








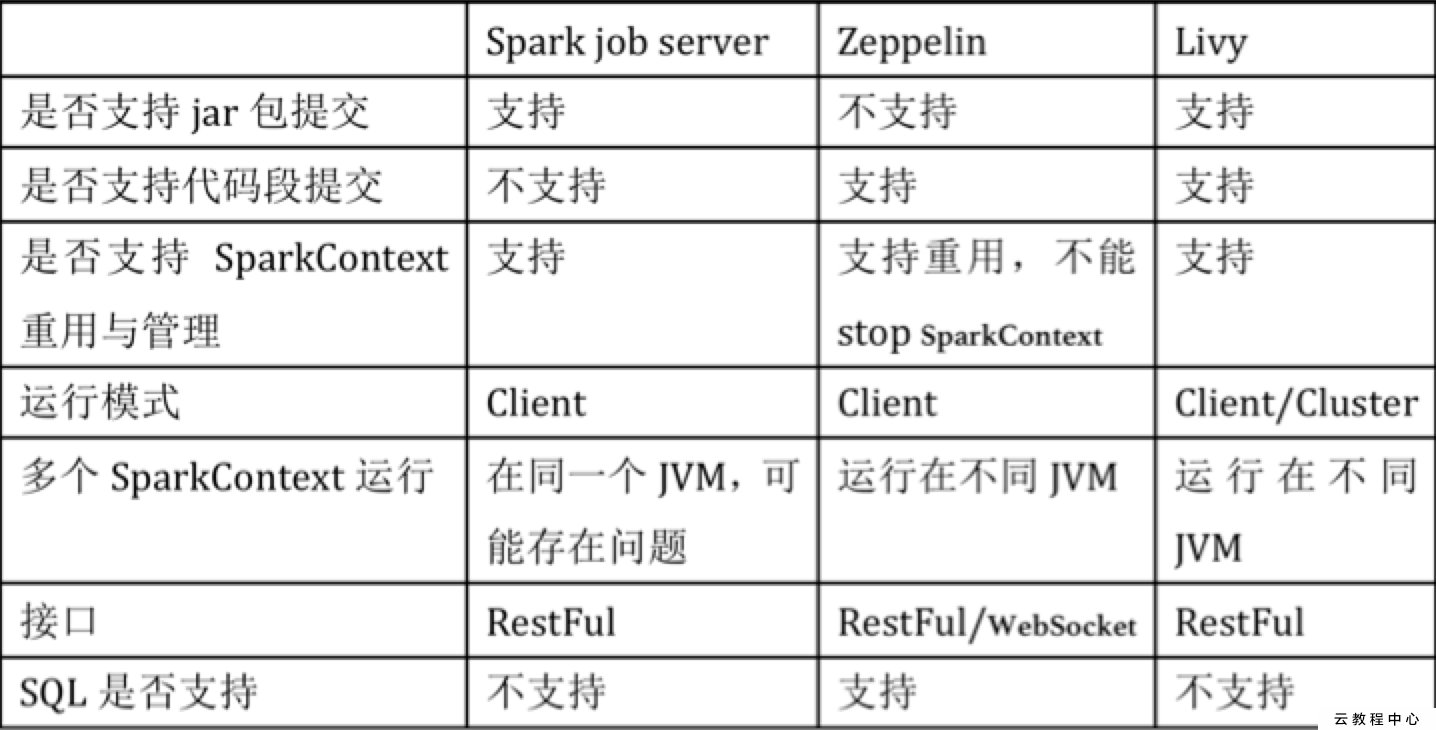
livy简介
Livy是一个提供rest接口和spark集群交互的服务。它可以提交spark job或者spark一段代码,同步或者异步的返回结果;也提供sparkcontext的管理,通过restfull接口或RPC客户端库。Livy也简化了与spark与应用服务的交互,这允许通过web/mobile与spark的使用交互。其他特点还包含:
- 长时间运行的SparkContext,允许多个spark job和多个client使用。
- 在多个spark job和客户端之间共享RDD和Dataframe
- 多个sparkcontext可以简单的管理,并运行在集群中而不是Livy Server,以此获取更好的容错性和并行度。
- 作业可以通过重新编译的jar、片段代码、或Java/Scala的客户端API提交。
Livy结合了spark job server和Zeppelin的优点,并解决了spark job server和Zeppelin的缺点。
- 支持jar和snippet code
- 支持SparkContext和Job的管理
- 支持不同SparkContext运行在不同进程,同一个进程只能运行一个SparkContext
- 支持Yarn cluster模式
- 提供restful接口,暴露SparkConte
livy安装
下载livy
下载地址,我只下载的是livy-0.5.0-incubating-bin.zip,大小为71M,不要下900多k那个,那个缺少jars包,下载之后将livy上传服务器上
配置livy
安装livy之前需要先安装hadoop和spark,hadoop和spark的安装可以参考我之前的博客。另外livy要求spark只要是Spark 1.6以上,支持scala2.10和scala2.11。
配置环境变量
| 1 |
vim ~/.bashrc |
添加下面两个环境变量
| 1 2 |
export SPARK_HOME=/usr/lib/spark export HADOOP_CONF_DIR=/etc/hadoop/conf |
保存退出之后,输入source ~/.bashrc使环境变量生效
在livy.conf中可以进行一些配置,一般默认就好
| 1 2 3 4 5 6 7 |
//默认使用hiveContext livy.repl.enableHiveContext = true //开启用户代理 livy.impersonation.enabled = true //设置session空闲过期时间 livy.server.session.timeout = 1h livy.server.session.factory = yarn/local本地模式或者yarn模式 |
运行livy
进入到livy的安装目录下,输入下面命令启动livy
| 1 |
./bin/livy-server |
出现如下界面表示启动成功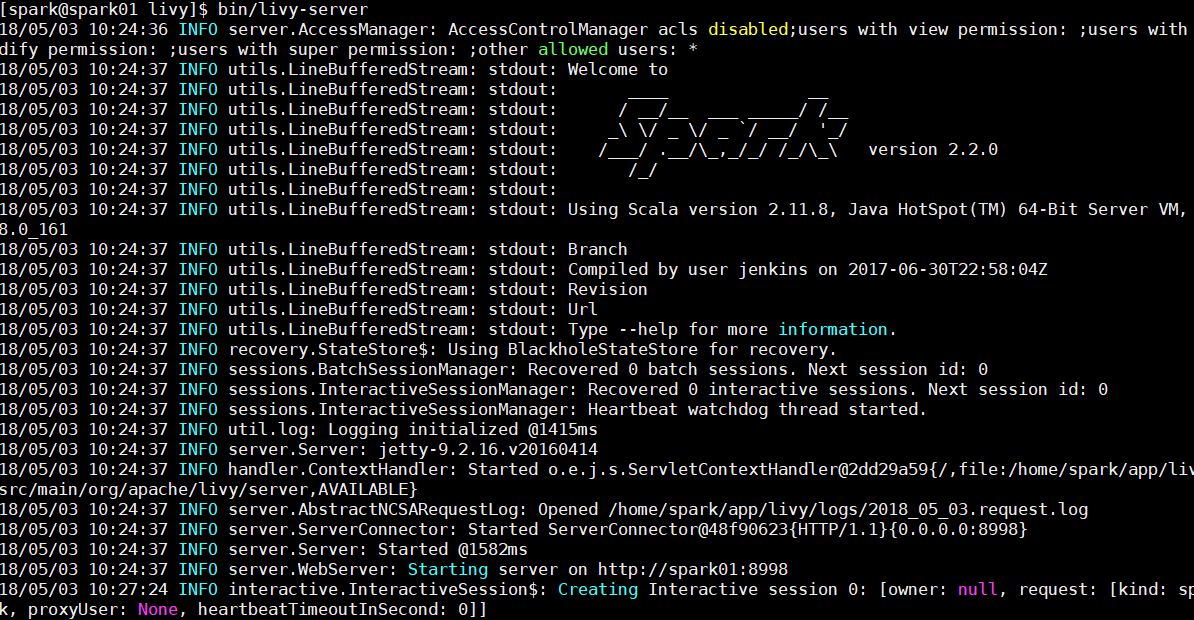
livy使用教程
官网例子
官网api说明
官网的例子已经介绍的很好了,但是它没有介绍怎样调用本地写好的jar包执行spark任务,我在下面会介绍的。
下面我介绍一下几个常用的api,使用python3的request库。
livy官网上说支持local和YARN cluster两种运行模式,在我的测试下,spark自带的集群运行模式Standalone也是支持的
创建session
| 1 2 |
host = 'http://10.4.20.181:8998' headers = {'Content-Type': 'application/json'} |
host是你的主机ip夹端口号,headers是请求头
| 1 2 3 4 |
def create_session(): data = {'kind': 'spark'} r = requests.post(host + '/sessions', data=json.dumps(data), headers=headers) print(r.json()) |
执行上面的函数后,输出如下
在浏览器输入http://10.4.20.181:8998/ui 可以看到livy的ui界面,如下如所示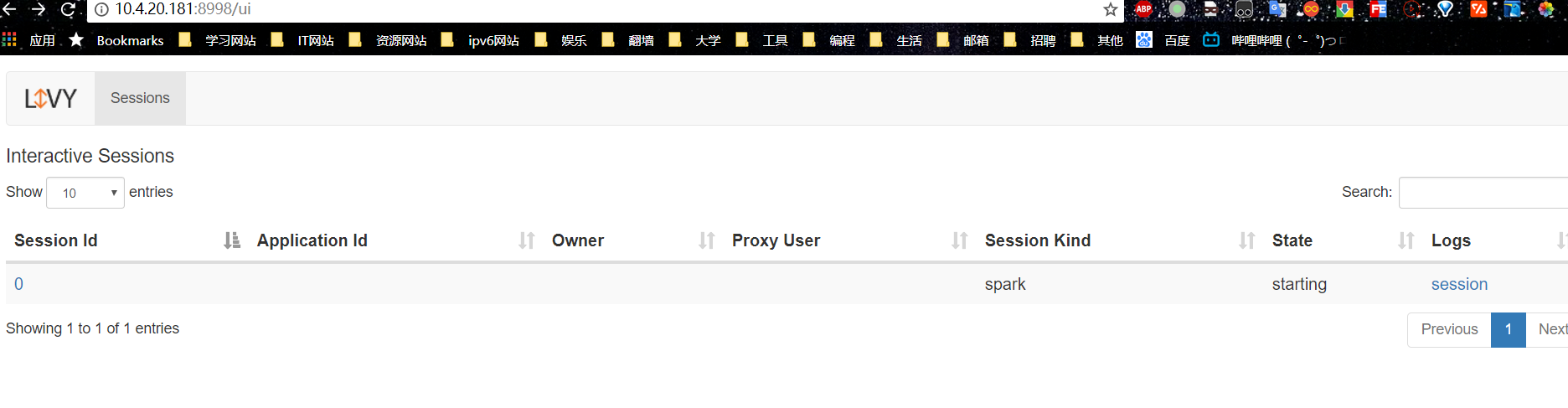
可以看到session的id,运行状态,点击右边的session也可以查看日志
查询session的转态
| 1 2 3 4 |
def state_session(session_id): session_url = host + "/sessions/" + session_id + "/state" r = requests.get(session_url, headers=headers) print(r.json()) |
删除session
| 1 2 3 4 |
def delete_session(session_id): session_url = host + "/sessions/" + session_id r = requests.delete(session_url, headers=headers) print(r.json()) |
向batches提交jar包
| 1 2 3 4 5 |
def submit_jars(jar_name, class_name): data = {'file': jar_name, 'className': class_name} r = requests.post(host + '/batches', data=json.dumps(data), headers=headers) print(r.json()) |
这里的file指的是hdfs上的路径,className是要运行的类名,官方api中还有许多其他参数,对我来说这两个参数就够用了,其他的我就不介绍了,感兴趣的参考官方api
查看batches执行状态
| 1 2 3 4 |
def batchs_state_session(batch_id): session_url = host + "/batches/" + batch_id + "/state" |
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 4037
4037











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









