







1.先来说说,我为什么要来理解jvm的逻辑和模型?
很简单,面试的时候会被问;
2.多线程中线程的运行是在jvm里怎么运行的?定义的数据在jvm里的哪里存放?为什么多线程下数据的修改会影响读到的值不是期待的?带着这些疑问,咱们来学习jvm的模型
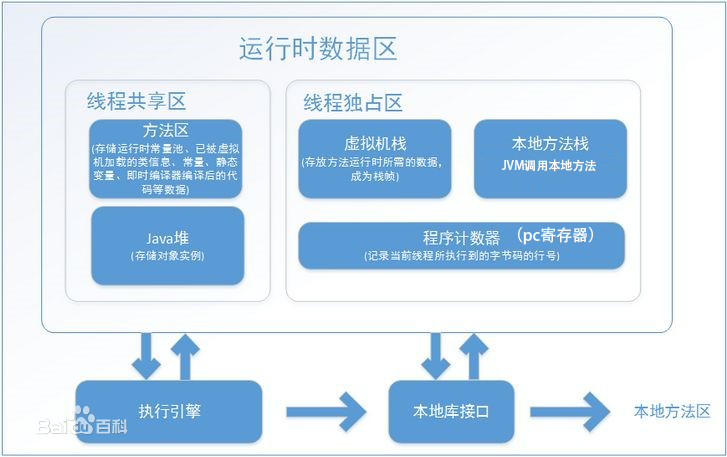
上图是jvm的模型,咱们大体可以将jvm分为方法区,堆内存(Java堆),栈内存(虚拟机栈和本地方法栈)、程序计数器(pc寄存器),执行引擎和本地库接口
每一块的作用基本都在图上标出来了
在吉利曹操专车的时候面试官问了我一个问题:说一个class类的名称存在哪里?我当时没有回到上来,记住了大家,类的信息都存在方法区里,所以类的名字在方法区
栈内存:存放方法运行时所需要的数据
堆是用来存放对象的地方,你可以将new理解为给堆内存创建对象的关键字,所有new出来的,都在堆内存中,比如Integer a = new Integer(1);这个语句大家都会,但是它的逻辑是什么呢,就是int i=1;Object o=new Object; Object a=i;解释就是,先在方法区中创建了1,然后在堆内存中创建了个地址,用来存放的值与栈内存中的1相等,也就是1,最后a=1;就是在方法区内存中开创了一个存放指向堆内存中那个1的指针的地址,名字叫做a;所以a只是具体值在内存中的地址别名。这是运行中的变化;int i =1;在方法区,new出来的都在堆内存
为什么要分栈内存和堆内存,内存中运行速度不是很快吗?
有句话叫没有最快,只有更快。以为堆内存中存了对象,但是对象是比较占内存的,会影响计算速度,而很多对象又是很多基础类型构造成的,所以又划分出来了一块区域,栈内存,它用来存储运行时所需的基本数据类型和一些计算逻辑,例如加减乘除…因为栈内存数据少,所以我们可以叫他高速内存
接下来咱们说线程,在线程中说说堆,方法区域之间是怎么运行的
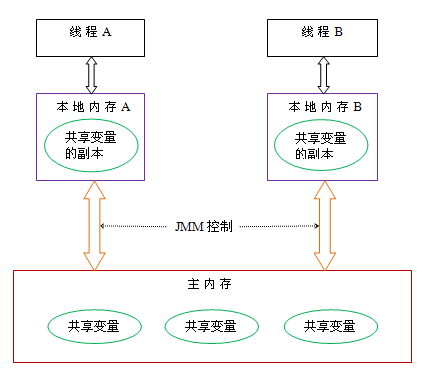
线程就是把栈内存分割到再细,让不同栈内存单元去执行不同的事情
上图的解释:创建了两个线程A,B,也就是高速内存中,线程在对共享内存中的数据修改的逻辑时,会先把所需的数据复制一份到高速内存中,等执行完,再将这个值更新到主内存中;
/**
* @author: TonyStarkSir
* @date: 2018/04/09/22/05
* @Description:
* @Modifed:
**/
public class VolatileTest {
volatile int a =0;
int b=1;
public void modify(){
a =100;
b=a+111;
}
public void read(){
System.out.println("b= " + b);
}
public static void main(String args[]){
final VolatileTest volatileTest =new VolatileTest();
Thread thread1 =new Thread(new Runnable() {
@Override
public void run() {
volatileTest.modify();
}
});
Thread thread2 =new Thread(new Runnable(){
@Override
public void run(){
volatileTest.read();
}
});
thread2.start();
try {
Thread.sleep(1000);
} catch (InterruptedException e) {
e.printStackTrace();
}
thread1.start();
}
}如果不用多线程,不用volatile修饰变量,read到的b应该是211;但是在多线程中就不一定了,结合jvm,线程A将a=0复制到栈内存中计算,还没更新在共享主内存中的值时,read的线程就会得到0+100=100;为了避免这种现象,咱们定义的时候可以用volatile修饰变量,volatile修饰的变量都是在主内存中,并且申明线程不准将它复制到高速内存中去,这样每次线程都在主内存中获取值,这个值就不会误读。
其实jvm是一个抽象出来的概念,咱们只要搞懂堆和栈就可以了,或者你可以将jvm看做堆和栈,栈用来存放所需的基本数据类型和堆内存对象的引用,以及存放对象的方法
堆中存放对象
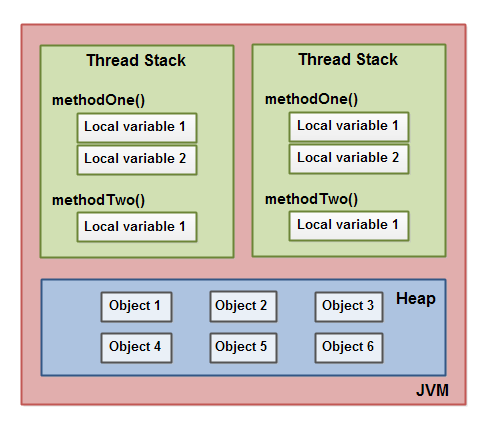
一个本地变量如果是原始类型,那么它会被完全存储到栈区。
一个本地变量也有可能是一个对象的引用,这种情况下,这个本地引用会被存储到栈中,但是对象本身仍然存储在堆区。
对于一个对象的成员方法,这些方法中包含本地变量,仍需要存储在栈区,即使它们所属的对象在堆区。
对于一个对象的成员变量,不管它是原始类型还是包装类型,都会被存储到堆区。
Static类型的变量以及类本身相关信息都会随着类本身存储在堆区。
堆中的对象可以被多线程共享。如果一个线程获得一个对象的应用,它便可访问这个对象的成员变量。如果两个线程同时调用了同一个对象的同一个方法,那么这两个线程便可同时访问这个对象的成员变量,但是对于本地变量,每个线程都会拷贝一份到自己的线程栈中。
下图展示了上面描述的过程:
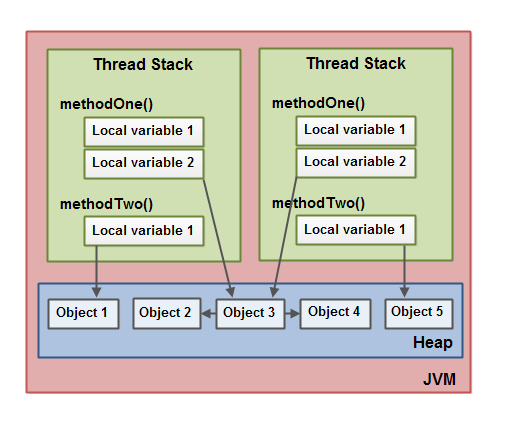
如果了解jvm的数据存储,会对理解多线程大有帮助;
JVM调优,以后文章见















 1105
1105

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









