






Kubenetes 1.13.5 集群源码安装
标签(空格分隔): k8s2019年06月13日
本文截选https://k.i4t.com
更多k8s内容请持续关注https://i4t.com
一、K8s简介
在1.11安装的地方已经讲过了,简单的查看K8s原理可以通过k8s 1.11源码安装查看,或者通过https://k.i4t.com查看更深入的原理
二、K8s环境准备
本次安装版本
Kubernetes v1.13.5 (v1.13.4有kubectl cp的bug)
CNI v0.7.5
Etcd v3.2.24
Calico v3.4
Docker CE 18.06.03
kernel 4.18.9-1 (不推荐使用内核5版本)
CentOS Linux release 7.6.1810 (Core)
K8s系统最好选择7.4-7.6
docker 提示
Centos7.4之前的版本安装docker会无法使用overlay2为docker的默认存储引擎。
关闭IPtables及NetworkManager
systemctl disable --now firewalld NetworkManager
setenforce 0
sed -ri '/^[^#]*SELINUX=/s#=.+$#=disabled#' /etc/selinux/configKubernetes v1.8+要求关闭系统Swap,若不关闭则需要修改kubelet设定参数( –fail-swap-on 设置为 false 来忽略 swap on),在所有机器使用以下指令关闭swap并注释掉/etc/fstab中swap的行
swapoff -a && sysctl -w vm.swappiness=0
sed -ri '/^[^#]*swap/s@^@#@' /etc/fstab设置yum源
yum install -y wget
curl -o /etc/yum.repos.d/CentOS-Base.repo http://mirrors.aliyun.com/repo/Centos-7.repo
wget -O /etc/yum.repos.d/epel.repo http://mirrors.aliyun.com/repo/epel-7.repo
yum makecache
yum install wget vim lsof net-tools lrzsz -y因为目前市面上包管理下内核版本会很低,安装docker后无论centos还是ubuntu会有如下bug,4.15的内核依然存在
kernel:unregister_netdevice: waiting for lo to become free. Usage count = 1所以建议先升级内核
perl是内核的依赖包,如果没有就安装下
[ ! -f /usr/bin/perl ] && yum install perl -y升级内核需要使用 elrepo 的yum 源,首先我们导入 elrepo 的 key并安装 elrepo 源
rpm --import https://www.elrepo.org/RPM-GPG-KEY-elrepo.org
rpm -Uvh http://www.elrepo.org/elrepo-release-7.0-3.el7.elrepo.noarch.rpm查看可用内核
(不导入升级内核的elrepo源,无法查看可用内核)
yum --disablerepo="*" --enablerepo="elrepo-kernel" list available --showduplicates在yum的ELRepo源中,mainline 为最新版本的内核,安装kernel
下面链接可以下载到其他归档版本的
http://mirror.rc.usf.edu/compute_lock/elrepo/kernel/el7/x86_64/RPMS/
下载rpm包,手动yum自选版本内核安装方法(求稳定我使用的是4.18内核版本)
export Kernel_Version=4.18.9-1
wget http://mirror.rc.usf.edu/compute_lock/elrepo/kernel/el7/x86_64/RPMS/kernel-ml{,-devel}-${Kernel_Version}.el7.elrepo.x86_64.rpm
yum localinstall -y kernel-ml*
#如果是手动下载内核rpm包,直接执行后面yum install -y kernel-ml*即可- 如果是不想升级后面的最新内核可以此时升级到保守内核去掉update的exclude即可
yum install epel-release -y
yum install wget git jq psmisc socat -y
yum update -y --exclude=kernel*重启下加载保守内核
reboot我这里直接就yum update -y
如果想安装最新内核可以使用下面方法
yum --disablerepo="*" --enablerepo="elrepo-kernel" list available --showduplicates | grep -Po '^kernel-ml.x86_64\s+\K\S+(?=.el7)'
yum --disablerepo="*" --enablerepo=elrepo-kernel install -y kernel-ml{,-devel}修改内核启动顺序,默认启动的顺序应该为1,升级以后内核是往前面插入,为0(如果每次启动时需要手动选择哪个内核,该步骤可以省略)
grub2-set-default 0 && grub2-mkconfig -o /etc/grub2.cfg使用下面命令看看确认下是否启动默认内核指向上面安装的内核
grubby --default-kernel
#这里的输出结果应该为我们升级后的内核信息docker官方的内核检查脚本建议
(RHEL7/CentOS7: User namespaces disabled; add 'user_namespace.enable=1' to boot command line)使用下面命令开启
grubby --args="user_namespace.enable=1" --update-kernel="$(grubby --default-kernel)"
重启加载新内核
reboot所有机器安装ipvs(ipvs性能甩iptables几条街并且排错更直观)
为什么要使用IPVS,从k8s的1.8版本开始,kube-proxy引入了IPVS模式,IPVS模式与iptables同样基于Netfilter,但是采用的hash表,因此当service数量达到一定规模时,hash查表的速度优势就会显现出来,从而提高service的服务性能。
- ipvs依赖于nf_conntrack_ipv4内核模块,4.19包括之后内核里改名为nf_conntrack,1.13.1之前的kube-proxy的代码里没有加判断一直用的nf_conntrack_ipv4,好像是1.13.1后的kube-proxy代码里增加了判断,我测试了是会去load nf_conntrack使用ipvs正常
在每台机器上安装依赖包:
yum install ipvsadm ipset sysstat conntrack libseccomp -y所有机器选择需要开机加载的内核模块,以下是 ipvs 模式需要加载的模块并设置开机自动加载
:> /etc/modules-load.d/ipvs.conf
module=(
ip_vs
ip_vs_rr
ip_vs_wrr
ip_vs_sh
nf_conntrack
br_netfilter
)
for kernel_module in ${module[@]};do
/sbin/modinfo -F filename $kernel_module |& grep -qv ERROR && echo $kernel_module >> /etc/modules-load.d/ipvs.conf || :
done
systemctl enable --now systemd-modules-load.service上面如果systemctl enable命令报错可以
systemctl status -l systemd-modules-load.service看看哪个内核模块加载不了,在/etc/modules-load.d/ipvs.conf里注释掉它再enable试试
所有机器需要设定/etc/sysctl.d/k8s.conf的系统参数。
cat <<EOF > /etc/sysctl.d/k8s.conf
# https://github.com/moby/moby/issues/31208
# ipvsadm -l --timout
# 修复ipvs模式下长连接timeout问题 小于900即可
net.ipv4.tcp_keepalive_time = 600
net.ipv4.tcp_keepalive_intvl = 30
net.ipv4.tcp_keepalive_probes = 10
net.ipv6.conf.all.disable_ipv6 = 1
net.ipv6.conf.default.disable_ipv6 = 1
net.ipv6.conf.lo.disable_ipv6 = 1
net.ipv4.neigh.default.gc_stale_time = 120
net.ipv4.conf.all.rp_filter = 0
net.ipv4.conf.default.rp_filter = 0
net.ipv4.conf.default.arp_announce = 2
net.ipv4.conf.lo.arp_announce = 2
net.ipv4.conf.all.arp_announce = 2
net.ipv4.ip_forward = 1
net.ipv4.tcp_max_tw_buckets = 5000
net.ipv4.tcp_syncookies = 1
net.ipv4.tcp_max_syn_backlog = 1024
net.ipv4.tcp_synack_retries = 2
# 要求iptables不对bridge的数据进行处理
net.bridge.bridge-nf-call-ip6tables = 1
net.bridge.bridge-nf-call-iptables = 1
net.bridge.bridge-nf-call-arptables = 1
net.netfilter.nf_conntrack_max = 2310720
fs.inotify.max_user_watches=89100
fs.may_detach_mounts = 1
fs.file-max = 52706963
fs.nr_open = 52706963
vm.swappiness = 0
vm.overcommit_memory=1
vm.panic_on_oom=0
EOF
sysctl --system检查系统内核和模块是否适合运行 docker (仅适用于 linux 系统)
curl https://raw.githubusercontent.com/docker/docker/master/contrib/check-config.sh > check-config.sh
bash ./check-config.sh这里利用docker的官方安装脚本来安装,可以使用yum list --showduplicates 'docker-ce'查询可用的docker版本,选择你要安装的k8s版本支持的docker版本即可,这里我使用的是18.06.03
export VERSION=18.06
curl -fsSL "https://get.docker.com/" | bash -s -- --mirror Aliyun这里说明一下,如果想使用yum list --showduplicates 'docker-ce'查询可用的docker版本。需要先使用docker官方脚本安装了一个docker,才可以list到其他版本
https://get.docker.com 首页是一个shell脚本,里面有设置yum源
所有机器配置加速源并配置docker的启动参数使用systemd,使用systemd是官方的建议,详见 https://kubernetes.io/docs/setup/cri/
mkdir -p /etc/docker/
cat > /etc/docker/daemon.json <<EOF
{
"exec-opts": ["native.cgroupdriver=systemd"],
"registry-mirrors": ["https://hjvrgh7a.mirror.aliyuncs.com"],
"log-driver": "json-file",
"log-opts": {
"max-size": "100m"
},
"storage-driver": "overlay2"
}
EOF
#这里配置当时镜像加速器,可以不进行配置,但是建议配置
要添加我们harbor仓库需要在添加下面一行
"insecure-registries": ["harbor.i4t.com"],
默认docker hub需要https协议,使用上面配置不需要配置https设置docker开机启动,CentOS安装完成后docker需要手动设置docker命令补全
yum install -y epel-release bash-completion && cp /usr/share/bash-completion/completions/docker /etc/bash_completion.d/
systemctl enable --now docker切记所有机器需要自行设定ntp,否则不只HA下apiserver通信有问题,各种千奇百怪的问题。
yum -y install ntp
systemctl enable ntpd
systemctl start ntpd
ntpdate -u cn.pool.ntp.org
hwclock --systohc
timedatectl set-timezone Asia/Shanghai三、K8s 集群安装
| IP | Hostname | Mem | VIP | 服务 |
|---|---|---|---|---|
| 10.4.82.138 | k8s-master1 | 4G | 10.4.82.141 | keeplived haproxy |
| 10.4.82.139 | k8s-master2 | 4G | 10.4.82.141 | keeplived haproxy |
| 10.4.82.140 | k8s-node1 | 4G | ||
| 10.4.82.142 | k8s-node2 | 4G |
本次VIP为,10.4.82.141,由master节点的keeplived+haporxy来选择VIP的归属保持高可用
- 所有操作使用root用户
- 本次软件包证书等都在10.4.82.138主机进行操作
3.1 环境变量SSH免密及主机名修改
- SSH免密
- NTP时间同步
- 主机名修改
- 环境变量生成
- Host 解析
这里需要说一下,所有的密钥分发以及后期拷贝等都在master1上操作,因为master1做免密了
K8S集群所有的机器都需要进行host解析
cat >> /etc/hosts << EOF
10.4.82.138 k8s-master1
10.4.82.139 k8s-master2
10.4.82.140 k8s-node1
10.4.82.142 k8s-node2
EOF批量免密
# 做免密前请修改好主机名对应的host
ssh-keygen -t rsa -P "" -f /root/.ssh/id_rsa
for i in 10.4.82.138 10.4.82.139 10.4.82.140 10.4.82.142 k8s-master1 k8s-master2 k8s-node1 k8s-node2;do
expect -c "
spawn ssh-copy-id -i /root/.ssh/id_rsa.pub root@$i
expect {
\"*yes/no*\" {send \"yes\r\"; exp_continue}
\"*password*\" {send \"123456\r\"; exp_continue}
\"*Password*\" {send \"123456\r\";}
} "
done 批量修改主机名
ssh 10.4.82.138 "hostnamectl set-hostname k8s-master1" &&
ssh 10.4.82.139 "hostnamectl set-hostname k8s-master2" &&
ssh 10.4.82.140 "hostnamectl set-hostname k8s-node1" &&
ssh 10.4.82.142 "hostnamectl set-hostname k8s-node2"
执行完毕bash刷新一下即可3.2 下载kubernetes
这里下载k8s二进制包分为2种,第一种是push镜像,将镜像的软件包拷贝出来,第二种是直接下载官网的软件包
- 1.使用镜像方式拷贝软件包 (不需要×××)
docker run --rm -d --name abcdocker-test registry.cn-beijing.aliyuncs.com/abcdocker/k8s:v1.13.5 sleep 10
docker cp abcdocker-test:/kubernetes-server-linux-amd64.tar.gz .
tar -zxvf kubernetes-server-linux-amd64.tar.gz --strip-components=3 -C /usr/local/bin kubernetes/server/bin/kube{let,ctl,-apiserver,-controller-manager,-scheduler,-proxy}- 2.有×××可以直接下载官方软件包
wget https://dl.k8s.io/v1.13.5/kubernetes-server-linux-amd64.tar.gz
tar -zxvf kubernetes-server-linux-amd64.tar.gz --strip-components=3 -C /usr/local/bin kubernetes/server/bin/kube{let,ctl,-apiserver,-controller-manager,-scheduler,-proxy}
#可以在浏览器上下载,上传到服务器分发master相关组件二进制文件到其他master上
for NODE in "k8s-master2"; do
scp /usr/local/bin/kube{let,ctl,-apiserver,-controller-manager,-scheduler,-proxy} $NODE:/usr/local/bin/
done
10.4.82.139为我们的master第二台节点,多个节点直接写进去就可以了分发node的kubernetes二进制文件,我们之分发到node1和node2
for NODE in k8s-node1 k8s-node2; do
echo "--- k8s-node1 k8s-node2 ---"
scp /usr/local/bin/kube{let,-proxy} $NODE:/usr/local/bin/
done在k81-master1下载Kubernetes CNI 二进制文件并分发
以下2种方式选择一种即可
1.官方下载
mkdir -p /opt/cni/bin
wget "${CNI_URL}/${CNI_VERSION}/cni-plugins-amd64-${CNI_VERSION}.tgz"
tar -zxf cni-plugins-amd64-${CNI_VERSION}.tgz -C /opt/cni/bin
# 分发cni文件 (所有主机)
for NODE in "${!Other[@]}"; do
echo "--- $NODE ${Other[$NODE]} ---"
ssh ${Other[$NODE]} 'mkdir -p /opt/cni/bin'
scp /opt/cni/bin/* ${Other[$NODE]}:/opt/cni/bin/
done
## 实际上下载地址就是https://github.com/containernetworking/plugins/releases/download/v0.7.5/cni-plugins-amd64-v0.7.5.tgz
2.abcdocker提供下载地址
mkdir -p /opt/cni/bin
wget http://down.i4t.com/cni-plugins-amd64-v0.7.5.tgz
tar xf cni-plugins-amd64-v0.7.5.tgz -C /opt/cni/bin
# 分发cni文件 (所有主机)
for NODE in k8s-master1 k8s-master2 k8s-node1 k8s-node2; do
echo "--- $NODE---"
ssh $NODE 'mkdir -p /opt/cni/bin'
scp /opt/cni/bin/* $NODE:/opt/cni/bin/
done
#这里可以写ip或者主机名3.3 创建集群证书
需要创建Etcd、Kubernetes等证书,并且每个集群都会有一个根数位凭证认证机构(Root Certificate Authority)被用在认证API Server 与Kubelet 端的凭证,本次使用openssl创建所有证书
配置openssl ip信息
mkdir -p /etc/kubernetes/pki/etcd
cat >> /etc/kubernetes/pki/openssl.cnf <<EOF
[ req ]
default_bits = 2048
default_md = sha256
distinguished_name = req_distinguished_name
[req_distinguished_name]
[ v3_ca ]
basicConstraints = critical, CA:TRUE
keyUsage = critical, digitalSignature, keyEncipherment, keyCertSign
[ v3_req_server ]
basicConstraints = CA:FALSE
keyUsage = critical, digitalSignature, keyEncipherment
extendedKeyUsage = serverAuth
[ v3_req_client ]
basicConstraints = CA:FALSE
keyUsage = critical, digitalSignature, keyEncipherment
extendedKeyUsage = clientAuth
[ v3_req_apiserver ]
basicConstraints = CA:FALSE
keyUsage = critical, digitalSignature, keyEncipherment
extendedKeyUsage = serverAuth
subjectAltName = @alt_names_cluster
[ v3_req_etcd ]
basicConstraints = CA:FALSE
keyUsage = critical, digitalSignature, keyEncipherment
extendedKeyUsage = serverAuth, clientAuth
subjectAltName = @alt_names_etcd
[ alt_names_cluster ]
DNS.1 = kubernetes
DNS.2 = kubernetes.default
DNS.3 = kubernetes.default.svc
DNS.4 = kubernetes.default.svc.cluster.local
DNS.5 = localhost
IP.1 = 10.96.0.1
IP.2 = 127.0.0.1
IP.3 = 10.4.82.141
IP.4 = 10.4.82.138
IP.5 = 10.4.82.139
IP.6 = 10.4.82.140
IP.7 = 10.4.82.142
[ alt_names_etcd ]
DNS.1 = localhost
IP.1 = 127.0.0.1
IP.2 = 10.4.82.138
IP.3 = 10.4.82.139
EOF
## 参数说明
alt_names_cluster 下面的IP.为主机IP,所有集群内的主机都需要添加进来,从2开头
IP.3 是VIP
IP.4 是master1
IP.5 是master2
IP.6 是node1
IP.7 是node2
alt_names_etcd 为ETCD的主机
IP.2 为master1
IP.3 为master2
将修改完毕的证书复制到证书目录
cd /etc/kubernetes/pki生成证书
kubernetes-ca
[info] 准备 kubernetes CA 证书,证书的颁发机构名称为 kubernets
openssl genrsa -out ca.key 2048
openssl req -x509 -new -nodes -key ca.key -config openssl.cnf -subj "/CN=kubernetes-ca" -extensions v3_ca -out ca.crt -days 10000etcd-ca
[info] 用于etcd客户端和服务器之间通信的证书
openssl genrsa -out etcd/ca.key 2048
openssl req -x509 -new -nodes -key etcd/ca.key -config openssl.cnf -subj "/CN=etcd-ca" -extensions v3_ca -out etcd/ca.crt -days 10000front-proxy-ca
openssl genrsa -out front-proxy-ca.key 2048
openssl req -x509 -new -nodes -key front-proxy-ca.key -config openssl.cnf -subj "/CN=kubernetes-ca" -extensions v3_ca -out front-proxy-ca.crt -days 10000当前证书路径
[root@k8s-master1 pki]# ll
总用量 20
-rw-r--r-- 1 root root 1046 5月 7 15:33 ca.crt
-rw-r--r-- 1 root root 1679 5月 7 15:33 ca.key
drwxr-xr-x 2 root root 34 5月 7 15:34 etcd
-rw-r--r-- 1 root root 1046 5月 7 15:34 front-proxy-ca.crt
-rw-r--r-- 1 root root 1679 5月 7 15:34 front-proxy-ca.key
-rw-r--r-- 1 root root 1229 5月 7 15:33 openssl.cnf
[root@k8s-master1 pki]# tree
.
├── ca.crt
├── ca.key
├── etcd
│ ├── ca.crt
│ └── ca.key
├── front-proxy-ca.crt
├── front-proxy-ca.key
└── openssl.cnf生成所有的证书信息
apiserver-etcd-client
openssl genrsa -out apiserver-etcd-client.key 2048
openssl req -new -key apiserver-etcd-client.key -subj "/CN=apiserver-etcd-client/O=system:masters" -out apiserver-etcd-client.csr
openssl x509 -in apiserver-etcd-client.csr -req -CA etcd/ca.crt -CAkey etcd/ca.key -CAcreateserial -extensions v3_req_etcd -extfile openssl.cnf -out apiserver-etcd-client.crt -days 10000kube-etcd
openssl genrsa -out etcd/server.key 2048
openssl req -new -key etcd/server.key -subj "/CN=etcd-server" -out etcd/server.csr
openssl x509 -in etcd/server.csr -req -CA etcd/ca.crt -CAkey etcd/ca.key -CAcreateserial -extensions v3_req_etcd -extfile openssl.cnf -out etcd/server.crt -days 10000kube-etcd-peer
openssl genrsa -out etcd/peer.key 2048
openssl req -new -key etcd/peer.key -subj "/CN=etcd-peer" -out etcd/peer.csr
openssl x509 -in etcd/peer.csr -req -CA etcd/ca.crt -CAkey etcd/ca.key -CAcreateserial -extensions v3_req_etcd -extfile openssl.cnf -out etcd/peer.crt -days 10000kube-etcd-healthcheck-client
openssl genrsa -out etcd/healthcheck-client.key 2048
openssl req -new -key etcd/healthcheck-client.key -subj "/CN=etcd-client" -out etcd/healthcheck-client.csr
openssl x509 -in etcd/healthcheck-client.csr -req -CA etcd/ca.crt -CAkey etcd/ca.key -CAcreateserial -extensions v3_req_etcd -extfile openssl.cnf -out etcd/healthcheck-client.crt -days 10000kube-apiserver
openssl genrsa -out apiserver.key 2048
openssl req -new -key apiserver.key -subj "/CN=kube-apiserver" -config openssl.cnf -out apiserver.csr
openssl x509 -req -in apiserver.csr -CA ca.crt -CAkey ca.key -CAcreateserial -days 10000 -extensions v3_req_apiserver -extfile openssl.cnf -out apiserver.crtapiserver-kubelet-client
openssl genrsa -out apiserver-kubelet-client.key 2048
openssl req -new -key apiserver-kubelet-client.key -subj "/CN=apiserver-kubelet-client/O=system:masters" -out apiserver-kubelet-client.csr
openssl x509 -req -in apiserver-kubelet-client.csr -CA ca.crt -CAkey ca.key -CAcreateserial -days 10000 -extensions v3_req_client -extfile openssl.cnf -out apiserver-kubelet-client.crtfront-proxy-client
openssl genrsa -out front-proxy-client.key 2048
openssl req -new -key front-proxy-client.key -subj "/CN=front-proxy-client" -out front-proxy-client.csr
openssl x509 -req -in front-proxy-client.csr -CA front-proxy-ca.crt -CAkey front-proxy-ca.key -CAcreateserial -days 10000 -extensions v3_req_client -extfile openssl.cnf -out front-proxy-client.crtkube-scheduler
openssl genrsa -out kube-scheduler.key 2048
openssl req -new -key kube-scheduler.key -subj "/CN=system:kube-scheduler" -out kube-scheduler.csr
openssl x509 -req -in kube-scheduler.csr -CA ca.crt -CAkey ca.key -CAcreateserial -days 10000 -extensions v3_req_client -extfile openssl.cnf -out kube-scheduler.crtsa.pub sa.key
openssl genrsa -out sa.key 2048
openssl ecparam -name secp521r1 -genkey -noout -out sa.key
openssl ec -in sa.key -outform PEM -pubout -out sa.pub
openssl req -new -sha256 -key sa.key -subj "/CN=system:kube-controller-manager" -out sa.csr
openssl x509 -req -in sa.csr -CA ca.crt -CAkey ca.key -CAcreateserial -days 10000 -extensions v3_req_client -extfile openssl.cnf -out sa.crtadmin
openssl genrsa -out admin.key 2048
openssl req -new -key admin.key -subj "/CN=kubernetes-admin/O=system:masters" -out admin.csr
openssl x509 -req -in admin.csr -CA ca.crt -CAkey ca.key -CAcreateserial -days 10000 -extensions v3_req_client -extfile openssl.cnf -out admin.crt清理 csr srl(csr只要key不变那每次生成都是一样的,所以可以删除,如果后期根据ca重新生成证书来添加ip的话可以此处不删除)
find . -name "*.csr" -o -name "*.srl"|xargs rm -f证书结构如下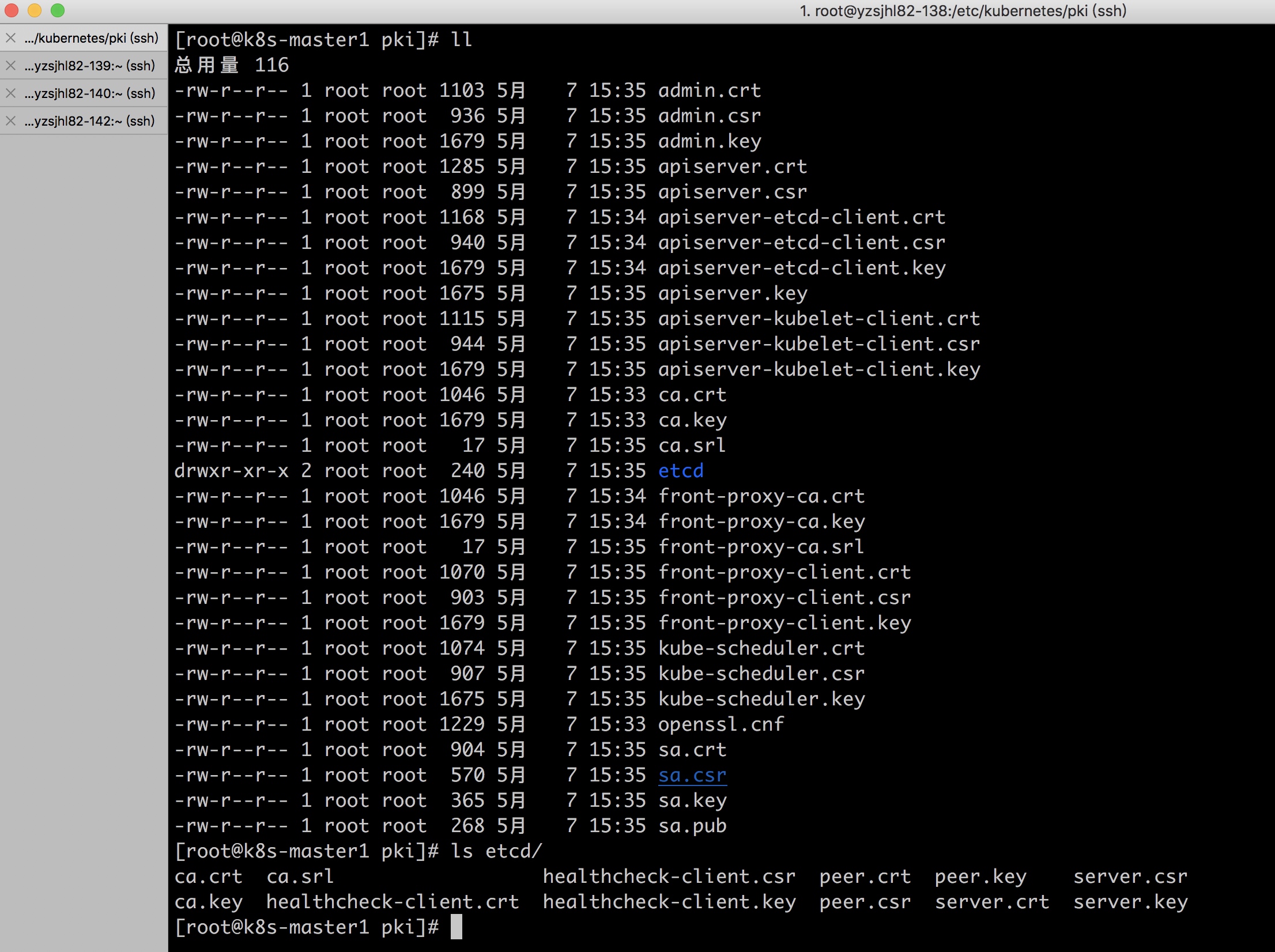
[root@k8s-master1 pki]# tree
.
├── admin.crt
├── admin.csr
├── admin.key
├── apiserver.crt
├── apiserver.csr
├── apiserver-etcd-client.crt
├── apiserver-etcd-client.csr
├── apiserver-etcd-client.key
├── apiserver.key
├── apiserver-kubelet-client.crt
├── apiserver-kubelet-client.csr
├── apiserver-kubelet-client.key
├── ca.crt
├── ca.key
├── ca.srl
├── etcd
│ ├── ca.crt
│ ├── ca.key
│ ├── ca.srl
│ ├── healthcheck-client.crt
│ ├── healthcheck-client.csr
│ ├── healthcheck-client.key
│ ├── peer.crt
│ ├── peer.csr
│ ├── peer.key
│ ├── server.crt
│ ├── server.csr
│ └── server.key
├── front-proxy-ca.crt
├── front-proxy-ca.key
├── front-proxy-ca.srl
├── front-proxy-client.crt
├── front-proxy-client.csr
├── front-proxy-client.key
├── kube-scheduler.crt
├── kube-scheduler.csr
├── kube-scheduler.key
├── openssl.cnf
├── sa.crt
├── sa.csr
├── sa.key
└── sa.pub利用证书生成组件的kubeconfig
kubectl的参数意义为
- –certificate-authority:验证根证书;
- –client-certificate、–client-key:生成的 组件证书和私钥,连接 kube-apiserver 时会用到
- –embed-certs=true:将 ca.pem 和 组件.pem 证书内容嵌入到生成的 kubeconfig 文件中(不加时,写入的是证书文件路径)
- ${KUBE_APISERVER} 这里我们apiserver使用haproxy ip+8443代替
定义apiserver变量,下面替换所使用
export KUBE_APISERVER=https://10.4.82.141:8443
#后面的IP为我们的VIPkube-controller-manager
CLUSTER_NAME="kubernetes"
KUBE_USER="system:kube-controller-manager"
KUBE_CERT="sa"
KUBE_CONFIG="controller-manager.kubeconfig"
# 设置集群参数
kubectl config set-cluster ${CLUSTER_NAME} \
--certificate-authority=/etc/kubernetes/pki/ca.crt \
--embed-certs=true \
--server=${KUBE_APISERVER} \
--kubeconfig=/etc/kubernetes/${KUBE_CONFIG}
# 设置客户端认证参数
kubectl config set-credentials ${KUBE_USER} \
--client-certificate=/etc/kubernetes/pki/${KUBE_CERT}.crt \
--client-key=/etc/kubernetes/pki/${KUBE_CERT}.key \
--embed-certs=true \
--kubeconfig=/etc/kubernetes/${KUBE_CONFIG}
# 设置上下文参数
kubectl config set-context ${KUBE_USER}@${CLUSTER_NAME} \
--cluster=${CLUSTER_NAME} \
--user=${KUBE_USER} \
--kubeconfig=/etc/kubernetes/${KUBE_CONFIG}
# 设置当前使用的上下文
kubectl config use-context ${KUBE_USER}@${CLUSTER_NAME} --kubeconfig=/etc/kubernetes/${KUBE_CONFIG}
# 查看生成的配置文件
kubectl config view --kubeconfig=/etc/kubernetes/${KUBE_CONFIG}kube-scheduler
CLUSTER_NAME="kubernetes"
KUBE_USER="system:kube-scheduler"
KUBE_CERT="kube-scheduler"
KUBE_CONFIG="scheduler.kubeconfig"
# 设置集群参数
kubectl config set-cluster ${CLUSTER_NAME} \
--certificate-authority=/etc/kubernetes/pki/ca.crt \
--embed-certs=true \
--server=${KUBE_APISERVER} \
--kubeconfig=/etc/kubernetes/${KUBE_CONFIG}
# 设置客户端认证参数
kubectl config set-credentials ${KUBE_USER} \
--client-certificate=/etc/kubernetes/pki/${KUBE_CERT}.crt \
--client-key=/etc/kubernetes/pki/${KUBE_CERT}.key \
--embed-certs=true \
--kubeconfig=/etc/kubernetes/${KUBE_CONFIG}
# 设置上下文参数
kubectl config set-context ${KUBE_USER}@${CLUSTER_NAME} \
--cluster=${CLUSTER_NAME} \
--user=${KUBE_USER} \
--kubeconfig=/etc/kubernetes/${KUBE_CONFIG}
# 设置当前使用的上下文
kubectl config use-context ${KUBE_USER}@${CLUSTER_NAME} --kubeconfig=/etc/kubernetes/${KUBE_CONFIG}
# 查看生成的配置文件
kubectl config view --kubeconfig=/etc/kubernetes/${KUBE_CONFIG}admin(kubectl)
CLUSTER_NAME="kubernetes"
KUBE_USER="kubernetes-admin"
KUBE_CERT="admin"
KUBE_CONFIG="admin.kubeconfig"
# 设置集群参数
kubectl config set-cluster ${CLUSTER_NAME} \
--certificate-authority=/etc/kubernetes/pki/ca.crt \
--embed-certs=true \
--server=${KUBE_APISERVER} \
--kubeconfig=/etc/kubernetes/${KUBE_CONFIG}
# 设置客户端认证参数
kubectl config set-credentials ${KUBE_USER} \
--client-certificate=/etc/kubernetes/pki/${KUBE_CERT}.crt \
--client-key=/etc/kubernetes/pki/${KUBE_CERT}.key \
--embed-certs=true \
--kubeconfig=/etc/kubernetes/${KUBE_CONFIG}
# 设置上下文参数
kubectl config set-context ${KUBE_USER}@${CLUSTER_NAME} \
--cluster=${CLUSTER_NAME} \
--user=${KUBE_USER} \
--kubeconfig=/etc/kubernetes/${KUBE_CONFIG}
# 设置当前使用的上下文
kubectl config use-context ${KUBE_USER}@${CLUSTER_NAME} --kubeconfig=/etc/kubernetes/${KUBE_CONFIG}
# 查看生成的配置文件
kubectl config view --kubeconfig=/etc/kubernetes/${KUBE_CONFIG}分发证书
分发到k8s配置及证书其他 master 节点
for NODE in k8s-master2 k8s-master1; do
echo "--- $NODE---"
scp -r /etc/kubernetes $NODE:/etc
done3.4 配置ETCD
Etcd 二进制文件
- Etcd:用于保存集群所有状态的Key/Value存储系统,所有Kubernetes组件会通过API Server来跟Etcd进行沟通从而保存或读取资源状态
- 我们将etcd存储在master上,可以通过apiserver制定etcd集群
etcd所有标准版本可以在下面url查看
https://github.com/etcd-io/etcd/releases
在k8s-master1上下载etcd的二进制文件
ETCD版本v3.1.9
下载etcd
第一种方式:
export ETCD_version=v3.2.24
wget https://github.com/etcd-io/etcd/releases/download/${ETCD_version}/etcd-${ETCD_version}-linux-amd64.tar.gz
tar -zxvf etcd-${ETCD_version}-linux-amd64.tar.gz --strip-components=1 -C /usr/local/bin etcd-${ETCD_version}-linux-amd64/etcd{,ctl}
第二种方式:
docker pull registry.cn-beijing.aliyuncs.com/abcdocker/etcd:v3.2.24
or
docker pull quay.io/coreos/etcd:v3.2.24
#可以选择官网镜像或者我提供的(以下选择一个)
docker run --rm -d --name abcdocker-etcd quay.io/coreos/etcd:v3.2.24
docker run --rm -d --name abcdocker-etcd registry.cn-beijing.aliyuncs.com/abcdocker/etcd:v3.2.24
sleep 10
docker cp abcdocker-etcd:/usr/local/bin/etcd /usr/local/bin
docker cp abcdocker-etcd:/usr/local/bin/etcdctl /usr/local/bin在k8s-master1上分发etcd的二进制文件到其他master上
for NODE in "k8s-master2"; do
echo "--- $NODE ---"
scp /usr/local/bin/etcd* $NODE:/usr/local/bin/
done在k8s-master1上配置etcd配置文件并分发相关文件
配置文件路径为/etc/etcd/etcd.config.yml,参考官方 https://github.com/etcd-io/etcd/blob/master/etcd.conf.yml.sample
cat >> /opt/etcd.config.yml <<EOF
name: '{HOSTNAME}'
data-dir: /var/lib/etcd
wal-dir: /var/lib/etcd/wal
snapshot-count: 5000
heartbeat-interval: 100
election-timeout: 1000
quota-backend-bytes: 0
listen-peer-urls: 'https://{PUBLIC_IP}:2380'
listen-client-urls: 'https://{PUBLIC_IP}:2379,http://127.0.0.1:2379'
max-snapshots: 3
max-wals: 5
cors:
initial-advertise-peer-urls: 'https://{PUBLIC_IP}:2380'
advertise-client-urls: 'https://{PUBLIC_IP}:2379'
discovery:
discovery-fallback: 'proxy'
discovery-proxy:
discovery-srv:
initial-cluster: 'k8s-master1=https://10.4.82.138:2380,k8s-master2=https://10.4.82.139:2380'
initial-cluster-token: 'etcd-k8s-cluster'
initial-cluster-state: 'new'
strict-reconfig-check: false
enable-v2: true
enable-pprof: true
proxy: 'off'
proxy-failure-wait: 5000
proxy-refresh-interval: 30000
proxy-dial-timeout: 1000
proxy-write-timeout: 5000
proxy-read-timeout: 0
client-transport-security:
ca-file: '/etc/kubernetes/pki/etcd/ca.crt'
cert-file: '/etc/kubernetes/pki/etcd/server.crt'
key-file: '/etc/kubernetes/pki/etcd/server.key'
client-cert-auth: true
trusted-ca-file: '/etc/kubernetes/pki/etcd/ca.crt'
auto-tls: true
peer-transport-security:
ca-file: '/etc/kubernetes/pki/etcd/ca.crt'
cert-file: '/etc/kubernetes/pki/etcd/peer.crt'
key-file: '/etc/kubernetes/pki/etcd/peer.key'
peer-client-cert-auth: true
trusted-ca-file: '/etc/kubernetes/pki/etcd/ca.crt'
auto-tls: true
debug: false
log-package-levels:
log-output: default
force-new-cluster: false
EOF
# 修改initial-cluster后面的主机及IP地址,etcd我们只是在master1和2上运行,如果其他机器也有逗号分隔即可创建etcd启动文件
cat >> /opt/etcd.service <<EOF
[Unit]
Description=Etcd Service
Documentation=https://coreos.com/etcd/docs/latest/
After=network.target
[Service]
Type=notify
ExecStart=/usr/local/bin/etcd --config-file=/etc/etcd/etcd.config.yml
Restart=on-failure
RestartSec=10
LimitNOFILE=65536
[Install]
WantedBy=multi-user.target
Alias=etcd3.service
EOF分发systemd和配置文件
cd /opt/
for NODE in k8s-master1 k8s-master2; do
echo "--- $NODE ---"
ssh $NODE "mkdir -p /etc/etcd /var/lib/etcd"
scp /opt/etcd.service $NODE:/usr/lib/systemd/system/etcd.service
scp /opt/etcd.config.yml $NODE:/etc/etcd/etcd.config.yml
done
#当etcd.config.yml拷贝到master1和master2上后,还需要对etcd进行配置修改
ssh k8s-master1 "sed -i "s/{HOSTNAME}/k8s-master1/g" /etc/etcd/etcd.config.yml" &&
ssh k8s-master1 "sed -i "s/{PUBLIC_IP}/10.4.82.138/g" /etc/etcd/etcd.config.yml" &&
ssh k8s-master2 "sed -i "s/{HOSTNAME}/k8s-master2/g" /etc/etcd/etcd.config.yml" &&
ssh k8s-master2 "sed -i "s/{PUBLIC_IP}/10.4.82.139/g" /etc/etcd/etcd.config.yml"
#如果有多台etcd就都需要替换,我这里的etcd为master1、master2在k8s-master1上启动所有etcd
etcd 进程首次启动时会等待其它节点的 etcd 加入集群,命令 systemctl start etcd 会卡住一段时间,为正常现象
可以全部启动后后面的etcdctl命令查看状态确认正常否
for NODE in k8s-master1 k8s-master2; do
echo "--- $NODE ---"
ssh $NODE "systemctl daemon-reload"
ssh $NODE "systemctl enable --now etcd" &
done
wait检查端口进程是否正常
[root@k8s-master1 master]# ps -ef|grep etcd
root 14744 1 3 18:42 ? 00:00:00 /usr/local/bin/etcd --config-file=/etc/etcd/etcd.config.yml
root 14754 12464 0 18:42 pts/0 00:00:00 grep --color=auto etcd
[root@k8s-master1 master]# lsof -i:2379
COMMAND PID USER FD TYPE DEVICE SIZE/OFF NODE NAME
etcd 14744 root 6u IPv4 1951765 0t0 TCP localhost:2379 (LISTEN)
etcd 14744 root 7u IPv4 1951766 0t0 TCP k8s-master1:2379 (LISTEN)
etcd 14744 root 18u IPv4 1951791 0t0 TCP k8s-master1:53826->k8s-master1:2379 (ESTABLISHED)
etcd 14744 root 19u IPv4 1951792 0t0 TCP localhost:54924->localhost:2379 (ESTABLISHED)
etcd 14744 root 20u IPv4 1951793 0t0 TCP localhost:2379->localhost:54924 (ESTABLISHED)
etcd 14744 root 21u IPv4 1951795 0t0 TCP k8s-master1:2379->k8s-master1:53826 (ESTABLISHED)k8s-master1上执行下面命令验证 ETCD 集群状态,下面第二个是使用3的api去查询集群的键值
etcdctl \
--cert-file /etc/kubernetes/pki/etcd/healthcheck-client.crt \
--key-file /etc/kubernetes/pki/etcd/healthcheck-client.key \
--ca-file /etc/kubernetes/pki/etcd/ca.crt \
--endpoints https://10.4.82.138:2379,https://10.4.82.139:2379 cluster-health
#这里需要填写etcd的地址+端口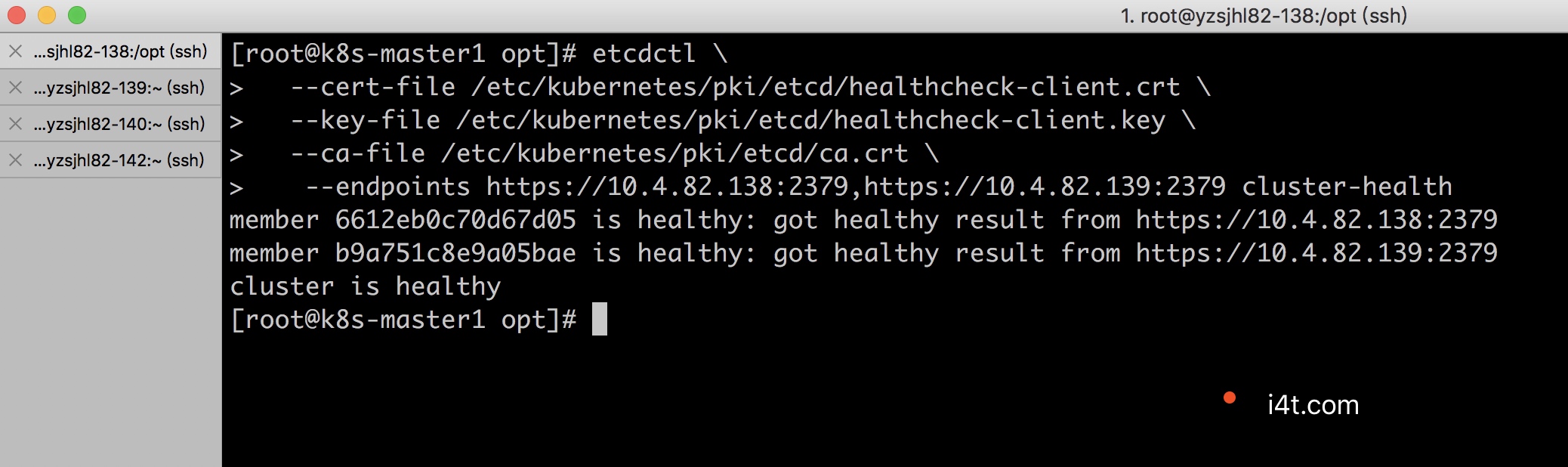
使用3的api去查询集群的键值
ETCDCTL_API=3 \
etcdctl \
--cert /etc/kubernetes/pki/etcd/healthcheck-client.crt \
--key /etc/kubernetes/pki/etcd/healthcheck-client.key \
--cacert /etc/kubernetes/pki/etcd/ca.crt \
--endpoints https://IP+端口 get / --prefix --keys-only如果想了解更多etcdctl操作可以去官网etcdctl command 文章。
3.5 Kubernetes Master Install
接下来我们部署master上的服务器
首先介绍一下master部署的组件作用
- Kubelet
1.负责管理容器的声明周期,定期从API Server获取节点上的状态(如网络、存储等等配置)资源,并让对应的容器插件(CRI、CNI等)来达成这个状态。
2.关闭只读端口,在安全端口10250接收https请求,对请求进行认真和授权,拒绝匿名访问和非授权访问
3.使用kubeconfig访问apiserver的安全端口
- Kube-Apiserver
1.以REST APIs 提供Kubernetes资源的CRUD,如授权、认真、存取控制与API注册等机制
2.关闭非安全端口,在安全端口6443接收https请求
3.严格的认真和授权策略(RBAC、token)
4.开启bootstrap token认证,支持kubelet TLS bootstrapping
5.使用https访问kubelet、etcd、加密通信
- Kube-controller-manager
1.通过核心控制循环(Core Control Loop)监听Kubernetes API的资源来维护集群的状态,这些资源会被不同的控制器所管理,如Replication Controller、Namespace Controller等等。而这些控制器会处理着自动扩展、滚动更新等等功能
2.关闭非安全端口,在安全端口10252接收https请求
3.使用kubeconfig访问apiserver的安全端口
- Kube-scheduler
负责将一个或多个容器依据调度策略分配到对应节点上让容器引擎执行,而调度收到QoS要求、软硬性约束、亲和力(Affinty)等因素影响
- HAProxy
提供多个API Server的负载均衡(Load Balance),确保haproxy的端口负载到所有的apiserver的6443端口
也可以使用nginx实现
- Keepalived
提供虚拟IP(VIP),让VIP落在可用的master主机上供所有组件都能访问到高可用的master,结合haproxy(nginx)能访问到master上的apiserver的6443端口
部署说明
1.信息可以按照自己的环境填写,或者和我相同
2.网卡名称都为eth0,如有不相同建议修改下面配置,或者直接修改centos7网卡为eth0
3.cluster dns或domain有改变的话,需要修改kubelet-conf.yml
HA(haproxy+keepalived) 单台master就不要用HA了
首先所有master安装haproxy+keeplived
for NODE in k8s-master1 k8s-master2; do
echo "--- $NODE---"
ssh $NODE 'yum install haproxy keepalived -y' &
done安装完记得检查 (是每台master进行检查)
for NODE in k8s-master1 k8s-master2;do
echo "--- $NODE ---"
ssh $NODE "rpm -qa|grep haproxy"
ssh $NODE "rpm -qa|grep keepalived"
done在k8s-master1修改配置文件,并分发给其他master
- haproxy配置文件修改
cat >> /opt/haproxy.cfg <<EOF
global
maxconn 2000
ulimit-n 16384
log 127.0.0.1 local0 err
stats timeout 30s
defaults
log global
mode http
option httplog
timeout connect 5000
timeout client 50000
timeout server 50000
timeout http-request 15s
timeout http-keep-alive 15s
frontend monitor-in
bind *:33305
mode http
option httplog
monitor-uri /monitor
listen stats
bind *:8006
mode http
stats enable
stats hide-version
stats uri /stats
stats refresh 30s
stats realm Haproxy\ Statistics
stats auth admin:admin
frontend k8s-api
bind 0.0.0.0:8443
bind 127.0.0.1:8443
mode tcp
option tcplog
tcp-request inspect-delay 5s
default_backend k8s-api
backend k8s-api
mode tcp
option tcplog
option tcp-check
balance roundrobin
default-server inter 10s downinter 5s rise 2 fall 2 slowstart 60s maxconn 250 maxqueue 256 weight 100
server k8s-api-1 10.4.82.138:6443 check
server k8s-api-2 10.4.82.139:6443 check
EOF
#在最后一行添加我们的master节点,端口默认是6443- keeplived配置文件修改
cat >> /opt/keepalived.conf <<EOF
vrrp_script haproxy-check {
script "/bin/bash /etc/keepalived/check_haproxy.sh"
interval 3
weight -2
fall 10
rise 2
}
vrrp_instance haproxy-vip {
state BACKUP
priority 101
interface eth0
virtual_router_id 47
advert_int 3
unicast_peer {
10.4.82.138
10.4.82.139
}
virtual_ipaddress {
10.4.82.141
}
track_script {
haproxy-check
}
}
EOF
#unicast_peer 为master节点IP
#virtual_ipaddress 为VIP地址,自行修改
#interface 物理网卡地址添加keeplived健康检查脚本
cat >> /opt/check_haproxy.sh <<EOF
#!/bin/bash
errorExit() {
echo "*** $*" 1>&2
exit 1
}
if ip addr | grep -q $VIRTUAL_IP ; then
curl -s --max-time 2 --insecure https://10.4.82.141:8443/ -o /dev/null || errorExit "Error GET https://10.4.82.141:8443/"
fi
EOF
##注意修改VIP地址分发keeplived及haproxy文件给所有master
# 分发文件
for NODE in k8s-master1 k8s-master2; do
echo "--- $NODE ---"
scp -r /opt/haproxy.cfg $NODE:/etc/haproxy/
scp -r /opt/keepalived.conf $NODE:/etc/keepalived/
scp -r /opt/check_haproxy.sh $NODE:/etc/keepalived/
ssh $NODE 'systemctl enable --now haproxy keepalived'
doneping下vip看看能通否,先等待大概四五秒等keepalived和haproxy起来
ping 10.4.82.141
这里的141位我们漂移IP (VIP)如果vip没起来就是keepalived没起来就每个节点上去restart下keepalived或者确认下配置文件/etc/keepalived/keepalived.conf里网卡名和ip是否注入成功
for NODE in k8s-master1 k8s-master2; do
echo "--- $NODE ---"
ssh $NODE 'systemctl restart haproxy keepalived'
done配置master 组件
- kube-apiserver启动文件
编辑apiserver启动文件
vim /opt/kube-apiserver.service
[Unit]
Description=Kubernetes API Server
Documentation=https:/github.com/kubernetes/kubernetes
After=network.target
[Service]
ExecStart=/usr/local/bin/kube-apiserver \
--authorization-mode=Node,RBAC \
--enable-admission-plugins=NamespaceLifecycle,LimitRanger,ServiceAccount,PersistentVolumeClaimResize,DefaultStorageClass,DefaultTolerationSeconds,NodeRestriction,MutatingAdmissionWebhook,ValidatingAdmissionWebhook,ResourceQuota,Priority,PodPreset \
--advertise-address={{ NODE_IP }} \
--bind-address={{ NODE_IP }} \
--insecure-port=0 \
--secure-port=6443 \
--allow-privileged=true \
--apiserver-count=2 \
--audit-log-maxage=30 \
--audit-log-maxbackup=3 \
--audit-log-maxsize=100 \
--audit-log-path=/var/log/audit.log \
--enable-swagger-ui=true \
--storage-backend=etcd3 \
--etcd-cafile=/etc/kubernetes/pki/etcd/ca.crt \
--etcd-certfile=/etc/kubernetes/pki/apiserver-etcd-client.crt \
--etcd-keyfile=/etc/kubernetes/pki/apiserver-etcd-client.key \
--etcd-servers=https://10.4.82.138:2379,https://10.4.82.139:2379 \
--event-ttl=1h \
--enable-bootstrap-token-auth \
--client-ca-file=/etc/kubernetes/pki/ca.crt \
--kubelet-https \
--kubelet-client-certificate=/etc/kubernetes/pki/apiserver-kubelet-client.crt \
--kubelet-client-key=/etc/kubernetes/pki/apiserver-kubelet-client.key \
--kubelet-preferred-address-types=InternalIP,ExternalIP,Hostname \
--runtime-config=api/all,settings.k8s.io/v1alpha1=true \
--service-cluster-ip-range=10.96.0.0/12 \
--service-node-port-range=30000-32767 \
--service-account-key-file=/etc/kubernetes/pki/sa.pub \
--tls-cert-file=/etc/kubernetes/pki/apiserver.crt \
--tls-private-key-file=/etc/kubernetes/pki/apiserver.key \
--requestheader-client-ca-file=/etc/kubernetes/pki/front-proxy-ca.crt \
--requestheader-username-headers=X-Remote-User \
--requestheader-group-headers=X-Remote-Group \
--requestheader-allowed-names=front-proxy-client \
--requestheader-extra-headers-prefix=X-Remote-Extra- \
--proxy-client-cert-file=/etc/kubernetes/pki/front-proxy-client.crt \
--proxy-client-key-file=/etc/kubernetes/pki/front-proxy-client.key \
--feature-gates=PodShareProcessNamespace=true \
--v=2
Restart=on-failure
RestartSec=10s
LimitNOFILE=65535
[Install]
WantedBy=multi-user.target
#配置修改参数解释
--etcd-servers 为etcd节点ip,逗号分隔
--apiserver-count (最好根据master节点创建)指定集群运行模式,多台 kube-apiserver 会通过 leader 选举产生一个工作节点,其它节点处于阻塞状态
--advertise-address 将IP修改为当前节点的IP
--bind-address 将IP修改为当前节点的IP - kube-controller-manager.service 启动文件
cat >> /opt/kube-controller-manager.service <<EOF
[Unit]
Description=Kubernetes Controller Manager
Documentation=https://github.com/kubernetes/kubernetes
After=network.target
[Service]
ExecStart=/usr/local/bin/kube-controller-manager \
--allocate-node-cidrs=true \
--kubeconfig=/etc/kubernetes/controller-manager.kubeconfig \
--authentication-kubeconfig=/etc/kubernetes/controller-manager.kubeconfig \
--authorization-kubeconfig=/etc/kubernetes/controller-manager.kubeconfig \
--client-ca-file=/etc/kubernetes/pki/ca.crt \
--cluster-signing-cert-file=/etc/kubernetes/pki/ca.crt \
--cluster-signing-key-file=/etc/kubernetes/pki/ca.key \
--bind-address=127.0.0.1 \
--leader-elect=true \
--cluster-cidr=10.244.0.0/16 \
--service-cluster-ip-range=10.96.0.0/12 \
--requestheader-client-ca-file=/etc/kubernetes/pki/front-proxy-ca.crt \
--service-account-private-key-file=/etc/kubernetes/pki/sa.key \
--root-ca-file=/etc/kubernetes/pki/ca.crt \
--use-service-account-credentials=true \
--controllers=*,bootstrapsigner,tokencleaner \
--experimental-cluster-signing-duration=86700h \
--feature-gates=RotateKubeletClientCertificate=true \
--v=2
Restart=always
RestartSec=10s
[Install]
WantedBy=multi-user.target
EOF- kube-scheduler.service 启动文件
cat >> /opt/kube-scheduler.service <<EOF
[Unit]
Description=Kubernetes Scheduler
Documentation=https://github.com/kubernetes/kubernetes
After=network.target
[Service]
ExecStart=/usr/local/bin/kube-scheduler \
--leader-elect=true \
--kubeconfig=/etc/kubernetes/scheduler.kubeconfig \
--address=127.0.0.1 \
--v=2
Restart=always
RestartSec=10s
[Install]
WantedBy=multi-user.target
EOF分发文件
for NODE in 10.4.82.138 10.4.82.139; do
echo "--- $NODE ---"
ssh $NODE 'mkdir -p /etc/kubernetes/manifests /var/lib/kubelet /var/log/kubernetes'
scp /opt/kube-*.service $NODE:/usr/lib/systemd/system/
#注入网卡ip
ssh $NODE "sed -ri '/bind-address/s#=[^\]+#=$NODE #' /usr/lib/systemd/system/kube-apiserver.service && sed -ri '/--advertise-address/s#=[^\]+#=$NODE #' /usr/lib/systemd/system/kube-apiserver.service"
done
#这里for循环要写ip地址,不可以写host,因为下面配置文件有替换地址的步骤
For 循环拷贝以下文件
kube-apiserver.service
kube-controller-manager.service
kube-scheduler.service在k8s-master1上给所有master机器启动kubelet 服务
for NODE in k8s-master1 k8s-master2; do
echo "--- $NODE---"
ssh $NODE 'systemctl enable --now kube-apiserver kube-controller-manager kube-scheduler;
mkdir -p ~/.kube/
cp /etc/kubernetes/admin.kubeconfig ~/.kube/config;
kubectl completion bash > /etc/bash_completion.d/kubectl'
done
#apiserver默认端口为8080端口,但是我们k8s内部定义端口为8443,如果不复制环境变量,通过kubectl 命令就会提示8080端口连接异常验证组件
完成后,在任意一台master节点通过简单指令验证:
# 这里需要等待一会,等api server和其他服务启动成功
[root@k8s-master1 ~]# kubectl get cs
NAME STATUS MESSAGE ERROR
scheduler Healthy ok
controller-manager Healthy ok
etcd-0 Healthy {"health": "true"}
etcd-1 Healthy {"health": "true"}配置Bootstrap
本次安装启用了TLS认证,需要每个节点的kubelet都必须使用kube-apiserver的CA凭证后,才能与kube-apiserver进行沟通,而该过程需要手动针对每台节点单独签署凭证是一件繁琐的事情,可以通过kubelet先使用一个预定低权限使用者连接到kube-apiserver,然后在对kube-apiserver申请凭证签署,当授权Token一致时,Node节点的kubelet凭证将由kube-apiserver动态签署提供。具体作法可以参考TLS Bootstrapping与Authenticating with Bootstrap Tokens。
说明
以下步骤是属于自动签发认证证书的步骤,如果不需要可以不进行创建 (k8s集群node节点加入需要apiserver签发证书)
下面的步骤在任意一台master上执行就可以
首先在k8s-master1建立一个BOOTSTRAP_TOKEN,并建立bootstrap的kubeconfig文件,接着在k8s-master1建立TLS bootstrap secret来提供自动签证使用
TOKEN_PUB=$(openssl rand -hex 3)
TOKEN_SECRET=$(openssl rand -hex 8)
BOOTSTRAP_TOKEN="${TOKEN_PUB}.${TOKEN_SECRET}"
kubectl -n kube-system create secret generic bootstrap-token-${TOKEN_PUB} \
--type 'bootstrap.kubernetes.io/token' \
--from-literal description="cluster bootstrap token" \
--from-literal token-id=${TOKEN_PUB} \
--from-literal token-secret=${TOKEN_SECRET} \
--from-literal usage-bootstrap-authentication=true \
--from-literal usage-bootstrap-signing=true建立bootstrap的kubeconfig文件
KUBE_APISERVER=https://10.4.82.141:8443
CLUSTER_NAME="kubernetes"
KUBE_USER="kubelet-bootstrap"
KUBE_CONFIG="bootstrap.kubeconfig"
# 设置集群参数
kubectl config set-cluster ${CLUSTER_NAME} \
--certificate-authority=/etc/kubernetes/pki/ca.crt \
--embed-certs=true \
--server=${KUBE_APISERVER} \
--kubeconfig=/etc/kubernetes/${KUBE_CONFIG}
# 设置上下文参数
kubectl config set-context ${KUBE_USER}@${CLUSTER_NAME} \
--cluster=${CLUSTER_NAME} \
--user=${KUBE_USER} \
--kubeconfig=/etc/kubernetes/${KUBE_CONFIG}
# 设置客户端认证参数
kubectl config set-credentials ${KUBE_USER} \
--token=${BOOTSTRAP_TOKEN} \
--kubeconfig=/etc/kubernetes/${KUBE_CONFIG}
# 设置当前使用的上下文
kubectl config use-context ${KUBE_USER}@${CLUSTER_NAME} --kubeconfig=/etc/kubernetes/${KUBE_CONFIG}
# 查看生成的配置文件
kubectl config view --kubeconfig=/etc/kubernetes/${KUBE_CONFIG}授权 kubelet 可以创建 csr
kubectl create clusterrolebinding kubeadm:kubelet-bootstrap \
--clusterrole system:node-bootstrapper --group system:bootstrappers批准 csr 请求
允许 system:bootstrappers 组的所有 csr
cat <<EOF | kubectl apply -f -
# Approve all CSRs for the group "system:bootstrappers"
kind: ClusterRoleBinding
apiVersion: rbac.authorization.k8s.io/v1
metadata:
name: auto-approve-csrs-for-group
subjects:
- kind: Group
name: system:bootstrappers
apiGroup: rbac.authorization.k8s.io
roleRef:
kind: ClusterRole
name: system:certificates.k8s.io:certificatesigningrequests:nodeclient
apiGroup: rbac.authorization.k8s.io
EOF允许 kubelet 能够更新自己的证书
cat <<EOF | kubectl apply -f -
# Approve renewal CSRs for the group "system:nodes"
kind: ClusterRoleBinding
apiVersion: rbac.authorization.k8s.io/v1
metadata:
name: auto-approve-renewals-for-nodes
subjects:
- kind: Group
name: system:nodes
apiGroup: rbac.authorization.k8s.io
roleRef:
kind: ClusterRole
name: system:certificates.k8s.io:certificatesigningrequests:selfnodeclient
apiGroup: rbac.authorization.k8s.io
EOF说明
以上步骤是属于自动签发认证证书的步骤,如果不需要可以不进行创建 (k8s集群node节点加入需要apiserver签发证书)
3.6 Kubernetes ALL Node
本部分操作主要是将node节点添加到k8s集群中,在开始之前,先在k8s-master1将需要用到的文件复制到所有其他节点上
Kubelet的配置选项官方建议大多数的参数写一个yaml里用
--config去指定https://godoc.org/k8s.io/kubernetes/pkg/kubelet/apis/config#KubeletConfiguration
1.在所有节点创建存储证书目录
2.拷贝ca证书及bootstrap.kubeconfig(kubelet需要用到里面的配置)拷贝到节点上
for NODE in k8s-master1 k8s-master2 k8s-node1 k8s-node2; do
echo "--- $NODE ---"
ssh $NODE "mkdir -p /etc/kubernetes/pki /etc/kubernetes/manifests /var/lib/kubelet/"
for FILE in /etc/kubernetes/pki/ca.crt /etc/kubernetes/bootstrap.kubeconfig; do
scp ${FILE} $NODE:${FILE}
done
done生成kubelet.service(启动脚本)及kubelet-conf.yaml(配置文件)
1.生成kubelet.service启动脚本
cat >> /opt/kubelet.service <<EOF
[Unit]
Description=Kubernetes Kubelet
Documentation=https://github.com/kubernetes/kubernetes
After=docker.service
Requires=docker.service
[Service]
ExecStart=/usr/local/bin/kubelet \
--bootstrap-kubeconfig=/etc/kubernetes/bootstrap.kubeconfig \
--kubeconfig=/etc/kubernetes/kubelet.kubeconfig \
--config=/etc/kubernetes/kubelet-conf.yml \
--pod-infra-container-image=registry.cn-hangzhou.aliyuncs.com/google_containers/pause-amd64:3.1 \
--allow-privileged=true \
--network-plugin=cni \
--cni-conf-dir=/etc/cni/net.d \
--cni-bin-dir=/opt/cni/bin \
--cert-dir=/etc/kubernetes/pki \
--v=2
Restart=always
RestartSec=10s
[Install]
WantedBy=multi-user.target
EOF
#--pod-infra-container-image 为Pod基础镜像
#--bootstrap-kubeconfig 上面拷贝的步骤
#--kubeconfig 这里是连接apiserver的信息
#--config 配置文件地址
2.生成kubelet.yaml配置文件
cat >> /opt/kubelet-conf.yml <<EOF
address: 0.0.0.0
apiVersion: kubelet.config.k8s.io/v1beta1
authentication:
anonymous:
enabled: false
webhook:
cacheTTL: 2m0s
enabled: true
x509:
clientCAFile: /etc/kubernetes/pki/ca.crt
authorization:
mode: Webhook
webhook:
cacheAuthorizedTTL: 5m0s
cacheUnauthorizedTTL: 30s
cgroupDriver: systemd
cgroupsPerQOS: true
clusterDNS:
- 10.96.0.10
clusterDomain: cluster.local
configMapAndSecretChangeDetectionStrategy: Watch
containerLogMaxFiles: 5
containerLogMaxSize: 10Mi
contentType: application/vnd.kubernetes.protobuf
cpuCFSQuota: true
cpuCFSQuotaPeriod: 100ms
cpuManagerPolicy: none
cpuManagerReconcilePeriod: 10s
enableControllerAttachDetach: true
enableDebuggingHandlers: true
enforceNodeAllocatable:
- pods
eventBurst: 10
eventRecordQPS: 5
evictionHard:
imagefs.available: 15%
memory.available: 100Mi
nodefs.available: 10%
nodefs.inodesFree: 5%
evictionPressureTransitionPeriod: 5m0s
failSwapOn: true
fileCheckFrequency: 20s
hairpinMode: promiscuous-bridge
healthzBindAddress: 127.0.0.1
healthzPort: 10248
httpCheckFrequency: 20s
imageGCHighThresholdPercent: 85
imageGCLowThresholdPercent: 80
imageMinimumGCAge: 2m0s
iptablesDropBit: 15
iptablesMasqueradeBit: 14
kind: KubeletConfiguration
kubeAPIBurst: 10
kubeAPIQPS: 5
makeIPTablesUtilChains: true
maxOpenFiles: 1000000
maxPods: 110
nodeLeaseDurationSeconds: 40
nodeStatusReportFrequency: 1m0s
nodeStatusUpdateFrequency: 10s
oomScoreAdj: -999
podPidsLimit: -1
port: 10250
registryBurst: 10
registryPullQPS: 5
resolvConf: /etc/resolv.conf
rotateCertificates: true
runtimeRequestTimeout: 2m0s
serializeImagePulls: true
staticPodPath: /etc/kubernetes/manifests
streamingConnectionIdleTimeout: 4h0m0s
syncFrequency: 1m0s
volumeStatsAggPeriod: 1m0s
EOF拷贝kubelet服务及配置
#这里分发的时候要写ip,因为后面有sed直接引用ip了
for NODE in 10.4.82.138 10.4.82.139 10.4.82.140 10.4.82.142; do
echo "--- $NODE ---"
#拷贝启动文件
scp /opt/kubelet.service $NODE:/lib/systemd/system/kubelet.service
#拷贝配置文件
scp /opt/kubelet-conf.yml $NODE:/etc/kubernetes/kubelet-conf.yml
#替换相关配置
ssh $NODE "sed -ri '/0.0.0.0/s#\S+\$#$NODE#' /etc/kubernetes/kubelet-conf.yml"
ssh $NODE "sed -ri '/127.0.0.1/s#\S+\$#$NODE#' /etc/kubernetes/kubelet-conf.yml"
done
###########
#sed 替换只是将原来的ip替换为本机IP
[root@k8s-master1 kubernetes]# grep -rn "10.4.82.138" kubelet-conf.yml
1:address: 10.4.82.138
44:healthzBindAddress: 10.4.82.138在k8s-master1 节点上启动所有节点的kubelet
#这里写主机名或者ip都ok
for NODE in 10.4.82.138 10.4.82.139 10.4.82.140 10.4.82.142; do
echo "--- $NODE ---"
ssh $NODE 'systemctl enable --now kubelet.service'
done验证集群
完成后在任意一台master节点并通过简单的指令验证
[root@k8s-master1 kubernetes]# kubectl get node
NAME STATUS ROLES AGE VERSION
k8s-master1 NotReady <none> 19s v1.13.5
k8s-master2 NotReady <none> 17s v1.13.5
k8s-node1 NotReady <none> 17s v1.13.5
k8s-node2 NotReady <none> 17s v1.13.5
这里同时自动签发认证
[root@k8s-master1 kubernetes]# kubectl get csr
NAME AGE REQUESTOR CONDITION
node-csr-0PvaysNOBlR86YaXTgkjKwoRFVXVVVxCUYR_X-_SboM 69s system:bootstrap:8c5a8c Approved,Issued
node-csr-4lKI3gwJ5Mv4Lh96rJn--mF8mmAr9dh5RC0r2iogYlo 67s system:bootstrap:8c5a8c Approved,Issued
node-csr-aXKiI5FgkYq0vL5IHytfrY5VB7UEfxr-AnL1DkprmWo 67s system:bootstrap:8c5a8c Approved,Issued
node-csr-pBZ3_Qd-wnkmISuipHkyE6zDYhI0CQ6P94LVi0V0nGw 67s system:bootstrap:8c5a8c Approved,Issued
#手动签发证书
kubectl certificate approve csr-l9d25
#csr-l9d25 为证书名称
或者执行kubectl get csr | grep Pending | awk '{print $1}' | xargs kubectl certificate approve3.7 Kubernetes Proxy Install
Kube-proxy概念
1.Service在很多情况下只是一个概念,而真正将Service实现的是kube-proxy
2.每个Node节点上都会运行一个kube-proxy服务进程
3.对每一个TCP类型的Kubernetes Service,Kube-proxy都会在本地Node节点上简历一个Socket Server来负责接收请求,然后均匀发送到后端某个Pod的端口上。这个过程默认采用Round Robin负载均衡算法。4.Kube-proxy在运行过程中动态创建于Service相关的Iptables规则,这些规则实现了Clusterip及NodePort的请求流量重定向到kube-proxy进行上对应服务的代理端口功能
5.Kube-proxy通过查询和监听API Server中Service和Endpoints的变化,为每个Service都建立一个"服务代理对象",并自动同步。服务代理对象是kube-proxy程序内部的一种数据结构,它包括一个用于监听此服务请求的Socker Server,Socker Server的端口是随机选择一个本地空闲端口,此外,kube-proxy内部创建了一个负载均衡器-LoadBalancer
6.针对发生变化的Service列表,kube-proxy会逐个处理
a.如果没有设置集群IP,则不做任何处理,否则,取该Service的所有端口定义和列表
b.为Service端口分配服务代理对象并为该Service创建相关的IPtables规则
c.更新负载均衡器组件中对应Service的转发地址列表7.Kube-proxy在启动时和监听到Service或Endpoint的变化后,会在本机Iptables的NAT表中添加4条规则链
a.KUBE-PORTALS-CONTAINER: 从容器中通过Cluster IP 和端口号访问service.
b.KUBE-PORTALS-HOST: 从主机中通过Cluster IP 和端口号访问service.
c.KUBE-NODEPORT-CONTAINER:从容器中通过NODE IP 和端口号访问service.
d. KUBE-NODEPORT-HOST:从主机中通过Node IP 和端口号访问service.
Kube-proxy是实现Service的关键插件,kube-proxy会在每台节点上执行,然后监听API Server的Service与Endpoint资源物件的改变,然后来依据变化执行iptables来实现网路的转发。这边我们会需要建议一个DaemonSet来执行,并且建立一些需要的Certificates。
a.二进制部署方式
创建一个kube-proxy的service account
Service Account为Pod中的进程和外部用户提供身份信息。所有的kubernetes集群中账户分为两类,Kubernetes管理的serviceaccount(服务账户)和useraccount(用户账户)
kubectl -n kube-system create serviceaccount kube-proxy将 kube-proxy 的 serviceaccount 绑定到 clusterrole system:node-proxier 以允许 RBAC
kubectl create clusterrolebinding kubeadm:kube-proxy \
--clusterrole system:node-proxier \
--serviceaccount kube-system:kube-proxy创建kube-proxy的kubeconfig
CLUSTER_NAME="kubernetes"
KUBE_CONFIG="kube-proxy.kubeconfig"
SECRET=$(kubectl -n kube-system get sa/kube-proxy \
--output=jsonpath='{.secrets[0].name}')
JWT_TOKEN=$(kubectl -n kube-system get secret/$SECRET \
--output=jsonpath='{.data.token}' | base64 -d)
kubectl config set-cluster ${CLUSTER_NAME} \
--certificate-authority=/etc/kubernetes/pki/ca.crt \
--embed-certs=true \
--server=${KUBE_APISERVER} \
--kubeconfig=/etc/kubernetes/${KUBE_CONFIG}
kubectl config set-context ${CLUSTER_NAME} \
--cluster=${CLUSTER_NAME} \
--user=${CLUSTER_NAME} \
--kubeconfig=/etc/kubernetes/${KUBE_CONFIG}
kubectl config set-credentials ${CLUSTER_NAME} \
--token=${JWT_TOKEN} \
--kubeconfig=/etc/kubernetes/${KUBE_CONFIG}
kubectl config use-context ${CLUSTER_NAME} --kubeconfig=/etc/kubernetes/${KUBE_CONFIG}
kubectl config view --kubeconfig=/etc/kubernetes/${KUBE_CONFIG}k8s-master1分发kube-proxy 的相关文件到所有节点
for NODE in k8s-master2 k8s-node1 k8s-node2; do
echo "--- $NODE ---"
scp /etc/kubernetes/kube-proxy.kubeconfig $NODE:/etc/kubernetes/kube-proxy.kubeconfig
done创建kube-proxy启动文件及配置文件
cat >> /opt/kube-proxy.conf <<EOF
apiVersion: kubeproxy.config.k8s.io/v1alpha1
bindAddress: 0.0.0.0
clientConnection:
acceptContentTypes: ""
burst: 10
contentType: application/vnd.kubernetes.protobuf
kubeconfig: /etc/kubernetes/kube-proxy.kubeconfig
qps: 5
clusterCIDR: "10.244.0.0/16"
configSyncPeriod: 15m0s
conntrack:
max: null
maxPerCore: 32768
min: 131072
tcpCloseWaitTimeout: 1h0m0s
tcpEstablishedTimeout: 24h0m0s
enableProfiling: false
healthzBindAddress: 0.0.0.0:10256
hostnameOverride: ""
iptables:
masqueradeAll: true
masqueradeBit: 14
minSyncPeriod: 0s
syncPeriod: 30s
ipvs:
excludeCIDRs: null
minSyncPeriod: 0s
scheduler: ""
syncPeriod: 30s
kind: KubeProxyConfiguration
metricsBindAddress: 127.0.0.1:10249
mode: "ipvs"
nodePortAddresses: null
oomScoreAdj: -999
portRange: ""
resourceContainer: /kube-proxy
udpIdleTimeout: 250ms
EOF
#生成启动文件
cat >> /opt/kube-proxy.service <<EOF
[Unit]
Description=Kubernetes Kube Proxy
Documentation=https://github.com/kubernetes/kubernetes
After=network.target
[Service]
ExecStart=/usr/local/bin/kube-proxy \
--config=/etc/kubernetes/kube-proxy.conf \
--v=2
Restart=always
RestartSec=10s
[Install]
WantedBy=multi-user.target
EOF拷贝kube-proxy及启动文件到所有节点
for NODE in 10.4.82.138 10.4.82.139 10.4.82.140 10.4.82.142;do
echo "--- $NODE ---"
scp /opt/kube-proxy.conf $NODE:/etc/kubernetes/kube-proxy.conf
scp /opt/kube-proxy.service $NODE:/usr/lib/systemd/system/kube-proxy.service
ssh $NODE "sed -ri '/0.0.0.0/s#\S+\$#$NODE#' /etc/kubernetes/kube-proxy.conf"
done
#sed替换bindAddress及healthzBindAddress在所有节点上启动kube-proxy服务
for NODE in 10.4.82.138 10.4.82.139 10.4.82.140 10.4.82.142; do
echo "--- $NODE ---"
ssh $NODE 'systemctl enable --now kube-proxy'
done通过ipvsadm查看proxy规则
[root@k8s-master1 k8s-manual-files]# ipvsadm -ln
IP Virtual Server version 1.2.1 (size=4096)
Prot LocalAddress:Port Scheduler Flags
-> RemoteAddress:Port Forward Weight ActiveConn InActConn
TCP 10.96.0.1:443 rr
-> 10.4.82.138:6443 Masq 1 0 0
-> 10.4.82.139:6443 Masq 1 0 0确认使用ipvs模式
curl localhost:10249/proxyMode
ipvsb.daemonSet部署方式
等会写
四、Kubernetes 集群网络
Kubernetes和Docker的网络有所不同,在Kuernetes中有四个问题是需要被解决的
- 高耦合的容器到容器通信:通过Pods内部localhost来解决
- Pod到Pod的通信:通过实现网络模型来解决
- Pod到Service通信:由解析服务结合kube-proxy来解决
- 外部到Service通信:一样由解析服务结合kube-proxy来解决
而Kubernetes对于任何网络的实现都有一下基本要求
- 所有容器能够在没有NAT模式下通信
- 所有节点可以在没有NAT模式下通信
Kubernetes 已经有非常多种的网络模型作为网络插件(Network Plugins)方式被实现,因此可以选用满足自己需求的网络功能来使用。另外 Kubernetes 中的网络插件有以下两种形式
- CNI plugins:以 appc/CNI 标准规范所实现的网络,CNI插件负责将网络接口插入容器网络命名空间并在主机上进行任何必要的更改。然后,它应该通过调用适当的IPAM插件将IP分配给接口并设置与IP地址管理部分一致的路由。详细可以阅读 CNI Specification。
- Kubenet plugin:使用 CNI plugins 的 bridge 与 host-local 来实现基本的 cbr0。这通常被用在公有云服务上的 Kubernetes 集群网络。
网络部署
以下部署方式任选其一
4.1 Flannel部署
flannel 使用 vxlan 技术为各节点创建一个可以互通的 Pod 网络,使用的端口为 UDP 8472,需要开放该端口(如公有云 AWS 等)。
flannel 第一次启动时,从 etcd 获取 Pod 网段信息,为本节点分配一个未使用的 /24 段地址,然后创建 flannel.1(也可能是其它名称,如 flannel1 等) 接口
本次安装需要所有节点pull镜像版本v0.11.0
for NODE in 10.4.82.138 10.4.82.139 10.4.82.140 10.4.82.142;do
echo "--- $NODE ---"
ssh $NODE "docker pull quay.io/coreos/flannel:v0.11.0-amd64"
done
##网络不好可以使用我的方法
for NODE in 10.4.82.138 10.4.82.139 10.4.82.140 10.4.82.142;do
echo "--- $NODE ---"
ssh $NODE "wget -P /opt/ http://down.i4t.com/flannel_v0.11.tar"
ssh $NODE "docker load -i /opt/flannel_v0.11.tar"
done当所有节点pull完镜像,我们修改yaml文件
wget http://down.i4t.com/kube-flannel.yml
sed -ri "s#\{\{ interface \}\}#eth0#" kube-flannel.yml
kubectl apply -f kube-flannel.yml
#配置网卡在master节点执行
$ kubectl get pod -n kube-system
NAME READY STATUS RESTARTS AGE
kube-flannel-ds-amd64-bjfdf 1/1 Running 0 28s
kube-flannel-ds-amd64-tdzbr 1/1 Running 0 28s
kube-flannel-ds-amd64-wxkgb 1/1 Running 0 28s
kube-flannel-ds-amd64-xnks7 1/1 Running 0 28s4.2 Calico部署
Calico
Calico整合了云原生平台(Docker、Mesos与OPenStack等),且Calico不采用vSwitch,而是在每个Kubernetes节点使用vRouter功能,并通过Linux Kernel既有的L3 forwarding功能,而当资料中心复杂度增加时,Calico也可以利用BGP route reflector来达成
Calico提供了Kubernetes Yaml文件用来快速以容器方式部署网络至所有节点上,因此只需要在Master上创建yaml文件即可
本次calico版本还是使用3.1
我们需要下载calico.yaml文件,同时在所有节点pull镜像
wget -P /opt/ http://down.i4t.com/calico.yml
wget -P /opt/ http://down.i4t.com/rbac-kdd.yml
wget -P /opt/ http://down.i4t.com/calicoctl.yml
for NODE in 10.4.82.138 10.4.82.139 10.4.82.140 10.4.82.142;do
echo "--- $NODE ---"
ssh $NODE "docker pull quay.io/calico/typha:v0.7.4"
ssh $NODE "docker pull quay.io/calico/node:v3.1.3"
ssh $NODE "docker pull quay.io/calico/cni:v3.1.3"
done
###如果网络不好,可以使用下面我提供的方式
for NODE in 10.4.82.138 10.4.82.139 10.4.82.140 10.4.82.142;do
echo "--- $NODE ---"
ssh $NODE "wget -P /opt/ http://down.i4t.com/calico.tar"
ssh $NODE "docker load -i /opt/calico.tar"
done
执行yaml文件
#替换网卡,我们默认使用eth0
sed -ri "s#\{\{ interface \}\}#eth0#" /opt/calico.yml
执行yaml文件
kubectl apply -f /opt/calico.yml
kubectl apply -f /opt/rbac-kdd.yml
kubectl apply -f /opt/calicoctl.yml检查服务是否正常
kubectl get pod -n kube-system --all-namespaces
NAMESPACE NAME READY STATUS RESTARTS AGE
kube-system calico-node-94hpv 2/2 Running 0 2m33s
kube-system calico-node-bzvj5 2/2 Running 0 2m33s
kube-system calico-node-kltt6 2/2 Running 0 2m33s
kube-system calico-node-r96k8 2/2 Running 0 2m33s
kube-system calicoctl-54567cf646-7xrw5 1/1 Running 0 2m32s通过 kubectl exec calicoctl pod 执行命令来检查功能是否正常
calicoctl 1.0之后calicoctl管理的都是资源(resource),之前版本的ip pool,profile, policy等都是资源。资源通过yaml或者json格式方式来定义,通过calicoctl create或者apply来创建和应用,通过calicoctl get命令来查看
1.找到calicoctl 容器
kubectl -n kube-system get po -l k8s-app=calicoctl
NAME READY STATUS RESTARTS AGE
calicoctl-54567cf646-7xrw5 1/1 Running 0 6m22s
2.检查是否正常
kubectl -n kube-system exec calicoctl-54567cf646-7xrw5 -- calicoctl get profiles -o wide
NAME LABELS
kns.default map[]
kns.kube-public map[]
kns.kube-system map[]
kubectl -n kube-system exec calicoctl-54567cf646-7xrw5 -- calicoctl get node -o wide
NAME ASN IPV4 IPV6
k8s-master1 (unknown) 10.4.82.138/24
k8s-master2 (unknown) 10.4.82.139/24
k8s-node1 (unknown) 10.4.82.140/24
k8s-node2 (unknown) 10.4.82.142/24网络安装完毕,此时k8s小集群已经可以使用,Node节点状态为Ready
4.3 CoreDNS
1.11后CoreDNS 已取代 Kube DNS 作为集群服务发现元件,由于 Kubernetes 需要让 Pod 与 Pod 之间能夠互相通信,然而要能够通信需要知道彼此的 IP 才行,而这种做法通常是通过 Kubernetes API 来获取,但是 Pod IP 会因为生命周期变化而改变,因此这种做法无法弹性使用,且还会增加 API Server 负担,基于此问题 Kubernetes 提供了 DNS 服务来作为查询,让 Pod 能夠以 Service 名称作为域名来查询 IP 位址,因此使用者就再不需要关心实际 Pod IP,而 DNS 也会根据 Pod 变化更新资源记录(Record resources)
CoreDNS 是由 CNCF 维护的开源 DNS 方案,该方案前身是 SkyDNS,其采用了 Caddy 的一部分来开发伺服器框架,使其能够建立一套快速灵活的 DNS,而 CoreDNS 每个功能都可以被当作成一個插件的中介软体,如 Log、Cache、Kubernetes 等功能,甚至能够将源记录存储在 Redis、Etcd 中
同样的步骤,所有节点pull镜像
for NODE in 10.4.82.138 10.4.82.139 10.4.82.140 10.4.82.142;do
echo "--- $NODE ---"
ssh $NODE "docker pull coredns/coredns:1.4.0"
done
###网络不好可以直接拉去我提供的镜像
for NODE in 10.4.82.138 10.4.82.139 10.4.82.140 10.4.82.142;do
echo "--- $NODE ---"
ssh $NODE "wget -P /opt/ http://down.i4t.com/coredns_v1.4.tar"
ssh $NODE "docker load -i /opt/coredns_v1.4.tar"
done
#拉完镜像下载yaml文件,直接执行即可
wget http://down.i4t.com/coredns.yml
kubectl apply -f coredns.yml执行完毕后,pod启动成功 (Running状态为正常)
kubectl get pod -n kube-system -l k8s-app=kube-dns
NAME READY STATUS RESTARTS AGE
coredns-d7964c8db-vgl5l 1/1 Running 0 21s
coredns-d7964c8db-wvz5k 1/1 Running 0 21s现在我们查看node节点,已经恢复正常
kubectl get node
NAME STATUS ROLES AGE VERSION
k8s-master1 Ready <none> 105m v1.13.5
k8s-master2 Ready <none> 105m v1.13.5
k8s-node1 Ready <none> 105m v1.13.5
k8s-node2 Ready <none> 105m v1.13.5CoreDNS安装完毕,可以直接跳到4.5进行验证
4.4 KubeDNS
Kube DNS是Kubernetes集群内部Pod之前互相沟通的重要插件,它允许Pod可以通过Domain Name方式来连接Service,通过Kube DNS监听Service与Endpoint变化,来进行解析地址
如果不想使用CoreDNS,需要先删除它,确保pod和svc不存在,才可以安装kubeDNS
kubectl delete -f /opt/coredns.yml
kubectl -n kube-system get pod,svc -l k8s-app=kube-dns
No resources found.创建KubeDNS
wget -P /opt/ http://down.i4t.com/kubedns.yml
kubectl apply -f /opt/kubedns.yml创建完成后我们需要查看pod状态
kubectl -n kube-system get pod,svc -l k8s-app=kube-dns
NAME READY STATUS RESTARTS AGE
pod/kube-dns-57f56f74cb-gtn99 3/3 Running 0 107s
pod/kube-dns-57f56f74cb-zdj92 3/3 Running 0 107s
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
service/kube-dns ClusterIP 10.96.0.10 <none> 53/UDP,53/TCP 108s安装完毕,可以直接跳到4.5进行验证
4.5 验证
温馨提示:busybox高版本有nslookup Bug,不建议使用高版本,请按照我的版本进行操作即可!
创建一个yaml文件测试是否正常
cat<<EOF | kubectl apply -f -
apiVersion: v1
kind: Pod
metadata:
name: busybox
namespace: default
spec:
containers:
- name: busybox
image: busybox:1.28.3
command:
- sleep
- "3600"
imagePullPolicy: IfNotPresent
restartPolicy: Always
EOF创建成功后,我们进行检查
kubectl get pod
NAME READY STATUS RESTARTS AGE
busybox 1/1 Running 0 4s使用nslookup查看是否能返回地址
kubectl exec -ti busybox -- nslookup kubernetes
Server: 10.96.0.10
Address 1: 10.96.0.10 kube-dns.kube-system.svc.cluster.local
Name: kubernetes
Address 1: 10.96.0.1 kubernetes.default.svc.cluster.local温馨提示一下:busybox镜像不要使用太高版本,否则容易出问题
https://my.oschina.net/zlhblogs/blog/298076
原文地址:https://k.i4t.com/kubernetes1.13_install.html
有问题可以直接在下面提问,看到问题我会马上解决!
转载于:https://blog.51cto.com/abcdocker/2408763














 2056
2056











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









