






昨天研究了网站的注册流程,感兴趣的可以看下:从前后端分别学习——注册/登录流程1
今天接着研究注册/登录流程之登录。
登录
首先来看一下登陆过程:

登录逻辑和注册逻辑基本一致,但登录的过程只对数据库进行读,比对用户的信息是否存在。
登录页面的 HTML 和 CSS 基本一致,这里就不放上来了。
注册成功后跳转
当用户注册成功后,会跳转到登录页面,进入登录页面,发送GET请求,所以需要做一个路由,代码和之前一样,不熟悉的可以看上面该出的链接,这里就不放上来了。
当我检测到服务器成功返回的状态码时,操作页面跳转至登录页面
window.location.herf = '/sign_in'
当用户输入用户名和密码后,点击登录按钮,会发送POST请求,服务器收到请求后,解析前端传过来的数据,并读取数据库将二者的信息进行比对,如果一致就说明是本人。和之前相同的地方,这边就省略了。
let usersString = fs.readFileSync('./db/db','utf8')
let usersArr = JSON.parse(usersString)
let foundUser = false
for(let i = 0; i < usersArr.length; i++){
if(usersArr[i].email === email && usersArr[i].password === password){
foundUser = true
break
}
}
if(foundUser){
response.statusCode = 200
response.write(`{
"successes":{
"success":"success"
}
}`)
}else{
response.statusCode = 400
response.write(`{
"errors":{
"email":"foundUser"
}
}`)
}
如果对比成功,说明该用户已注册过;如果对比失败,返回对应的响应数据,让前端提示用户。
至此登录流程做完,是不是觉得很简单,在弄懂注册流程后,登录流程基本和它基本一致。
Cookie
登录流程虽然简单,这不是我们今天要研究的重点。
既然网站服务商需要用户祖册,那肯定注册用户和非注册用户能访问的页面肯定不一样,那网站服务商怎么区分注册用户和非注册用户呢?
对,就是Cookie,当用户登录成功后,浏览器会向用户发送一个 Cookie,用户下次请求时会带上Cookie,后端都能匹配上Cookie,就说明他是我们的注册用户,可以访问这个页面;如果Cookie匹配不上,当然就禁止访问了,Cookie具体的参数下一篇讨论,这里先上手直接使用一下,看看效果。
登录成功后跳转页面
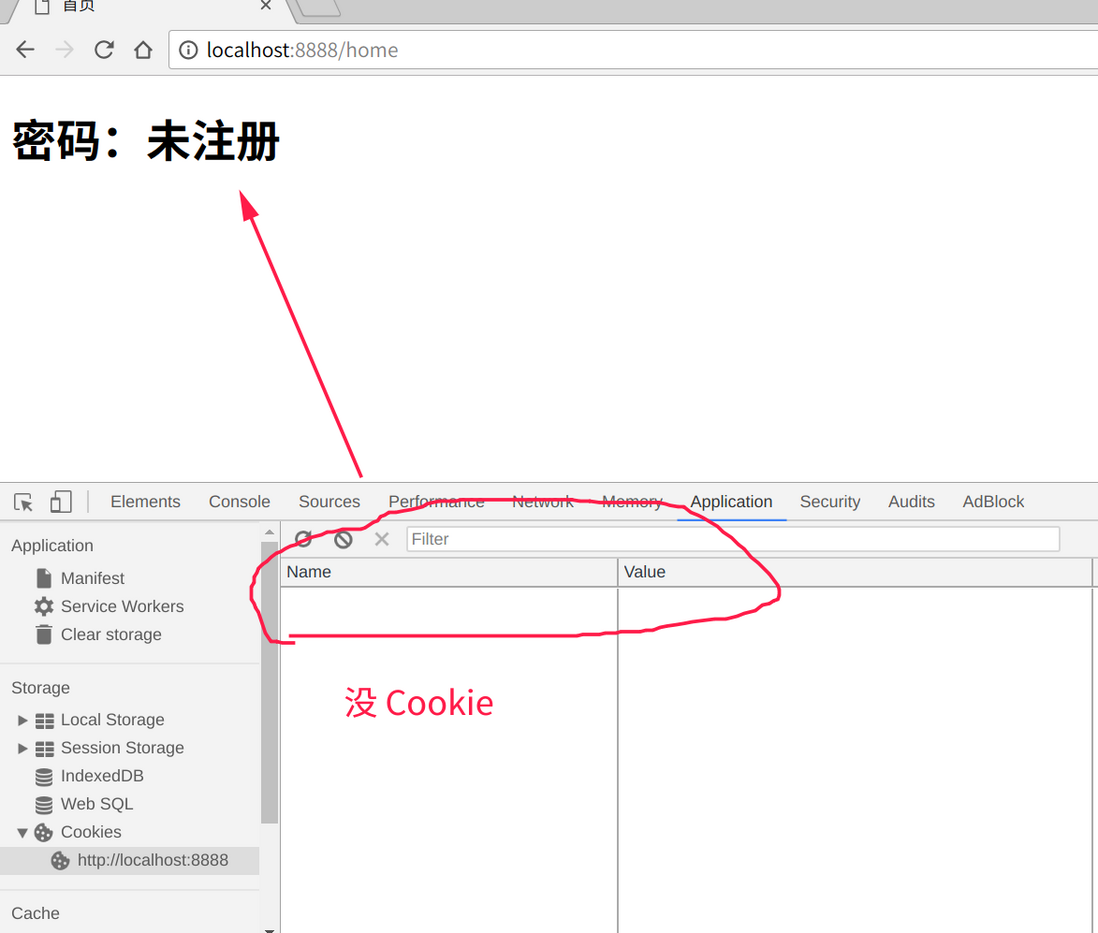
当用户登录成功后,让他跳转至首页,首页上显示用户的密码,当然实际工作中不能这样用,这里显示密码以示区分注册用和非注册用户。
密码:__password__
首页非常简单,__password__处只是占位符,如果是注册用户这里会显示对应的密码。
在登录成功后,服务器要给用户发放一个Cookie,这里现已用户的邮箱作为Cookie。
response.setHeader('Set-Cookie',`sign_in_email=${email}`)
设置了Cookie之后,可看到响应头中有了Set-Cookie
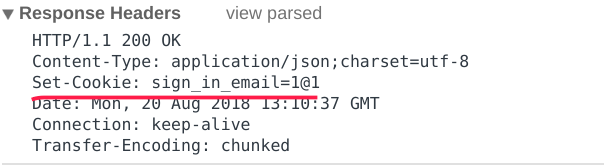
当跳转首页时,会带上这个Cookie。
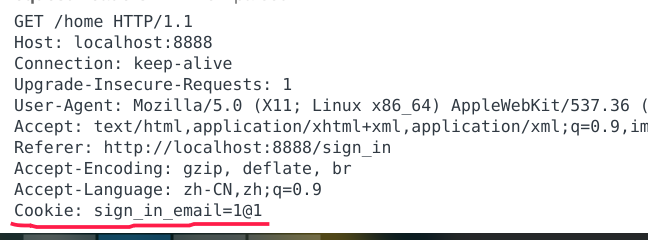
后端继续做一个路由,当登录首页时,判断用户是否是注册用户,只需要看它的Cookie
读取Cookie
读取Cookie时要注意两点:
多Cookie是以"; "间隔,分号后面有空格
如非注册用户访问,没Cookie会报错,初始化时要赋值一个空数组。
if(path === '/home'){
let string = fs.readFileSync('./home.html','utf8')
response.setHeader('Content-Type','text/html;charset=utf-8')
let cookieArr = [] //初始化为空数组
if(request.headers.cookie){
cookieArr = request.headers.cookie.split('; ')
}
let cookieHashes = {} //拆分成需要的格式
cookieArr.forEach((e)=>{
let part =e.split('=')
cookieHashes[part[0]] = part[1]
})
response.write(string)
response.end()
}
验证Cookie
服务器发放的Cookie是用户的邮箱,所以这边就比对数据库里的邮箱,如果匹配上,说明是注册用户
let {sign_in_email} = cookieHashes
let usersString = fs.readFileSync('./db/db','utf8')
let usersArr = JSON.parse(usersString)
let foundUser
for(let i = 0; i < usersArr.length; i++){
if(usersArr[i].email === sign_in_email){ // 验证 Cookie
foundUser = usersArr[i]
break
}
}
权限分配
验证成功,给予访问;验证失败,不给访问。
if(foundUser){
response.statusCode = 200
string = string.replace('__password__',foundUser.password)
}else{
response.statusCode = 400
string = string.replace('__password__','未注册')
}
验证成功
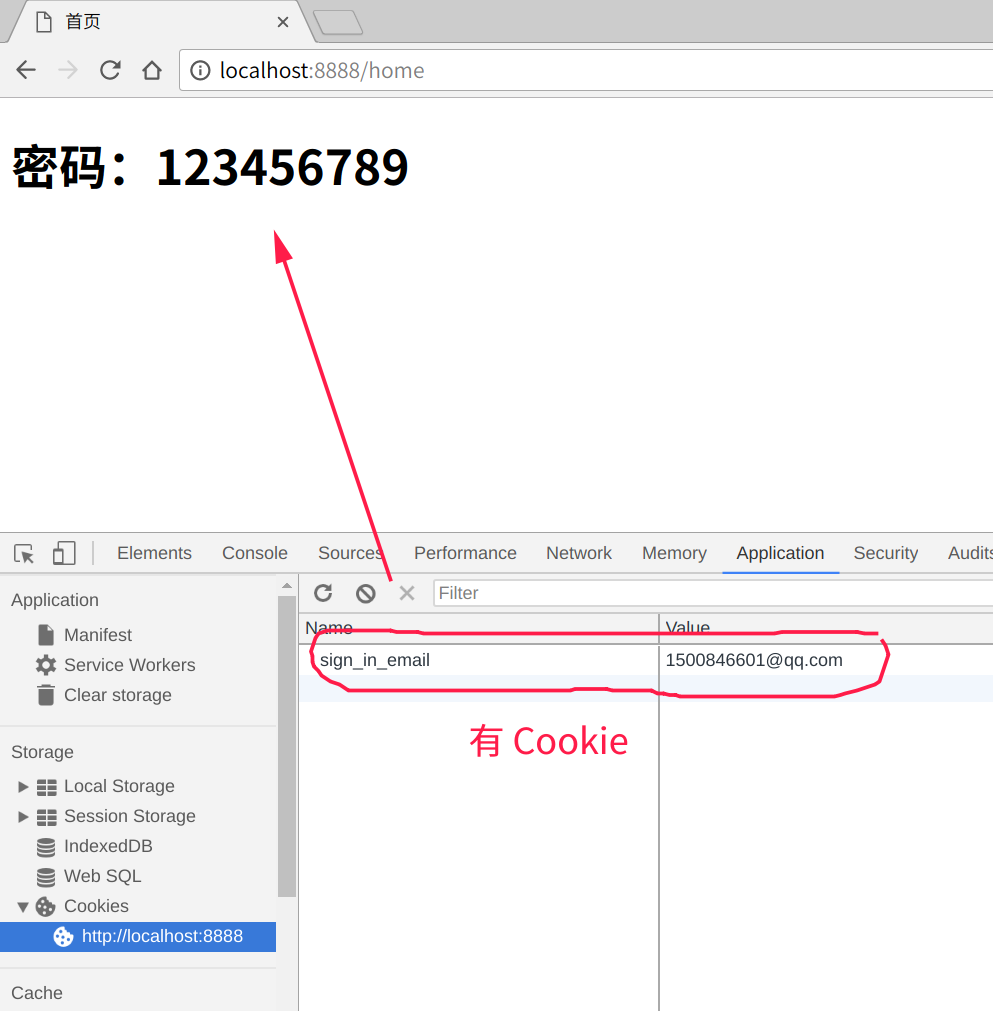
验证失败
Session
用Cookie有个很大的问题:用户可以随意更改,如果有人知道了Cookie的规律,那他就可以随意获取用户信息了。
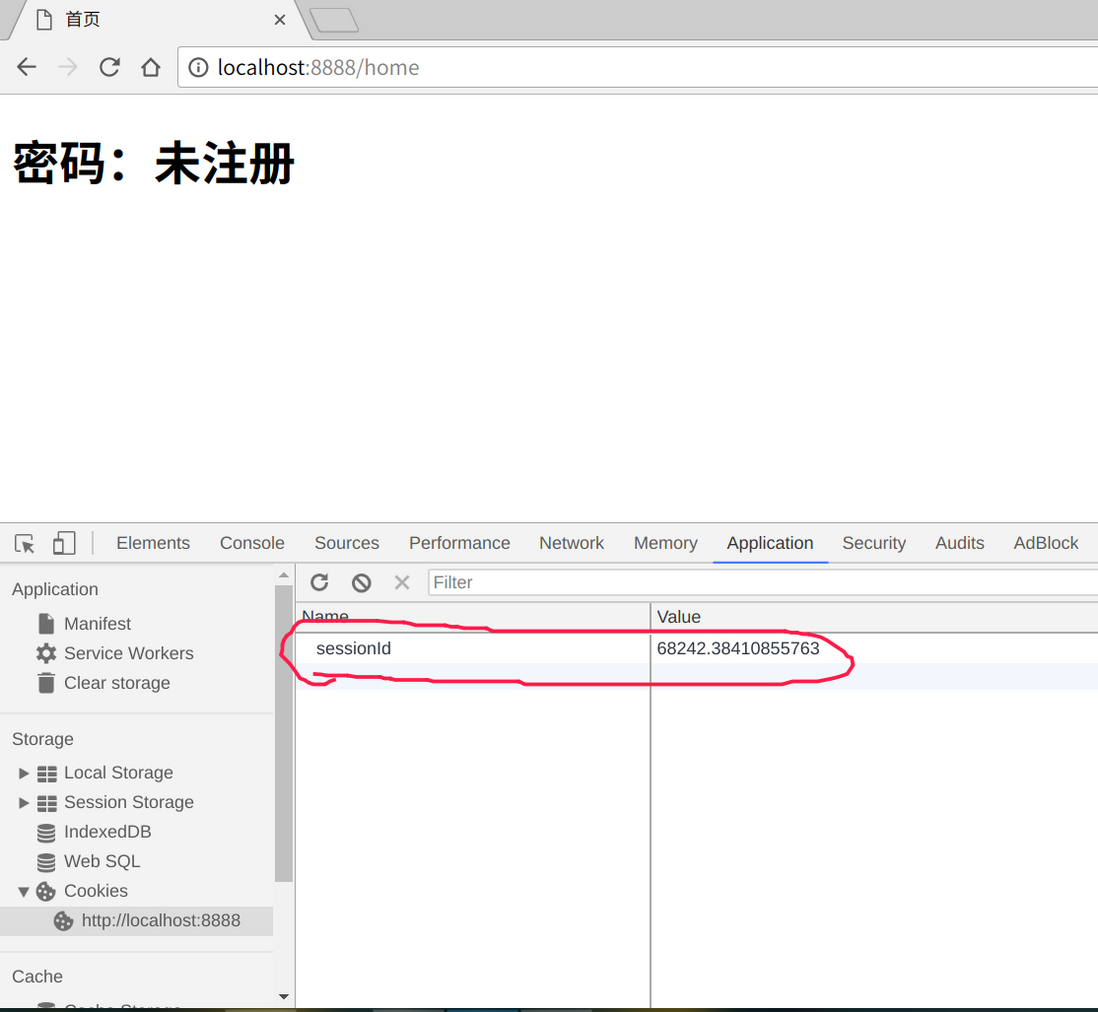
为解决这个问题,引入Session,它是由一组随机数组合的哈希表,当用户登录成功,本来发放Cookie给用户,现在变成发放Session给用户。
具体看下怎么实现呢
var sessions = {}
sessions[sessionId] = {sign_in_email:email}
response.setHeader('Set-Cookie',`sessionId=${sessionId}`)
之前发放的Cookie,现在变成了Session
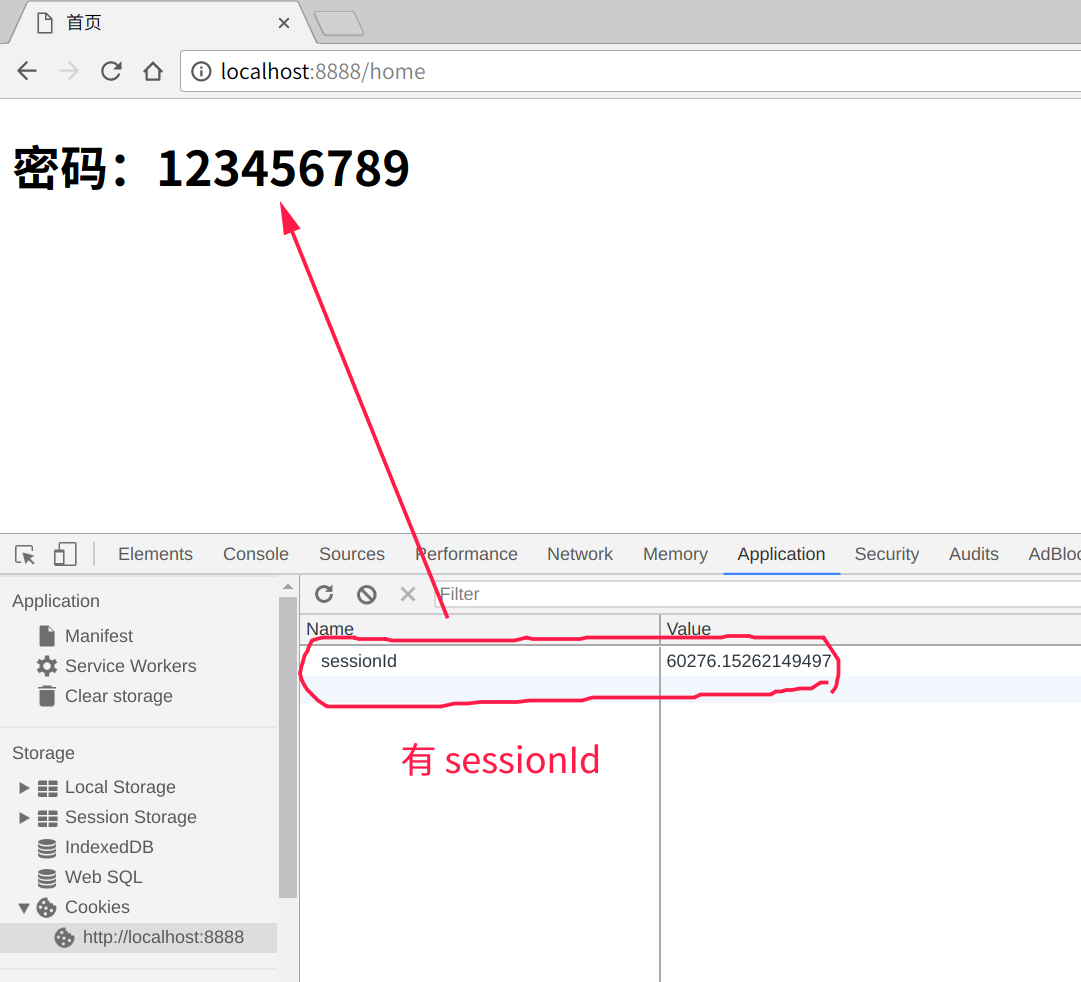
服务器不能在读Cookie了,也要变成读取Session,才能正常显示
let sessionsArr = []
if(request.headers.cookie){
sessionsArr = request.headers.cookie.split('; ')
}
let sessionHashes = {}
sessionsArr.forEach((e)=>{
let part =e.split('=')
sessionHashes[part[0]] = part[1]
})
//通过读取用户的 sessionId 比对 session 表中的 email
let sign_in_email
if(sessionHashes.sessionId){
sign_in_email = sessions[sessionHashes.sessionId].sign_in_email
}
上面代码都一样,这里换了个变量而已,只有最后一句不一样,如果sessionId存在才能找到session表中的用户邮箱。
总结

经过两天研究注册和登录流程,弄清楚了各个环节,详细的过程如上图所示,有2点需要了解:
Cookie不可靠,用户可随意更改
Session一般用随机数表示,增强了安全性,缺点太占内存
通过这次学习不仅对ajax、Promise等技术了解更深,也大致明白了后端的工作流程。














 148
148











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









