






具体参考:http://hadoop.apache.org/docs/r2.2.0/hadoop-yarn/hadoop-yarn-site/HDFSHighAvailabilityWithNFS.html
在Hadoop2.0.0之前,NameNode(NN)在HDFS集群中存在单点故障(single point of failure),每一个集群中存在一个NameNode,如果NN所在的机器出现了故障,那么将导致整个集群无法利用,直到NN重启或者在另一台主机上启动NN守护线程。
主要在两方面影响了HDFS的可用性:
(1)、在不可预测的情况下,如果NN所在的机器崩溃了,整个集群将无法利用,直到NN被重新启动;
(2)、在可预知的情况下,比如NN所在的机器硬件或者软件需要升级,将导致集群宕机。
HDFS的高可用性将通过在同一个集群中运行两个NN(active NN & standby NN)来解决上面两个问题,这种方案允许在机器破溃或者机器维护快速地启用一个新的NN来恢复故障。
在典型的HA集群中,通常有两台不同的机器充当NN。在任何时间,只有一台机器处于Active状态;另一台机器是处于Standby状态。Active NN负责集群中所有客户端的操作;而Standby NN主要用于备用,它主要维持足够的状态,如果必要,可以提供快速的故障恢复。
为了让Standby NN的状态和Active NN保持同步,即元数据保持一致,它们都将会和JournalNodes守护进程通信。当Active NN执行任何有关命名空间的修改,它需要持久化到一半以上的JournalNodes上(通过edits log持久化存储),而Standby NN负责观察edits log的变化,它能够读取从JNs中读取edits信息,并更新其内部的命名空间。一旦Active NN出现故障,Standby NN将会保证从JNs中读出了全部的Edits,然后切换成Active状态。Standby NN读取全部的edits可确保发生故障转移之前,是和Active NN拥有完全同步的命名空间状态。
为了提供快速的故障恢复,Standby NN也需要保存集群中各个文件块的存储位置。为了实现这个,集群中所有的Database将配置好Active NN和Standby NN的位置,并向它们发送块文件所在的位置及心跳,如下图所示:
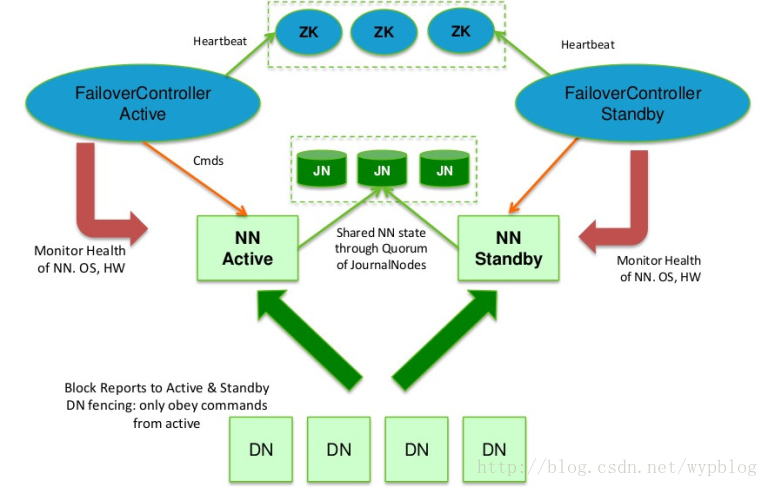
Hadoop中HDFS高可用性实现
在任何时候,集群中只有一个NN处于Active 状态是极其重要的。否则,在两个Active NN的状态下NameSpace状态将会出现分歧,这将会导致数据的丢失及其它不正确的结果。为了保证这种情况不会发生,在任何时间,JNs只允许一个NN充当writer。在故障恢复期间,将要变成Active 状态的NN将取得writer的角色,并阻止另外一个NN继续处于Active状态。
为了部署 HA 集群,你需要准备以下事项:
(1)、NameNode machines:运行Active NN和Standby NN的机器需要相同的硬件配置;
(2)、JournalNode machines:也就是运行JN的机器。JN守护进程相对来说比较轻量,所以这些守护进程可以可其他守护线程(比如NN,YARN ResourceManager)运行在同一台机器上。在一个集群中,最少要运行3个JN守护进程,这将使得系统有一定的容错能力。当然,你也可以运行3个以上的JN,但是为了增加系统的容错能力,你应该运行奇数个JN(3、5、7等),当运行N个JN,系统将最多容忍(N-1)/2个JN崩溃。
在HA集群中,Standby NN也执行namespace状态的checkpoints,所以不必要运行Secondary NN、CheckpointNode和BackupNode;事实上,运行这些守护进程是错误的。
硬件资源
为了部署一个HA集群环境,您需要准备以下资源:
- NameNode 机器:运行活动节点和备用节点的机器和非HA环境的机器需要有同相的硬件配置。
- 共享存储:您需要有一个主备namenode节点都是可读写的共享目录,通常情况,这是一个远程的文件管理器,它支持使用NFS挂载到每个namenode节点。目前只支持一个可编辑目录。因此,系统的是否可用将受限于共享目录是否可用,因此,为了消除所有单点故障,需要对共享目录再加冗余,具体来说,多个网络路径的存储需要实现存储系统自身的冗余。因为这个原因,建议共享存储服务器是一个高品质的专用NAS设备,而不是一个简单的Linux服务器。
注:在HA集群环境里,备用的namenode还要执行检测命名空间的状态,因此,没有必要再运行Secondary NameNode,CheckpointNode,BackupNode。事实上,这样做将会报错,这也允许在从非集群环境到集群环境的重新配置时,重新利用之前的Secondary NameNode的硬件资源。
部署
配置简介
类似联邦配置,HA配置向后兼容,允许在不改变当前单节点的情况下配置成集群环境,新的配置方案确保了在集群环境中的所有节点的配置文件都是相同的,没有必要因为节点的不同而配置不同的文件。
和联邦配置一样,HA集群环境重复使用名称服务ID来确定一个单一的HDFS实例,实际上可能包括多个HA namenodes.此外,一个新的namenode增加到HA,集群中的每一个nameNode都有一个不同的ID来标识它,为了支持所有namenode有同一个配置文件,所有的配置参数都以命名服务ID和nameNodeID为后缀。
详细配置
配置HA nameNodes,您需要增加一些配置选项到 hdfs-site.xml 配置文件。
这些配置选项的顺序不重要,但dfs.federation.nameservices和dfs.ha.namenodes.[nameservice ID]的值将决定下面配置的Key值。因此,在配置其它选项前,需要确定这两个选项的值。
dfs.federation.nameservices一个新的名称服务的逻辑名称。为名称服务选择一个逻辑名称,如“mycluster”,使用这个逻辑名称作为这个配置项的值。这个名称可以是随意的,它将用于配置和集群环境中HDFS绝对路径的认证组件。
注:如果您还使用HDFS联邦,这个配置项应该包括其它的名称服务列表,HA或者其它,用逗号进行分隔。
<property>
<name>dfs.federation.nameservices</name>
<value>mycluster</value>
</property>
dfs.ha.namenodes.[nameservice ID]在名称服务中每一个nameNode的唯一标识符
配置一个逗号分隔的NameNode的ID的列表,DataNode会用它来确定在集群中的所有namenode.如我们前面使用"mycluster"作为我们名称服务的ID,你如果使用nn1和nn2作为namenode的ID,你应该这样配置:
<property>
<name>dfs.ha.namenodes.mycluster</name>
<value>nn1,nn2</value>
</property>
注:当前一个名称服务最多只允许配置两个namenode。
dfs.namenode.rpc-address.[nameservice ID].[name node ID]每一个namenode监听的标准RPC地址
对于前面配置的两个namenode的ID,设置namenode节点详细的地址和端口,注意,这个配置项将在两个单独的配置项里配置,如:
<property>
<name>dfs.namenode.rpc-address.mycluster.nn1</name>
<value>machine1.example.com:8020</value>
</property>
<property>
<name>dfs.namenode.rpc-address.mycluster.nn2</name>
<value>machine2.example.com:8020</value>
</property>
注:如果你愿意,你可以配置相同的RPC地址。
dfs.namenode.http-address.[nameservice ID].[namenode ID]每一个namenode监听的标准HTTP地址
和RPC地址一样,设置两个namenode监听的http地址,如:
<property>
<name>dfs.namenode.http-address.mycluster.nn1</name>
<value>machine1.example.com:50070</value>
</property>
<property>
<name>dfs.namenode.http-address.mycluster.nn2</name>
<value>machine2.example.com:50070</value>
</property>
注:如果你启用了hadoop的安全功能,你也可以同样设置成https地址。
dfs.namenode.shared.edits.dir共享存储目录的位置
这是配置备份节点需要随时保持同步活动节点所作更改的远程共享目录,你只能配置一个目录,之个目录挂载到两个namenode上都必须是可读写的,且必须是绝对路径。如:
<property>
<name>dfs.namenode.shared.edits.dir</name>
<value>file:///mnt/filer1/dfs/ha-name-dir-shared</value>
</property>
dfs.client.failover.proxy.provider.[nameserviceID]HDFS客户端用来和活动的namenode节目联系的java类
配置的java类是用来给HDFS客户端判断哪个namenode节点是活动的,当前是哪个namenode处理客户端的请求,当前hadoop唯一的实现类是ConfiguredFailoverProxyProvider,除非你自己定义了一个类,否则都将使用这个类。如:
<property>
<name>dfs.client.failover.proxy.provider.mycluster</name>
<value>org.apache.hadoop.hdfs.server.namenode.ha.ConfiguredFailoverProxyProvider</value>
</property>
dfs.ha.fencing.methods将用于停止活动NameNode节点的故障转移期间的脚本或Java类的列表
任何时候只有一个namenode处于活动状态,对于HA集群的操作是至关重要的,因此,在故障转移期间,在启动备份节点前,我们首先要确保活动节点处于等待状态,或者进程被中止,为了达到这个目的,您至少要配置一个强行中止的方法,或者回车分隔的列表,这是为了一个一个的尝试中止,直到其中一个返回成功,表明活动节点已停止。hadoop提供了两个方法:shell和sshfence,要实现您自己的方法,请看org.apache.hadoop.ha.NodeFencer类。
sshfence 通过ssh连接活动namenode节点,杀掉进程
为了实现SSH登录杀掉进程,还需要配置免密码登录的SSH密匙信息,如下所示:
<property>
<name>dfs.ha.fencing.methods</name>
<value>sshfence</value>
</property>
<property>
<name>dfs.ha.fencing.ssh.private-key-files</name>
<value>/home/exampleuser/.ssh/id_rsa</value>
</property>
另外,也可以配置一个用户名和SSH端口。也可以为SSH设定一个超时,以毫秒为单位,它可以像这样配置:
<property>
<name>dfs.ha.fencing.methods</name>
<value>sshfence([[username][:port]])</value>
</property>
<property>
<name>dfs.ha.fencing.ssh.connect-timeout</name>
<value>34</value>
</property>
shell -执行任意的shell命令来终止活动namenode节点
配置如下:
<property>
<name>dfs.ha.fencing.methods</name>
<value>shell(/path/to/my/script.sh arg1arg2 ...)</value>
</property>
shell脚本将会运行在包括所有Hadoop配置参数变量的环境中,只需将配置key的.换成_即可。如dfs_namenode_rpc-address。除此之外,还包括以下的变量:
| $target_host | 需要中止的服务器hostname |
| $target_port | 需要中止的服务器端口 |
| $target_address | 上面两个参数的组合 |
| $target_nameserviceid | 需要中止的名称服务ID |
| $target_namenodeid | 需要中止的namenode的ID |
这些变量也可以直接在shell脚本中使用,如:
<property>
<name>dfs.ha.fencing.methods</name>
<value>shell(/path/to/my/script.sh--nameservice=$target_nameserviceid $target_host:$target_port)</value>
</property>
如果脚本返回0表示中止成功,返回其它值表示失败,同时将尝试列表中的其它中止方法。
注:这个方法没有实现超时设置,所有超时设置都取决于脚本自身。
fs.defaultFS当FS客户端没有设置时的默认路径的前缀
另外,您可以配置为hadoop客户端配置HA集群的URI作为默认路径。如果你使用"mycluster"作为名称服务ID,那么在core-site.xml文件中将配置为:
<property>
<name>fs.defaultFS</name>
<value>hdfs://mycluster</value>
</property>
部署详情
所有配置完成后,最初必须同步两个HAnamenode磁盘上的元数据。如果您是全新安装一个HDFS集群,那么您需要在其中一个namenode运行格式化命令(hdfsnamenode -format),如果你已经格式化过namenode或者是从一个非HA环境转换到HA环境,那么你需要使用scp或类似的命令把namenode上的元数据目录复制到另一个namenode。通过配置 dfs.namenode.name.dir 和 dfs.namenode.edits.dir两个选项到包含namenode元数据目录的位置。在这个时候,你必须保证之前配置的共享目录包括在您namenode元数据目录下的最近的编辑文件信息。
然后,您可以和平时启动namenode一样,启动两个HA namenode。
您可以通过配置的HTTP web地址访问两个namenode,你会看到两个HAnamenode当前的状态(主/备),当namenode启动的时候,它的最被状态都是“备”状态。
管理命令
现在完成了配置和启动,你可以执行其它的命令来管理你的HA集群。具体来说,你应该熟悉所有hdfs haadmin下的所有命令。不加任何参数的情况下,将显示如下信息:
Usage: DFSHAAdmin [-ns<nameserviceId>]
[-transitionToActive<serviceId>]
[-transitionToStandby<serviceId>]
[-failover [--forcefence][--forceactive] <serviceId> <serviceId>]
[-getServiceState<serviceId>]
[-checkHealth<serviceId>]
[-help <command>]
本指南将介绍这此子命令的高级别用法,每个命令的详细使用帮助,您可以运行如下命令来查看:
hdfs haadmin -help<command>
transitionToActive 和transitionToStandby就是把指定的namenode转换到主/备状态。
注:这个命令把指定的namenode转换到主/备状态,但这个命令不会试图去停止活动节点,所以,尽量少使用它,可以使用hdfs haadmin -failover来代替。
failover - 在两个namenode之间做故障转移。
此命令将会把故障从第一个转移到第二个namenode,如果第一个namenode是“备”状态,这个命令会成功的将第二个namenode转换到“主”状态,如果第一个namenode是“主”状态,它将会尝试把它转换到“备”状态,它会使用在之前配置的 dfs.ha.fencing.methods 所有方法列表中从第一个开始,只到成功为止,它才会把第二个namenode转换成“主”状态。如果所有方法都不能把第一个namenode转换到“备”状态,那么第二个namenode也不能转换成“主”状态,它将返回一个错误信息。
getServiceState - 获取指定namenode的状态。
连接到指定的namenode去确定它当前的状态,并打印出出它的状态(主或备)。根据namenode不同的状态,这个命令会使用cron作业或监控脚本来执行。
checkHealth - 检查指定namenode的健康状态。
连接到指定的namenode去检查它的健康状态,namenode能够对自身进行一些诊断,包括检查内部服务是否按预期运行。如果namenode运行正常,它将返回0,否则返回非0的值。这个命令的唯一用途就是进行监测。
注: 当前这个命令还没有实现, 除非namenode完成宕机,否则它总是返回成功.














 3179
3179











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









