






一:首先要将linux 和winodws的exlipse关联起来
第一步:在windows中部署hadoop包:解压一个hadoop压缩文件
第二步:将解压后的hadoop文件目录下的bin文件中的文件全部被替换成下面文件夹下的文件:该文件已经压缩并上传:bin.rar
第三步:将替换后的文件夹下的一个hadoop.dll复制到windows-->system32文件夹下
第四步:配置hadoop的环境变量:
需要配置的环境变量包括:
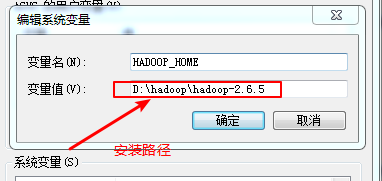
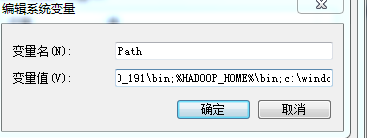
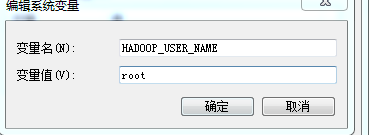
这里的root 是虚拟机的管理员账户
第五步:验证是否部署成功:在eclipse创建一个java项目
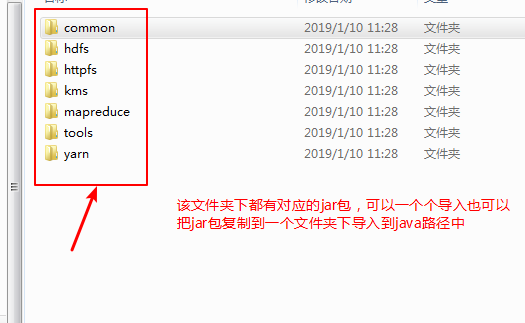
第六步:导入hadoop文件夹下相关的jar包:
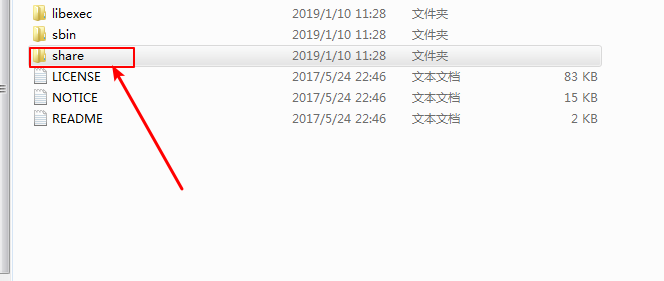
第七步:利用jar包写第一个验证java项目:代码如下:
package com.sxt.test;
import java.net.URI;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
public class TestHadoop {
public static void main(String[] args) throws Exception {
Configuration conf=new Configuration();
FileSystem fs=FileSystem.newInstance(new URI("hdfs://hadoop-node01:9000"), conf, "root");
fs.mkdirs(new Path("/a123"));
fs.close();
}
}
第八步:运行该java项目:可以在浏览器中看到对应的文件是否生成;如果生成了则部署成功,否则失败
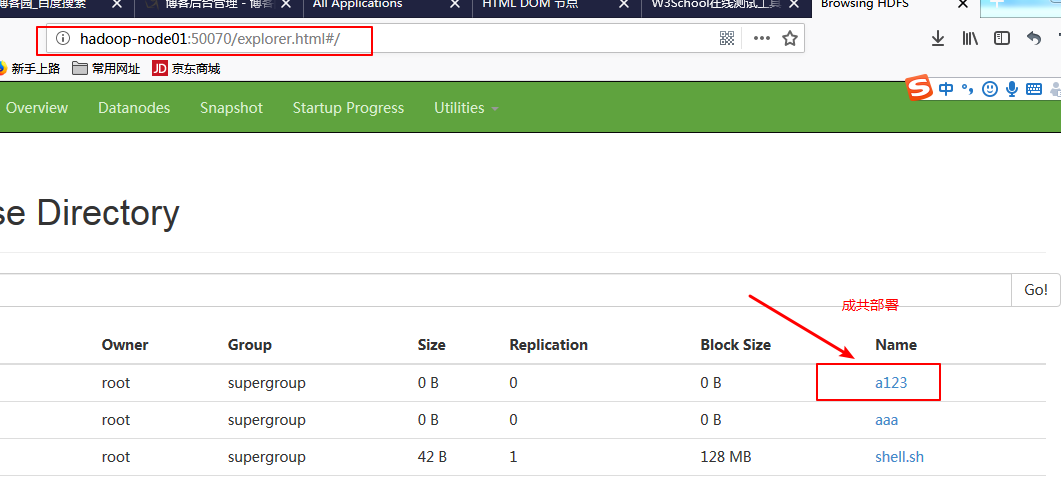
那么我们现在就可以在eclipse中通过java代码来操作hadoop了。
现在我们自己写一个jar包来统计一个文件中的单词的出现的次数。在这之前要理解mapreduce统计文档单词的原理
第一步:在eclipse中部署一个java项目
该java项目包括三个类:
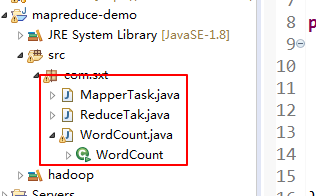
这是根据mapreduce的原理来实现的java类:mapperTask是用来统计每个节点的文件的一部分的单词以及出现的次数
package com.sxt;
import java.io.IOException;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Mapper;
/**
* 这是统计每一个节点数据的每一行的单词出现的次数
* KEYIN
* 这是默认是一行一行读取的偏移量:比如 java ja jvas js hadoop 这是第一行那么偏移量就是0
* js js jsjjsjs jsp json 这是第二行,那么偏移量就是第一行的单词的统计的个数:5
* 以此类推到每个节点的数据读取完毕
* 这个类型是Long ---LongWritable
* VALUEIN
* 默认是读取一行的数据的类型:这里是String
* KEYOUT
* 处理完一个节点之后返回的数据key:单词:例如在一个节点的一部分数据中统计的单词有
* java
* ja
* js ....
* VALUEOUT
* 处理完一个节点的数据返回的每一行中每一个单词出现的次数:IntWritable
* 最后mapper处理完后返回的是: java[1,1,1,]
* js[1,1,1]...
* @author ASUS
*
*/
public class MapperTask extends Mapper<LongWritable, Text ,Text , IntWritable>{
@Override
/**
* map阶段的任务的方法:是每次读取一行数据执行一次该方法
*/
protected void map(LongWritable key, Text value,Context context)
throws IOException, InterruptedException {
// TODO Auto-generated method stub
String line = value.toString();
//利用空格进行分割
String[] words = line.split(" ");
for (String word : words) {
// 将单词作为key 将1作为值 以便于后续的数据分发
context.write(new Text(word), new IntWritable(1));
}
}
}
reduceTask是将各个节点获取的数据进行运算和统计
package com.sxt;
import java.io.IOException;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Reducer;
/**
* 这是做数据统计汇总的
* KEYIN:这是map统计的单词
* VALUEIN:这是map统计的数量
* KEYOUT:这是汇总之后的单词
* VALUEOUT:这是汇总之后的数量
* @author ASUS
*
*/
public class ReduceTak extends Reducer<Text, IntWritable, Text, IntWritable>{
@Override
/**
*这是做汇总的方法:每个节点统计完毕执行一次
*/
protected void reduce(Text key, Iterable<IntWritable> values,
Context context) throws IOException, InterruptedException {
// TODO Auto-generated method stub
int count=0;
for (IntWritable value : values) {
count+=value.get();
}
context.write(key, new IntWritable(count));
}
}
wordCount是用来启动的。
package com.sxt;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
/**
* 这是启动工具
* @author ASUS
*
*/
public class WordCount {
public static void main(String[] args) throws Exception {
//创建配置文件对象
Configuration conf=new Configuration(true);
//获取job对象
Job job=Job.getInstance(conf);
//设置相关类
job.setJarByClass(WordCount.class);
//指定map阶段和reduce阶段的处理类
job.setMapperClass(MapperTask.class);
job.setReducerClass(ReduceTak.class);
//指定map的输出的kv类型
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(IntWritable.class);
//指定joB的原始的输入输出路径,通过参数传入
FileInputFormat.setInputPaths(job, new Path(args[0]));
FileOutputFormat.setOutputPath(job, new Path(args[1]));
// 将job中配置的参数和job所用的jar包提交给 yarn运行
// waitForCompletion等待执行的结果
job.waitForCompletion(true);
}
}
第二步:将该java项目导出成一个jar包
第三步:在xshell中进行相应的操作:先将第二步导出的jar包上传到虚拟机
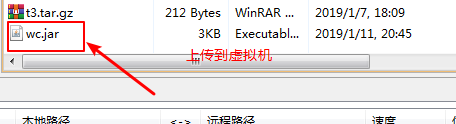
第四步:删除相应的/wordcount/input文件夹
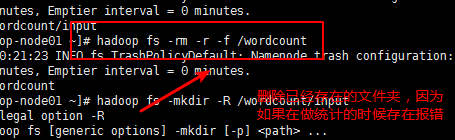
第五步:重新创建对应的文件夹:
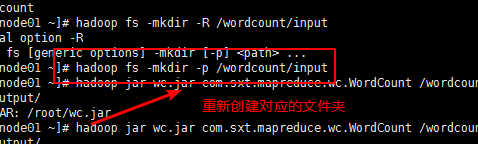
第六步:导入相关的要统计的文件
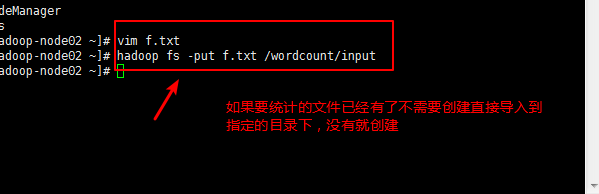
第八步:在浏览器中检查该文件是否存在:
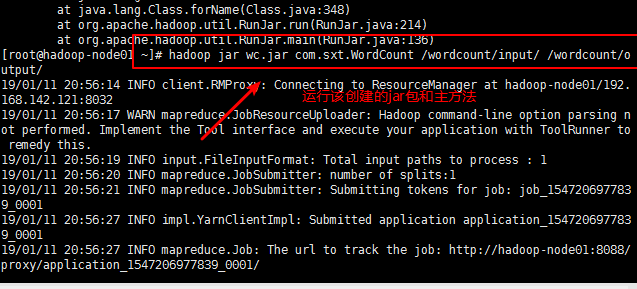
第九步:运行创建的jar包和主方法:hadoop jar wc.jar com.sxt.WordCount (这是传入的两个参数,在主方法中设置的,也可以写死)
第十步:看到结果:
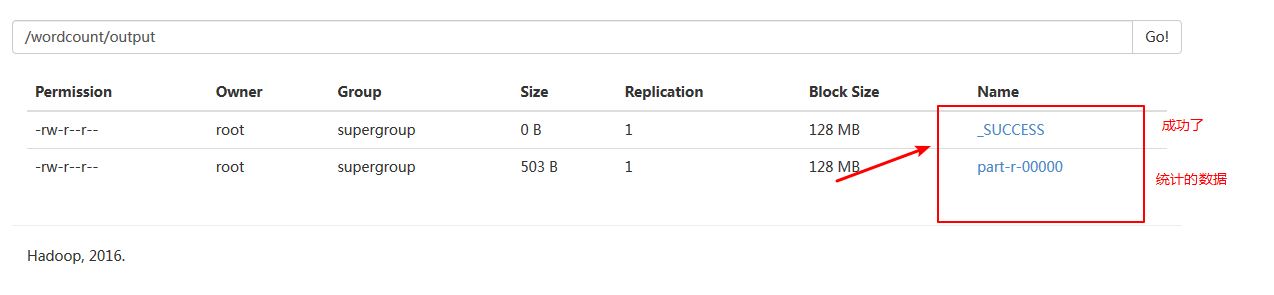
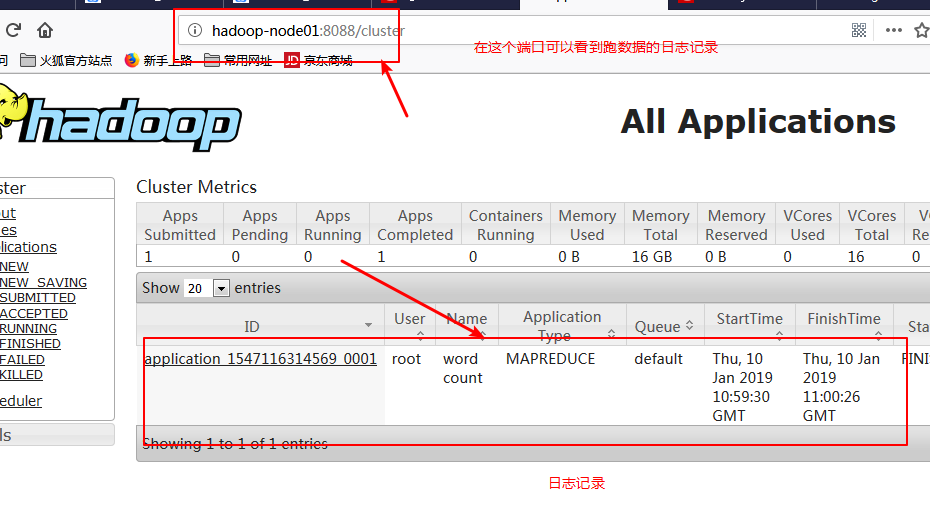
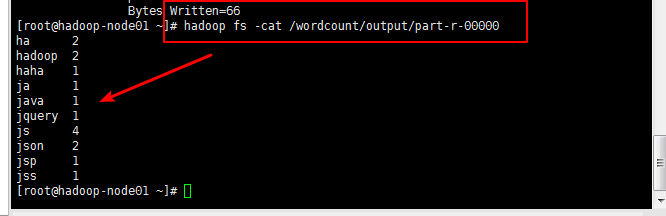
还可以利用命令查看统计的结果:hadoop fs -cat /wordcount/output/part-r-00000














 444
444











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









