







特点
- 一个实现了JDBC API的jar包
- 客户端直连数据库,没有中间层
- 支持同时分表分库
- 读写分离
- 分布式主键
- 最终一致性事务(最大努力送达型)
- 多种配置方式:java, YAML, XML, Spring Boot Starter
- 分片配置集中化,动态化
核心概念
- LogicTable 数据分片的逻辑表,对于水平拆分的数据库(表),同一类表的总称。例:订单数据根据主键尾数拆分为10张表,分别是t_order_0到t_order_9,他们的逻辑表名为t_order。
- ActualTable 在分片的数据库中真实存在的物理表。即上个示例中的t_order_0到t_order_9。
- DataNode 数据分片的最小单元。由数据源名称和数据表组成,例:ds_1.t_order_0。配置时默认各个分片数据库的表结构均相同,直接配置逻辑表和真实表对应关系即可。如果各数据库的表结果不同,可使用ds.actual_table配置。
- BindingTable 指在任何场景下分片规则均一致的主表和子表。例:订单表和订单项表,均按照订单ID分片,则此两张表互为BindingTable关系。BindingTable关系的多表关联查询不会出现笛卡尔积关联,关联查询效率将大大提升。
- ShardingColumn 分片字段。用于将数据库(表)水平拆分的关键字段。例:订单表订单ID分片尾数取模分片,则订单ID为分片字段。SQL中如果无分片字段,将执行全路由,性能较差。Sharding-JDBC支持多分片字段。
整体架构
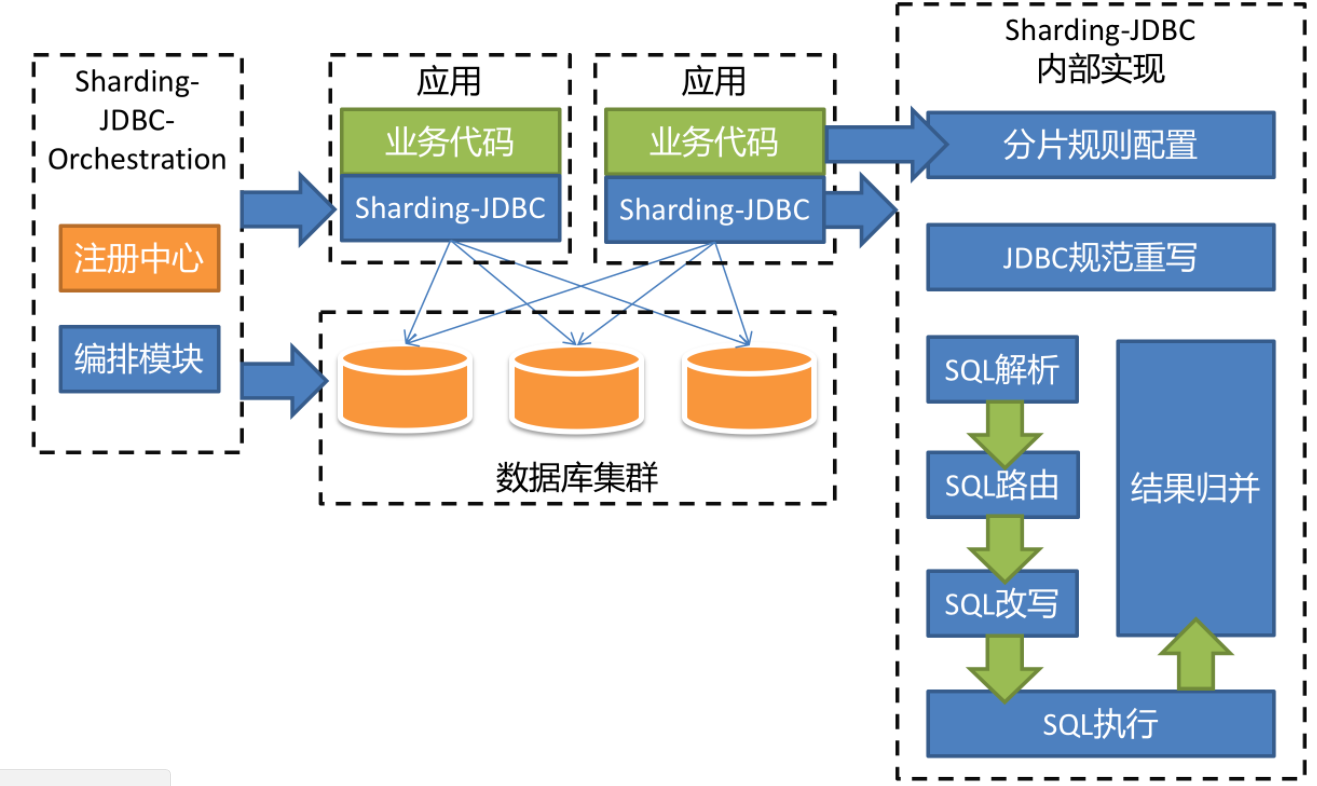
分片规则配置
| ds_0 ├── user_0 ├── user_1 ├── order_0 ├── order_1 | ds_1 |
分库键: user.id, order.user_id
分表键: user.id, order.user_id
分库算法: ${分片键} % 4 / 2
分表算法: ${分片键} % 4
SQL路由
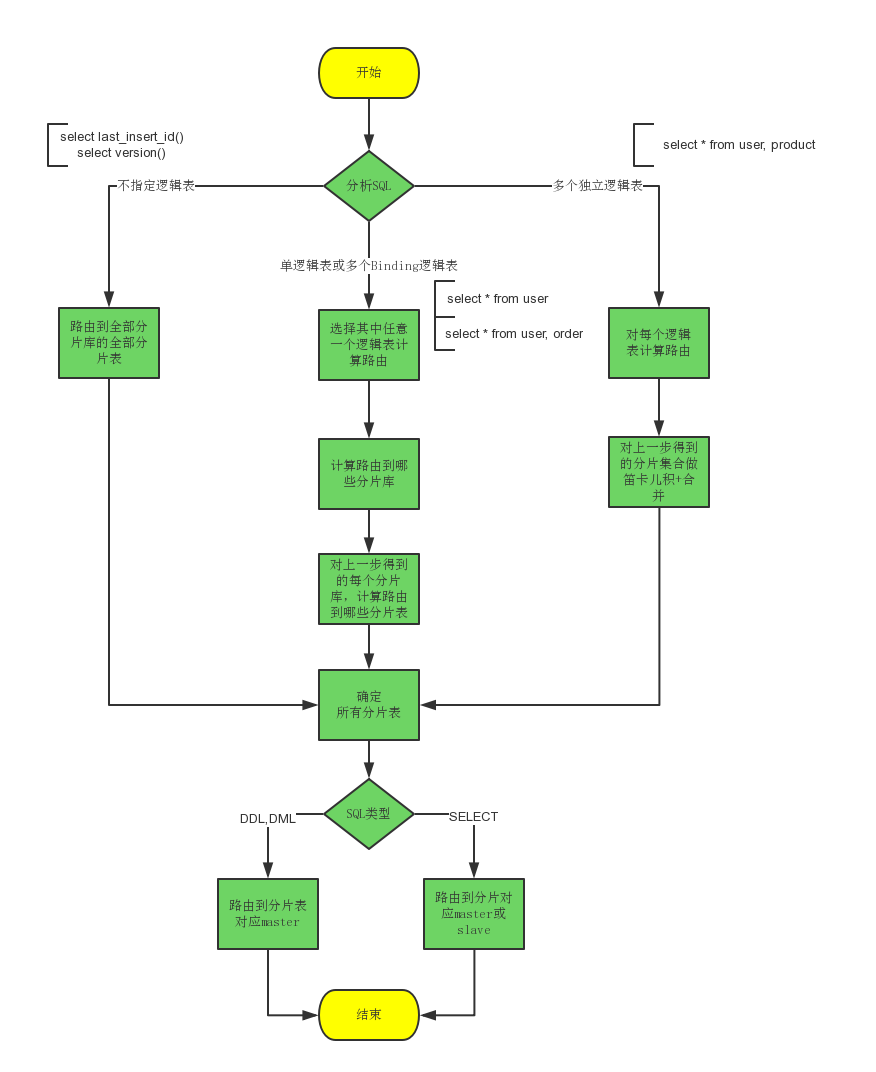
| Case | Logic SQL: | Actual SQL: |
|---|---|---|
| 没有指定分片键 | select * from user | ds_0 ::: select * from user_0 ds_0 ::: select * from user_1 ds_1 ::: select * from user_2 ds_1 ::: select * from user_3 |
| 指定分片键 | select * from user where id = 1 | ds_0 ::: select * from user_1 where id = 1 |
| 绑定表join | select * from user, order where user.id = order.user_id | ds_0 ::: select * from user_0, order_0 where user_0.id = order_0.user_id ds_0 ::: select * from user_1, order_1 where user_1.id = order_1.user_id ds_1 ::: select * from user_2, order_2 where user_2.id = order_2.user_id ds_1 ::: select * from user_3, order_3 where user_3.id = order_3.user_id |
| 自动生成id作为分片键 | insert into user(username, password, channel) values('terry', '123456', 'OFFLINE') | ds_0 ::: insert into user_1(username, password, channel, id) values('terry', '123456', 'OFFLINE', 5595064747165309) |
SQL改写
| Case | Logic SQL: | Actual SQL: |
|---|---|---|
| 换表名 | select * from user where id = 1 | ds_0 ::: select * from user_1 where id = 1 |
| 自动生成分布式主键 | insert into user(username, password, channel) values('terry', '123456', 'OFFLINE') | ds_0 ::: insert into user_1(username, password, channel, id) values('terry', '123456', 'OFFLINE', 5595064747165309) |
| 翻页 | select * from order order by amount limit 100, 10 | ds_0 ::: select * from order_0 order by amount limit 0, 110 ds_0 ::: select * from order_1 order by amount limit 0, 110 ds_1 ::: select * from order_2 order by amount limit 0, 110 ds_1 ::: select * from order_3 order by amount limit 0, 110 |
| 聚合函数 | select avg(amount) from order | ds_0 ::: select avg(amount) , COUNT(amount) AS AVG_DERIVED_COUNT_0 , SUM(amount) AS AVG_DERIVED_SUM_0 from order_0 ds_0 ::: select avg(amount) , COUNT(amount) AS AVG_DERIVED_COUNT_0 , SUM(amount) AS AVG_DERIVED_SUM_0 from order_1 ds_1 ::: select avg(amount) , COUNT(amount) AS AVG_DERIVED_COUNT_0 , SUM(amount) AS AVG_DERIVED_SUM_0 from order_2 ds_1 ::: select avg(amount) , COUNT(amount) AS AVG_DERIVED_COUNT_0 , SUM(amount) AS AVG_DERIVED_SUM_0 from order_3 |
结果合并
order by sql的结果集合并使用归并排序算法, 一边遍历一边排序,无需放到内存中排序.
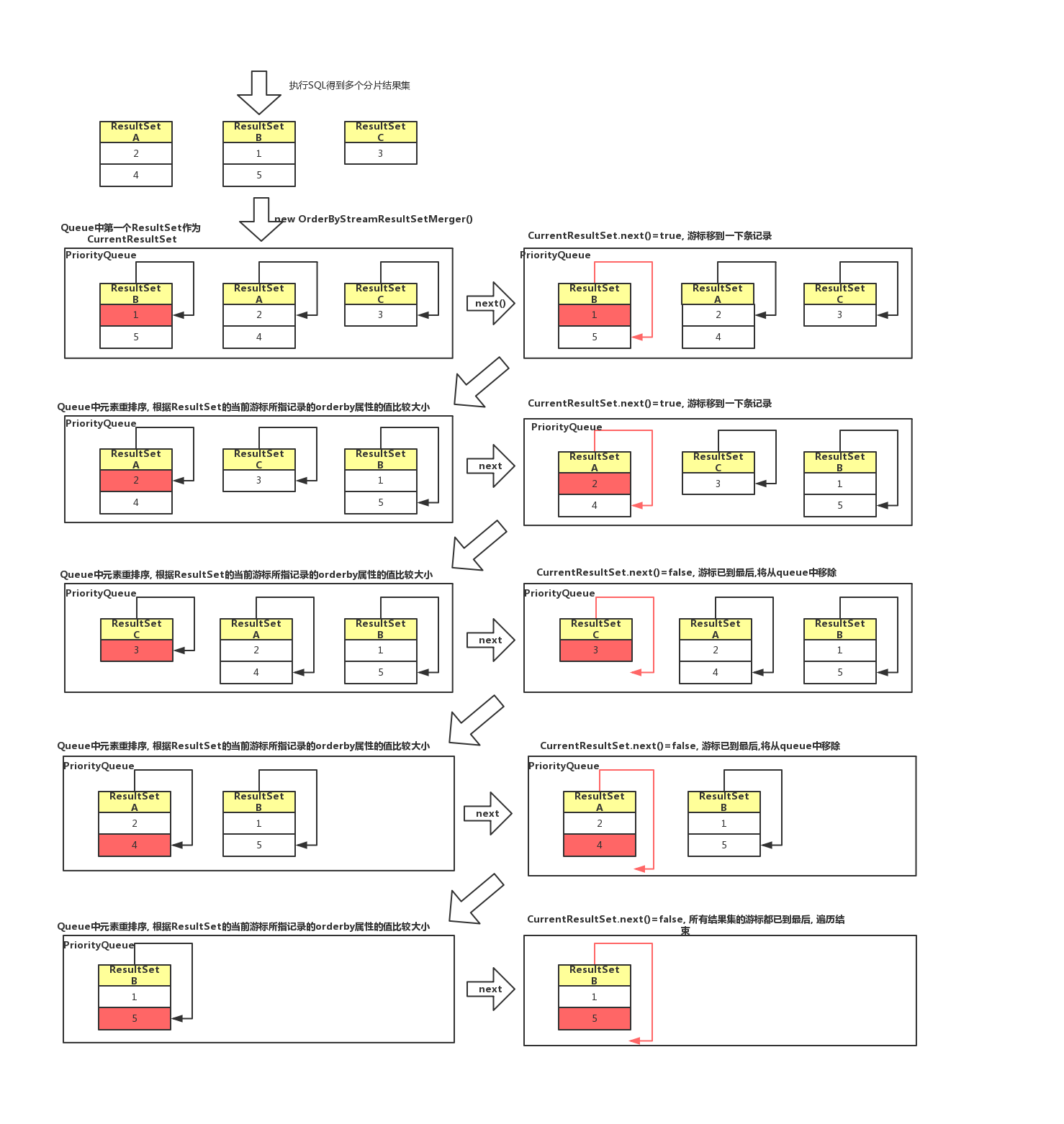
| Case | Logic SQL: | 合并算法 |
|---|---|---|
| 仅合并 | select * from user | merge(resultset1, resltset2, ..resultsetN) |
| order by | select * from user order by id | sort(merge(resultset1, resltset2, ..resultsetN) |
| sum, count | select count(*) from user | count1 + count2 +.. countN |
| 分组聚合 | select count(*), user_id from order group by user_id | (count1 + count2 +.. countN) group by user_id |
| avg | select avg(amount) from order | (sum1 + sum2 +.. sumN) / count1 + count2 +.. countN |
| max, min | select max(amount) from order | max(max1, max2, ..maxN) |
| 分页 | select * from order limit 100, 10 | merge(limit1(0, 110) + limit2(0, 110) + limitN(0,110)) -> limit(100, 10) |
SQL执行
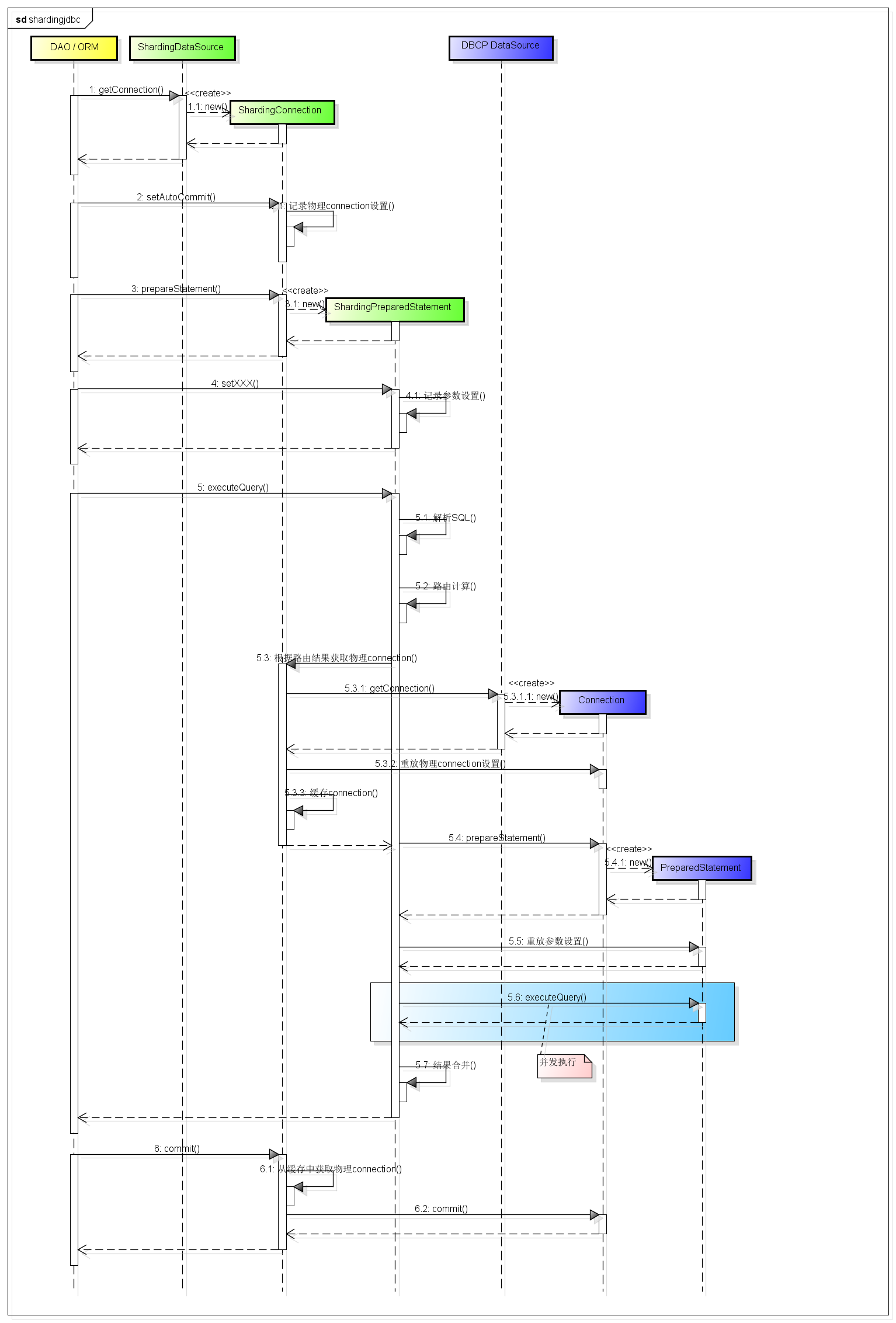
示例
// 配置真实数据源
Map<String, DataSource> dataSourceMap = new HashMap<>();
// 配置第一个数据源
BasicDataSource dataSource1 = new BasicDataSource();
dataSource1.setDriverClassName("com.mysql.jdbc.Driver");
dataSource1.setUrl(jdbcurl + "mycat_demo00");
dataSource1.setUsername(username);
dataSource1.setPassword(password);
dataSourceMap.put("ds_0", dataSource1);
// 配置第二个数据源
BasicDataSource dataSource2 = new BasicDataSource();
dataSource2.setDriverClassName("com.mysql.jdbc.Driver");
dataSource2.setUrl(jdbcurl + "mycat_demo01");
dataSource2.setUsername(username);
dataSource2.setPassword(password);
dataSourceMap.put("ds_1", dataSource2);
// 配置表规则
TableRuleConfiguration userTableRuleConfig = new TableRuleConfiguration();
userTableRuleConfig.setLogicTable("user");
userTableRuleConfig.setActualDataNodes("ds_0.user_${0..1}, ds_1.user_${2..3}");
userTableRuleConfig.setKeyGeneratorColumnName("id");
TableRuleConfiguration orderTableRuleConfig = new TableRuleConfiguration();
orderTableRuleConfig.setLogicTable("order");
orderTableRuleConfig.setActualDataNodes("ds_0.order_${0..1}, ds_1.order_${2..3}");
orderTableRuleConfig.setKeyGeneratorColumnName("id");
// 配置分库策略
userTableRuleConfig.setDatabaseShardingStrategyConfig(new InlineShardingStrategyConfiguration("id", "ds_${(id % 4).intdiv(2)}"));
orderTableRuleConfig.setDatabaseShardingStrategyConfig(new InlineShardingStrategyConfiguration("user_id", "ds_${(user_id % 4).intdiv(2)}"));
// 配置分表策略
userTableRuleConfig.setTableShardingStrategyConfig(new InlineShardingStrategyConfiguration("id", "user_${id % 4}"));
orderTableRuleConfig.setTableShardingStrategyConfig(new InlineShardingStrategyConfiguration("user_id", "order_${user_id % 4}"));
// 配置分片规则
ShardingRuleConfiguration shardingRuleConfig = new ShardingRuleConfiguration();
shardingRuleConfig.setDefaultKeyGeneratorClass("io.shardingjdbc.core.keygen.DefaultKeyGenerator");
shardingRuleConfig.getTableRuleConfigs().add(userTableRuleConfig);
shardingRuleConfig.getTableRuleConfigs().add(orderTableRuleConfig);
shardingRuleConfig.getBindingTableGroups().add("user, order");
// 获取数据源对象
Properties properties = new Properties();
properties.put("sql.show", "true");
DataSource dataSource = ShardingDataSourceFactory.createDataSource(dataSourceMap, shardingRuleConfig, new ConcurrentHashMap(), properties);















 370
370

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









