






最近开始写搜索引擎项目了,基于Linux平台的,用纯C编写。项目主要参考以下书籍:
- 《走进搜索引擎》,梁斌,电子工业出版社
- 《搜索引擎原理、实践与应用》,卢亮、张博文,电子工业出版社
- 《搜索引擎——原理、技术与系统》,李晓明、闫宏非、王继民,科学出版社
这三本书其实重复的部分很多,但是国内这方面的参考资料实在少的可怜,而且太偏理论,所以有条件的话,还是建议把三本书都找来读读。
开发计划
项目第一步是实现对于给定范围内的数据的抓取和更新,目标区域是海大所有网站或教育网所有网站,千万级的数据量。
这个计划又分为三步:
- 单线程定向抓取
- 多线程抓取
- 分布式抓取
目前第一步:单线程的定向抓取已经完成。
流程
整个系统的流程图如下:
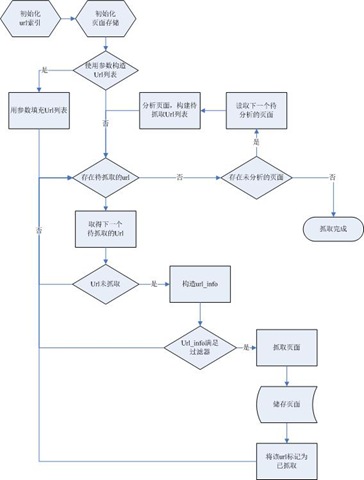
系统模块
根据系统的流程将其分为七个模块:
- store:负责数据的存储,包括将页面储存到磁盘、获取下一个未分析的页面等。
- url_info:负责Url信息的转换,主要是根据Url提取域名和服务器的IP地址。
- url_index:判断Url是否已被抓取。
- url_filter:Url过滤器,用于实现定向抓取。
- http:负责根据Url抓取页面。
- page_parse:页面的解析,提取包含的Url。
- main:主程序。
以后会陆续介绍各个模块的实现。
开发环境
操作系统:Ubuntu 8.04
部署服务器:Ubuntu 8.04 Server
编译工具:gcc,make
IDE:Eclipse CDT 4.0.1
本文转自冬冬博客园博客,原文链接:http://www.cnblogs.com/yuandong/archive/2008/06/20/Web_Spider_Summary.html,如需转载请自行联系原作者















 1289
1289

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









