






##=====================================================================================##
在数据库表设计中会纠结于”自然键”和”代理键”的选择,自然键在实现数据“软删除”时实现比较复杂,部分自然键因为键值过长或多列组合导致不适合作为表主键,而比较常见两种代理键为自增列(auto incremnet)和全局唯一标识列(GUID)。
使用自增列作为主键的优缺点:
1、 主键键值长度短,INT列需要4个字节,BIGINT列需要8个字节;
2、 自增主键顺序递增,在INSERT操作时”顺序”写入表;
3、 由于数据集中插入到表尾部,在高并发情况下容易造成”数据页热点”,影响插入效率;
4、 自增主键只能保证在表内数据唯一,对于分库分表场景,可能因错误操作产生相同的“唯一值”。
使用GUID列的优缺点:
1、 32位GUID字符串需要更多的存储空间来存放(具体存储长度与字符集相关),影响主键和其他索引的查询性能。
2、 GUID可实现全局唯一,能保证在多个表之间的数据唯一性
3、 GUID将数据分散到全表,不会产生热点数据页,但会造成大量随机IO读写
在实际使用过程中,很少场景会使用GUID作为主键,大部分业务按照数据量需求使用INT或BIGINT的自增列作为主键,对于需要多表唯一的场景可以通过程序实现全局唯一的自增ID。
##=====================================================================================##
MySQL在很早版本便支持自增列并在各版本中优化自增列功能,在MySQL 5.1.22版本引入轻量级互斥自增长实现机制,MySQL 5.5版本中引入change buffer特性,在MySQL 8.0版本引入自增列持久化。针对目前京东主要使用MySQL 5.5/5.6/5.7三个主版本,罗列部分使用自增列需要掌握的知识点:
知识点1:自增列数据类型选择问题
自增列除常见的TINYINT/SMALLINT/INT/BIGINT等整数数据类型外,还可以使用FLOAT等浮点数数据类型,但强烈建议不使用非整数数据类型作为自增列。
选取数据类型时:
1、 按照所需要范围值进行最小化选取,如果只需要0-20的范围值,则选择可以存放-128到127数值的TINYINT。
2、 当所需自增范围值不确定时,建议选择足够使用的数据类型,先保证数据安全再考虑操作性能,相同数据量下,使用BIGINT并不会比使用INT带来太多性能影响。京东订单号在前期设计时使用INT数据类型,当INT无法满足需求时,商城花费大量资源进行INT到BIGINT的升级改造,同时影响诸多关联系统。
##=====================================================================================##
知识点2:自增列跳号问题
1、无论MySQL还是其他关系型数据库,为提高自增列的生成效率,都将生成自增值的操作设计为非事务性操作,表现为当事务回滚时,事务中生成的自增值不会被回滚。
2、当对自增表进行批量插入时(INSERT … SELECT …),即使在单一会话下,MySQL仍不能保证两次获取到的自增ID值连续,批量插入数据量越大,产生的自增ID跳号范围越大。
自增跳号对普通业务没有太多影响,但对于像发票这类要求号码连续的业务,不能通过自增列来实现。
##=====================================================================================##
知识点3:自增列持久化问题
在MySQL 5.5/5.6/5.7三个版本中,MySQL并不会将自增列分配的自增值信息固化到磁盘,当MySQL重启后,会根据自增列上当前最大值和参数auto_increment_offset来确定下一次的自增值,为快速获取自增列上最大值,MySQL要求自增列必须建有索引。如果一张自增表的数据在重启实例前被清空,实例重启后该表数据会从”1”开始自增(假设表的自增初始值定义为1)。
在一次亚一数据库升级过程中,某张业务表”恰好”因为业务逻辑将表中所有数据删除,重启后该表自增值从1开始生成,当该表数据流转到其他表出现数据冲突,发现问题后,我们紧急手动设置该表自增值,避免事故进一步恶化,并再后期类似操作时,重点关注此类自增表。
建议1:如果业务会对自增表数据进行硬删除,在服务器重启前应重点关注该自增表使用的自增值,可以通过information_schema.tables中的auto_increment列来获取。
PS1:在MySQL 8.0中引入自增列持久化特性,可以避免上述问题。
##=====================================================================================##
知识点4:自增列初始值问题
在运维过程中,会遇到研发同事问为什么新创建的表不是从1开始自增,该问题可以从以下两个角度排查:
1、 建表语句,在使用SHOW CREATE TABLE或MySQLDump等命令导出表结构时,会包含该表当前使用的自增值,如:
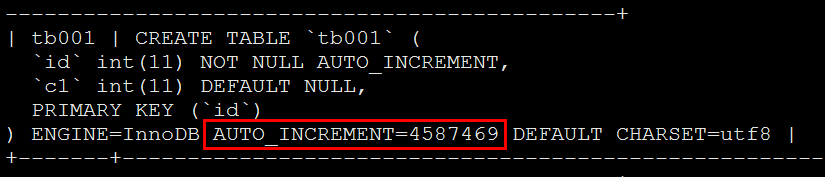
2、 全局参数auto_increment_increment和auto_increment_offset,这两全局参数可以作用实例下所有自增表,主要应用在分库分表的场景。
##=====================================================================================##
知识点5:修改数据列为自增数据列
当数据类型为数值类型且表中数据唯一时,可以将该数据列转换为自增列,修改操作会保持列中现有数据,不会重新生成新数据。
##=====================================================================================##
知识点6:修改普通表为自增表
在MySQL中允许使用ALTER TABLE方式为普通表新增一个自增列,但由于ALTER操作为DDL语句,在主从复制时会将该DDL语句传递给从库执行,MySQL并不能保证相同记录在主从服务器上获得相同的自增ID,会导致主从数据差异。
模拟测试:
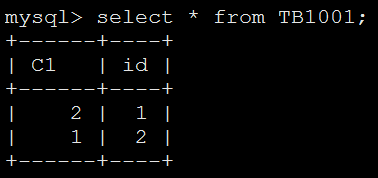
主库上创建表: CREATE TABLE TB1001 ( C1 INT ); 会话1开启事务并执行: START TRANSACTION; INSERT INTO TB1001(C1) SELECT 1; 会话2执行: INSERT INTO TB1001(C1) SELECT 2; 会话1提交事务。 然后将表修改为自增表: ALTER TABLE TB1001 ADD ID INT PRIMARY KEY AUTO_INCREMENT;
主库数据为:

从库数据为:
原因分析:
在主库上,C1=2的数据晚于C1=1的数据被插入,但由于C1=2的数据所在事务被先提交,因此C1=2的记录先于C1=1的记录在从库上执行,因此两条记录在主库和从库上的插入顺序不同,在生成自增ID时获得到自增ID不同,最终导致数据差异。
建议:在将普通表修改为自增表时,如果表中存在数据,请勿使用ALTER TABLE的方式修改,建议新建自增临时表,然后将数据导入到该表中,再兑换表名。
##=====================================================================================##
















 6535
6535











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









