






搜索服务,已经成为了互联网最常用的基本服务: 从谷歌、百度搜索关键字,到电商平台搜索商品,再到微信查看附近的人。我们几乎每时每刻都在用到它。所以,搜索引擎技术一直为大家关注。作者本人曾负责一些大型的分布式搜索系统,本文从个人项目出发,讲讲基于 Lucene 的核心搜索引擎技术实践。希望让大家对搜索系统有进一步了解和启发。
之前,我曾分享过 Qunar 的机票搜索系统,一种基于航运业务的垂直搜索应用。今天聊到的 Lucene,是一种最常用的文本搜索引擎技术。
Lucene 介绍
Lucene是一个高性能、可伸缩的文本搜索引擎库,诞生于 2000 年。它可以为应用程序添加索引和搜索能力,是一个 Java 语言编写的开源项目,也是著名的 Apache Jakarta 大家庭的一员。目前国内的阿里、美团,国外的 Netflix、MySpace、LinkedIn、Twitter、IBM 都有基于Lucene 的搜索服务。Lucene 是非常经典的搜索引擎,基于 Lucene 上诞生了不少企业搜索平台,比如 Elastic Search、Solr、Index Tank。
Lucene 的特点:
Lucene可以支持多种数据来源建立索引库:支持 PDF、Word、txt 等常用文档,也可以支持数据库,搜索索引的大致流程如图:

Lucene作为搜索引擎,具备以下优势。
1)高性能
· 一小时可以索引 150GB 的数据
· 千万级增量索引能达到毫秒级
2)搜索高扩展性
· 可定制的排序模型
· 支持多种查询类型
· 通过特定的字段搜索、排序
· 通过特定的字段排序
· 近实时的索引和搜索
· Faceting,Grouping,Highlighting,Suggestions 等
3)对 LBS 服务更友好的支持
目前Lucene 最新版本已经到 6.X,它最重要的变化引用了一种新的重要数据结构,这种数据采用 K-D trees 存储方式,叫做 block K-D trees , 其针对于数值型和地理位置的新的数据结构。Lucene 低版本对 LBS、多维数值查询性能并不是很好。 6.X 在一些官方测评查询性能上升最少 30%,磁盘空间缩小 50%
KD-Tree本质上是一种二叉树,该算法将散布在空间中的点通过超平面切分在不同的空间中,在搜索的过程中,如果某个空间中最近的点离目标点距离超过目标距离的话,整个空间将会被抛弃。对于所有点与目标点的距离都小于目标距离的空间,算法将进行一次子空间遍历。
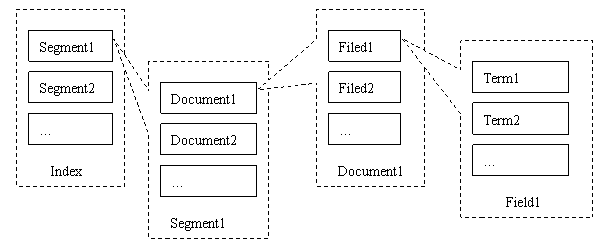
Lucene 的存储结构

如上图,Lucene 基本存储单元从上往下,分别有:
1. Index(索引):一般对应文件目录,包含了多个 Segment。可以理解为数据库中表。
2. Document(文档):文档是我们建索引的基本单位,可以理解为数据库表一条行数据。
3. Segment(段):不同的文档是保存在不同的段中的,一个段可以包含多篇文档。新添加的文档是单独保存在一个新生成的段中,随着段的合并,不同的文档合并到同一个段中。
从存储结构上看,在使用 Lucene 提供搜索服务时,业务场景需要考虑一些性能因素:
1. Lucene 有读写锁,能支持到类似 DB 的行锁粒度。
2. Lucene 的数据更新会写入索引文件,这会涉及磁盘的读写 IO。不过,Lucene 采用异步更新机制,同时优化了并发读写的问题。后面文中会提到。
3. 索引更新:索引有全量更新、增量更新两种,增量更新就是局部更新,如果数据量在百万量级以上,数据变化不多的场景下,尽量用增量更新。另外,索引的 Update 实际是先 Delete 指定记录,然后再把指定记录对应的新值 Add 到索引。
基于 Lucene 实现的企业搜索平台
鉴于Lucene 强大的特性和稳定性,有很多种基于 Lucene 封装的企业级搜索平台。其中最流行有两个:Apache Solr 和 Elastic search。
· Apache Solr:它本身是 Apache Lucene 项目下的开源企业搜索平台,算是 Lucene 的直系。美团、阿里搜索服务是基于 Solr 来搭建的。
· Elastic Search:简称 ES,由 Elastic 公司开发。Elastic成立于 2012 年,总部在阿姆斯特丹,不久前 Google 宣布与 Elastic 达成战略合作协议,为谷歌云提供新的搜索以及相关分析服务。 最近几年,ES变得越来越普及,StackOverflow、Github、百度等都在使用。
企业搜索都有些什么不同,解决了什么需求呢?综合 Solr 和 ES,我觉得主要有两点:
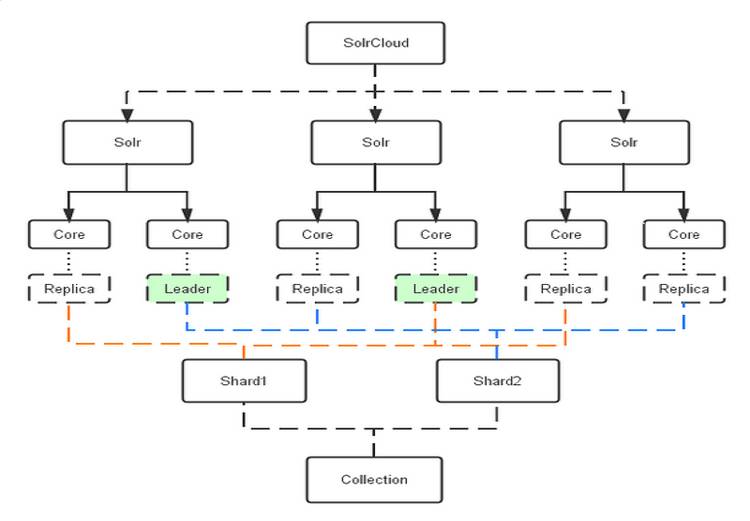
1. 高可用的分布式集群管理
Solr有 SolrCloud 来管理集群,它是基于ZooKeeper 来控制节点的负载均衡:

Solr控制节点的管理后台:

ES 集群管理是透明化,它基于 Cluster+Node+Shards(分片实现主从复制) 机制,自己实现节点管理。它的主从配置 Demo:
Master的配置 (elasticsearch.yml):
cluster.name: esappnode.name: esnode0node.master:truenode.data: truenetwork.host: 0.0.0.0
Slave的配置:
cluster.name: esappnode.name: esnode2node.master:falsenode.data: truenetwork.host: 0.0.0.0discovery.zen.ping.unicast.hosts:["esnode0"]
其中,network.host:0.0.0.0 代表了没有绑定具体的 ip,这样其他机器可以通过 9200 这个默认端口通过 http 方式访问查看服务。而 slave 中的 discovery.zen.ping.unicast.hosts 指定了 master 的地址。
2. 健全的管理平台和搜索 API
Solr、ES 都提供了基于 HTTP 的搜索管理平台,Solr 自带管理后台, ES 有独立数据视图产品,如下图:

此外,Solr和 ES 都提供方便的 REST API,以供各种客户端调用搜索服务,比如 Solr API:

搜索服务的高并发实例
因为ES 在 12 年后才出现,早年 Solr 在企业级搜索市场算是一枝独秀。我在阿里的时候,早期 Taobao SKU 搜索服务还是基于 Solr 实现,那时的 Solr 对百万量级 SKU 做全量更新就已经是毫秒级别。
在美团,我也采用 Solr 集群搭建团购 SKU 搜索系统。大体的架构实现:

美团团购搜索主要有:商品列表按价格、购买量、人气等各种排序;移动端有大量 LBS 服务,它比较耗性能;一些热词的关键字搜索。最早,美团采用 MongoDB 提供的搜索,当时考虑:
· MongoDB 存储是 JSON 数据,查询也方便。
· 它是基于平衡二叉树的内存索引,查询比较快,当时一台实例能撑到3000 的 QPS(里面有大概 30% 是 LBS 查询)。不过 MongoDB 现在已经采用了新的搜索引擎叫 WiredTiger,一种文档级锁的存储引擎取代过去内存存储引擎 MMAP。
· 友好支持基于 GEO Hash 算法的 LBS 搜索。这点满足我们的移动端的 LBS 服务,它还可以一个 SKU 有多个坐标(分店)的查询。而 Solr 当时只能支持一个 SKU 一个坐标关联,遇到多个分店要拆解成多个 Docs 记录放在索引库中。
后来我们发现 MongoDB 就越来越不适合我们的业务场景,也踩过来很多坑。
当时我们 SKU 有几十万量级,每个月 30% 增量。因为销量、价格是时常变动的。当时策略隔五分钟来一次全量更新,中间增量更新是实时的。
虽然商户数量基数不大,对于 MongoDB 这样的 NoSQL 来说数据量并不高。但是短短几个月,APP 用户量却从 0 开始陡增到千万量级。每天数百万的日活下,可想而知,高并发下的读写压力就上来了。之前说过 MongoDB 基于内存引擎,它的存储结构最大的问题是它的锁是库锁级别!对,是库锁。可以想象我们深入了解以后内心的尴尬。
因为锁的巨大瓶颈,MongoDB 不遗余力想解决锁粒度的问题。后来几个大的版本迭代很快,但针对这个问题,也只优化到表锁粒度。对同一个表并发读写还是很容易被锁住。搜索服务没秒承载上千的 QPS 查询时,我们全量索引一来,MongoDB 的服务就几乎变得不可用。
于是我们尝试做基于 MongoDB 的读写分离,结果发现它在做分布式集群时,写库同步数据到读库的时候,读库的请求也在队列堵塞!从 MongoDB 的控制台 Mongostat 你会看到一个实时的统计:qr|qw。qr 表示当前排在队列中的读请求数,qw 表示写。当写请求来时,qr 就会持续飙高,直到 MongoDB 服务挂掉。当全量索引一来,哪怕没有其他写,qw 为 1,读队列也是堵塞的。
考虑锁瓶颈的问题,MongoDB 尝试过优化版,关注早期 2.X~3.0 都在致力解决这块问题。可能后来基于内存这种方式很难根本解决锁问题,也不好做分布式方案,最后才有后来用 WiredTiger 的文件引擎作为缺省引擎,算是彻底放弃了内存引擎。
基于周期成本太高,我决定采用 Solr 取代了 Mongo,通过SolrCloud 技术,搭建了 Solr 分布式搜索集群。
SolrCloud大致原理:基于 ZooKeeper 管理节点、索引分片、节点做主从。

Solr单台实例只读的 QPS 不如 MongoDB,大概在 1500QPS。在 Solr4 版本LBS 搜索在 700~800 QPS。不过关键是,在并发读写时候,Solr 不存在并发读写锁的问题。不会出现卡顿。而且它的主从同步是毫秒级别。这些优点是基于它的 NRT(NearRealTime) 技术来实现的:

NRT:Near Real Time , Lucene 为了支持实时搜索,在 2.9 版本就已经设计出来。想更多了解可以看看 http://wiki.apache.org/lucene-java/NearRealtimeSearch它的原理记录在 LUCENE-1313 和 LUCENE-1516。介绍下代码实现的过程:
· 在 Index Writer 内部维护了一个 Ram Directory,在内存够用前,flush 和 merge 操作只是把数据更新到 Ram Directory,这个时候读写最新的索引都在内存中。只有 Index Writer 在 optimize 和 commit 操作会把 Ram Directory 上的数据完全同步到文件
· 当内存索引达到一个阀值时,程序主动执行 commit 操作时,内存索引中的数据异步写入硬盘。当数据已经全部写入硬盘之后,程序会对硬盘索引重读,形成新的 IndexReader,在新的硬盘 IndexReader 替换旧的硬盘 IndexReader 时,形成新的 IndexReader。后面再来的读请求交给新的 IndexReader 处理。
· 补充一下,在 1 过程中,变动的数据不是简单更新到 Old IndexReader 里面,它是暂存到一个新的 Reader.clone,在新的 IndexReader 生成前,读请求得到数据是 OldIndexReader+Reader.clone 它们 merge 的结果。
Lucene的 index 组织方式为一个 index 目录下的多个 segment。新的 doc 会加入新的 segment 里,这些新的小 segment 每隔一段时间就合并起来。因为合并,总的 segment 数量保持的较小,总体 search 速度仍然很快。为了防止读写冲突,lucene 只创建新的 segment,并在任何 active 的 reader 不在使用后删除掉老的 segment。
另外,解释下上面的几个专业词语。
· flush:把数据写入到操作系统的缓冲区,只要缓冲区不满,就不会有硬盘操作。
· commit:把所有内存缓冲区的数据写入到硬盘,是完全的硬盘操作。
· optimize:是对多个 segment 进行合并,这个过程涉及到老 segment 的重新读入和新 segment 的合并,这个过程是不定期。
同理Elastic Search 也支持 NRT,实例也做到了读写分离。
从MongoDB 迁移到 Solr 实践过程,在架构方面给我深刻的启发:
1. 架构的设计和选型花时间调研是必要的,不要太盲目的应用新技术,尤其是一些方案不完备的开源框架。看似跑个 Demo 很好,实际的坑还得填。
2. 新机会要掌握核心原理,掌握它合理的应用场景,MongoDB 也许只适合并发只读的搜索服务,比如很多公司用来搜索日志。
企业搜索高可用的优化
缓存调优
为了提高查询速度,Solr 和 ES 支持使用 Cache,还是以 Solr 为例:
Solr支持 queryResultCache,documentCache,filtercache 主要缓存结果集。其中 filtercache、queryResultCache 运用得好对性能会有明显提升。
filtercache:它存储了 filter queries(“fq”参数) 得到的 document id 集合结果,你可以理解查询语句中的过滤条件。比如:下面业务场景一组搜索条件:
q=status:0 AND biz_type:1 AND class_id:1 ANDgroup_id:3q=status:0 AND biz_type:1 AND class_id:1 AND group_id:4q=status:0 ANDbiz_type:1 AND class_id:1 AND group_id:5
可以看到 status、biz_type、class_id是固定查询条件,唯一动态变化的是 group_id。
因此,我们把整个查询条件可分成两部分:一部分是以 status,biz_type,class_id 这几个条件组成的子查询条件,另外一部分是除它们外的子查询。在进程查询的时候,先将 status,biz_type,class_id 条件组成的条件作为 key,对应的结果作为 value 进行缓存,然后和另外一部分查询的结果进行求交运算。
这样,减少了查询过程的 IO 操作。
queryResultCache:比较好理解,就是整个查询结果缓存。这个在一些业务场景:比如排行榜、美团 APP 缺省列表首页,推荐列表页,这些高频固定查询,可以直接有queryResultCache 返回结果。
这样,减少了查询次数和提高了响应时间。
一般搜索的 Cache 常基于 LRU 算法来调度。
分片 (Shard)
分片(Shard) 可以减低大数据量的索引库操作粒度,和数据库分库分表思想一致。
Solr的 DataBase 叫做 Core,ES 叫做 index,它们和Shard 是一对多的关系。根据数据量和访问 QPS,合理设置分片数量,以期望到达搜索节点最大并发数。
Elastic Search VS Solr 对比
数据源
Solr支持添加多种格式的索引,比如:HTML、PDF、微软 Office 系列软件格式以及 JSON、XML、CSV 等文件格式,还支持 DB数据源。而 Elastic Search 仅支持 JSON 数据源。
高并发的实时搜索
基于Solr 和 ES 都有成熟高可用架构设计。高并发的实时搜索两者都没有太大问题。但是 Elastic Search 读写并发性能更优于 Solr。
需要注意的是,搜索引擎不推荐像 DB 一样做类似 like 的通配符查询,这样会导致性大大降低。之前线上有一个 ES 搜索集群,一段时间 8 核CPU 的 load 飚到了 10 以上,后来排查,原来是用到了 wildcard query(通配符查询),出现了大量的慢查询,导致服务变得不可用。下面我具体介绍下。
当时的查询条件:
}},{"range":{"saleTime":{"from":"20170514000000000","to":"20170515000000000","include_lower":true,"include_upper":false}}},{"match":{"terminalNumber":{"query":"99996DEE5CB2","type":"boolean"}}}]}}}
监控每天 1min load、5 min load、15min load 统计情况:

非常明显看出来,当我们去掉通配符(改用普通全匹配查询)后,load 立马降下来。可见通配符查询都 CPU 性能影响很大。而且,如果首尾通配符中间输入的字符串越长。对应的 wildcard Query 执行更慢。性能越差。
这是什么原因呢?
在Lucene 4.0 开始,为了加速通配符和正则表达式的匹配速度,将输入的字符串模式构建成一个 DFA(Deterministic Finite Automaton),带有通配符的 pattern 构造出来的 DFA 可能会很复杂,开销很大。具体原理可以了解下 DFA。
wildcardquery 应杜绝使用通配符打头,改变实现方式:使用更廉价的 term query 来实现同等的模糊搜索功能。或者获取一个大的结果集,在内存里面匹配。
易用性:
Solr分布式基于 ZooKeeper,而 ES 自带分布式管理。两者在分布式管理和部署都比较成熟。
扩展性
Elastic公司除了开发 ES 以外, 还基于此,开发了 Kinbana(针对Elasticsearch 的开源分析及可视化平台,用来搜索、查看Elasticsearch 索引中的数据)、Logstash(开源的具有实时输入数据能力的数据收集引擎, 主要方便分布式系统收集汇总日志) 等一整套服务产品。
目前,Kinbana、Logstash 在很多公司被使用。基于 Elastic + LogStash +Kinbana 的 ELK 框架成为了一种流行的分布式日志收集监控技术方案。

Solr自带了管理索引的 Web 控制台,只专注在企业级搜索引擎。
搜索引擎拓展应用
推荐系统使用搜索
推荐系统往往利用搜索进行复杂的离线查询和数据过滤。早期,美团团购 App 做了一个每日推荐功能,主要基于用户购买记录,个性化每天推送相关团购。当时这样做的:
首先,数据组在每天的前一天算好用户推荐规则,固定早上一段时间,批量执行推荐规则和用户匹配操作,大体过程:

整个操作上午串行开始推送。我们是并发请求多台搜索服务器,得到推荐数据,并行开始多个用户的消息推送。大概在 9:00~12:00 APP 用户会收到一条团购推送(如上面截图)。当时,推荐功能通过搜索进行个性化推荐,因为匹配的好,下单重复转化率是不错的。
数据分析、BI 调用搜索服务
我们提到数据分析、BI,总是联想到大数据,但并不是每家公司的数据都有海量规模。
实际情况,往往一定数据规模下,为了更低、更高效满足数据分析业务场景,往往用搜索系统承担一部分数据集合存储、处理的功能(这样的比例不低)。这样的好处是:
1. 搜索系统查询太方便,对一些实时性,数据关联不大业务完全适用 。
2. 搜索系统也是一种稳定的数据源,它的数据持久化也是很稳定的。
比如之前我们数据部门就大量使用 ES 做一些负责的查询,帮忙他们做数据分析。
思考总结
搜索服务应用的领域太广泛,随着人工智能技术发展,个性化搜索服务越来越人性化。从近几年火热的内容、短视频个性推送,语音搜索。搜索技术还会有一个新的革新。
作者介绍
蒋志伟,前美团、Qunar 架构师,先后就职于阿里、Qunar、美团,精通在线旅游、O2O 等业务,擅长大型用户的 SOA 架构设计,在垂直搜索系统领域有丰富的经验,尤其在高并发线上系统方面有深入的理论和实践,曾在 pmcaff 担任 CTO。















 1315
1315

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言










{kind=link}
{kind=link}
{kind=link}