







最近一直在研究solr的源码,主要是标准分词源码分析:
solr底层是使用的是Lucene,标准分词的问题其实 也是lucene的底层的问题。
闲话不多说,最近在项目中遇到各种与公司业务相悖的问题,开始使用solr6.3配置一个单机的solr,分词用的是目前国内比较流行的ik分词器,分词速度和索引速度,也比较可以,但是在搜索的时候遇到了很多问题,也是分词造成的问题,其中包括:搜索漏词、漏新闻、关键字新增的问题,最后考虑到公司没有目前词库量没有那么大,而且公司搜索那块业务,是不断更新新词,所以决定采用一元分词,(标准分词),用标准分词的确满足了公司的搜索业务,但是不用考虑新增关键字,搜索中词量不足造成的影响。
但是在搜索时 却还是有一些问题,比如用标准分词,搜索“国美” 结果会匹配出 “国,美”这类信息,搜索会出现误差,一些特殊符号,也不能搜索分词 如“C++、C#”,因此我下载solr的源码 ,准备对分词这块源码进行一些调整,适合于我们业务 。
solr源码包 本身不是 一个java项目,是一个 基于ant的文件,需要下载 ant工具,这个 可以百度自己安装,安装成功后,还需要一个ivy插件,具体操作百度;简单的一些配置。然后打成源码包,导入eclipse中,就可以随心所欲的研究源码了。
开始 分析源码》》》
solr的标准分词源码入口都是一个 StandardTokenizerFactory 的类;solr在建立索引和搜索的时候需要拆分它们、并做一些相应的处理(比如英文要去掉介词、转成小写、单词原形化等,中文要恰当地要分词)。这些工作,一般由Analyzers、Tokenizers、和Filter来实现。这三个都是在配置在fieldType中。
ananlyzer:告诉solr在建立索引和搜索的时候,如何处理text类型的内容,比如要不要去掉“a”、去掉介词、去掉复数,要不要全部变成小写等等。。。它在managed-schema文件中配置,可以直接指定一个类给它;也可以由tokenizer和filter的组合来实现:
- type:可选参数,index或query,表名这个配置是在建立索引还是在搜索的时候使用
- tokenizer:分词器,比如:StandardTokenizerFactory
- filter:过滤器,比如:LowerCaseFilterFactory,小写转换
- Analyzer负责把文本field转成token流,然后自己处理、或调用Tokenzier和Filter进一步处理,Tokenizer和Filter是同等级和顺序执行的关系,一个处理完后交给下一个处理代码如下:
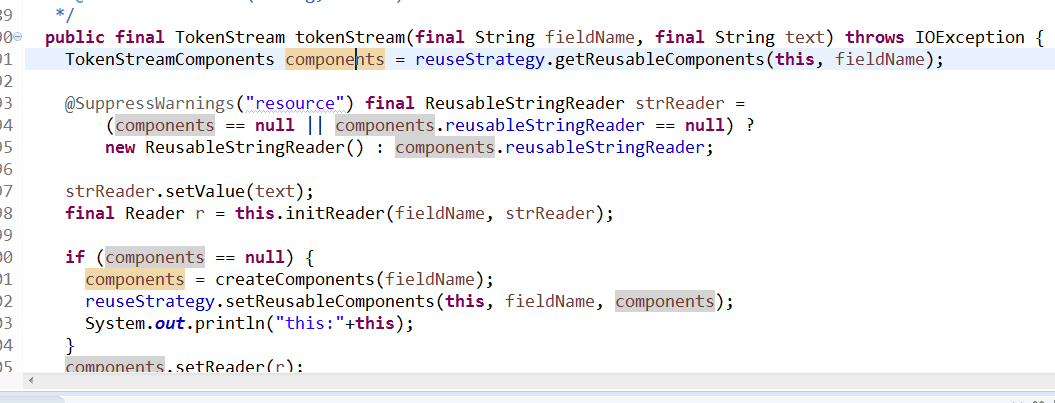
- 再通过filter过滤大小写、同义词、和数字等操作。
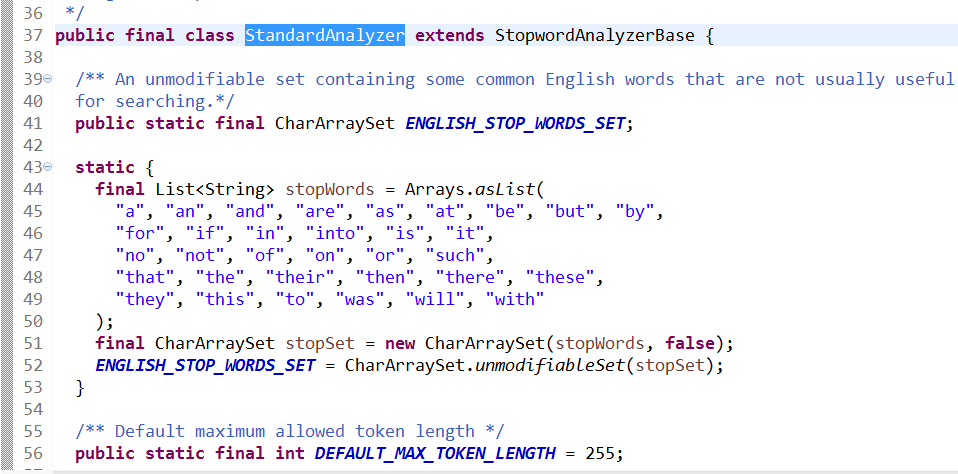
上面代码是,停用词相关的操作
Tokenizer和Filter的区别:
- Tokenizer:接收text(通过从solr那里获得一个reader来读取文本),拆分成tokens,输出token stream
- Filter:接收token stream,对每个token进行处理(比如:替换、丢弃、不理),输出token stream
因此,在配置文件中,Tokenizer放在第一位,Filter放在第二位直到最后一位。
- token:标记、记号,solr中被用来索引或搜索的最小元素,比如英文单词的原形、中文的词语。tokenize:分词,tokenizer:分词器。
- stem:词干,EnglishPorterFilterFactory负责把单词还原成词干,比如:hugs, hugging, hugged -> hug。
- 最后重点:修改分词器让分词适合我们自己的业务
package org.apache.lucene.analysis.standard.StandardTokenizerImpl.java Java文件753行的位置添加判断如果输入的字符(zzInput)为- ,就将zzNext (The transition table of the DFA)值设置为2,”-“在(ASCII 表)十进制的值为:45 详情参考下图
if(zzInput==45) {
zzNext = 2} 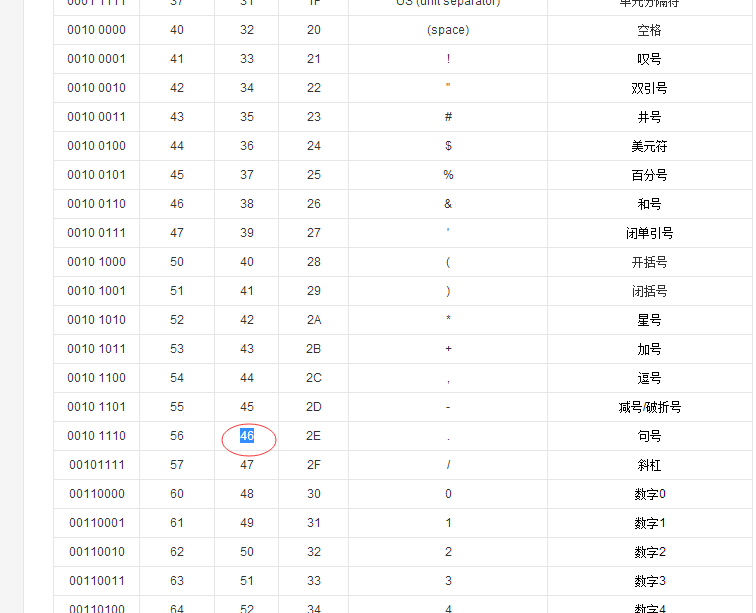
solr源码位置在
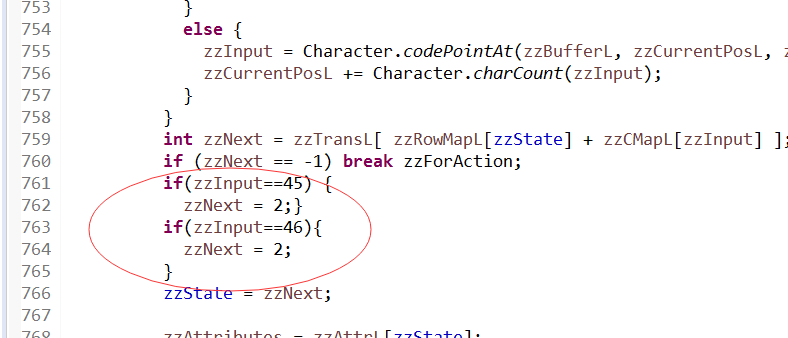
这样就能让solr分词,分出特殊字符
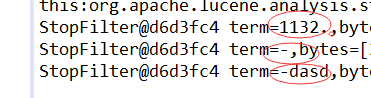
分词结果如下:















 3079
3079

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









