







以上篇博客的项目为例。找到MapReduceTest类中的main方法。如下
public static void main(String[] args) throws Exception {
String[] args2=new String[2];
args2[0]="hdfs://192.168.1.55:9000/test2-in/singlemaptest.log";
args2[1]="hdfs://192.168.1.55:9000/test2-out";
int res=ToolRunner.run(new Configuration(), new MapReduceTest(), args2);
System.exit(res);
}删除args2,并将所有args2改为args,如下:
public static void main(String[] args) throws Exception {
//String[] args2=new String[2];
//args2[0]="hdfs://192.168.1.55:9000/test2-in/singlemaptest.log";
//args2[1]="hdfs://192.168.1.55:9000/test2-out";
//int res=ToolRunner.run(new Configuration(), new MapReduceTest(), args2);
int res=ToolRunner.run(new Configuration(), new MapReduceTest(), args);
System.exit(res);
}保存后在项目上右键,选择Export,在弹出的对话框中找到jar file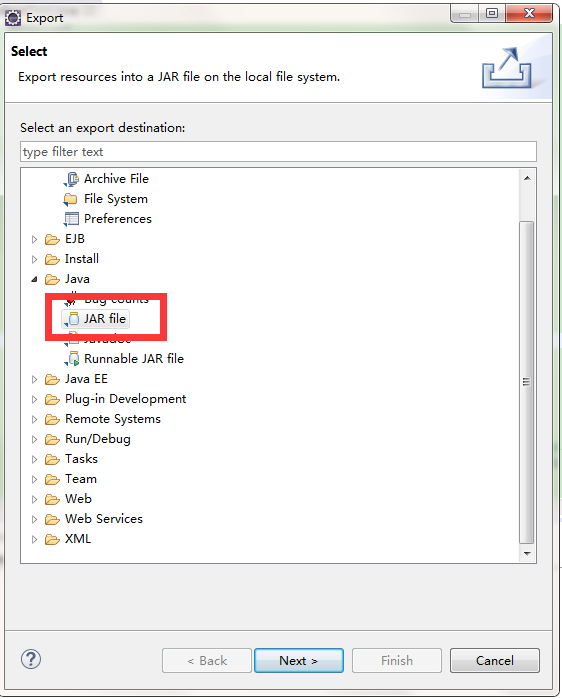
点击next,在jar file里写上导出的路径和文件名

点击next,使用默认选择,再点击next,在最下面的Main class处选择项目里的MapReduceTest

再点击finish,完成!
测试:
1、打开安装hadoop的机器,将刚才打包的文件复制上去。然后找到hadoop的文件夹,在根路径下建立一个文件名称为mylib,然后将刚才复制的jar拷贝进去。
2、打开命令行,切换到hadoop目录下,输入一下命令(如果test2-out已存在请先删除)
bin/hadoop jar mylib/loglevecount.jar mapreducetest.MapReduceTest /test2-in/singlemaptest.log /test2-out注意从命令行调用和在Eclipse下调用不同,命令行会传三个参数,所哟输入目录和输出目录是在参数数组的第二和第三位置,需要修改源码中的run方法,如下:
//设置日志文件路径(hdfs路径)
FileInputFormat.setInputPaths(job, new Path(arg0[1]));
//设置结果输出路径(hdfs路径)
FileOutputFormat.setOutputPath(job, new Path(arg0[2]));下面是运行效果:
[hadoop@h1 hadoop-2.6.0]$ bin/hadoop jar mylib/loglevecount.jar mapreducetest.MapReduceTest /test1-in/singlemaptest.log /test2-out
/test1-in/singlemaptest.log
/test2-out
15/05/27 17:19:59 INFO Configuration.deprecation: session.id is deprecated. Instead, use dfs.metrics.session-id
15/05/27 17:19:59 INFO jvm.JvmMetrics: Initializing JVM Metrics with processName=JobTracker, sessionId=
15/05/27 17:19:59 INFO input.FileInputFormat: Total input paths to process : 1
15/05/27 17:19:59 INFO mapreduce.JobSubmitter: number of splits:1
15/05/27 17:20:00 INFO mapreduce.JobSubmitter: Submitting tokens for job: job_local602619796_0001
15/05/27 17:20:00 INFO mapreduce.Job: The url to track the job: http://localhost:8080/
15/05/27 17:20:00 INFO mapreduce.Job: Running job: job_local602619796_0001
15/05/27 17:20:00 INFO mapred.LocalJobRunner: OutputCommitter set in config null
15/05/27 17:20:00 INFO mapred.LocalJobRunner: OutputCommitter is org.apache.hadoop.mapreduce.lib.output.FileOutputCommitter
15/05/27 17:20:00 INFO mapred.LocalJobRunner: Waiting for map tasks
15/05/27 17:20:00 INFO mapred.LocalJobRunner: Starting task: attempt_local602619796_0001_m_000000_0
15/05/27 17:20:00 INFO mapred.Task: Using ResourceCalculatorProcessTree : [ ]
15/05/27 17:20:00 INFO mapred.MapTask: Processing split: hdfs://192.168.1.55:9000/test1-in/singlemaptest.log:0+827505
15/05/27 17:20:00 INFO mapred.MapTask: (EQUATOR) 0 kvi 26214396(104857584)
15/05/27 17:20:00 INFO mapred.MapTask: mapreduce.task.io.sort.mb: 100
15/05/27 17:20:00 INFO mapred.MapTask: soft limit at 83886080
15/05/27 17:20:00 INFO mapred.MapTask: bufstart = 0; bufvoid = 104857600
15/05/27 17:20:00 INFO mapred.MapTask: kvstart = 26214396; length = 6553600
15/05/27 17:20:00 INFO mapred.MapTask: Map output collector class = org.apache.hadoop.mapred.MapTask$MapOutputBuffer
15/05/27 17:20:01 INFO mapred.LocalJobRunner:
15/05/27 17:20:01 INFO mapred.MapTask: Starting flush of map output
15/05/27 17:20:01 INFO mapred.MapTask: Spilling map output
15/05/27 17:20:01 INFO mapred.MapTask: bufstart = 0; bufend = 38550; bufvoid = 104857600
15/05/27 17:20:01 INFO mapred.MapTask: kvstart = 26214396(104857584); kvend = 26198980(104795920); length = 15417/6553600
15/05/27 17:20:01 INFO mapred.MapTask: Finished spill 0
15/05/27 17:20:01 INFO mapred.Task: Task:attempt_local602619796_0001_m_000000_0 is done. And is in the process of committing
15/05/27 17:20:01 INFO mapred.LocalJobRunner: map
15/05/27 17:20:01 INFO mapred.Task: Task 'attempt_local602619796_0001_m_000000_0' done.
15/05/27 17:20:01 INFO mapred.LocalJobRunner: Finishing task: attempt_local602619796_0001_m_000000_0
15/05/27 17:20:01 INFO mapred.LocalJobRunner: map task executor complete.
15/05/27 17:20:01 INFO mapred.LocalJobRunner: Waiting for reduce tasks
15/05/27 17:20:01 INFO mapred.LocalJobRunner: Starting task: attempt_local602619796_0001_r_000000_0
15/05/27 17:20:01 INFO mapred.Task: Using ResourceCalculatorProcessTree : [ ]
15/05/27 17:20:01 INFO mapred.ReduceTask: Using ShuffleConsumerPlugin: org.apache.hadoop.mapreduce.task.reduce.Shuffle@3b65b4e3
15/05/27 17:20:01 INFO reduce.MergeManagerImpl: MergerManager: memoryLimit=333971456, maxSingleShuffleLimit=83492864, mergeThreshold=220421168, ioSortFactor=10, memToMemMergeOutputsThreshold=10
15/05/27 17:20:01 INFO reduce.EventFetcher: attempt_local602619796_0001_r_000000_0 Thread started: EventFetcher for fetching Map Completion Events
15/05/27 17:20:01 INFO reduce.LocalFetcher: localfetcher#1 about to shuffle output of map attempt_local602619796_0001_m_000000_0 decomp: 46262 len: 46266 to MEMORY
15/05/27 17:20:01 INFO reduce.InMemoryMapOutput: Read 46262 bytes from map-output for attempt_local602619796_0001_m_000000_0
15/05/27 17:20:01 INFO reduce.MergeManagerImpl: closeInMemoryFile -> map-output of size: 46262, inMemoryMapOutputs.size() -> 1, commitMemory -> 0, usedMemory ->46262
15/05/27 17:20:01 INFO reduce.EventFetcher: EventFetcher is interrupted.. Returning
15/05/27 17:20:01 INFO mapred.LocalJobRunner: 1 / 1 copied.
15/05/27 17:20:01 INFO reduce.MergeManagerImpl: finalMerge called with 1 in-memory map-outputs and 0 on-disk map-outputs
15/05/27 17:20:01 INFO mapred.Merger: Merging 1 sorted segments
15/05/27 17:20:01 INFO mapred.Merger: Down to the last merge-pass, with 1 segments left of total size: 46255 bytes
15/05/27 17:20:01 INFO reduce.MergeManagerImpl: Merged 1 segments, 46262 bytes to disk to satisfy reduce memory limit
15/05/27 17:20:01 INFO reduce.MergeManagerImpl: Merging 1 files, 46266 bytes from disk
15/05/27 17:20:01 INFO reduce.MergeManagerImpl: Merging 0 segments, 0 bytes from memory into reduce
15/05/27 17:20:01 INFO mapred.Merger: Merging 1 sorted segments
15/05/27 17:20:01 INFO mapred.Merger: Down to the last merge-pass, with 1 segments left of total size: 46255 bytes
15/05/27 17:20:01 INFO mapred.LocalJobRunner: 1 / 1 copied.
15/05/27 17:20:01 INFO Configuration.deprecation: mapred.skip.on is deprecated. Instead, use mapreduce.job.skiprecords
15/05/27 17:20:01 INFO mapred.Task: Task:attempt_local602619796_0001_r_000000_0 is done. And is in the process of committing
15/05/27 17:20:01 INFO mapred.LocalJobRunner: 1 / 1 copied.
15/05/27 17:20:01 INFO mapred.Task: Task attempt_local602619796_0001_r_000000_0 is allowed to commit now
15/05/27 17:20:01 INFO mapreduce.Job: Job job_local602619796_0001 running in uber mode : false
15/05/27 17:20:01 INFO mapreduce.Job: map 100% reduce 0%
15/05/27 17:20:01 INFO output.FileOutputCommitter: Saved output of task 'attempt_local602619796_0001_r_000000_0' to hdfs://192.168.1.55:9000/test2-out/_temporary/0/task_local602619796_0001_r_000000
15/05/27 17:20:01 INFO mapred.LocalJobRunner: reduce > reduce
15/05/27 17:20:01 INFO mapred.Task: Task 'attempt_local602619796_0001_r_000000_0' done.
15/05/27 17:20:01 INFO mapred.LocalJobRunner: Finishing task: attempt_local602619796_0001_r_000000_0
15/05/27 17:20:01 INFO mapred.LocalJobRunner: reduce task executor complete.
15/05/27 17:20:02 INFO mapreduce.Job: map 100% reduce 100%
15/05/27 17:20:02 INFO mapreduce.Job: Job job_local602619796_0001 completed successfully
15/05/27 17:20:02 INFO mapreduce.Job: Counters: 38
File System Counters
FILE: Number of bytes read=105770
FILE: Number of bytes written=655320
FILE: Number of read operations=0
FILE: Number of large read operations=0
FILE: Number of write operations=0
HDFS: Number of bytes read=1655010
HDFS: Number of bytes written=18
HDFS: Number of read operations=13
HDFS: Number of large read operations=0
HDFS: Number of write operations=4
Map-Reduce Framework
Map input records=3855
Map output records=3855
Map output bytes=38550
Map output materialized bytes=46266
Input split bytes=116
Combine input records=0
Combine output records=0
Reduce input groups=2
Reduce shuffle bytes=46266
Reduce input records=3855
Reduce output records=2
Spilled Records=7710
Shuffled Maps =1
Failed Shuffles=0
Merged Map outputs=1
GC time elapsed (ms)=9
CPU time spent (ms)=0
Physical memory (bytes) snapshot=0
Virtual memory (bytes) snapshot=0
Total committed heap usage (bytes)=565182464
Shuffle Errors
BAD_ID=0
CONNECTION=0
IO_ERROR=0
WRONG_LENGTH=0
WRONG_MAP=0
WRONG_REDUCE=0
File Input Format Counters
Bytes Read=827505
File Output Format Counters
Bytes Written=18查看生成的内容
bin/hadoop dfs -cat /test2-out结果如下:
INFO 3800
WARN 55














 1106
1106











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









