






1. 前言
在年前大概翻看了一下SequoiaDB的源代码,是为了寻找其宣称的比MongoDB领先的特性,尽管泛泛而过,但是其设计给我留下了比较深刻的映像。从业8年来,虽偶有冲动,从未敢于深入到数据库服务器这种由c++实现的动辄几十万行代码的大型软件的源代码中去,抱着学习的态度,第一次专门花了几周时间,对整个SequoiaDB的代码进行了研究,收获颇多,其高质量的代码,设计和思路,很值得学习。同时也希望在这里分享给大家,减少乐意学习的同学阅读代码的困难。
2. 总体架构
先上大图,对整个数据库引擎的模块有一个了解,能够很好的把握代码的脉络。
我根据我的理解,对数据库引擎的层次结构画了一个图如下。

从代码中可以看出,其层次结构非常的清晰。数据库引擎对外提供TCP和REST两种形式的接口,不管哪种接口,最终会把协议上的payload转换为内部标准的Message,然后在内核中完成相应的操作。它使用直接内存映射的方式,使用底层的文件用于数据存储,这些都由一层称为DMS的数据管理服务层实现。
3. 控制块(ControlBlock)管理
在SequoiaDB中,功能模块通过ControlBlock组织在一起,其各种功能特性,通过各种各样的CB实现。其中有一个核心的CB称为KRCB(Kernel Control Block),由它负责对其他的CB进行管理,对于每个数据库进程,只有一个KRCB实例,其他所有的CB都可以调用KRCB上的对应方法获取。在不同的数据库角色下,会初始化不同的CB集注册到KRCB中。每种角色下的CB如下所示:
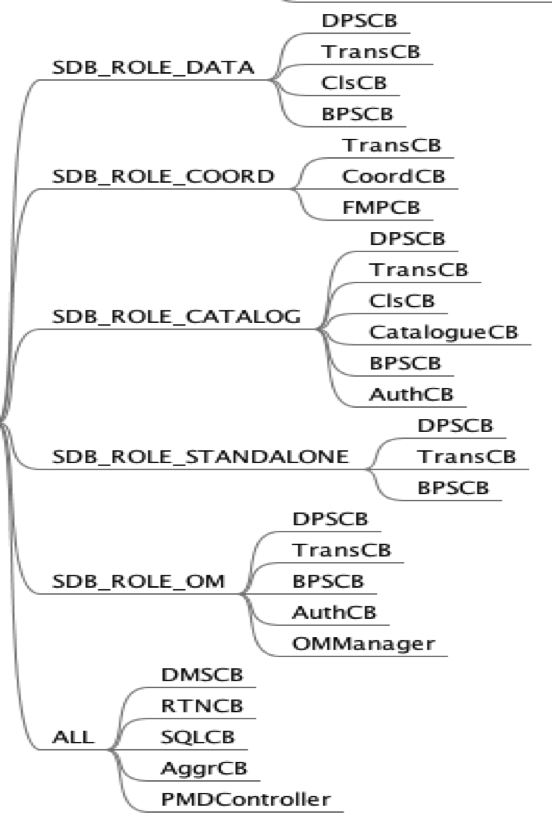
所有的CB都有init,active,deactive,fini四个方法,分别表示控制块的四个生命周期,这样的设计,实现了SequoiaDB模块化的设计思路,也便于其统一管理和控制,更方便了可扩展性。目前具备的CB分别实现了存储管理,事务管理,数据保护,集群管理,权限认证,SQL,聚合等功能,根据CB名称的简写,顾名思义,很容易了解其代表的含义,如果要增加功能,增加对应功能的CB即可。
4. 可执行单元及其管理
为了高效的处理各种操作,SequoiaDB实现了一个工作线程池的东西。线程池的设计在很多软件中都可以用到,其核心思想是为了减少线程的创建的开销,实现线程池中工作线程的复用。在SequoiaDB中其工作线程成为EDU(Engine Dispatchable Unit),它们在EDUMGR中进行管理,也就是说EDUMGR负责线程的创建,初始化,状态设置和销毁。需要工作线程进行处理的数据,都通过封装为事件消息发布到线程池的消息队列中让EDU进行处理。
其工作线程的状态按照如下的状态表转换:
| Creating | Running | Waiting | Idle | Destroy | |
| Creating | createNewEDU | ||||
| Running | activeEDU | - | activeEDU | activeEDU | - |
| Waiting | - | waitEDU | - | - | - |
| Idle | deactiveEDU | - | deactiveEDU | - | - |
| Destroy | destroyEDU | - | destroyEDU | destroyEDU | - |
对于可执行单元,按照类型分为了28种,每种可执行单元有一个自己的类型编号,每种可执行单元的实现,实际上通过实现一个入口函数,在运行时根据可执行单元所代表的类型动态调用。在pmdEDUEntryPoint中,定义了一个getEntryFuncByType的函数,负责动态定位入口函数。
在数据库引擎启动时,由pmdController启动和注册三个system EDU,分别为TCPListener,RESTListener和SYNCClock,这三个系统EDU分别负责处理TCP连接,Rest连接和同步节点间的时钟。
所有的功能模块,最终靠各种不同类型的EDU来执行,他们之间的关系如下:

5.存储服务实现
在SequoiaDB中,数据存储使用BSON格式,它直接使用操作系统提供的文件内存映射方式,获得高效的文件访问方式。借助google的snappy库,SequoiaDB还实现了数据压缩的功能。在SequoiaDB中,CollectionSpace相当于传统数据库中的库的概念,Collection相当于表的概念;对于一个CollectionSpace有一个dmsStorageUnit负责管理。它有几个特点:第一,对于数据,索引和二进制文件的存储都单独处理,分别由dmsStorageData,dmsStorageIndex,dmsStorageLob进行处理。第二,数据文件分块存放,有多个实际的数据文件组成完整的存储空间,这跟传统的数据库中通常看到的方式不一样,我想这应该是更方便了在集群系统中的数据文件的处理。
6 典型源码分析
下面列举几个典型的过程,对于不熟悉SequoiaDB源码的同学,通过跟这几个过程,结合前面的内容,应该可以很容易的熟悉代码的主要脉络,进而快速的学习到整个数据库引擎的实现过程。
6.1 数据库引擎启动过程相关
pmdMain.cpp为主入口,在pmdMainThreadMain中,实现了读取命令行参数,初始化KRCB,然后调用pmdController中的registerCB方法,根据数据库的角色,注册ControlBlock,最后启动一个while循环每100毫秒检测一下状态,完成数据库的启动。
pmdController本身也是一个ControlBlock,在前面pmdMain中调用其registerCB的过程中,pmdController实例也注册到了KRCB中,随后其状态被统一管理。所以,虽然在pmdMain中仅仅调用了registerCB方法,但是实际上很多初始化工作由pmdController才刚刚开始。
在init方法中,pmdController主要实现了对监听端口的绑定。
在active方法中,启动和注册了三个系统EDU,分别负责时钟同步,TCP连接处理和REST连接处理。
以TCPListener为例,其启动之后将不断的检查事件队列中是否有传递进来的连接,如果有,则启动一个pmdAgent EDU,由其工作线程负责处理后续的工作。
在pmdTcpListener.cpp中,可以看到其其实只是定义了一个入口函数名为pmdTcpListenerEntryPoint,由它来处理当EDU type为EDU_TYPE_TCPLISTENER时的具体工作。其他类型的EDU和其类型的映射,通过查看pmdEDUEntryPoint.cpp中的getEntryFuncByType函数可以得到。
6.2 数据查询的实现流程
pmdTcpListener.cpp中实现了tcpListener这个EDU的入口函数,在这个EDU执行时,会不断的检查客户端到来的tcp连接,如果建立了连接,就启动一个Agent类型的EDU来处理这个连接。在pmdAgent.cpp中实现了Agent这个类型的EDU的入口函数。其主要代码如下:
SOCKET s = *(( SOCKET *) &arg ) ;
pmdLocalSession localSession( s ) ;
localSession.attach( cb ) ;
if ( pmdGetDBRole() == SDB_ROLE_COORD )
{
pmdCoordProcessor coordProcessor ;
localSession.attachProcessor( &coordProcessor ) ;
rc = localSession.run() ;
localSession.detachProcessor() ;
}
else
{
pmdDataProcessor dataProcessor ;
localSession.attachProcessor( &dataProcessor ) ;
rc = localSession.run() ;
localSession.detachProcessor() ;
}
localSession.detach() ;根据当前启动的数据库引擎的角色,是协调节点还是数据节点,分别交由pmdCoordProcessor和pmdDataProcessor来处理。在pmdSession中实现了对socket上来的信息进行处理和转换,提取消息头,并且封装成后续模块能够处理的消息,如果不对通信协议细节感兴趣,其消息的处理过程和定义可以略过,看pmdProcessor即可。在processMsg中可以看到,在processMsg函数中,根据消息类型不同,转而让各种对应的函数处理,我们现在感兴趣的是_onQueryReqMsg函数,接着往下跟。
对于一个查询请求,需要提取的是集合名,返回数量,查询条件,返回字段,排序等信息,通过msgExtractQuery函数对请求中的相关信息进行提取:
rc = msgExtractQuery ( (CHAR *)msg, &flags, &pCollectionName,
&numToSkip, &numToReturn, &pQueryBuff,
&pFieldSelector, &pOrderByBuffer, &pHintBuffer ) ;随后封装为对应的BSON对象,交给rtnQuery执行:
BSONObj matcher ( pQueryBuff ) ;
BSONObj selector ( pFieldSelector ) ;
BSONObj orderBy ( pOrderByBuffer ) ;
BSONObj hint ( pHintBuffer ) ;
// 省略部分代码
rc = rtnQuery( pCollectionName, selector, matcher, orderBy,
hint, flags, eduCB(), numToSkip, numToReturn,
_pDMSCB, _pRTNCB, contextID, &pContext, TRUE ) ;在rtnQuery中,根据需要查找的结果集的名字查找其存储的块的位置,最后建立对应的上下文环境:
rc = rtnResolveCollectionNameAndLock ( pCollectionName, dmsCB, &su,
&pCollectionShortName, suID ) ;//找到结果集对应的存储块
rc = su->data()->getMBContext( &mbContext, pCollectionShortName, -1 ) ;
rc = rtnCB->contextNew ( ( flags & FLG_QUERY_PARALLED ) ?
RTN_CONTEXT_PARADATA : RTN_CONTEXT_DATA,
(rtnContext**)&dataContext, contextID, cb ) ;然后根据是否需要排序,调用dataContext的open方法,见rtnContext.cpp中的_rtnContextData::open的代码。根据查询的条件,如果有索引则使用索引扫描,如果没有则使用表扫描。然后落实在_openTBScan和_openIXScan两个函数的实现之上。以表扫描为例,会把表所涉及的分区块的id号dmsExtendID找到并存储在这个dataContext中;最后调用此dataContext->getMore方法读取所需的数据。
根据前面整理出来的模块关系,搞清楚了EDU和CB这两个核心概念,基本上循着所需要探索的功能特性一步步把每个模块的代码搞清楚,SequoiaDB的内部世界也就毫无保留的展现出来了。从源码中学习大牛的思想,进而提高自己的能力,也许这就是开源的魅力吧!















 134
134











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









