







1. 监控io性能
iostat命令被用于监视系统输入输出设备和CPU的使用情况。它的特点是汇报磁盘活动统计情况,同时也会汇报出CPU使用情况。同vmstat一样,iostat也有一个弱点,就是它不能对某个进程进行深入分析,仅对系统的整体情况进行分析。
iostat和sar属于同一个包sysstat。iostat和sar –b命令效果差不多。
语法
iostat(选项)(参数)
选项
-c:仅显示CPU使用情况; -d:仅显示设备利用率; -k:显示状态以千字节每秒为单位,而不使用块每秒; -m:显示状态以兆字节每秒为单位; -p:仅显示块设备和所有被使用的其他分区的状态; -t:显示每个报告产生时的时间; -V:显示版号并退出; -x:显示扩展状态。
参数
- 间隔时间:每次报告的间隔时间(秒);
- 次数:显示报告的次数。
实例
用iostat -x /dev/sda1来观看磁盘I/O的详细情况:
iostat -x /dev/sda1 Linux 2.6.18-164.el5xen (localhost.localdomain) 2010年03月26日 avg-cpu: %user %nice %system %iowait %steal %idle 0.11 0.02 0.18 0.35 0.03 99.31 Device: tps Blk_read/s Blk_wrtn/s Blk_read Blk_wrtn sda1 0.02 0.08 0.00 2014 4
详细说明:第二行是系统信息和监测时间,第三行和第四行显示CPU使用情况(具体内容和mpstat命令相同)。这里主要关注后面I/O输出的信息,如下所示:
| 标示 | 说明 |
|---|---|
| Device | 监测设备名称 |
| rrqm/s | 每秒需要读取需求的数量 |
| wrqm/s | 每秒需要写入需求的数量 |
| r/s | 每秒实际读取需求的数量 |
| w/s | 每秒实际写入需求的数量 |
| rsec/s | 每秒读取区段的数量 |
| wsec/s | 每秒写入区段的数量 |
| rkB/s | 每秒实际读取的大小,单位为KB |
| wkB/s | 每秒实际写入的大小,单位为KB |
| avgrq-sz | 需求的平均大小区段 |
| avgqu-sz | 需求的平均队列长度 |
| await | 等待I/O平均的时间(milliseconds) |
| svctm | I/O需求完成的平均时间 |
| %util | 被I/O需求消耗的CPU百分比 |
- iostat -x
说明: util%:表示io等待占比,正常情况下该值和磁盘读写(r/w)成正比,如果该值很大,读写数值很小则说明磁盘存在问题,系统性能会受影响!
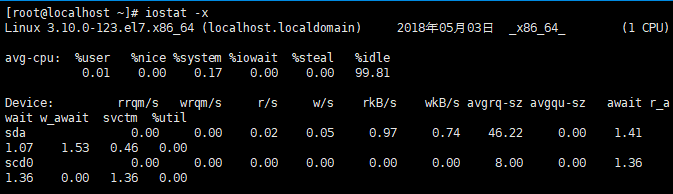
rrqm/s:每秒这个设备相关的读取请求有多少被Merge了(当系统调用需要读取数据的时候,VFS将请求发到各个FS,如果FS发现不同的读取请求读取的是相同Block的数据,FS会将这个请求合并Merge);wrqm/s:每秒这个设备相关的写入请求有多少被Merge了。
r/s:每秒完成的读 I/O 设备次数。即 delta(rio)/s
w/s:每秒完成的写 I/O 设备次数。即 delta(wio)/s
rsec/s:每秒读取的扇区数;
wsec/:每秒写入的扇区数。
rkB/s: 每秒读K字节数。是 rsect/s 的一半,因为每扇区大小为512字节。(需要计算)
wkB/s:每秒写K字节数。是 wsect/s 的一半。(需要计算)
avgrq-sz: 平均每次设备I/O操作的数据大小 (扇区)。delta(rsect+wsect)/delta(rio+wio)
avgqu-sz: 平均I/O队列长度。即 delta(aveq)/s/1000 (因为aveq的单位为毫秒)。毫无疑问,队列长度越短越好。
也就是说,一般情况下,await大于svctm,它们的差值越小,则说明队列时间越短,反之差值越大,队列时间越长,说明系统出了问题。
。一般地,如果该参数是100%表示设备已经接近满负荷运行了(当然如果是多磁盘,即使%util是100%,因为磁盘的并发能力,所以磁盘使用未必就到了瓶颈。
常用命令
iostat -d -k 2参数 -d 表示,显示设备(磁盘)使用状态;-k某些使用block为单位的列强制使用Kilobytes为单位;2表示,数据显示每隔2秒刷新一次。
kB_wrtn: 写入的总数量数据量;这些单位都为Kilobytes。
iostat -d -k 1 10 #查看TPS和吞吐量信息(磁盘读写速度单位为KB)
iostat -d -m 2 #查看TPS和吞吐量信息(磁盘读写速度单位为MB)
iostat -d -x -k 1 10 #查看设备使用率(%util)、响应时间(await) iostat -c 1 10 #查看cpu状态
yum安装, yum install iotop
- iostat,从proc中获取thread的IO信息,进行汇总。
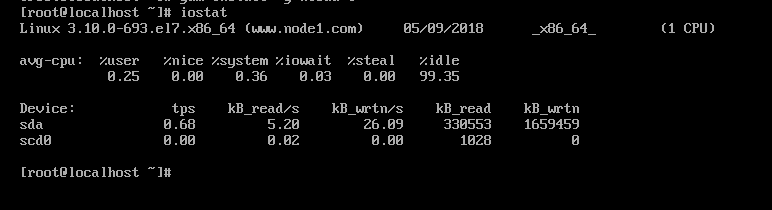
tps:该设备每秒的传输次数(Indicate the number of transfers per second that were issued to the device.)。"一次传输"意思是"一次I/O请求"。多个逻辑请求可能会被合并为"一次I/O请求"。"一次传输"请求的大小是未知的。
kB_read/s:每秒从设备(drive expressed)读取的数据量;
kB_wrtn/s:每秒向设备(drive expressed)写入的数据量;
kB_read:读取的总数据量;
实例:
iostat -x #磁盘使用
iotop磁盘使用
iostat命令和sar在同一个包里,使用iostat,需要安装sysstat,命令:yum install sysstat
- iostat #监视系统输入输出设备和CPU的使用情况
- ifstat #统计网络接口流量状态
- dstat #通用的系统资源统计工具
- iotop #用来监视磁盘I/O使用状况的工具
- mpstat # 显示各个可用CPU的状态
2.iotop命令
用来监视磁盘I/O使用状况的top类工具,查看其中包括PID、用户、I/O、进程等相关信息。Linux下的IO统计工具如iostat,nmon等大多数是只能统计到per设备的读写情况,如果你想知道每个进程是如何使用IO的就比较麻烦,使用iotop命令可以很方便的查看。查看每个进程是如何使用IO的。
安装
Ubuntu
apt-get install iotop
CentOS
yum install iotop
编译安装
wget http://guichaz.free.fr/iotop/files/iotop-0.4.4.tar.gz tar zxf iotop-0.4.4.tar.gz python setup.py build python setup.py install
语法
iotop(选项)
选项
-o:只显示有io操作的进程
-b:批量显示,无交互,主要用作记录到文件。
-n NUM:显示NUM次,主要用于非交互式模式。
-d SEC:间隔SEC秒显示一次。
-p PID:监控的进程pid。
-u USER:监控的进程用户。
iotop常用快捷键:
- 左右箭头:改变排序方式,默认是按IO排序。
- r:改变排序顺序。
- o:只显示有IO输出的进程。
- p:进程/线程的显示方式的切换。
- a:显示累积使用量。
- q:退出。
实例
直接执行iotop就可以看到效果了:
Total DISK read: 0.00 B/s | Total DISK write: 0.00 B/s TID PRIO USER DISK READ DISK WRITE SWAPIN IO> command 1 be/4 root 0.00 B/s 0.00 B/s 0.00 % 0.00 % init [3] 2 be/4 root 0.00 B/s 0.00 B/s 0.00 % 0.00 % [kthreadd] 3 rt/4 root 0.00 B/s 0.00 B/s 0.00 % 0.00 % [migration/0] 4 be/4 root 0.00 B/s 0.00 B/s 0.00 % 0.00 % [ksoftirqd/0] 5 rt/4 root 0.00 B/s 0.00 B/s 0.00 % 0.00 % [watchdog/0] 6 rt/4 root 0.00 B/s 0.00 B/s 0.00 % 0.00 % [migration/1] 7 be/4 root 0.00 B/s 0.00 B/s 0.00 % 0.00 % [ksoftirqd/1] 8 rt/4 root 0.00 B/s 0.00 B/s 0.00 % 0.00 % [watchdog/1] 9 be/4 root 0.00 B/s 0.00 B/s 0.00 % 0.00 % [events/0] 10 be/4 root 0.00 B/s 0.00 B/s 0.00 % 0.00 % [events/1] 11 be/4 root 0.00 B/s 0.00 B/s 0.00 % 0.00 % [khelper] 2572 be/4 root 0.00 B/s 0.00 B/s 0.00 % 0.00 % [bluetooth]
注: 在此关注‘IO>’这一列!
iotop常用快捷键
- 左右箭头:改变排序方式,默认是按IO排序
- r:改变排序顺序。
- o:只显示有IO输出的进程。
- p:进程/线程的显示方式的切换。
- a:显示累积使用量。
- q:退出。
3. free命令
free命令可以显示当前系统未使用的和已使用的内存数目,还可以显示被内核使用的内存缓冲区。
语法: free [options]
Options:
-b/k/m/g:分别以byte、KB、M、G为单位显示(默认以KB为单位)
-h:已适当的单位显示
-t:显示内存总和
free #查看内存使用情况
free -m / -g / -h #常用的命令
buffer /cacha区别
公式 : total=used + free +buff/cache
avaliable包含free和buffer/cache剩下部分。
buff(缓冲):当CPU向磁盘写入数据时,由于磁盘存储速率低于CPU,所以CPU工作时先将写好的数据存放在内存中,该部分内存即为缓冲内存。
cache(缓存):当CPU从磁盘读取数据时,由于磁盘输出速率低于CPU的读取速度,所以磁盘的数据会预先存放在内存中,该部分内存即为缓存内存。
MySQL数据库慢,是因为磁盘转速慢。4/6 raid 10又安全又快。
查看内存使用剩余时:查看的是swap交互分区的使用情况。swap不够说明内存不够了。
()数据流向:
0000(读取数据磁盘) --->内存(cache)-->cpu #cache
cpu(0000(计算完的数据)) -->内存(buffer)-->磁盘 #buffer
free命令可以显示当前系统未使用的和已使用的内存数目,还可以显示被内核使用的内存缓冲区。
语法
free(选项)
选项
-b:以Byte为单位显示内存使用情况; -k:以KB为单位显示内存使用情况; -m:以MB为单位显示内存使用情况; -h:在具体的后面添加单位; -o:不显示缓冲区调节列; -s<间隔秒数>:持续观察内存使用状况; -t:显示内存总和列; -V:显示版本信息。
实例
使用free,查看使用情况

在具体的后面添加单位:兆

指定单位M兆,显示。
free -m
total used free shared buffers cached
Mem: 2016 1973 42 0 163 1497
-/+ buffers/cache: 312 1703
Swap: 4094 0 4094
第一部分Mem行解释:
total:内存总数; used:已经使用的内存数; free:空闲的内存数; shared:当前已经废弃不用; buffers Buffer:缓存内存数; cached Page:缓存内存数。
关系:total = used + free
第二部分(-/+ buffers/cache)解释:
(-buffers/cache) used内存数:第一部分Mem行中的 used – buffers – cached (+buffers/cache) free内存数: 第一部分Mem行中的 free + buffers + cached
可见-buffers/cache反映的是被程序实实在在吃掉的内存,而+buffers/cache反映的是可以挪用的内存总数。
第三部分是指交换分区。
4. ps命令
ps命令用于报告当前系统的进程状态。可以搭配kill指令随时中断、删除不必要的程序。ps命令是最基本同时也是非常强大的进程查看命令,使用该命令可以确定有哪些进程正在运行和运行的状态、进程是否结束、进程有没有僵死、哪些进程占用了过多的资源等等,总之大部分信息都是可以通过执行该命令得到的。
用法
语法: ps [options]
Options:
a:显示现行终端机下的所有程序,包括其他用户的程序。
u:以用户为主的格式来显示系统状况。
x:显示所有程序,包括历史进程。
-e:显示所有进程(同a)
-f:显示UID、PPIP、C与STIME栏
-l:显示进程详细信息
线程和进程的区别是什么呢?
最大的区别就是:
1 进程里包含了线程,线程是进程的子单元
2 同一个进程下的线程全部共享相同的内存,而进程之间内存相互隔离。
ps 查看系统进程
用法:ps aux、ps -elf
进程的状态:
STAT部分说明
- D 不能中断的进程
- R run状态的进程
- S sleep状态的进程
- T 暂停的进程
- Z 僵尸进程
- < 高优先级进程
- N 低优先级进程
- L 内存中被锁了内存分页
- s 主进程(master process)
- l 多线程进程
- + 前台进程
注意:(root启动)主进程(master process)子进程(worker process)
语法
ps(选项)
选项
-a:显示所有终端机下执行的程序,除了阶段作业领导者之外。 a:显示现行终端机下的所有程序,包括其他用户的程序。 -A:显示所有程序。 -c:显示CLS和PRI栏位。 c:列出程序时,显示每个程序真正的指令名称,而不包含路径,选项或常驻服务的标示。 -C<指令名称>:指定执行指令的名称,并列出该指令的程序的状况。 -d:显示所有程序,但不包括阶段作业领导者的程序。 -e:此选项的效果和指定"A"选项相同。 e:列出程序时,显示每个程序所使用的环境变量。 -f:显示UID,PPIP,C与STIME栏位。 f:用ASCII字符显示树状结构,表达程序间的相互关系。 -g<群组名称>:此选项的效果和指定"-G"选项相同,当亦能使用阶段作业领导者的名称来指定。 g:显示现行终端机下的所有程序,包括群组领导者的程序。 -G<群组识别码>:列出属于该群组的程序的状况,也可使用群组名称来指定。 h:不显示标题列。 -H:显示树状结构,表示程序间的相互关系。 -j或j:采用工作控制的格式显示程序状况。 -l或l:采用详细的格式来显示程序状况。 L:列出栏位的相关信息。 -m或m:显示所有的执行绪。 n:以数字来表示USER和WCHAN栏位。 -N:显示所有的程序,除了执行ps指令终端机下的程序之外。 -p<程序识别码>:指定程序识别码,并列出该程序的状况。 p<程序识别码>:此选项的效果和指定"-p"选项相同,只在列表格式方面稍有差异。 r:只列出现行终端机正在执行中的程序。 -s<阶段作业>:指定阶段作业的程序识别码,并列出隶属该阶段作业的程序的状况。 s:采用程序信号的格式显示程序状况。 S:列出程序时,包括已中断的子程序资料。 -t<终端机编号>:指定终端机编号,并列出属于该终端机的程序的状况。 t<终端机编号>:此选项的效果和指定"-t"选项相同,只在列表格式方面稍有差异。 -T:显示现行终端机下的所有程序。 -u<用户识别码>:此选项的效果和指定"-U"选项相同。 u:以用户为主的格式来显示程序状况。 -U<用户识别码>:列出属于该用户的程序的状况,也可使用用户名称来指定。 U<用户名称>:列出属于该用户的程序的状况。 v:采用虚拟内存的格式显示程序状况。 -V或V:显示版本信息。 -w或w:采用宽阔的格式来显示程序状况。 x:显示所有程序,不以终端机来区分。 X:采用旧式的Linux i386登陆格式显示程序状况。 -y:配合选项"-l"使用时,不显示F(flag)栏位,并以RSS栏位取代ADDR栏位 。 -<程序识别码>:此选项的效果和指定"p"选项相同。 --cols<每列字符数>:设置每列的最大字符数。 --columns<每列字符数>:此选项的效果和指定"--cols"选项相同。 --cumulative:此选项的效果和指定"S"选项相同。 --deselect:此选项的效果和指定"-N"选项相同。 --forest:此选项的效果和指定"f"选项相同。 --headers:重复显示标题列。 --help:在线帮助。 --info:显示排错信息。 --lines<显示列数>:设置显示画面的列数。 --no-headers:此选项的效果和指定"h"选项相同,只在列表格式方面稍有差异。 --group<群组名称>:此选项的效果和指定"-G"选项相同。 --Group<群组识别码>:此选项的效果和指定"-G"选项相同。 --pid<程序识别码>:此选项的效果和指定"-p"选项相同。 --rows<显示列数>:此选项的效果和指定"--lines"选项相同。 --sid<阶段作业>:此选项的效果和指定"-s"选项相同。 --tty<终端机编号>:此选项的效果和指定"-t"选项相同。 --user<用户名称>:此选项的效果和指定"-U"选项相同。 --User<用户识别码>:此选项的效果和指定"-U"选项相同。 --version:此选项的效果和指定"-V"选项相同。 --widty<每列字符数>:此选项的效果和指定"-cols"选项相同。
进程/线程
进程
进程(Process)是计算机中的程序关于某数据集合上的一次运行活动,是系统进行资源分配和调度的基本单位,是操作系统结构的基础。在早期面向进程设计的计算机结构中,进程是程序的基本执行实体;在当代面向线程设计的计算机结构中,进程是线程的容器。程序是指令、数据及其组织形式的描述,进程是程序的实体。
状态分类
进程执行时的间断性,决定了进程可能具有多种状态。事实上,运行中的进程可能具有以下三种基本状态:
- 就绪状态(Ready):进程已获得除处理器外的所需资源,等待分配处理器资源;只要分配了处理器进程就可执行。就绪进程可以按多个优先级来划分队列。例如,当一个进程由于时间片用完而进入就绪状态时,排入低优先级队列;当进程由I/O操作完成而进入就绪状态时,排入高优先级队列。
- 运行状态(Running):进程占用处理器资源;处于此状态的进程的数目小于等于处理器的数目。在没有其他进程可以执行时(如所有进程都在阻塞状态),通常会自动执行系统的空闲进程。
- 阻塞状态(Blocked):由于进程等待某种条件(如I/O操作或进程同步),在条件满足之前无法继续执行。该事件发生前即使把处理机分配给该进程,也无法运行。
线程
线程,有时被称为轻量级进程(Lightweight Process,LWP),是程序执行流的最小单元。一个标准的线程由线程ID,当前指令指针(PC),寄存器集合和堆栈组成。另外,线程是进程中的一个实体,是被系统独立调度和分派的基本单位,线程自己不拥有系统资源,只拥有一点儿在运行中必不可少的资源,但它可与同属一个进程的其它线程共享进程所拥有的全部资源。一个线程可以创建和撤消另一个线程,同一进程中的多个线程之间可以并发执行。由于线程之间的相互制约,致使线程在运行中呈现出间断性。线程也有就绪、阻塞和运行三种基本状态。每一个程序都至少有一个线程,若程序只有一个线程,那就是程序本身。
在单个程序中同时运行多个线程完成不同的工作,称为多线程。
分类
- 用户级线程:管理过程全部由用户程序完成,操作系统内核心只对进程进行管理。
- 系统级线程(核心级线程):由操作系统内核进行管理。操作系统内核给应用程序提供相应的系统调用和应用程序接口API,以使用户程序可以创建、执行、撤消线程。
实例:
查看内存使用进程命令:ps(静态查看) aux=top(动态查看)
![]()
查看某一个进程有没有运行,如nginx,mysql。

命令ps elf类似于ls,查看系统的所有进程。
![]()
查看vmstat运行的状态,使用fg调出来,在前台显示+,在后台不显示+号。
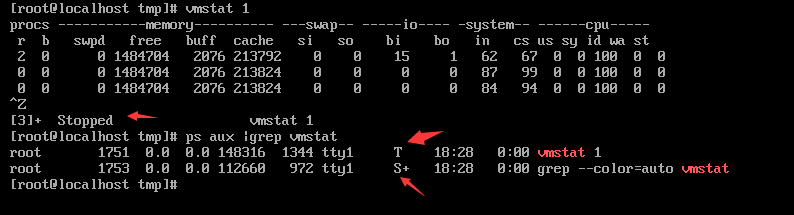
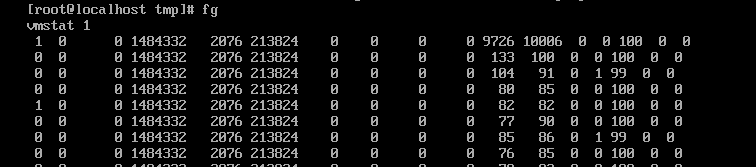
杀死一个110进程命令:kill 110 (PID号)
查看进程在哪里启动的,110是要查看的进程的PID号,使用命令:ls -l /proc/110/
5. 查看网络状态
netstat命令
netstat命令用来打印Linux中网络系统的状态信息,可让你得知整个Linux系统的网络情况。
语法: netstat [options]
Options:
-a:=all 显示所有连线中的socket
-l:=listening 显示监控中的服务器的socket
-n:=numeric 直接使用IP地址
-p:=programs 显示正在使用socket的程序识别码和程序名称
-t:=tcp 显示tcp传输协议的连接状况-p 显示建立相关链接的程序名
-c 每隔一个固定时间,执行该netstat命令。
-r 显示路由信息,路由表
提示:LISTEN和LISTENING的状态只有用-a或者-l才能看到
状态列表:
LISTEN :在监听状态中。
ESTABLISHED:已建立联机的联机情况。
TIME_WAIT:该联机在目前已经是等待的状态。
netstat #查看网络状态
netstat -lnp #查看监听端口
netstat -an #查看系统的网络连接状况
netstat lntp #只看出tcpde ,不包含socket
ss -an和nestat异曲同工
一个小技巧”
netstat -an| awk '/^tcp/ {+ +sta[$NF} END {for(key in sta)print key,"\t",sta[key]}' #查看所有的状态,数字
首先 ^ 是开头的意思,就是说开头是TCP字样的,$NF表示最后一个字段,把它放入数组S中,然后自加,awk是采用的关联数组.END最后用for取出数组中的下标,也就是TCP的几种状态,然后对应该下标的值,就是统计的数量.
参考链接:
http://www.cnblogs.com/lixiaohui-ambition/archive/2012/12/11/2813419.html
http://www.cnblogs.com/chengmo/archive/2010/10/08/1846190.html
语法
netstat(选项)
选项
-a或--all:显示所有连线中的Socket; -A<网络类型>或--<网络类型>:列出该网络类型连线中的相关地址; -c或--continuous:持续列出网络状态; -C或--cache:显示路由器配置的快取信息; -e或--extend:显示网络其他相关信息; -F或--fib:显示FIB; -g或--groups:显示多重广播功能群组组员名单; -h或--help:在线帮助; -i或--interfaces:显示网络界面信息表单; -l或--listening:显示监控中的服务器的Socket; -M或--masquerade:显示伪装的网络连线; -n或--numeric:直接使用ip地址,而不通过域名服务器; -N或--netlink或--symbolic:显示网络硬件外围设备的符号连接名称; -o或--timers:显示计时器; -p或--programs:显示正在使用Socket的程序识别码和程序名称; -r或--route:显示Routing Table; -s或--statistice:显示网络工作信息统计表; -t或--tcp:显示TCP传输协议的连线状况; -u或--udp:显示UDP传输协议的连线状况; -v或--verbose:显示指令执行过程; -V或--version:显示版本信息; -w或--raw:显示RAW传输协议的连线状况; -x或--unix:此参数的效果和指定"-A unix"参数相同; --ip或--inet:此参数的效果和指定"-A inet"参数相同。
实例:
安装过程

命令:netstat -an |awk '/^tcp/ {++sta[$NF]} END {for(key in sta) print key,"\t",sta[key]}'

netstat -ltnp列出来tcp;netstat -ltunp列出来tcp和udq;
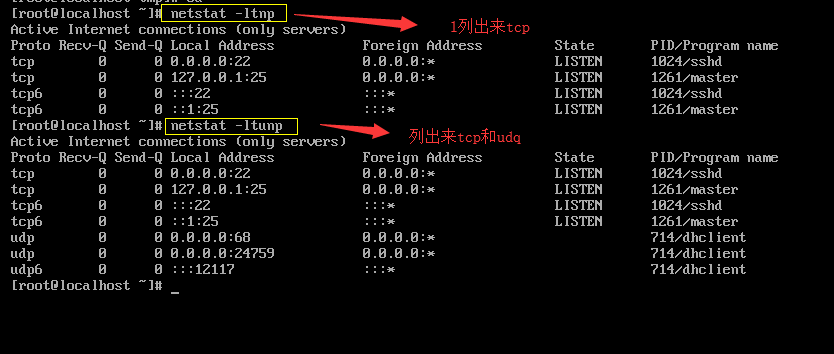
netstat -lnp #查看监听端口

查看listen进程,ss不显示进程的名字。

- netstat -an 查看系统网络连接状况
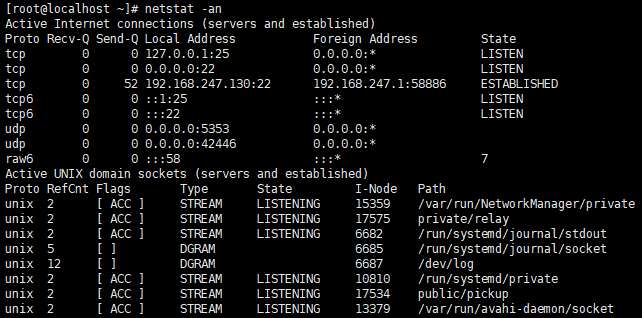
查看tcp协议状态的命令:

列出所有端口 (包括监听和未监听的)
netstat -a #列出所有端口 netstat -at #列出所有tcp端口 netstat -an #列出所有tcp状态 netstat -au #列出所有udp端口
列出所有处于监听状态的 Sockets
netstat -l #只显示监听端口
netstat -lt #只列出所有监听 tcp 端口
netstat -lu #只列出所有监听 udp 端口
netstat -lx #只列出所有监听 UNIX 端口
显示每个协议的统计信息
netstat -s 显示所有端口的统计信息 netstat -st 显示TCP端口的统计信息 netstat -su 显示UDP端口的统计信息
在netstat输出中显示 PID 和进程名称
netstat -pt
netstat -p可以与其它开关一起使用,就可以添加“PID/进程名称”到netstat输出中,这样debugging的时候可以很方便的发现特定端口运行的程序。
在netstat输出中不显示主机,端口和用户名(host, port or user)
当你不想让主机,端口和用户名显示,使用netstat -n。将会使用数字代替那些名称。同样可以加速输出,因为不用进行比对查询。
netstat -an
如果只是不想让这三个名称中的一个被显示,使用以下命令:
netsat -a --numeric-ports netsat -a --numeric-hosts netsat -a --numeric-users
持续输出netstat信息
netstat -c #每隔一秒输出网络信息
显示系统不支持的地址族(Address Families)
netstat --verbose
在输出的末尾,会有如下的信息:
netstat: no support for `AF IPX' on this system. netstat: no support for `AF AX25' on this system. netstat: no support for `AF X25' on this system. netstat: no support for `AF NETROM' on this system.
显示核心路由信息
netstat -r
使用netstat -rn显示数字格式,不查询主机名称。
找出程序运行的端口
并不是所有的进程都能找到,没有权限的会不显示,使用 root 权限查看所有的信息。
netstat -ap | grep ssh
找出运行在指定端口的进程:
netstat -an | grep ':80'
显示网络接口列表
netstat -i
显示详细信息,像是ifconfig使用netstat -ie。
IP和TCP分析
查看连接某服务端口最多的的IP地址:
netstat -ntu | grep :80 | awk '{print $5}' | cut -d: -f1 | awk '{++ip[$1]} END {for(i in ip) print ip[i],"\t",i}' | sort -nr
TCP各种状态列表:
netstat -nt | grep -e 127.0.0.1 -e 0.0.0.0 -e ::: -v | awk '/^tcp/ {++state[$NF]} END {for(i in state) print i,"\t",state[i]}'
查看phpcgi进程数,如果接近预设值,说明不够用,需要增加:
netstat -anpo | grep "php-cgi" | wc -l
ss命令
ss命令用来显示处于活动状态的套接字信息。ss命令可以用来获取socket统计信息,它可以显示和netstat类似的内容。但ss的优势在于它能够显示更多更详细的有关TCP和连接状态的信息,而且比netstat更快速更高效,缺点是不会显示进程的名称。
语法: ss [options]
Options:
-a:显示所有套接字(socket)
-n:不解析服务器名称,以数字方式显示
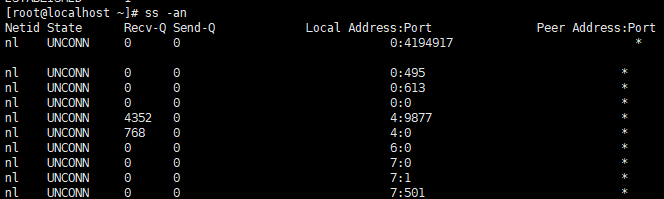
常见问题:
1.ESTABLISHED能接收1000范围以内的数值,跟cpu的核数和内存有关联么?
答案:这个数值的大小取决于很多因素。
比如,服务器仅仅是lvs调度器,那established数值就算10000也不是问题,因为即使连接数再多也不会对调度器造成多大影响。
反而,如果是httpd或者php-fpm,这个数值很大,说明访问量很大,那也就意味着php的处理比较繁忙,自然会对机器造成影响。
那归根到底就是跟服务器作用于哪方面有关了?1000数值只是取的所有服务的中间值了?
2.netstat -an |awk `/^tcp/ {++sta[$NF]} END {for(key in sta) print key,"\t",sta[key]}`
怎么敲了 显示不出来?单引号的问题
3.没有显示swap?,因为阿里云没有swap.

笔记网址:
6. linux下抓包
tcpdump命令
tcpdump命令是一款sniffer工具,它可以打印所有经过网络接口的数据包的头信息,也可以使用-w选项将数据包保存到文件中,方便以后分析。
语法: tcpdump [options]
Options:
-i:指定网卡名,使用指定的网络送出数据包
-c:指定数量
-w:指定存放位置
-r:=read,从指定文件查看数据包数据
用法
- tcpdump -nn -i ens33 (第一个n表示以数字形式显示IP,如果不加该选项会显示成主机名)
- tcpdump -nn ens33 port 22 (not port 22)指定端口为22的(非22的)
- tcpdump -nn ens33 port 22 and host 192.168.8.1 指定多个条件(host:主机,后面跟主机名或IP)
- tcpdump -nn -i ens33 -c 10 -w /tmp/1.cap 指定抓包数量和存放位置
安装tcpdump命令:yum install -y tcpdump
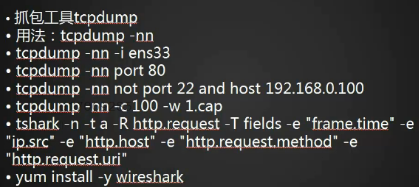
抓包工具tcpdump
用法:tcpdump -nn #显示IP;第一个ip表示以数字的形式显示出来
tcpdump -nn -i ens33 #显示IP地址和端口号
tcpdump -nn port 80 #查看指定端口80的,显示出来。
tcpdump -nn not port 22 and host 192.168..0.100 #查看指定端口22的,指定网段192.168..0.100的包
tcpdump -nn -c 100 -w 1.cap #指定数据包,只抓一百个。存在 1.cap 中去
tshark -n -t a -R http.request -T fields -e "frame.time"-e "ip.src" -e "http.host" -e "http.request.method" -e #在80 端口监听,查看时间,IP,访问的域,链接。
yum install -y wireshark #安装wireshark抓包,使用tshark命令前安装。
tcpdump命令是一款sniffer工具,它可以打印所有经过网络接口的数据包的头信息,也可以使用-w选项将数据包保存到文件中,方便以后分析。
语法
tcpdump(选项)
选项
-a:尝试将网络和广播地址转换成名称; -c<数据包数目>:收到指定的数据包数目后,就停止进行倾倒操作; -d:把编译过的数据包编码转换成可阅读的格式,并倾倒到标准输出; -dd:把编译过的数据包编码转换成C语言的格式,并倾倒到标准输出; -ddd:把编译过的数据包编码转换成十进制数字的格式,并倾倒到标准输出; -e:在每列倾倒资料上显示连接层级的文件头; -f:用数字显示网际网络地址; -F<表达文件>:指定内含表达方式的文件; -i<网络界面>:使用指定的网络截面送出数据包; -l:使用标准输出列的缓冲区; -n:不把主机的网络地址转换成名字; -N:不列出域名; -O:不将数据包编码最佳化; -p:不让网络界面进入混杂模式; -q :快速输出,仅列出少数的传输协议信息; -r<数据包文件>:从指定的文件读取数据包数据; -s<数据包大小>:设置每个数据包的大小; -S:用绝对而非相对数值列出TCP关联数; -t:在每列倾倒资料上不显示时间戳记; -tt: 在每列倾倒资料上显示未经格式化的时间戳记; -T<数据包类型>:强制将表达方式所指定的数据包转译成设置的数据包类型; -v:详细显示指令执行过程; -vv:更详细显示指令执行过程; -x:用十六进制字码列出数据包资料; -w<数据包文件>:把数据包数据写入指定的文件。
实例
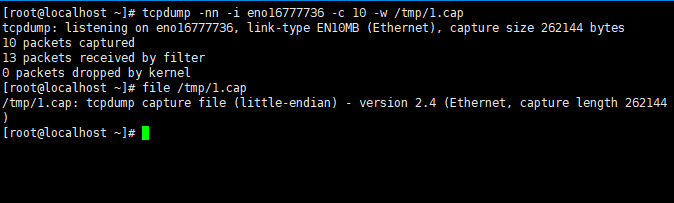
注: 1.cap内容无法使用cat命令查看,可使用tcpdump -r命令查看
tcpdump -r 1.cap 查看指定数据包内容
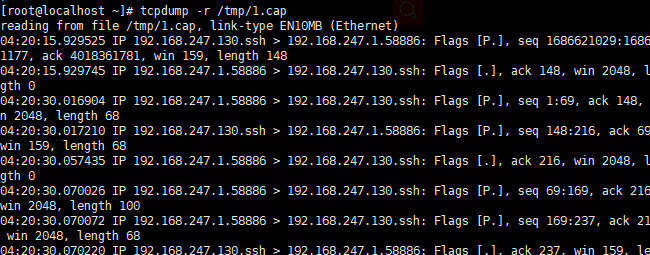
说明: 包内内容为使用tcpdump打包时的数据。
tcpdump -nn -i ens33 #显示IP地址和端口号;指定一下具体的网卡名字。用-i选项。
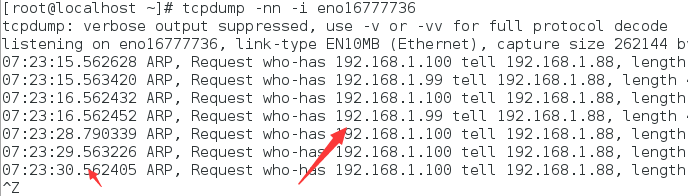
tcpdump -nn en0 显示线上的服务器
![]()
指定端口查找。
![]()
eth0网段,不是端口22的,包是192.168.168.0的,指定的
![]()
读取数据流,指定文件的1.cap,命令:tcpdump -r /tmp/1.cat。。。-w写入的是包。

直接启动tcpdump将监视第一个网络接口上所有流过的数据包
tcpdump
监视指定网络接口的数据包
tcpdump -i eth1
如果不指定网卡,默认tcpdump只会监视第一个网络接口,一般是eth0,下面的例子都没有指定网络接口。
监视指定主机的数据包
打印所有进入或离开sundown的数据包。
tcpdump host sundown
也可以指定ip,例如截获所有210.27.48.1 的主机收到的和发出的所有的数据包
tcpdump host 210.27.48.1
打印helios 与 hot 或者与 ace 之间通信的数据包
tcpdump host helios and \( hot or ace \)
截获主机210.27.48.1 和主机210.27.48.2 或210.27.48.3的通信
tcpdump host 210.27.48.1 and \ (210.27.48.2 or 210.27.48.3 \)
打印ace与任何其他主机之间通信的IP 数据包, 但不包括与helios之间的数据包.
tcpdump ip host ace and not helios
如果想要获取主机210.27.48.1除了和主机210.27.48.2之外所有主机通信的ip包,使用命令:
tcpdump ip host 210.27.48.1 and ! 210.27.48.2
截获主机hostname发送的所有数据
tcpdump -i eth0 src host hostname
监视所有送到主机hostname的数据包
tcpdump -i eth0 dst host hostname
监视指定主机和端口的数据包
如果想要获取主机210.27.48.1接收或发出的telnet包,使用如下命令
tcpdump tcp port 23 host 210.27.48.1
对本机的udp 123 端口进行监视 123 为ntp的服务端口
tcpdump udp port 123
监视指定网络的数据包
打印本地主机与Berkeley网络上的主机之间的所有通信数据包
tcpdump net ucb-ether
ucb-ether此处可理解为“Berkeley网络”的网络地址,此表达式最原始的含义可表达为:打印网络地址为ucb-ether的所有数据包
打印所有通过网关snup的ftp数据包
tcpdump 'gateway snup and (port ftp or ftp-data)'
注意:表达式被单引号括起来了,这可以防止shell对其中的括号进行错误解析
打印所有源地址或目标地址是本地主机的IP数据包
tcpdump ip and not net localnet
如果本地网络通过网关连到了另一网络,则另一网络并不能算作本地网络。
7、抓包工具tshark命令
某个网卡上都有哪些数据包,当初步判定您的服务器上有流量攻击。使用抓包工具来抓一下数据包,就可以知道有哪些IP在攻击了
该命令也是用于抓包的。yum install -y tcpdump 命令安装。
使用前需要安装该工具‘wireshark’:

- tshark命令选项:
- 1. 抓包接口类
- -i 设置抓包的网络接口,不设置则默认为第一个非自环接口。
- -D 列出当前存在的网络接口。在不了解OS所控制的网络设备时,一般先用“tshark -D”查看网络接口的编号以供-i参数使用。
- -f 设定抓包过滤表达式(capture filter expression)。抓包过滤表达式的写法雷同于tcpdump,可参考tcpdump man page的有关部分。
- -s 设置每个抓包的大小,默认为65535,多于这个大小的数据将不会被程序记入内存、写入文件。(这个参数相当于tcpdump的-s,tcpdump默认抓包的大小仅为68)
- -p 设置网络接口以非混合模式工作,即只关心和本机有关的流量。
- -B 设置内核缓冲区大小,仅对windows有效。
- -y 设置抓包的数据链路层协议,不设置则默认为-L找到的第一个协议,局域网一般是EN10MB等。
- -L 列出本机支持的数据链路层协议,供-y参数使用。
- 2. 抓包停止条件
- -c 抓取的packet数,在处理一定数量的packet后,停止抓取,程序退出。
- -a 设置tshark抓包停止向文件书写的条件,事实上是tshark在正常启动之后停止工作并返回的条件。条件写为test:value的形式,如“-a duration:5”表示tshark启动后在5秒内抓包然后停止;“-a filesize:10”表示tshark在输出文件达到10kB后停止;“-a files:n”表示tshark在写满n个文件后停止。(windows版的tshark0.99.3用参数“-a files:n”不起作用——会有无数多个文件生成。由于-b参数有自己的files参数,所谓“和-b的其它参数结合使用”无从说起。这也许是一个bug,或tshark的man page的书写有误。)
- 3. 文件输出控制
- -b 设置ring buffer文件参数。ring buffer的文件名由-w参数决定。-b参数采用test:value的形式书写。“-b duration:5”表示每5秒写下一个ring buffer文件;“-b filesize:5”表示每达到5kB写下一个ring buffer文件;“-b files:7”表示ring buffer文件最多7个,周而复始地使用,如果这个参数不设定,tshark会将磁盘写满为止。
- 4. 文件输入
- -r 设置tshark分析的输入文件。tshark既可以抓取分析即时的网络流量,又可以分析dump在文件中的数据。-r不能是命名管道和标准输入。
- 5. 处理类
- -R 设置读取(显示)过滤表达式(read filter expression)。不符合此表达式的流量同样不会被写入文件。注意,读取(显示)过滤表达式的语法和底层相关的抓包过滤表达式语法不相同,它的语法表达要丰富得多,请参考http://www.ethereal.com/docs/dfref/和http://www.ethereal.com/docs/man-pages/ethereal-filter.4.html。类似于抓包过滤表达式,在命令行使用时最好将它们quote起来。
- -n 禁止所有地址名字解析(默认为允许所有)。
- -N 启用某一层的地址名字解析。“m”代表MAC层,“n”代表网络层,“t”代表传输层,“C”代表当前异步DNS查找。如果-n和-N参数同时存在,-n将被忽略。如果-n和-N参数都不写,则默认打开所有地址名字解析。
- -d 将指定的数据按有关协议解包输出。如要将tcp 8888端口的流量按http解包,应该写为“-d tcp.port==8888,http”。注意选择子和解包协议之间不能留空格。
- 6. 输出类
- -w 设置raw数据的输出文件。这个参数不设置,tshark将会把解码结果输出到stdout。“-w-”表示把raw输出到stdout。如果要把解码结果输出到文件,使用重定向“>”而不要-w参数。
- -F 设置输出raw数据的格式,默认为libpcap。“tshark -F”会列出所有支持的raw格式。
- -V 设置将解码结果的细节输出,否则解码结果仅显示一个packet一行的summary。
- -x 设置在解码输出结果中,每个packet后面以HEX dump的方式显示具体数据。
- -T 设置解码结果输出的格式,包括text,ps,psml和pdml,默认为text。
- -t 设置解码结果的时间格式。“ad”表示带日期的绝对时间,“a”表示不带日期的绝对时间,“r”表示从第一个包到现在的相对时间,“d”表示两个相邻包之间的增量时间(delta)。
- -S 在向raw文件输出的同时,将解码结果打印到控制台。
- -l 在处理每个包时即时刷新输出。
- -X 扩展项。
- -q 设置安静的stdout输出(例如做统计时)
- -z 设置统计参数。
- 7. 其它
- -h 显示命令行帮助。
- -v 显示tshark的版本信息。
- -o 重载选项。
用法
- 查看指定网卡80端口的1个web服务的访问情况(类似于web的访问日志):
[ 命令:tshark -n -t a -R http.request -T fields -e "frame.time" -e "ip.src" -e "http.host" -e "http.request.method" -e "http.request.uri" ] - 这条命令用于web服务器。类似于web访问日志,若服务器没有配置访问日志,可以临时使用该命令查看一下当前服务器上的web请求。在这里要注意的是,如果你的机器上没有开启web服务,是不会显示任何内容的。

#tshark –n –i ens33 –R 'mysql.query' –T fields –e "ip.src" –e "mysql.query"
上面的命令会抓取ens33网卡mysql的查询有哪些,不过这种方法仅仅适用于mysql的端口为3306的情况,如果不是3306,使用下面的方法。
#tshark –i ens33 port 3307 –d tcp.port==3307,mysql –z "proto,colinfo,mysql.query,mysql.query"
- 抓取mysql的查询


注: 因无相关进程运行所以一无所获!
- 抓取指定类型的MySQL查询

- 统计http的状态
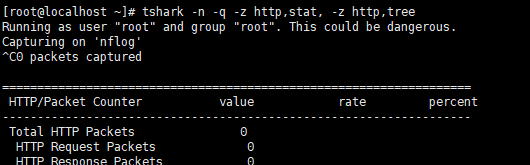
注: 这个命令,直到你ctrl + c 才会显示出结果!
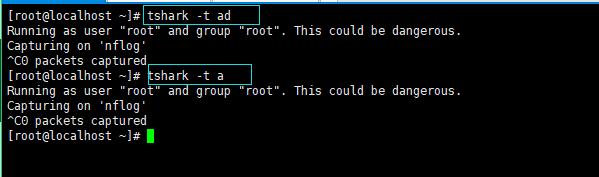
- tshark 增加时间标签
8、性能监控命令——sar详解
sar命令可以从文件的读写情况、系统调用的使用情况、磁盘I/O、CPU效率、内存使用状况、进程活动及IPC有关的活动等方面进行报告。
安装:下载与安装 wget http://perso.orange.fr/sebastien.godard/sysstat-9.0.6.1.tar.gz,解压,按说明安装即可,这是原码安装,也可以下载rpm包安装,yum也可以安装。
命令格式:sar [options] [-A] [-o file] t [n]
t为采样间隔,n为采样次数,默认值是1
-o file表示将命令结果以二进制格式存放在文件中,file 是文件名。
options 为命令行选项
sar命令常用选项如下:
-A:所有报告的总和
-u:输出CPU使用情况的统计信息
-v:输出inode、文件和其他内核表的统计信息
-d:输出每一个块设备的活动信息
-r:输出内存和交换空间的统计信息
-b:显示I/O和传送速率的统计信息
-a:文件读写情况
-c:输出进程统计信息,每秒创建的进程数
-R:输出内存页面的统计信息
-y:终端设备活动情况
-w:输出系统交换活动信息
实例:
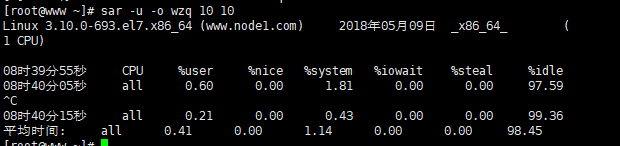
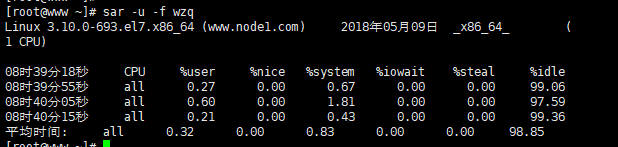
例一:使用命令行 sar -u t n
例如,每10秒采样一次,连续采样10次,观察CPU 的使用情况,并将采样结果以二进制形式存入当前目录下的文件zhou中,需键入如下命令:
# sar -u -o wzq 10 510
如果要查看二进制文件zhou中的内容,则需键入如下sar命令:
例二:使用命行sar -v t n
例如,每10秒采样一次,连续采样5次,观察核心表的状态,需键入如下命令:sar -v 10 5
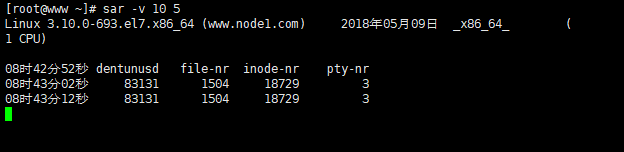
proc-sz:目前核心中正在使用或分配的进程表的表项数,由核心参数MAX-PROC控制。
inod-sz:目前核心中正在使用或分配的i节点表的表项数,由核心参数MAX-INODE控制。
file-sz: 目前核心中正在使用或分配的文件表的表项数,由核心参数MAX-FILE控制。
ov:溢出出现的次数。
Lock-sz:目前核心中正在使用或分配的记录加锁的表项数,由核心参数MAX-FLCKRE控制。
例三:使用命行sar -d t n
例如,每30秒采样一次,连续采样5次,报告设备使用情况,需键入如下命令:
# sar -d 30 5 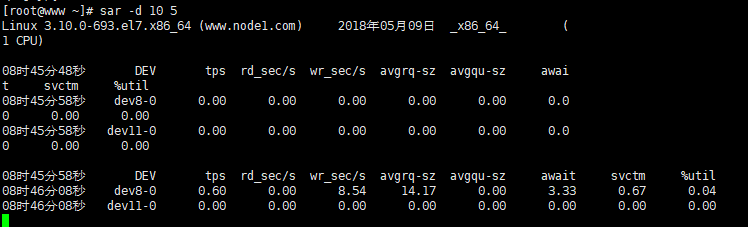
在显示的内容中,wd-0是硬盘的名字,%busy的值比较小,说明用于处理传送请求的有效时间太少,文件系统效率不高,一般来讲,%busy值高些,avque值低些,文件系统的效率比较高,如果%busy和avque值相对比较高,说明硬盘传输速度太慢,需调整。
例四:使用命行sar -b t n
例如,每30秒采样一次,连续采样5次,报告缓冲区的使用情况,需键入如下命令:
# sar -b 30 5
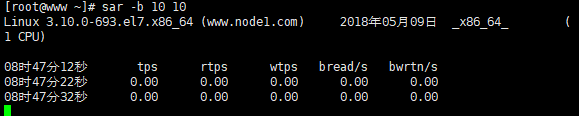
CPU资源监控:
每5s采样一次,连续采样10次,观察cpu使用情况,并将采样结果以二进制形式存入test_sar中(查看二进制文件test中的内容,sar命令:sar -u -f test_sar)
sar -u -o test_sar 5 10
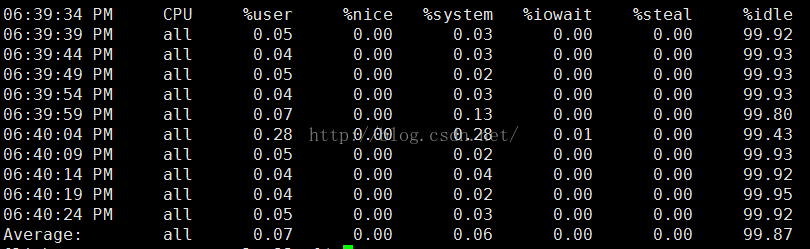
%iowait:显示用于等待I/O操作占用 CPU总时间的百分比。
%idle:显示 CPU空闲时间占用 CPU总时间的百分比。
%user:显示在用户级别(application)运行使用 CPU 总时间的百分比。
P.S:
1.若 %iowait的值过高,表示硬盘存在I/O瓶颈
2.若 %idle的值高但系统响应慢时,有可能是 CPU等待分配内存,此时应加大内存容量
3.若 %idle的值持续低于1,则系统的 CPU处理能力相对较低,表明系统中最需要解决的资源是 CPU。
inode、文件和其他内核表监控:
每5秒采样一次,连续采样10次,观察核心表的状态
sar -v 5 10
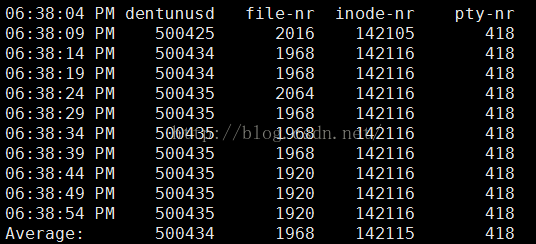
输出项说明:
dentunusd:目录高速缓存中未被使用的条目数量
file-nr:文件句柄(filehandle)的使用数量
inode-nr:索引节点句柄(inodehandle)的使用数量
pty-nr:使用的pty数量
内存和交换空间监控:
每5s采样一次,连续采样10次,监控内存分页
Sar –r 5 10
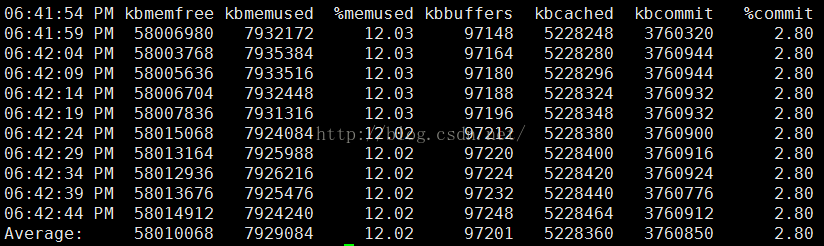
输出项说明:
kbmemfree:这个值和free命令中的free值基本一致,所以它不包括buffer和cache的空间.
kbmemused:这个值和free命令中的used值基本一致,所以它包括buffer和cache的空间.
%memused:这个值是kbmemused和内存总量(不包括swap)的一个百分比.
kbbuffers和kbcached:这两个值就是free命令中的buffer和cache.
kbcommit:保证当前系统所需要的内存,即为了确保不溢出而需要的内存(RAM+swap).
%commit:这个值是kbcommit与内存总量(包括swap)的一个百分比.
内存分页监控:
每5s采样一次,连续采样10次,监控内存分页
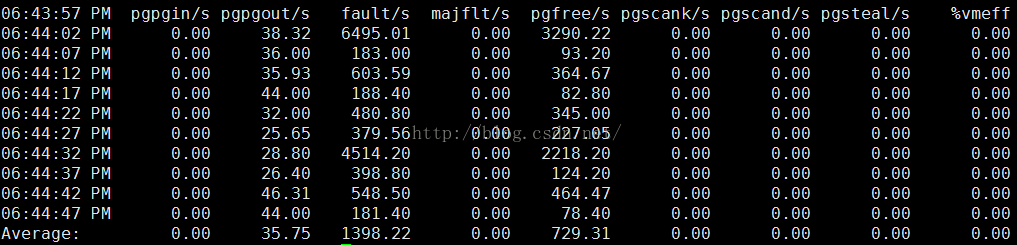
输出项说明:
pgpgin/s:表示每秒从磁盘或SWAP置换到内存的字节数(KB)
pgpgout/s:表示每秒从内存置换到磁盘或SWAP的字节数(KB)
fault/s:每秒钟系统产生的缺页数,即主缺页与次缺页之和(major +minor)
majflt/s:每秒钟产生的主缺页数.
pgfree/s:每秒被放入空闲队列中的页个数
pgscank/s:每秒被kswapd扫描的页个数
pgscand/s:每秒直接被扫描的页个数
pgsteal/s:每秒钟从cache中被清除来满足内存需要的页个数
%vmeff:每秒清除的页(pgsteal)占总扫描页(pgscank+pgscand)的百分比
I/O和传送速率监控:
每5s采样一次,连续采样10次,报告缓冲区的使用情况
sar -b 5 10
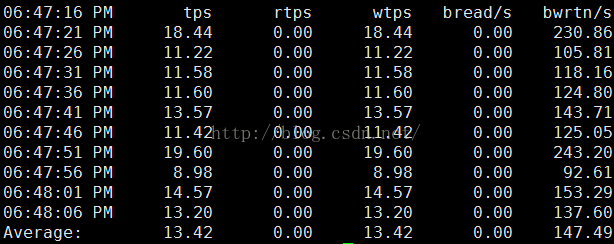
输出项说明:
tps:每秒钟物理设备的 I/O传输总量
rtps:每秒钟从物理设备读入的数据总量
wtps:每秒钟向物理设备写入的数据总量
bread/s:每秒钟从物理设备读入的数据量,单位为块/s
bwrtn/s:每秒钟向物理设备写入的数据量,单位为块/s
进程队列长度和平均负载状态监控:
每5s采样一次,连续采样10次,监控进程队列长度和平均负载状态
sar -q 5 10
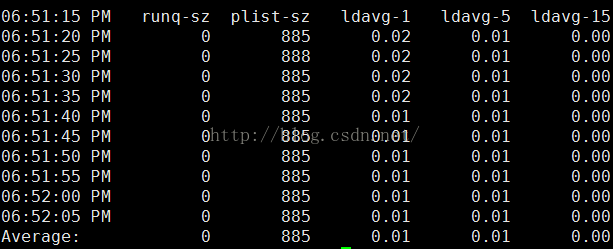
输出项说明:
runq-sz:运行队列的长度(等待运行的进程数)
plist-sz:进程列表中进程(processes)和线程(threads)的数量
ldavg-1:最后1分钟的系统平均负载(Systemload average)
ldavg-5:过去5分钟的系统平均负载
ldavg-15:过去15分钟的系统平均负载
系统交换活动信息监控:
每5s采样一次,连续采样10次,监控系统交换活动信息
sar -W 5 10
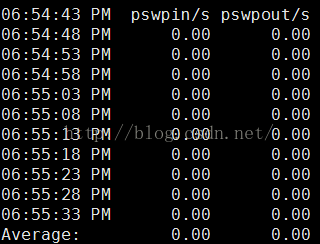
输出项说明:
pswpin/s:每秒系统换入的交换页面(swap page)数量
pswpout/s:每秒系统换出的交换页面(swap page)数量
设备使用情况监控:
每5s采样一次,连续采样10次,报告设备使用情况
sar -d 5 10 -p

参数-p可以打印出sda,hdc等磁盘设备名称,如果不用参数-p,设备节点则有可能是dev8-0,dev22-0
tps:每秒从物理磁盘I/O的次数.多个逻辑请求会被合并为一个I/O磁盘请求,一次传输的大小是不确定的.
rd_sec/s:每秒读扇区的次数.
wr_sec/s:每秒写扇区的次数.
avgrq-sz:平均每次设备I/O操作的数据大小(扇区).
avgqu-sz:磁盘请求队列的平均长度.
await:从请求磁盘操作到系统完成处理,每次请求的平均消耗时间,包括请求队列等待时间,单位是毫秒(1秒=1000毫秒).
svctm:系统处理每次请求的平均时间,不包括在请求队列中消耗的时间.
%util:I/O请求占CPU的百分比,比率越大,说明越饱和.
1. avgqu-sz的值较低时,设备的利用率较高。
2.当%util的值接近 1%时,表示设备带宽已经占满
要判断系统瓶颈问题,有时需几个 sar 命令选项结合起来
怀疑CPU存在瓶颈,可用 sar -u和 sar -q 等来查看
怀疑内存存在瓶颈,可用 sar -B、sar -r和 sar -W 等来查看
怀疑I/O存在瓶颈,可用 sar -b、sar -u 和 sar -d等来查看
常见问题:
1、
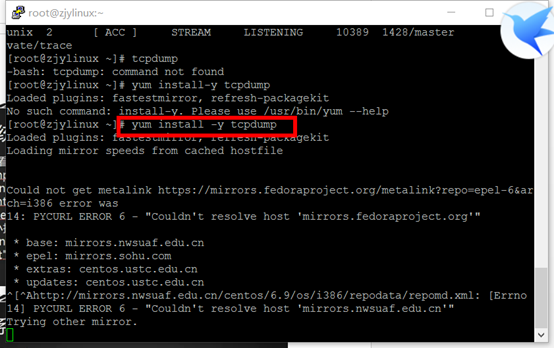
答案:网络有问题 yum不正常。
2、按PPT中只指定端口(不指定网卡),出现如下情况,加了网卡才能正常抓包,说明指定端口的同时也一定要指定网卡吗?

答案:你的系统网卡名字不规则。 理论上是应该制定网卡名字的。用-i参数指定。
3.实际工作中抓出来的包要怎样进行分析呢
主要是看源ip,源port,目标ip,目标port,还有协议之类的。再深入的就得借助图形化的抓包工具去分析了。















 1814
1814











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









