






Python简介
python是吉多·范罗苏姆发明的一种面向对象的脚本语言,可能有些人不知道面向对象和脚本具体是什么意思,但是对于一个初学者来说,现在并不需要明白。大家都知道,当下全栈工程师的概念很火,而Python是一种全栈的开发语言,所以你如果能学好Python,那么前端,后端,测试,大数据分析,爬虫等这些工作你都能胜任。
为什么选择Python
关于语言的选择,有各种各样的讨论,在这里我不多说,就引用Python里面的一个彩蛋来说明为什么要选择Python,在Python解释器里输入import this 就可以看到。
1 >>> import this 2 3 The Zen of Python by Tim Peters 4 5 Beautiful is better than ugly. 6 Explicit is better than implicit. 7 Simple is better than complex. 8 Complex is better than complicated. 9 Flat is better than nested. 10 Sparse is better than dense. 11 Readability counts. 12 Special cases aren't special enough to break the rules. 13 Although practicality beats purity. 14 Errors should never pass silently. 15 Unless explicitly silenced. 16 In the face of ambiguity, refuse the temptation to guess. 17 There should be one-- and preferably only one --obvious way to do it. 18 Although that way may not be obvious at first unless you're Dutch. 19 Now is better than never. 20 Although never is often better than *right* now. 21 If the implementation is hard to explain, it's a bad idea. 22 If the implementation is easy to explain, it may be a good idea. 23 Namespaces are one honking great idea -- let's do more of those!
上面的话简单的总结来说就是“优雅”、“明确”、“简单”,或许你还是有些不明白,举个简单的例子,若果同样的功能你用C/C++写可能要写100行代码,而如果用Python写你可能只要20行代码就搞定,同样的如果一个问题有好几种解决方案,但是Python会用一种最简单的方法来实现。所以Python是用最简单最优雅最明确的方法来解决问题。
Python 是一门什么样的语言?
编程语言主要从以下几个角度为进行分类,编译型和解释型、静态语言和动态语言、强类型定义语言和弱类型定义语言,每个分类代表什么意思呢,我们一起来看一下。
编译和解释的区别是什么?
编译器是把源程序的每一条语句都编译成机器语言,并保存成二进制文件,这样运行时计算机可以直接以机器语言来运行此程序,速度很快;
而解释器则是只在执行程序时,才一条一条的解释成机器语言给计算机来执行,所以运行速度是不如编译后的程序运行的快的.
这是因为计算机不能直接认识并执行我们写的语句,它只能认识机器语言(是二进制的形式)
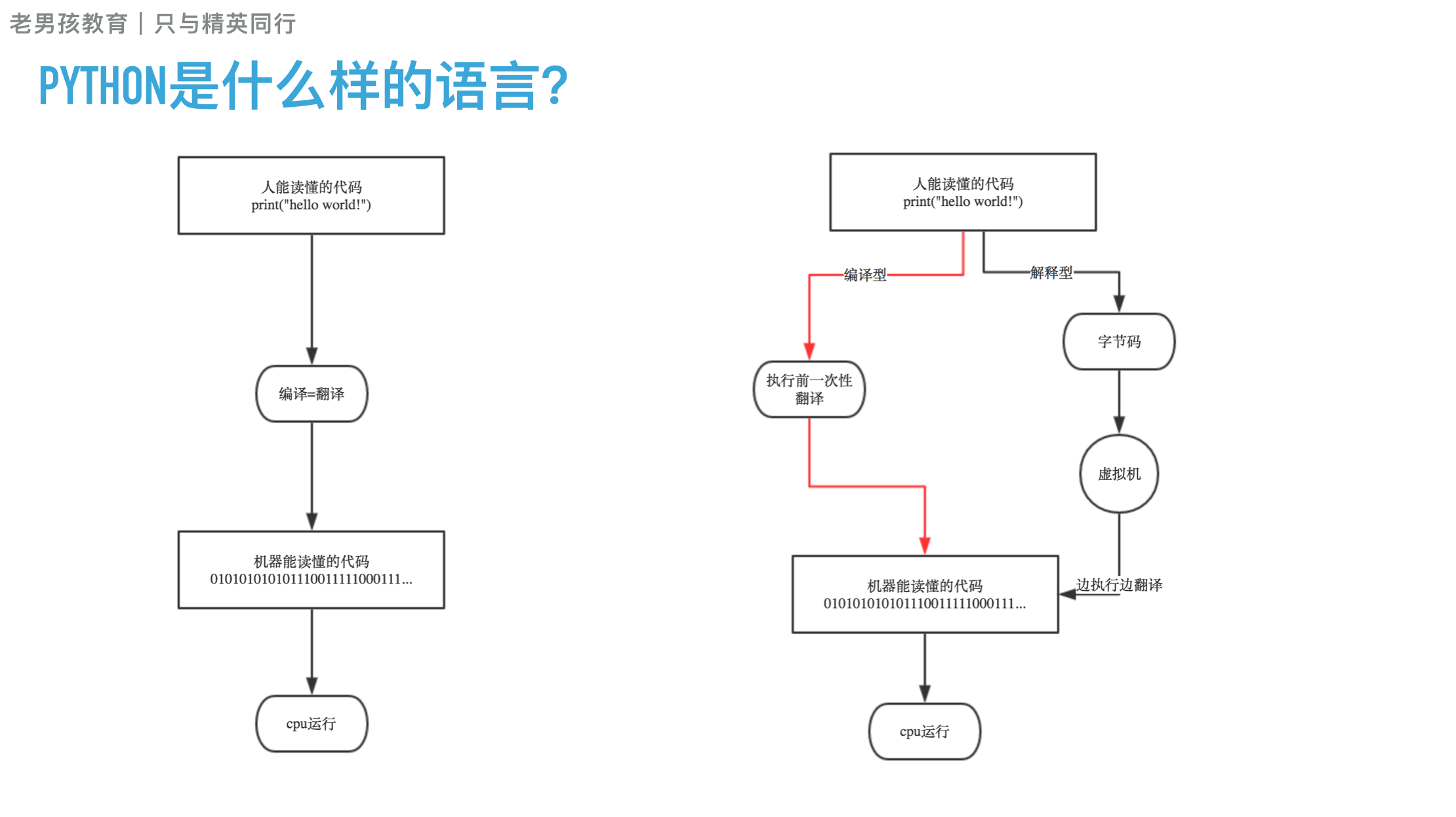
编译型vs解释型
编译型
优点:编译器一般会有预编译的过程对代码进行优化。因为编译只做一次,运行时不需要编译,所以编译型语言的程序执行效率高。可以脱离语言环境独立运行。
缺点:编译之后如果需要修改就需要整个模块重新编译。编译的时候根据对应的运行环境生成机器码,不同的操作系统之间移植就会有问题,需要根据运行的操作系统环境编译不同的可执行文件。
解释型
优点:有良好的平台兼容性,在任何环境中都可以运行,前提是安装了解释器(虚拟机)。灵活,修改代码的时候直接修改就可以,可以快速部署,不用停机维护。
缺点:每次运行的时候都要解释一遍,性能上不如编译型语言。
一、低级语言与高级语言
最初的计算机程序都是用0和1的序列表示的,程序员直接使用的是机器指令,无需翻译,从纸带打孔输入即可执行得到结果。后来为了方便记忆,就将用0、1序列表示的机器指令都用符号助记,这些与机器指令一一对应的助记符就成了汇编指令,从而诞生了汇编语言。无论是机器指令还是汇编指令都是面向机器的,统称为低级语言。因为是针对特定机器的机器指令的助记符,所以汇编语言是无法独立于机器(特定的CPU体系结构)的。但汇编语言也是要经过翻译成机器指令才能执行的,所以也有将运行在一种机器上的汇编语言翻译成运行在另一种机器上的机器指令的方法,那就是交叉汇编技术。
高级语言是从人类的逻辑思维角度出发的计算机语言,抽象程度大大提高,需要经过编译成特定机器上的目标代码才能执行,一条高级语言的语句往往需要若干条机器指令来完成。高级语言独立于机器的特性是靠编译器为不同机器生成不同的目标代码(或机器指令)来实现的。那具体的说,要将高级语言编译到什么程度呢,这又跟编译的技术有关了,既可以编译成直接可执行的目标代码,也可以编译成一种中间表示,然后拿到不同的机器和系统上去执行,这种情况通常又需要支撑环境,比如解释器或虚拟机的支持,Java程序编译成bytecode,再由不同平台上的虚拟机执行就是很好的例子。所以,说高级语言不依赖于机器,是指在不同的机器或平台上高级语言的程序本身不变,而通过编译器编译得到的目标代码去适应不同的机器。从这个意义上来说,通过交叉汇编,一些汇编程序也可以获得不同机器之间的可移植性,但这种途径获得的移植性远远不如高级语言来的方便和实用性大。
二、编译与解释
编译是将源程序翻译成可执行的目标代码,翻译与执行是分开的;而解释是对源程序的翻译与执行一次性完成,不生成可存储的目标代码。这只是表象,二者背后的最大区别是:对解释执行而言,程序运行时的控制权在解释器而不在用户程序;对编译执行而言,运行时的控制权在用户程序。
解释具有良好的动态特性和可移植性,比如在解释执行时可以动态改变变量的类型、对程序进行修改以及在程序中插入良好的调试诊断信息等,而将解释器移植到不同的系统上,则程序不用改动就可以在移植了解释器的系统上运行。同时解释器也有很大的缺点,比如执行效率低,占用空间大,因为不仅要给用户程序分配空间,解释器本身也占用了宝贵的系统资源。编译器是把源程序的每一条语句都编译成机器语言,并保存成二进制文件,这样运行时计算机可以直接以机器语言来运行此程序,速度很快;
而解释器则是只在执行程序时,才一条一条的解释成机器语言给计算机来执行,所以运行速度是不如编译后的程序运行的快的.
编译型和解释型
我们先看看编译型,其实它和汇编语言是一样的:也是有一个负责翻译的程序来对我们的源代码进行转换,生成相对应的可执行代码。这个过程说得专业一点,就称为编译(Compile),而负责编译的程序自然就称为编译器(Compiler)。如果我们写的程序代码都包含在一个源文件中,那么通常编译之后就会直接生成一个可执行文件,我们就可以直接运行了。但对于一个比较复杂的项目,为了方便管理,我们通常把代码分散在各个源文件中,作为不同的模块来组织。这时编译各个文件时就会生成目标文件(Object file)而不是前面说的可执行文件。一般一个源文件的编译都会对应一个目标文件。这些目标文件里的内容基本上已经是可执行代码了,但由于只是整个项目的一部分,所以我们还不能直接运行。待所有的源文件的编译都大功告成,我们就可以最后把这些半成品的目标文件“打包”成一个可执行文件了,这个工作由另一个程序负责完成,由于此过程好像是把包含可执行代码的目标文件连接装配起来,所以又称为链接(Link),而负责链接的程序就叫……就叫链接程序(Linker)。链接程序除了链接目标文件外,可能还有各种资源,像图标文件啊、声音文件啊什么的,还要负责去除目标文件之间的冗余重复代码,等等,所以……也是挺累的。链接完成之后,一般就可以得到我们想要的可执行文件了。
上面我们大概地介绍了编译型语言的特点,现在再看看解释型。噢,从字面上看,“编译”和“解释”的确都有“翻译”的意思,它们的区别则在于翻译的时机安排不大一样。打个比方:假如你打算阅读一本外文书,而你不知道这门外语,那么你可以找一名翻译,给他足够的时间让他从头到尾把整本书翻译好,然后把书的母语版交给你阅读;或者,你也立刻让这名翻译辅助你阅读,让他一句一句给你翻译,如果你想往回看某个章节,他也得重新给你翻译。
两种方式,前者就相当于我们刚才所说的编译型:一次把所有的代码转换成机器语言,然后写成可执行文件;而后者就相当于我们要说的解释型:在程序运行的前一刻,还只有源程序而没有可执行程序;而程序每执行到源程序的某一条指令,则会有一个称之为解释程序的外壳程序将源代码转换成二进制代码以供执行,总言之,就是不断地解释、执行、解释、执行……所以,解释型程序是离不开解释程序的。像早期的BASIC就是一门经典的解释型语言,要执行BASIC程序,就得进入BASIC环境,然后才能加载程序源文件、运行。解释型程序中,由于程序总是以源代码的形式出现,因此只要有相应的解释器,移植几乎不成问题。编译型程序虽然源代码也可以移植,但前提是必须针对不同的系统分别进行编译,对于复杂的工程来说,的确是一件不小的时间消耗,况且很可能一些细节的地方还是要修改源代码。而且,解释型程序省却了编译的步骤,修改调试也非常方便,编辑完毕之后即可立即运行,不必像编译型程序一样每次进行小小改动都要耐心等待漫长的Compiling…Linking…这样的编译链接过程。不过凡事有利有弊,由于解释型程序是将编译的过程放到执行过程中,这就决定了解释型程序注定要比编译型慢上一大截,像几百倍的速度差距也是不足为奇的。
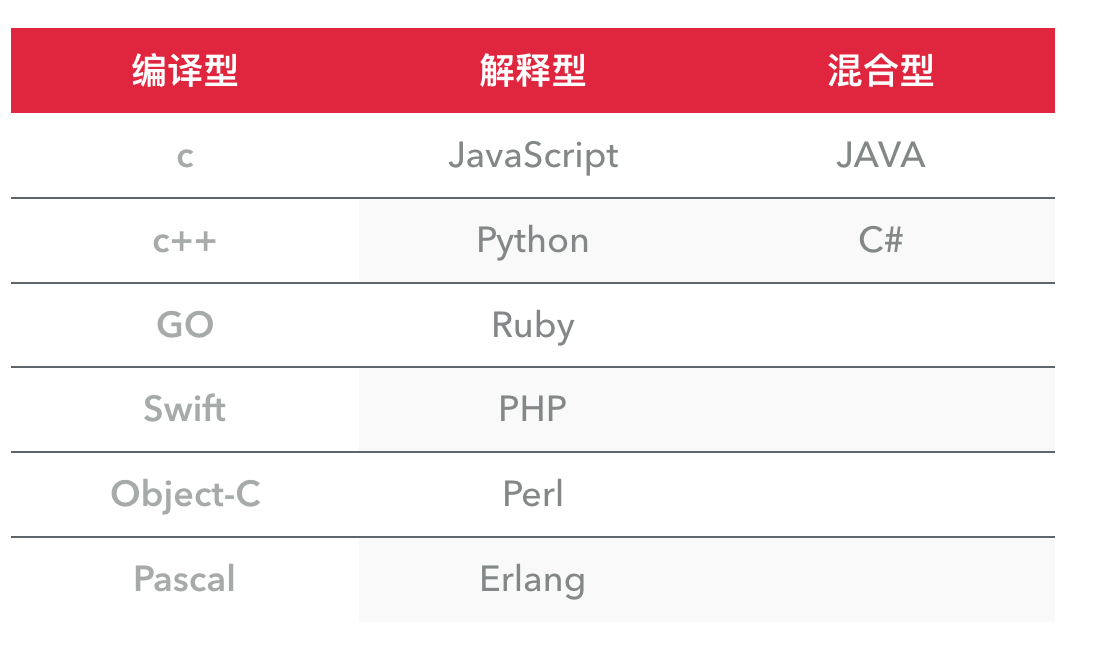
编译型与解释型,两者各有利弊。前者由于程序执行速度快,同等条件下对系统要求较低,因此像开发操作系统、大型应用程序、数据库系统等时都采用它,像C/C++、Pascal/Object Pascal(Delphi)、VB等基本都可视为编译语言,而一些网页脚本、服务器脚本及辅助开发接口这样的对速度要求不高、对不同系统平台间的兼容性有一定要求的程序则通常使用解释性语言,如Java、JavaScript、VBScript、Perl、Python等等。
但既然编译型与解释型各有优缺点又相互对立,所以一批新兴的语言都有把两者折衷起来的趋势,例如Java语言虽然比较接近解释型语言的特征,但在执行之前已经预先进行一次预编译,生成的代码是介于机器码和Java源代码之间的中介代码,运行的时候则由JVM(Java的虚拟机平台,可视为解释器)解释执行。它既保留了源代码的高抽象、可移植的特点,又已经完成了对源代码的大部分预编译工作,所以执行起来比“纯解释型”程序要快许多。而像VB6(或者以前版本)、C#这样的语言,虽然表面上看生成的是.exe可执行程序文件,但VB6编译之后实际生成的也是一种中介码,只不过编译器在前面安插了一段自动调用某个外部解释器的代码(该解释程序独立于用户编写的程序,存放于系统的某个DLL文件中,所有以VB6编译生成的可执行程序都要用到它),以解释执行实际的程序体。C#(以及其它.net的语言编译器)则是生成.net目标代码,实际执行时则由.net解释系统(就像JVM一样,也是一个虚拟机平台)进行执行。当然.net目标代码已经相当“低级”,比较接近机器语言了,所以仍将其视为编译语言,而且其可移植程度也没有Java号称的这么强大,Java号称是“一次编译,到处执行”,而.net则是“一次编码,到处编译”。呵呵,当然这些都是题外话了。总之,随着设计技术与硬件的不断发展,编译型与解释型两种方式的界限正在不断变得模糊。动态语言和静态语言
通常我们所说的动态语言、静态语言是指动态类型语言和静态类型语言。(1)动态类型语言:动态类型语言是指在运行期间才去做数据类型检查的语言,也就是说,在用动态类型的语言编程时,永远也不用给任何变量指定数据类型,该语言会在你第一次赋值给变量时,在内部将数据类型记录下来。Python和Ruby就是一种典型的动态类型语言,其他的各种脚本语言如VBScript也多少属于动态类型语言。
(2)静态类型语言:静态类型语言与动态类型语言刚好相反,它的数据类型是在编译其间检查的,也就是说在写程序时要声明所有变量的数据类型,C/C++是静态类型语言的典型代表,其他的静态类型语言还有C#、JAVA等。
强类型定义语言和弱类型定义语言
(1)强类型定义语言:强制数据类型定义的语言。也就是说,一旦一个变量被指定了某个数据类型,如果不经过强制转换,那么它就永远是这个数据类型了。举个例子:如果你定义了一个整型变量a,那么程序根本不可能将a当作字符串类型处理。强类型定义语言是类型安全的语言。
(2)弱类型定义语言:数据类型可以被忽略的语言。它与强类型定义语言相反, 一个变量可以赋不同数据类型的值。
强类型定义语言在速度上可能略逊色于弱类型定义语言,但是强类型定义语言带来的严谨性能够有效的避免许多错误。另外,“这门语言是不是动态语言”与“这门语言是否类型安全”之间是完全没有联系的!
例如:Python是动态语言,是强类型定义语言(类型安全的语言); VBScript是动态语言,是弱类型定义语言(类型不安全的语言); JAVA是静态语言,是强类型定义语言(类型安全的语言)。
Python入门
一、安装Python
在这里我我推荐安装Python3,因为随着时间的推移Python3,必定是未来的趋势,我们要顺应潮流。在Python的官网可以下载相应的版本,网址是https://www.python.org/downloads/,安装上面的提示安装好即可,就不在多说了,此外后面的操作都是基于windows下的操作。
二、编写Hello,World
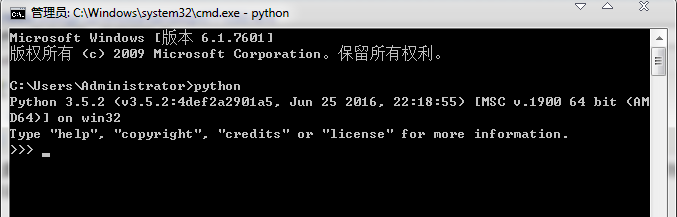
安装好了环境之后,我们就可以编写代码了,这里我们以两种方式输出Hello,World,第一种我们用解释器来实现,打开cmd
输入Python,如果没有出现下面的实例,检查下python环境变量是否配置好。
在这里我是用pycharm来写的因为他强大方便!!!!

他的界面是这样的

好了有了编辑器和环境那么我们开始来写第一个python
国际惯例“Hello World”
首先要注意一点
好吧开始写了
写之间要养成良好的代码习惯

好吧~~~真的开始了!
我这里用的是python3.0
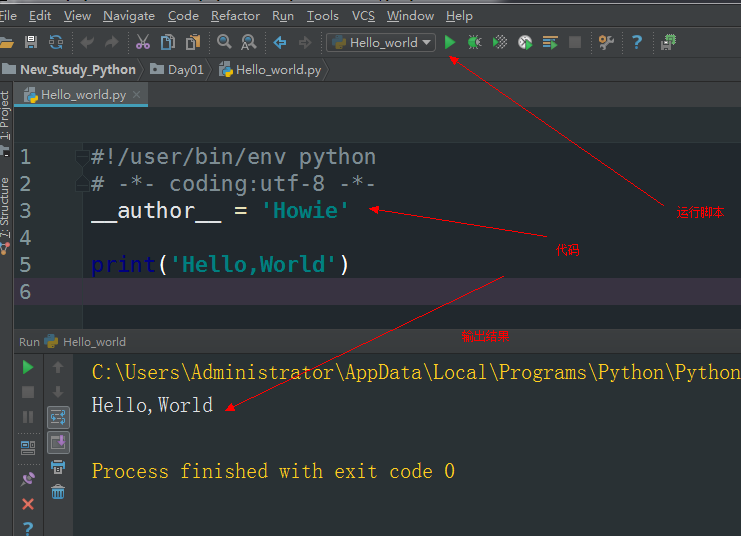
1 print('Hello,World')
记得这个是python3的写法
在这里就要说一下python2 和 python3 的分别了
print 'Hello,World' 这样是python 2 的做法
三、变量、输入、输出
变量就是一个内存地址的门牌,他的存在就在为了把内存地址给保存起来等待调用
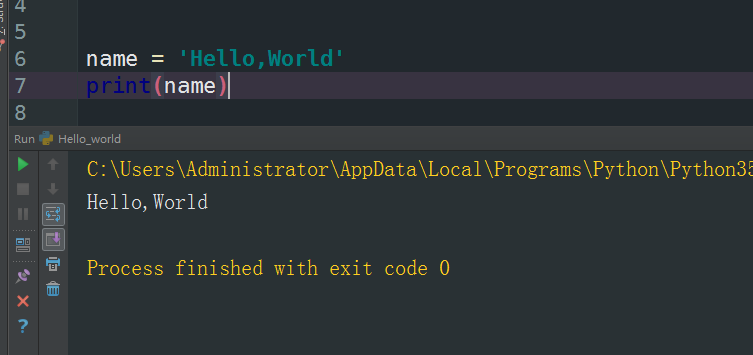
这样就可以了
配合使用就是这样
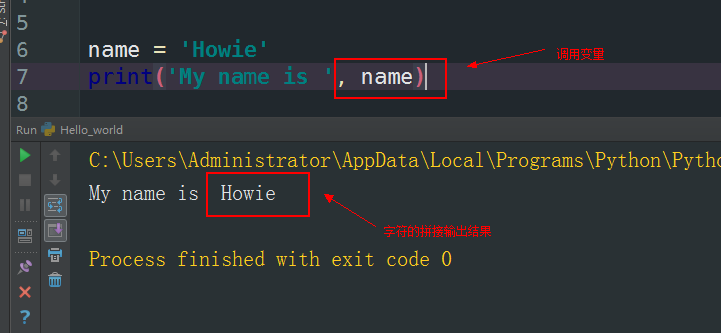
在命令行中执行python 1.py后,提示你输入一个用户名,输入完成后,打印出刚才输入的字符,上面声明了一个name变量,然后将输入的字符保存在name变量中,变量不仅可以是字符串,还可以是整数或浮点数,比如a=2
将定义了一个整形变量a,值为2。
此外变量定义的规则有以下几点:
- 变量名只能是 字母、数字或下划线的任意组合
- 变量名的第一个字符不能是数字
- python关键字不能声明为变量名
来咱们玩点复杂一点点的
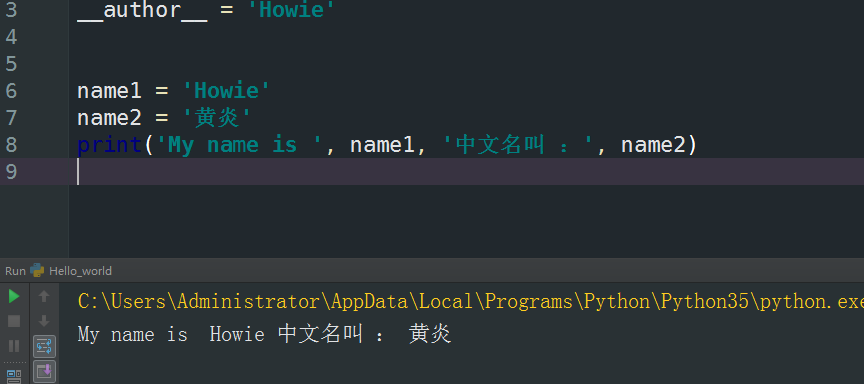
再玩一点更复杂的
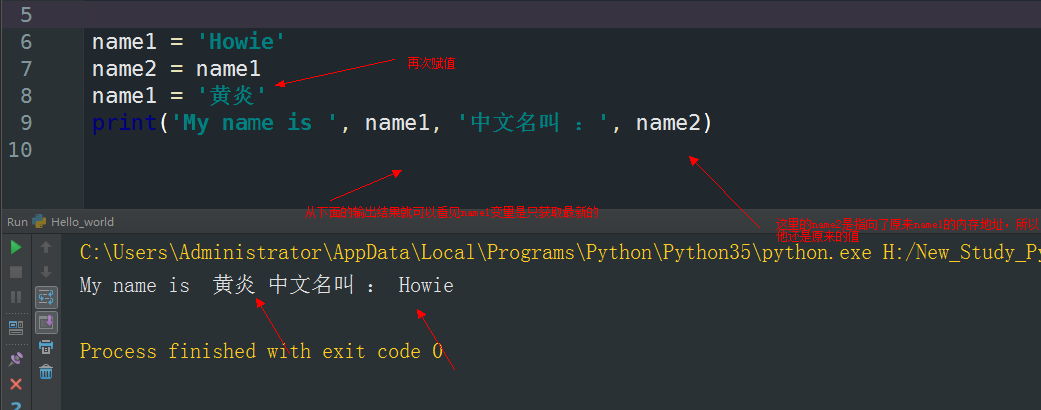
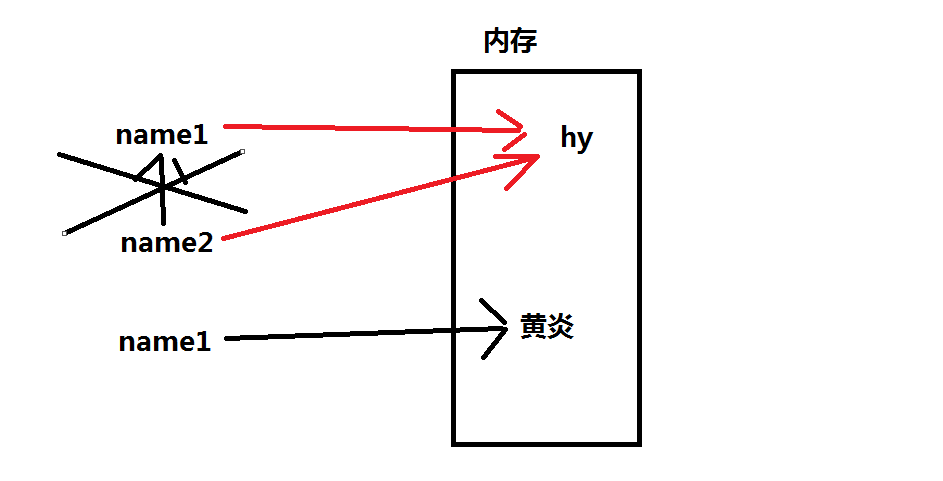
上面的这个图会比较好的表达出变量的作用
字符编码
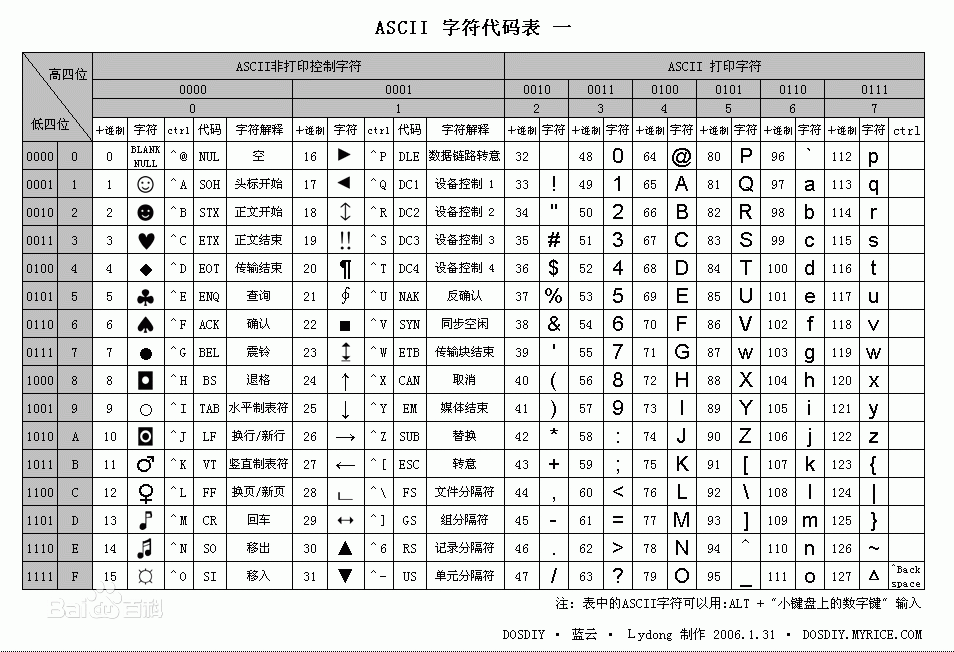
python解释器在加载 .py 文件中的代码时,会对内容进行编码(默认ascill)
ASCII(American Standard Code for Information Interchange,美国标准信息交换代码)是基于拉丁字母的一套电脑编码系统,主要用于显示现代英语和其他西欧语言,其最多只能用 8 位来表示(一个字节),即:2**8 = 256-1,所以,ASCII码最多只能表示 255 个符号。
关于中文
为了处理汉字,程序员设计了用于简体中文的GB2312和用于繁体中文的big5。
GB2312(1980年)一共收录了7445个字符,包括6763个汉字和682个其它符号。汉字区的内码范围高字节从B0-F7,低字节从A1-FE,占用的码位是72*94=6768。其中有5个空位是D7FA-D7FE。
GB2312 支持的汉字太少。1995年的汉字扩展规范GBK1.0收录了21886个符号,它分为汉字区和图形符号区。汉字区包括21003个字符。2000年的 GB18030是取代GBK1.0的正式国家标准。该标准收录了27484个汉字,同时还收录了藏文、蒙文、维吾尔文等主要的少数民族文字。现在的PC平台必须支持GB18030,对嵌入式产品暂不作要求。所以手机、MP3一般只支持GB2312。
从ASCII、GB2312、GBK 到GB18030,这些编码方法是向下兼容的,即同一个字符在这些方案中总是有相同的编码,后面的标准支持更多的字符。在这些编码中,英文和中文可以统一地处理。区分中文编码的方法是高字节的最高位不为0。按照程序员的称呼,GB2312、GBK到GB18030都属于双字节字符集 (DBCS)。
有的中文Windows的缺省内码还是GBK,可以通过GB18030升级包升级到GB18030。不过GB18030相对GBK增加的字符,普通人是很难用到的,通常我们还是用GBK指代中文Windows内码。
显然ASCII码无法将世界上的各种文字和符号全部表示,所以,就需要新出一种可以代表所有字符和符号的编码,即:Unicode
Unicode(统一码、万国码、单一码)是一种在计算机上使用的字符编码。Unicode 是为了解决传统的字符编码方案的局限而产生的,它为每种语言中的每个字符设定了统一并且唯一的二进制编码,规定虽有的字符和符号最少由 16 位来表示(2个字节),即:2 **16 = 65536,
注:此处说的的是最少2个字节,可能更多
UTF-8,是对Unicode编码的压缩和优化,他不再使用最少使用2个字节,而是将所有的字符和符号进行分类:ascii码中的内容用1个字节保存、欧洲的字符用2个字节保存,东亚的字符用3个字节保存...
所以,python解释器在加载 .py 文件中的代码时,会对内容进行编码(默认ascill),如果是如下代码的话:
注释
当行注视:# 被注释内容
多行注释:""" 被注释内容 """
四、缩进
Python的语法比较简单,采用缩进方式(注意一定要注意缩进,因为python是靠他来判断上下层关系的)
五、用户输入
OK 上面说了那么多都是废话~因为以后根本不需要记得,为什么呢?
因为你天天敲代码都必须这样敲!所以就和喝水一样不需要记得了
来!我们玩点好玩的,和代码进行交互了
OK 看见了这个就这个可以和人进行交互了
完整一些的写法包括一些字符串的格式化
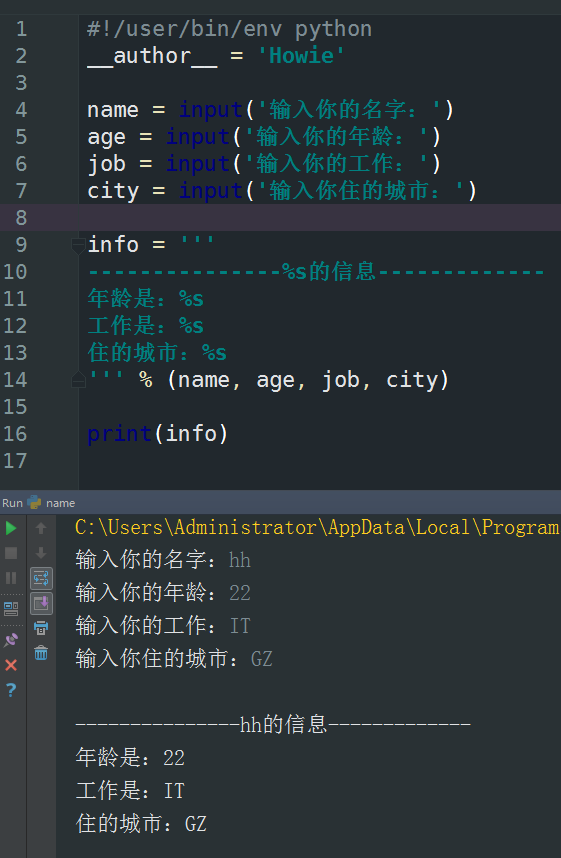
还有一个格式化是这样的~
在某些场景中只能用这个
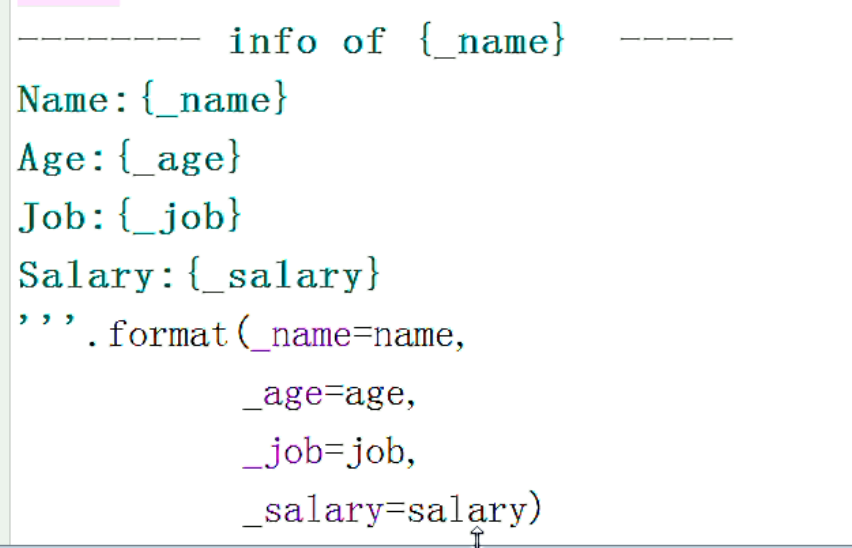
还有一种很少很少用到的

一般都是用前面两个
六、数据类型初识
2 是一个整数的例子。
长整数 不过是大一些的整数。
3.23和52.3E-4是浮点数的例子。E标记表示10的幂。在这里,52.3E-4表示52.3 * 10-4。
(-5+4j)和(2.3-4.6j)是复数的例子,其中-5,4为实数,j为虚数,数学中表示复数是什么?。
int(整型)
在64位系统上,整数的位数为64位,取值范围为-2**63~2**63-1,即-9223372036854775808~9223372036854775807
跟C语言不同,Python的长整数没有指定位宽,即:Python没有限制长整数数值的大小,但实际上由于机器内存有限,我们使用的长整数数值不可能无限大。
注意,自从Python2.2起,如果整数发生溢出,Python会自动将整数数据转换为长整数,所以如今在长整数数据后面不加字母L也不会导致严重后果了。
float(浮点型)
浮点数用来处理实数,即带有小数的数字。类似于C语言中的double类型,占8个字节(64位),其中52位表示底,11位表示指数,剩下的一位表示符号。
complex(复数)
复数由实数部分和虚数部分组成,一般形式为x+yj,其中的x是复数的实数部分,y是复数的虚数部分,这里的x和y都是实数。
"hello world"
|
1
2
3
4
|
name
=
"alex"
print
"i am %s "
%
name
#输出: i am alex
|
PS: 字符串是 %s;整数 %d;浮点数%f
- 移除空白
- 分割
- 长度
- 索引
- 切片
|
1
2
3
|
name_list
=
[
'alex'
,
'seven'
,
'eric'
]
或
name_list =
list
([
'alex'
,
'seven'
,
'eric'
])
|
基本操作:
- 索引 (就是从0开始一直自增长下去)
- 切片 ([0,2] 这样就是从第一个开始到第2个结束,他是顾前不顾后的,0就是第一个要了,1是第二个要了,2是第三个就是最后一个不要了 所以是从第一个开始到第2个)
- 追加 append[list]
- 删除 pip[list]
- 长度 len[list]
- 切片
- 循环 for i in [list]:
- 包含
|
1
2
3
|
ages
=
(
11
,
22
,
33
,
44
,
55
)
或
ages
=
tuple
((
11
,
22
,
33
,
44
,
55
))
|
|
1
2
3
|
person
=
{
"name"
:
"mr.wu"
,
'age'
:
18
}
或
person
=
dict
({
"name"
:
"mr.wu"
,
'age'
:
18
})
|
常用操作:
- 索引
- 新增 直接赋值
- 删除
- 键、值、键值对
- 循环 for k,v in {dict}
- 长度
嗯这一段我就照抄了哈~
其实比较重要的就是列表和字典~~~
他们会伴随着写代码的一生的~很重要很重要很重要!!!!
七、数据运算

比较运算:

赋值运算:

逻辑运算:

成员运算:

身份运算:

位运算:

*按位取反运算规则(按位取反再加1) 详解http://blog.csdn.net/wenxinwukui234/article/details/42119265
运算符优先级:

更多内容:猛击这里
八、表达式if ... else
ok,开始来条件判断了~
没错还是if elif else
先来一个经典的登录认证吧
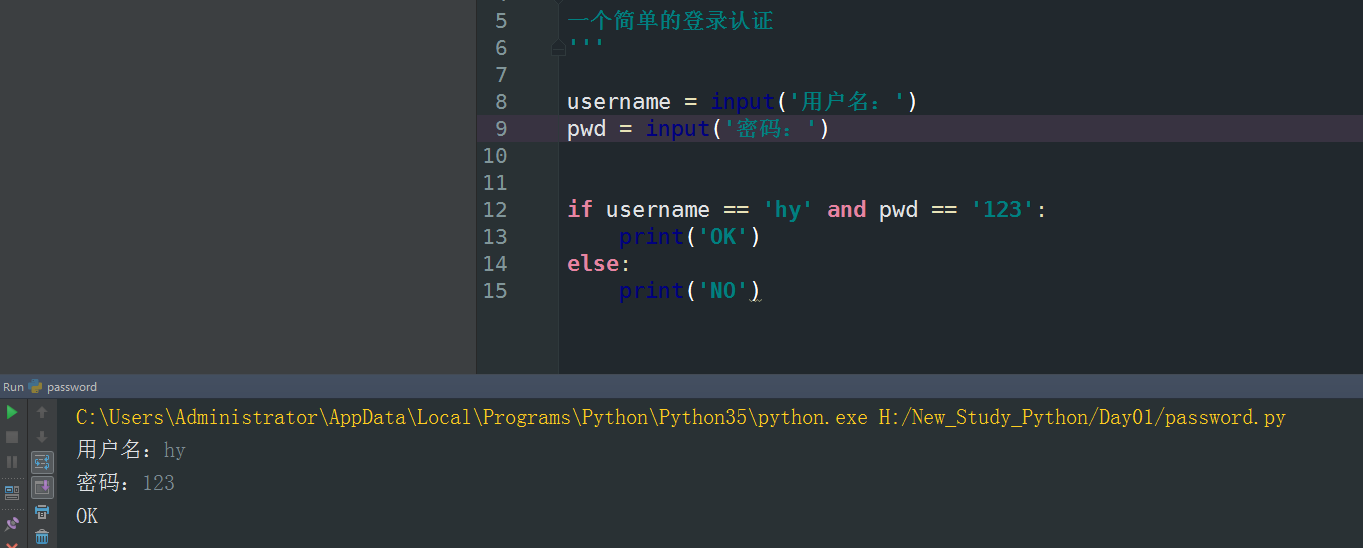
#!/user/bin/env python __author__ = 'Howie' ''' 一个简单的登录认证 ''' username = input('用户名:') pwd = input('密码:') if username == 'hy' and pwd == '123': print('OK') else: print('NO')
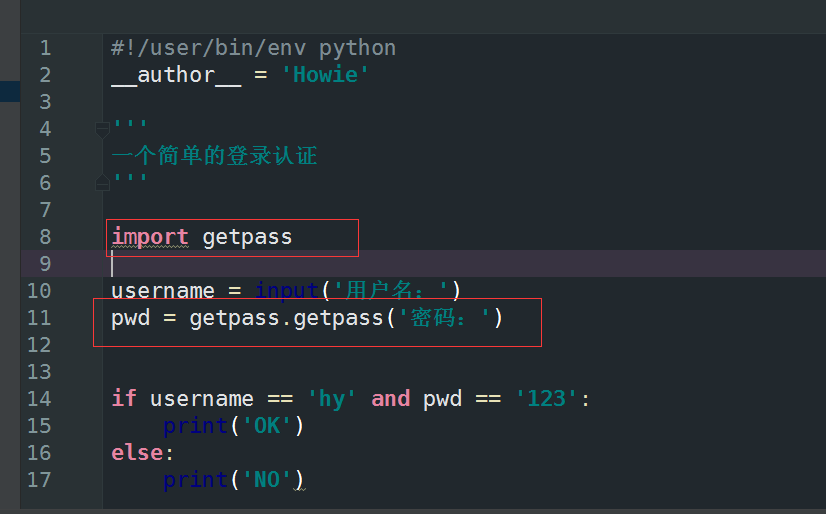
想要密码不想显示就用这个
对了这个是不能在windows下面用的哈
还有就是python是严格缩进的~这个一个要注意

当你看见这个的时候就是代表你的缩进有问题:

OK 再玩点复杂一点的
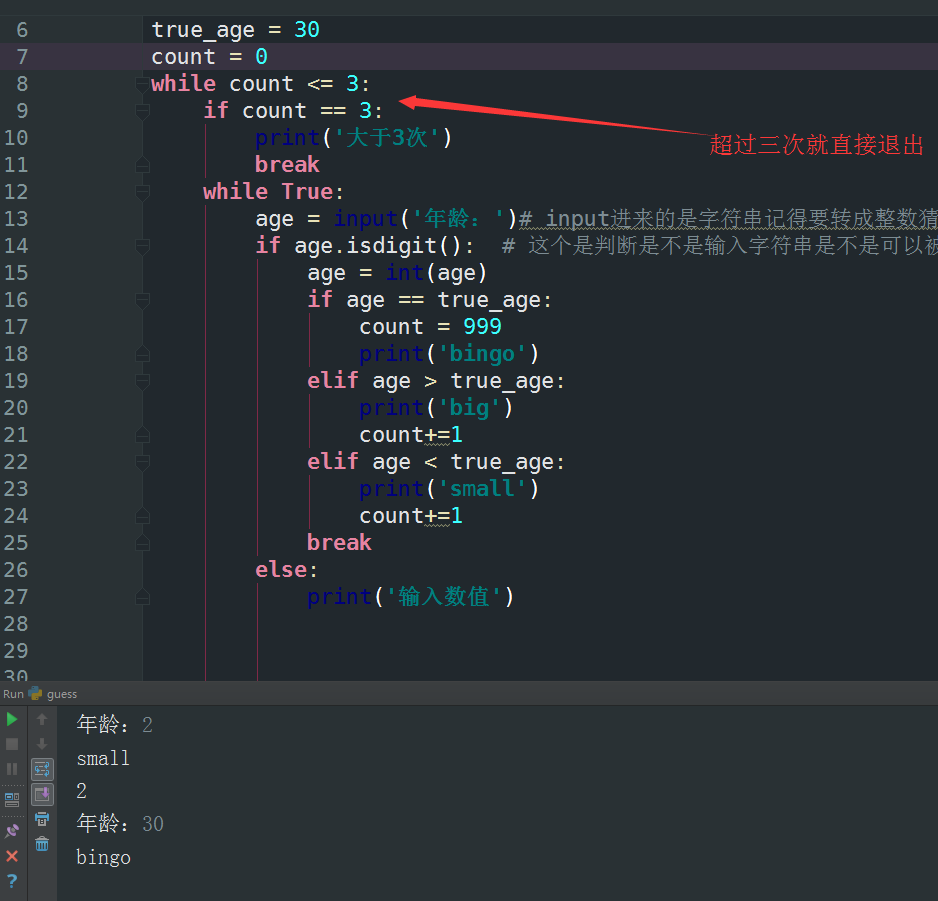
OK 还有简单一点的~

除了if有else 其实while 也有~!!!!有啊~~~要记得!!!!
ok 还有for循环~~~

看见rang(0,10,2)了吗??
是从0到9 隔1个 的意思啊
OK 玩点更加复杂一点的
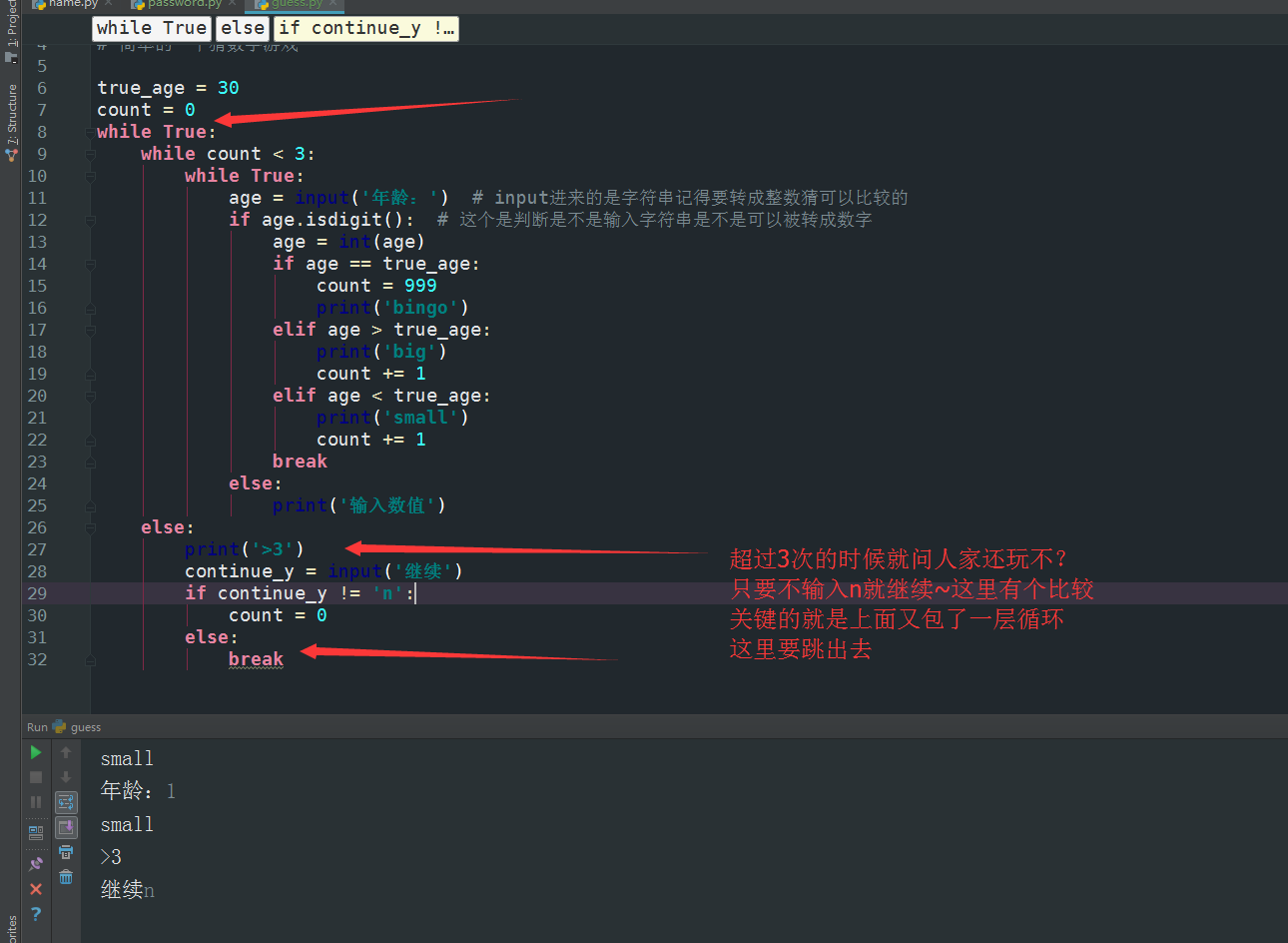
OK 上面是有问题~
这个才是正确的
这里是告诉我们不要用太多的循环啊~很容易就乱了的

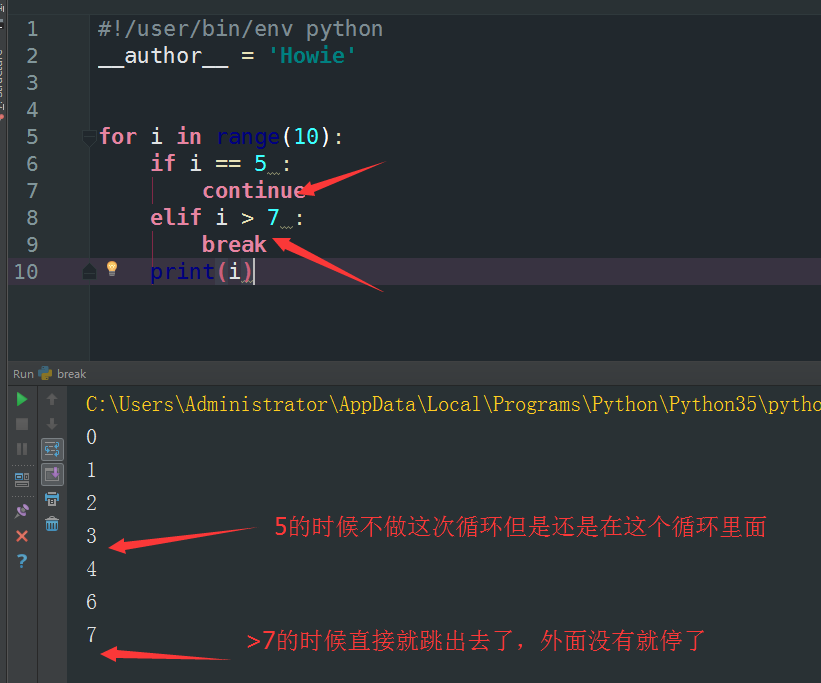
OK 说到循环就肯定要说到 break 和 continue
break 跳出当前这个循环。
continue跳出这次循环。
这样说可能很模糊那么这样说他们两个都是停止循环,但是break就是去到了上一层的循环那里去了,continue还会留着这个循环体内。














 1280
1280











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









