







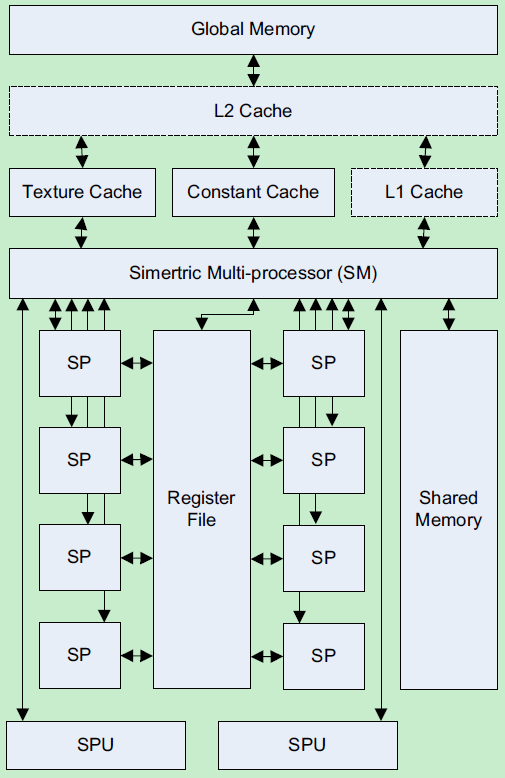
每个 stream processor 就是对应一个 thread
每个 multiprocessor 则对应一个 block
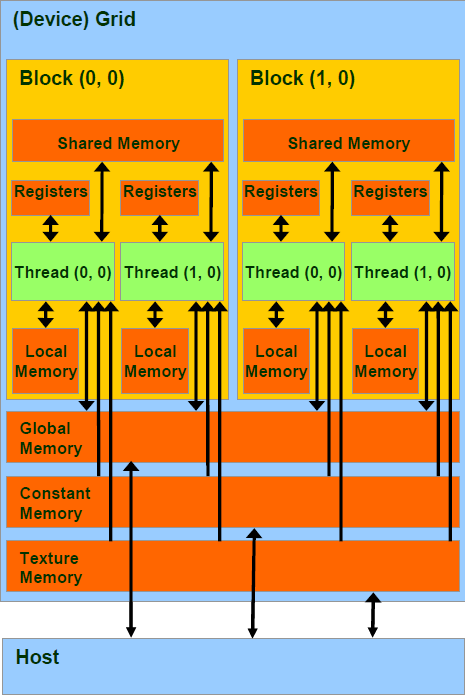
一个kernel程序执行在一个grid of threads blocks之中
Grid在GPU上启动;block被分配到SM上;SM把线程组织为warp;SM调度执行warp;执行结束后释放资源;block继续被分配....
GPU通过Global block scheduler来调度block,根据硬件架构分配block到某一个SM。每个SM最多分配8个block,每个SM最多可接受768个thread
Block是独立执行的,每个Block内的threads是可协同的。
每个线程由SM中的一个SP执行,每一瞬时,只有一组warp在SM中执行。Warp全部线程是执行同一个指令,每个指令需要4个clock cycle,通过复杂的机制执行
最小单元称为Streaming Processor(SP), 包含两个ALU和一个FPU,多组寄存器文件(register file,很多寄存器的组合),没有cache
一个 stream processor 基本上是一个浮点数的 fused multiply-add 单元,也就是说它可以进行一次乘法和一次加法,如下所示:
a = b * c + d;
compiler 会自动把适当的加法和乘法运算,结合成一个 fmad 指令
每个 multiprocessor 有 16KB 的 shared memory。Shared memory 分成 16 个 bank。如果同时每个 thread 是存取不同的 bank,就不
会产生任何问题,存取 shared memory 的速度和存取寄存器相同。不过,如果同时有两个(或更多个) threads 存取同一个 bank 的数据,就会
发生 bank conflict,这些 threads 就必须照顺序去存取,而无法同时存取 shared memory 了。
每个 stream processor 包含8个SP,2个special function unit(SFU,里面有4个FPU可以进行超越函数和插值计算), MultiThreading Issue Unit(MTIU分发线程指令)
每个 multiprocessor 有八个 stream processor,但是由于 stream processor 进行各种运算都有 latency,更不用提内存存取的 latency,
因此 CUDA 在执行程序的时候,是以 warp 为单位。目前的 CUDA 装置,一个 warp 里面有 32 个 threads,分成两组 16 threads 的 half-warp。
于 stream processor 的运算至少有 4 cycles 的 latency,因此对一个 4D 的 stream processors 来说,一次至少执行 16 个 threads(即
half-warp)才能有效隐藏各种运算的 latency















 2万+
2万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









