







1.已知关系模式:
S (SNO,SNAME) 学生关系。SNO 为学号,SNAME 为姓名
C (CNO,CNAME,CTEACHER) 课程关系。CNO 为课程号,CNAME 为课程名,CTEACHER 为任课教师
SC(SNO,CNO,SCGRADE) 选课关系。SCGRADE 为成绩
要求实现如下5个处理:
1. 找出没有选修过“李明”老师讲授课程的所有学生姓名
2. 列出有二门以上(含两门)不及格课程的学生姓名及其平均成绩
3. 列出既学过“1”号课程,又学过“2”号课程的所有学生姓名
4. 列出“1”号课成绩比“2”号同学该门课成绩高的所有学生的学号
5. 列出“1”号课成绩比“2”号课成绩高的所有学生的学号及其“1”号课和“2”号课的成绩
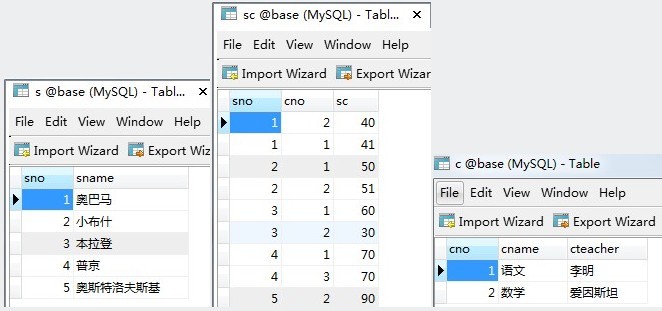
-- 首先,建立表:
-- ----------------------------
-- Table structure for `s`
-- ----------------------------
DROP TABLE IF EXISTS `s`;
CREATE TABLE `s` (
`sno` int(11) NOT NULL,
`sname` varchar(32) DEFAULT NULL,
PRIMARY KEY (`sno`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8;
-- ----------------------------
-- Records of s
-- ----------------------------
INSERT INTO `s` VALUES ('1', '奥巴马');
INSERT INTO `s` VALUES ('2', '小布什');
INSERT INTO `s` VALUES ('3', '本拉登');
INSERT INTO `s` VALUES ('4', '普京');
INSERT INTO `s` VALUES ('5', '奥斯特洛夫斯基');
-- ----------------------------
-- Table structure for `c`
-- ----------------------------
DROP TABLE IF EXISTS `c`;
CREATE TABLE `c` (
`cno` int(11) NOT NULL,
`cname` varchar(32) DEFAULT NULL,
`cteacher` varchar(32) DEFAULT NULL,
PRIMARY KEY (`cno`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8;
-- ----------------------------
-- Records of c
-- ----------------------------
INSERT INTO `c` VALUES ('1', '语文', '李明');
INSERT INTO `c` VALUES ('2', '数学', '爱因斯坦');
-- ----------------------------
-- Table structure for `sc`
-- ----------------------------
DROP TABLE IF EXISTS `sc`;
CREATE TABLE `sc` (
`sno` int(11) NOT NULL,
`cno` int(11) NOT NULL,
`sc` int(11) NOT NULL
) ENGINE=InnoDB DEFAULT CHARSET=utf8;
-- ----------------------------
-- Records of sc
-- ----------------------------
INSERT INTO `sc` VALUES ('1', '2', '50');
INSERT INTO `sc` VALUES ('1', '1', '50');
INSERT INTO `sc` VALUES ('2', '1', '50');
INSERT INTO `sc` VALUES ('2', '2', '50');
INSERT INTO `sc` VALUES ('3', '1', '60');
INSERT INTO `sc` VALUES ('3', '2', '60');
INSERT INTO `sc` VALUES ('4', '1', '70');
INSERT INTO `sc` VALUES ('4', '2', '70');
INSERT INTO `sc` VALUES ('5', '2', '90');
1. 找出没有选修过“李明”老师讲授课程的所有学生姓名
答案:
select s.sname as "不参加李明课程" from s where s.sno not in (select sno from c,sc where c.cteacher="李明" and sc.cno=c.cno)查询结果图:
 钢铁是怎么练成的?不上李明的课写完的.........Orz.开个玩笑.
钢铁是怎么练成的?不上李明的课写完的.........Orz.开个玩笑.
2.列出有二门以上(含两门)不及格课程的学生姓名及其平均成绩
这里为了更清晰,需要修改原始的成绩表.修改如下图.另一个是查询的结果:

分析:这里需要查询的是sname,这个人sc成绩的平均成绩,初步断定其需要用到group by,因为还有个判断是2门以上不及格,那么就是要用到 count(distinct 字段名)>1,因为用到了合计函数,那么需要在他前面用having.
最后的SQL语句为:
select s.sname,AVG(sc.sc)
from sc,s
where sc.sc<60
and s.sno=sc.sno
GROUP BY sc.sno
HAVING COUNT(DISTINCT sc.cno)>13. 列出既学过“1”号课程,又学过“2”号课程的所有学生姓名
--================初步答案=============
select s.sname from s
where s.sno in(
select sc.sno from sc
where sc.cno in (select cno from c where cname in ("语文","数学"))
group by sc.sno having count(sc.cno)>1)
--================优化==============
select s.sname from sc,s
where sc.cno in (select cno from c where cname in ("语文","数学"))
and sc.sno=s.sno
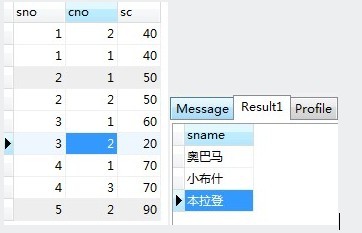
group by sc.sno having count(sc.cno)>1首先要修改数据,如图,左为修改后的数据库数据,将sno为4的一个cno改为一个并不存在的3,就是说我们在查询的时候不应该查出第四个来.查询结果显示是3个,是对的.
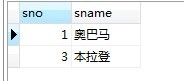
4.列出“1”号课成绩比“2”号同学该门课成绩高的所有学生的学号
select s1.sno,s1.sname
from sc as sc1,sc as sc2,s as s1
where sc1.sno=sc2.sno and sc1.cno=1 and sc2.cno=2 and sc1.sc>sc2.sc and s1.sno=sc1.sno
5. 列出“1”号课成绩比“2”号课成绩高的所有学生的学号及其“1”号课和“2”号课的成绩
select s1.sno,s1.sname,sc1.sc as "1" ,sc2.sc as "2"
from sc as sc1,sc as sc2,s as s1
where sc1.sno=sc2.sno and sc1.cno=1 and sc2.cno=2 and sc1.sc>sc2.sc and s1.sno=sc1.sno
















 5319
5319











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









