 类带有注解的代码清单在示例 16-23 中,下面先概述 Simulator.run 方法实现的算法。
(1) 迭代表示各辆出租车的进程。
a. 在各辆出租车上调用 next() 函数,预激协程。这样会产出各辆出租车的第一个事件。
b. 把各个事件放入 Simulator 类的 self.events 属性(队列)中。
(2) 满足 sim_time < end_time 条件时,运行仿真系统的主循环。
a. 检查 self.events 属性是否为空;如果为空,跳出循环。
b. 从 self.events 中获取当前事件(current_event),即 PriorityQueue 对象中时间值最小的 Event 对象。
c. 显示获取的 Event 对象。
d.获取 current_event 的 time 属性,更新仿真时间。
e.把时间发给 current_event 的 proc 属性标识的协程,产出下一个事件(next_event)。
f.把 next_event 添加到 self.events 队列中,排定 next_event。
示例 16-23 taxi_sim.py:Simulator,一个简单的离散事件仿真类;关注的重点是run 方法
# -*- coding: utf-8 -*- import collections, queue, time, random NUM_TAXIS = 3 DEFAULT_END_TIME = 180 SEARCH_DURATION = 5 TRIP_DURATION = 20 DEPARTURE_INTERVAL = 5 Event = collections.namedtuple('Event', ['time', 'proc', 'action']) def taxi_process(ident, trips, start_time=0): #1 """每次改变状态时创建事件,把控制权让给仿真器""" time = yield Event(start_time, ident, 'leave garage') #2 for i in range(trips): #3 time = yield Event(time, ident, 'pick up passenger') #4 time = yield Event(time, ident, 'drop off passenger') #5 yield Event(time, ident, 'going home') #6 # 出租车进程结束 #7 taxis = {i: taxi_process(i, (i + 1) * 2, i * DEPARTURE_INTERVAL) for i in range(NUM_TAXIS)} class Simulator(object): def __init__(self, procs_map): self.events = queue.PriorityQueue() self.procs = dict(procs_map) def run(self, end_time): #1 """排定并显示事件,直到时间结束""" # 排定各辆出租车的第一个事件 for _, proc in sorted(self.procs.items()): #2 first_event = next(proc) #3 self.events.put(first_event) #4 # 这个仿真系统的主循环 sim_time = 0 #5 while sim_time < DEFAULT_END_TIME: #6 if self.events.empty(): #7 print('*** end of events ***') break current_event = self.events.get() #8 在self.events中取出event后,该event就会从queue中删除 sim_time, proc_id, previous_action = current_event #9 print('taxi: ', proc_id, proc_id * ' ', current_event) #10 active_proc = self.procs[proc_id] #11 next_time = sim_time + compute_duration(previous_action) #12 try: next_event = active_proc.send(next_time) #13 except StopIteration: del self.procs[proc_id] #14 else: self.events.put(next_event) #15 else: msg = '*** end of simulation time: {} events pending ***' print(msg.format(self.event.qsize())) def compute_duration(previous_action): """使用指数分布计算操作的耗时""" if previous_action in ['leave garage', 'drop off passenger']: # 新状态是四处徘徊 interval = SEARCH_DURATION elif previous_action == 'pick up passenger': # 新状态是行程开始 interval = TRIP_DURATION elif previous_action == 'going home': interval = 1 else: raise ValueError('Unknown previous_action: %s' % previous_action) return int(random.expovariate(1 / interval)) + 1 sim = Simulator(taxis) sim.run(DEFAULT_END_TIME)
1、run 方法只需要仿真结束时间(end_time)这一个参数。
2、使用 sorted 函数获取 self.procs 中按键排序的元素;用不到键,因此赋值给 _。
3、 调用 next(proc) 预激各个协程,向前执行到第一个 yield 表达式,做好接收数据的准备。产出一个 Event 对象。
4、 把各个事件添加到 self.events 属性表示的 PriorityQueue 对象中。如示例16-20中的运行示例,各辆出租车的第一个事件是 'leave garage'。
5、 把 sim_time 变量(仿真钟)归零。
6、这个仿真系统的主循环:sim_time 小于 end_time 时运行。
7、如果队列中没有未完成的事件,退出主循环。
8、 获取优先队列中 time 属性最小的 Event 对象;这是当前事件(current_event)。
9、拆包 Event 对象中的数据。这一行代码会更新仿真钟 sim_time,对应于事件发生时的时间。
10、显示 Event 对象,指明是哪辆出租车,并根据出租车的编号缩进。
11、从 self.procs 字典中获取表示当前活动的出租车的协程。
12、调用 compute_duration(...) 函数,传入前一个动作(例如,'pick uppassenger'、'drop off passenger' 等),把结果加到 sim_time 上,计算出下一次活动的时间。
13、把计算得到的时间发给出租车协程。协程会产出下一个事件(next_event),或者抛出 StopIteration 异常(完成时)。
14、如果抛出了 StopIteration 异常,从 self.procs 字典中删除那个协程。
15、 否则,把 next_event 放入队列中。
16、如果循环由于仿真时间到了而退出,显示待完成的事件数量(有时可能碰巧是零)。
注意,示例 16-23 中的 Simulator.run 方法有两处用到了第 15 章介绍的 else 块,而且都不在 if 语句中。
1、主 while 循环有一个 else 语句,报告仿真系统由于到达结束时间而结束,而不是由于没有事件要处理而结束。
2、靠近主 while 循环底部那个 try 语句把 next_time 发给当前的出租车进程,尝试获取下一个事件(next_event),如果成功,执行 else 块,把 next_event 放入self.events 队列中。
我觉得,如果没有这两个 else 块,Simulator.run 方法的代码会有点难以阅读。
这个示例的要旨是说明如何在一个主循环中处理事件,以及如何通过发送数据驱动协程。这是 asyncio 包底层的基本思想。














 3027
3027











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









