






此博文主要介绍集群和负载均衡的基本理论和类别,内容看着比较枯燥、无味的,但是要想成为一个好的linux运维工程师,这些基本理论是必须理解透彻,才会在后来的系统调优和集群架构中得心应手,所以想成为linux运维工程师的我们必须承受得住寂寞~~~嘿嘿,命苦的我们啊!努力学习吧!今天很残酷,明天更残酷,后天会很美好,但不要死在明天晚上!
一、集群简介
- 集群并不是一个全新的概念,其实早在七十年代计算机厂商和研究机构就开始了对集群系统的研究和开发。由于主要
- 用于科学工程计算,所以这些系统并不为大家所熟知。直到Linux集群的出现,集群的概念才得以广为传播。集群系统主
- 要分为高可用(High Availability)集群,简称 HA 集群,和高性能计算(High Perfermance Computing)集群,
- 简称 HPC 集群。
- 计算机集群简称集群是一种计算机系统, 它通过一组松散集成的计算机软件或硬件连接起来高度紧密地协作完成计
- 算工作。在某种意义上,他们可以被看作是一台计算机。集群系统中的单个计算机通常称为节点,通常通过局域网连接,
- 但也有其它的可能连接方式。集群计算机通常用来改进单个计算机的计算速度和/或可靠性。一般情况下集群计算机比单个
- 计算机,比如工作站或超级计算机性能价格比要高得多。
二、集群分类
集群分为同构与异构两种,它们的区别在于:组成集群系统的计算机之间的体系结构是否相同。集群计算机按功能和结构可以分成以下几类:
- 负载均衡集群LB: Load balancing clusters
- 高可用性集群HA: High-availability (HA) clusters
- 高性能计算集群HP: High-performance (HPC) clusters
- 网格计算 Grid computing
三、各种集群定义详解
⑴、负载均衡集群-LB
- 负载均衡集群运行时,一般通过一个或者多个前端负载均衡器,将工作负载分发到后端的一组服务器上,从而达到整
- 个系统的高性能和高可用性。这样的计算机集群有时也被称为服务器群(Server Farm)。 一般高可用性集群和负载均
- 衡集群会使用类似的技术,或同时具有高可用性与负载均衡的特点。linux虚拟服务器(LVS)项目在linux操作系统上
- 提供了最常见的负载均衡软件。
- LB在提供负载均衡的时候,如果提供的是DNS负载均衡,由于DNS缓存服务存在的
- 机制,造成负载均衡的效果会大打折扣。所以在此出现了调度方法,常用的有两个调度
- 方法:
- RR:Round Robin 论调
- WRR:Weight Round Robin 加权论调
- 负载均衡:以提高服务的并发能力为集群的重点的集群
- 衡量标准:并发处理能力
⑵、高可用性集群-HA
- 一般是指当集群中有某个节点失效的情况下,其上的任务会自动转移到其他正常的节点上。还指可以将集群中的某节
- 点进行离线维护再上线,该过程并不影响整个集群的运行。
- 高可用集群:为了保证服务一直在线的高可用能力的集群
- 衡量标准:可用性=在线时间/(在线时间+故障处理时间)
⑶、高性能计算集群-HP
- 高性能计算集群采用将计算任务分配到集群的不同计算节点而提高计算能力,因而主要应用在科学计算领域。比较流
- 行的HPC采用Linux操作系统和其它一些免费软件来完成并行运算。这一集群配置通常被称为Beowulf集群。这类集群通
- 常运行特定的程序以发挥HPC cluster的并行能力。这类程序一般应用特定的运行库, 比如专为科学计算设计的MPI库。
- HPC集群特别适合于在计算中各计算节点之间发生大量数据通讯的计算作业,比如一个节点的中间结果或影响到其它
- 节点计算结果的情况。
- 高性能处理集群:利用的是分布式存储:分布式文件系统,分布式文件系统把一个大任务切割为小任务、分别进行处
- 理
⑷、网格计算
- 网格计算或网格集群是一种与集群计算非常相关的技术。网格与传统集群的主要差别是网格是连接一组相关并不信任
- 的计算机,它的运作更像一个计算公共设施而不是一个独立的计算机。还有,网格通常比集群支持更多不同类型的计算机
- 集合。
- 网格计算是针对有许多独立作业的工作任务作优化,在计算过程中作业间无需共享数据。网格主要服务于管理在独立
- 执行工作的计算机间的作业分配。资源如存储可以被所有结点共享,但作业的中间结果不会影响在其他网格结点上作业的
- 进展。
四、LB集群详解
- 1、负载均衡器设备类型:分为硬件和软件两种
- 硬件设备:
- F5的BIG IP负载均衡器
- Citrix的Netscaler负载均衡器
- A10
- 软件:分为基于四层和七层的两种类型
- 四层:
- lvs是一个开源的软件,由毕业于国防科技大学的章文嵩博士于1998年5月创立的,可以实现LINUX平台下的简单负载均衡。LVS是Linux Virtual Server的缩写,意思是Linux虚拟服务器
- 。
- 七层:反向代理
- Nginx:支持http,pop3,smtp,imap
- haproxy:支持http,tcp(mysql,smtp)
五、LVS详解
- 由于硬件设备价格比较高,动则上万、几十万刀,所以一般的小公司所使用的还是基于软件的架构方式来实现集群的。
- 当然,只要掌握了linux下基于软件的集群架构,其他基于硬件的架构配置也都大同小异,由于硬件的缺乏、嘿嘿--目
- 前还是小菜鸟一个,公司内部的设备还没见过是神马模样!!所以在此就着重介绍一下我们linux系统下基于LVS架构的
- 集群的搭建,当然,这也是我们作为linux运维人员必须掌握的重中之重~~是吧!好了,废话不扯那么多了~下面我们进
- 入正题吧!自己理解,如有错误还望各位大神们不吝赐教~~
①LVS基本解释
- lvs是一个开源的软件,由毕业于国防科技大学的章文嵩博士于1998年5月创立的,可以实现LINUX平台下的简单负载均
- 衡。LVS是Linux Virtual Server的缩写,意思是Linux虚拟服务器。
- 这是国人在开源上作出的最大贡献~我们为此骄傲、自豪!嘿嘿——说多了,中国在开源上面的贡献好像还真是少之
- 又少啊~~望各位大神们多做贡献,天朝还是可以出现大神的!-唠多了,下面接着咱们的VLS。
- LVS是linux系统上的一种机制,类似于iptables似,其相关属性也是通过与iptables命令类似的方式定义的,
- 等会会详细介绍。LVS是工作于内核上的,通过内核来提供工作,其工作空间在iptables的INPUT链上,当客户端请求到
- 达INPUT链上以后,通过LVS的验证如果是关于lvs的请求,则在此直接修改目标地址,然后通过postrouting链传送给
- 其定义的server!
- 注意:上面提到LVS其实是工作在iptables的INPUT和POSTROUTING链上的,所以在此系统上iptables
- 和LVS不能同时存在。
LVS的组成:
- ipvsadm:管理集群服务的命令行工具,工作于用户空间
- ipvs:为lvs提供服务的内核模块,工作于内核空间
- 在linux内核2.4.23之前的内核中模块默认是不存在的,需要自己手动打补丁,然后把此模块编译进内核才可以正常
- 使用。
②、LVS类型
- 为了便于表述下面的内容,在此插几句关于相关服务和名词的定义
- Director:复制调度集群的主机
- VIP:Virtual IP,向外提供服务的IP
- RIP:real IP,内部真的提供服务的主机IP
- DIP:向内部的IP通信的IP,在Director主机上
- CIP:客户端IP
⑴、 NAT:地址转换类型,主要是做目标地址转换,类似于iptables的DNAT
- 优点:多目标的NAT转换,能够实现负载均衡,一个Director最多额可以提供10个Real Server主机。
- 特点和要求:
- 1、LVS上面需要双网卡:DIP和VIP
- 2、内网的Real Server主机的IP必须和DIP在同一网络中,并且其网关需要指向DIP的地址
- 3、RIP地址都是私有IP地址,仅用于各个集节点之间通信
- 4、Director位于client和Real Server之间,并负责处理所有进站、出战的通信。
- 5、Real Server必须将网关指向DIP
- 6、支持端口映射
- 7、通常应用在较大规模应用场景中,但是Director易成为整个架构的瓶颈。
⑵、 DR:DIRECT ROUTE,直接路由
- 1、架构组成:
- 每个Real Server上都有两个IP:VIP和RIP,但是VIP是隐藏的,就是不能提高解析等功能,只是用来做请求回复
- 的源IP的,Director上只需要一个网卡,然后利用别名来配置两个IP:VIP和DIP
- 2、Director在接受到外部主机的请求的时候转发给Real Server的时候并不更改目标地址,只是通过arp解析的
- MAC地址进行封装然后转给Real Server,Real Server在接受到信息以后拆除MAC帧封装,然后直接回复给CIP。
- 3、企业中最常用的就是DR
- 特点和要求:
- 1、各个集群节点必须和Director在同一个物理网络中
- 2、RIP地址不能为私有地址,可以实现便捷的远程管理和监控
- 3、Director仅仅负责处理入站请求,响应报文则由Real Server直接发往客户端
- 4、集群节点Real Server 的网关一定不能指向DIP,而是指向外部路由
- 5、Director不支持端口映射
- 6、Director能够支持比NAT多很多的Real Server
⑶、TUN:隧道
- 1、架构
- Director必须有两个IP:VIP和DIP,在向外部进行转发的时候CIP和VIP不能更改,而是在数据报文的外面加层
- 封装(S:DIP,D:RIP),然后通过Internet传送给外部的Real Server,Real Server接收到请求以后,先拆除第一
- 层封装后拆除第二层封装,然后把响应数据直接传输给Client
- 2、特性:
- 1、集群节点可以跨越Internet
- 2、Director的VIP和RIP必须为公网IP
- 3、Director仅处理入站请求,响应报文则由Real Server直接发往客户端
- 4、Real Server的网关不能指向Director
- 5、只有支持隧道协议功能的OS才能作为Real Server
- 6、不支持端口映射
六、LVS的调度方法:分为静态和动态调度两种
- 静态调度:
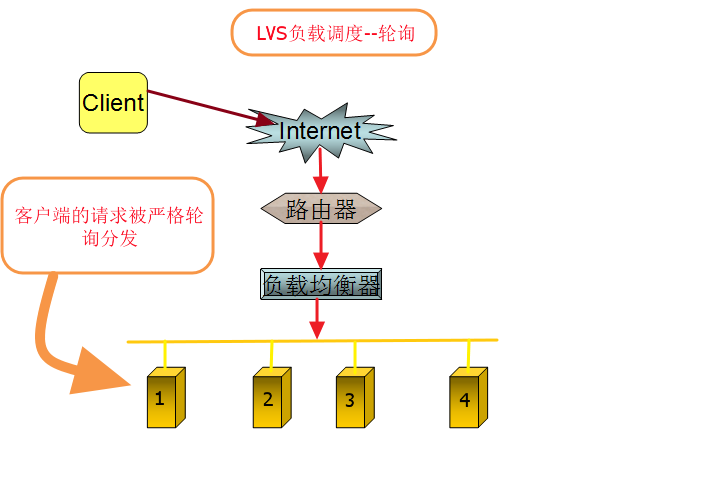
- 1、轮叫调度: Round-Robin Scheduling,简称RR,轮叫调度就是以轮叫的方式请求不同的服务器,算法的优点是其简洁性,它无需记录当前所有连接的状态,所以它是一种无状态调度。轮叫调度算法假设所有服务器处理性能均相同,不管服务器的当前连接数和响应速度。该算法相对简单,不适用于服务器组中处理性能不一的情况,而且当请求服务时间变化比较大时,轮叫调度算法容易导致服务器间的负载不平衡。
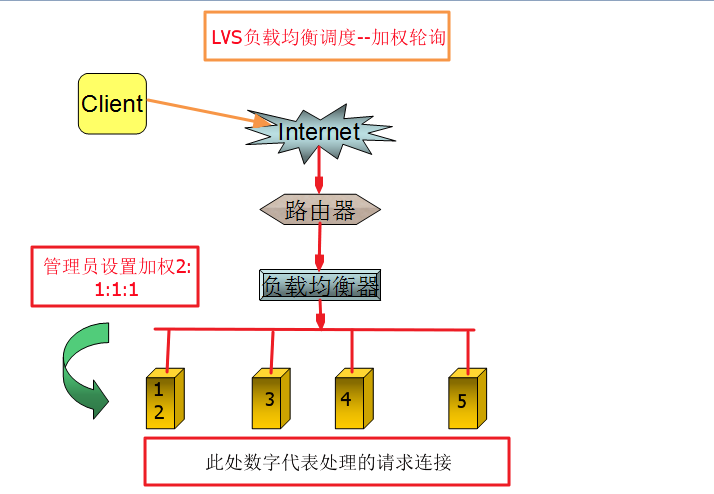
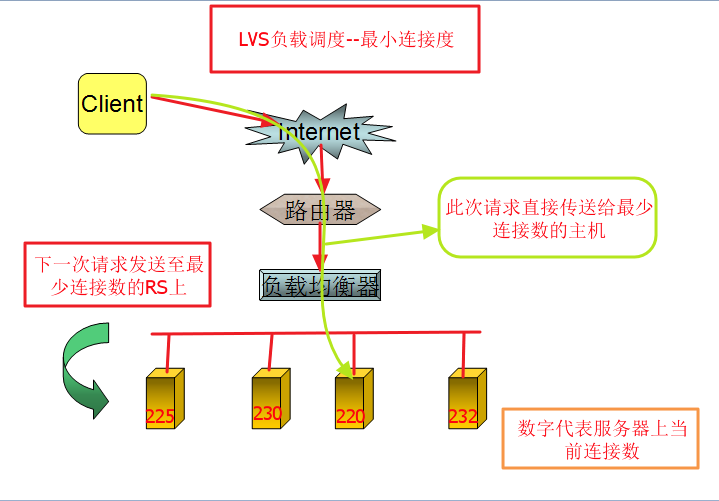
4、带复制的基于局部性最少链接(Locality-Based Least Connections with Replication Scheduling),简称LBLCR。"带复制的基于局部性最少链接"调度算法也是针对目标IP 地址的负载均衡,目前主要用于Cache 集群系统。它与LBLC 算法的不同之处是它要维护从一个目标IP 地址到一组服务器的映射,而LBLC 算法维护从一个目标IP 地址到一台服务器的映射。该算法根据请求的目标IP 地址找出该目标IP 地址对应的服务器组,按"最小连接"原则从服务器组中选出一台服务器,若服务器没有超载,将请求发送到该服务器,若服务器超载;则按"最小连接"原则从这个集群中选出一台服务器,将该服务器加入到服务器组中,将请求发送到该服务器。同时,当该服务器组有一段时间没有被修改,将最忙的服务器从服务器组中删除,以降低复制的程度。 5、最短期望延迟(Shortest Expected Delay Scheduling),简称SED,分配一个接踵而来的请求以最短的期望的延迟方式到服务器, 计算当前realserver 的负载情况计算方法:(active+1)*256/weight=overhead。 6、永不排队(Never Queue),又称最小队列调度,简称NQ。分配一个接踵而来的请求到一台空闲的服务器,此服务器不一定是最快的那台,如果所有服务器都是繁忙的,它采取最短的期望延迟分配请求。
七、LVS常用命令介绍
上面我们提到过LVS的相关模块:内核模块ipvs和用户空间命令ipvsadm。下面我们来介绍下常用的命令
在测试之前我们首先确定内核中是否有ipvs模块,grep -i 'ip_vs' /boot/config-2.6.18-308.el5

ipvsadm命令
ipvsadm的命令与iptables的相关命令及其相似,基本用法也相同。其大致如下:
- ⑴、管理集群服务命令
- 添加集群:-A
- 格式:ipvsadm -A|E -t|u|f service-address [-s scheduler算法]
- -t:tcp协议的集群
- -u:udp协议的集群
- -f或--fwmark-service:基于防火墙标记的集群服务
- fg:添加一条基于http的集群
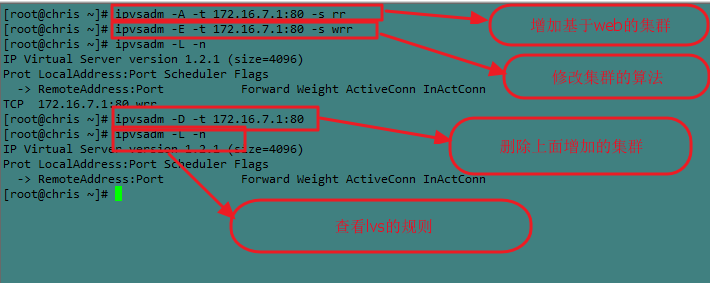
- ipvsadm -A -t 172.16.7.1:80 -s rr
- 修改集群:-E
- fg:修改上面增加的集群算法为wrr
- ipvsadm -A -t 172.16.7.1:80 -s wrr
- 删除集群:-D
- fg:删除上面增加的集群
- ipvsadm -D -t 172.16.7.1:80
- 清空集群计数器:-Z
- ipvsadm -Z
- 清空所有集群的配置:-C
- ipvsadm -C
⑵、管理集群内RealServer的命令
- 在集群中添加RS:-a
- 格式:ipvsadm -a -t|u|f service-address -r server-address [-g|i|m(LVS的类型)] [-w weight]
- -t|u|f service-address:事先定义好的某集群服务
- -r service-address:某RS的地址,在NAT模型中,可以使用IP:PORT实现端口映射
- [-g|i|m] :LVS 类型
- -g:DR类型
- -i:TUN类型
- -m:NAT
- [-w weight]:定义服务器权重
- fg:在集群172.16.7.1:80上增加RS1:172.16.7.2;RS2172.16.7.3,并定以为NAT模式,并且定义权重
- ipvsadm -A -t 172.17.7.1:80 -s wrr
- ipvsadm -a -t 172.17.7.1:80 -r 172.16.7.2 -m -w 2
- ipvsadm -a -t 172.17.7.1:80 -r 172.16.7.3 -m -w 1
- 修改集群中的RS:-e
- 格式:ipvsadm -e -t|u|f service-address -r server-address [-g|i|m(LVS的类型)] [-w weight]
- fg:修改上面的RS2的权重为3
- ipvsadm -e -t 172.17.7.1:80 -r 172.16.7.3 -m -w 3
- 删除集群中的RS:-d
- 格式:ipvsadm -d -t|u|f service-address -r server-address
- fg:删除上面的RS2
- ipvsadm -d -t 172.17.7.1:80 -r 172.16.7.3
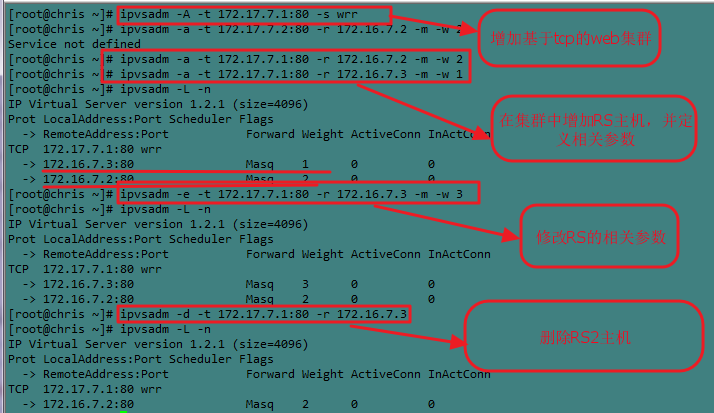
⑶、查看集群的命令 -L|l
- -n:不反解IP地址,以数字的形式显示主机地址和端口
- -c:显示当前的ipvs连接状态的
- --stats :显示统计信息
- --rate:显示速率信息
- --timeout:显示tcp、tcpfin、udp超时时间长度
- --daemon:显示进程的
- --sort:根据端口排序显示,默认是升序
- --persitent-conn 显示持久连接
⑷、保存和还原lvs配置规则的命令
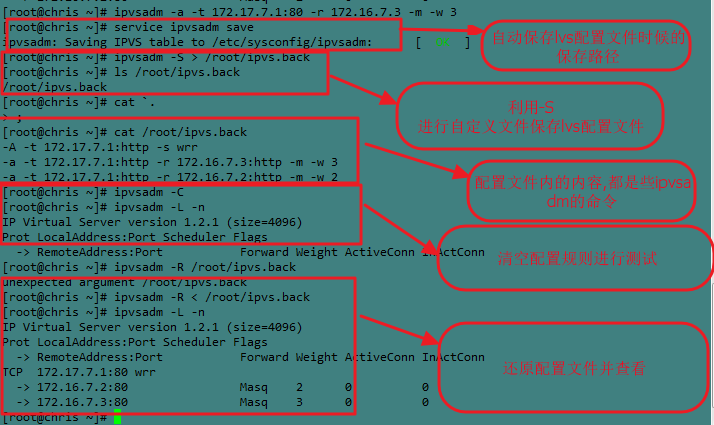
保存配置文件:
service ipvsadm save--类似于iptables的直接保存配置文件到/etc/sysconfig/ipvsadm
-S:手动指定文件保存规则
格式:ipvsadm -S > /path/to/somefile
还原配置规则:—R
格式:ipvsadm -R < /path/from/somefile
至此,关于负载集群的基本结构和类型已经介绍完毕,由于基本理论比较枯燥而且内容比较多,在此不再对基本架构进行实例介绍,由于我也是菜鸟,所以留点时间揣摩揣摩,然后在下篇博文"基于LVS实现NAT、DR和高可用集群HA的网络架构"内进行详细的探讨、说明,到时还望各位大神们多多指点!
由于是个人总结、亲自码字,中间难免出现错误还望各位大神拍砖~指出错误!--chrinux(chris linux)
转载于:https://blog.51cto.com/chrinux/1195206














 635
635











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









