






前言
用了一段时间T-SQL之后。哪怕自己没用过,也多多少少看过SSMS中的SET NOCOUNT ON命令,非常多性能优化文章中都有提到这个东西,它们建议尽可能使用这个命令降低网络传输的压力。那么今天来看看它是否是个鸡肋。
SET NOCOUNT的作用
在说明中的“备注”部分有这么一段话,注意红字部分:
假设大家对上面的DONE_IN_PROC有兴趣,能够看看这篇文章: https://msdn.microsoft.com/en-us/library/dd340553.aspx,可是我觉得不是必需过于纠结。
以下创建一个測试样例,并做演示:
USE tempdb
GO
IF object_id('NocountDemo', 'U') IS NOT NULL
DROP TABLE NocountDemo
GO
CREATE TABLE NocountDemo(
id INT identity(1, 1),
NAME VARCHAR(64)
)
GO
/*
插入測试数据
*/
INSERT INTO NocountDemo
SELECT NAME
FROM master..spt_values
/*
常规使用
*/
SELECT *
FROM NocountDemo
GO
/*
使用SET NOCOUNT选项
*/
SET NOCOUNT ON;
SELECT *
FROM NocountDemo
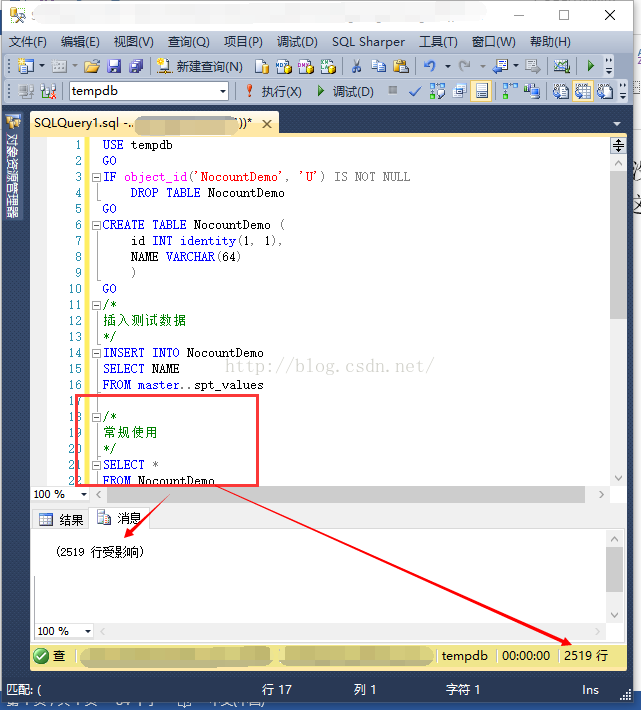
SET NOCOUNT OFF;首先看看默认情况。也就是SET NOCOUNT OFF的结果:
然后看看开启NOCOUNT选项的结果:
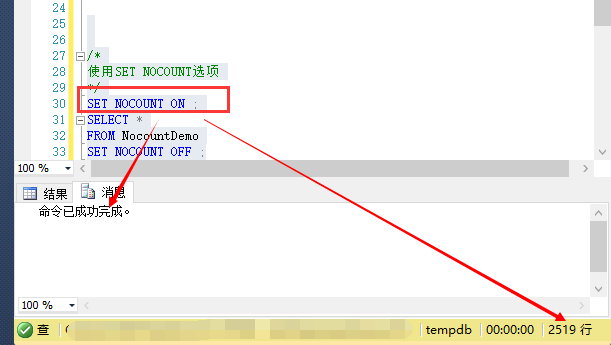
默认情况下,不论什么SQL语句成功完毕后都会返回一些信息。而NOCOUNT用于控制是否返回影响行数,须要提醒的是。哪怕不是真正的SQL语句。比方开启包括实际运行计划功能,当运行计划成功完毕后(注意是完毕),也会返回影响行数到client(也就是这里的SSMS)。
可是从实操层面,大家是否差点儿没有关注过这个信息?确实,是否成功运行完非常多时候不须要查看这个信息,一些SELECT语句自然会返回数据结果。所以实际上这个信息经常是非必要的。
作为最佳实践。一般建议不返回影响行数,特别是存储过程。只是有时候它又有存在价值。比方应用程序嵌入的SQL语句的调试。
在非常多性能优化的文章中(甚至前面提到的官方文档)都提到。为了减轻网络压力,建议启用这个设置(注意一点。这个设置和其它非常多设置不同,它默认是“开启”的,也就是说我们须要做“关闭”操作,而非常多操作是须要做“开启”操作)。这个原因貌似非常合理,只是作为DBA的习惯。我更愿意深究底层原理。所以以下再看个简单样例,插入一条数据后,循环更新100万次,并获取时间差:
SET NOCOUNT OFF;
DECLARE @i INT = 1;
DECLARE @x TABLE (a INT);
INSERT @x (a)
VALUES (1);
SELECT SYSDATETIME() AS [開始时间];
WHILE @i < 1000000
BEGIN
UPDATE @x
SET a = 1;
SET @i += 1;
END
SELECT SYSDATETIME() AS [结束时间];
在我本机上运行情况例如以下图:
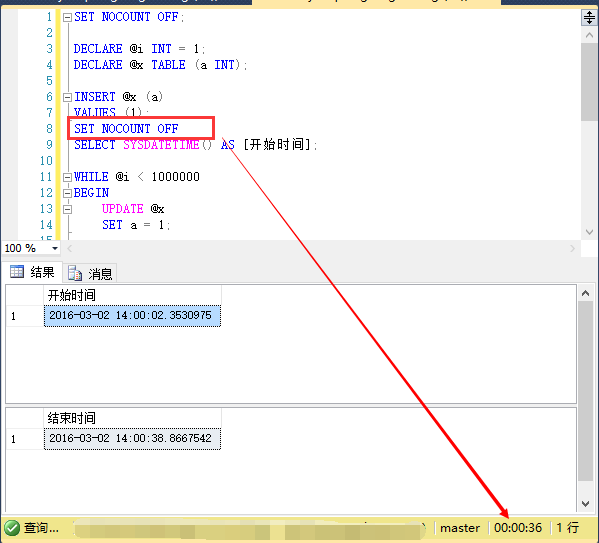
本文重点关注的是影响行数,所以我们先看影响行数的情况,选择结果集中的【消息】页
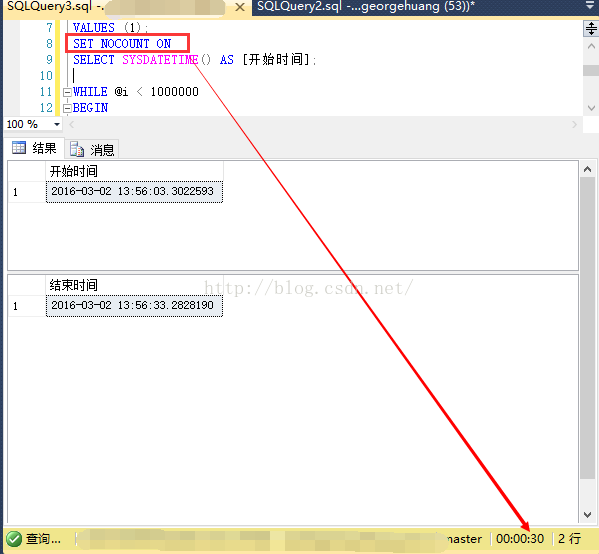
从右边的滚动栏能够大概预估这个行数应该非常多。实际上每次insert都有一行。外加循环外层的SELECT SYSDATETIME() ,总共10000002行。然后关闭返回影响行数,即使用SET NOCOUNT命令又一次运行:
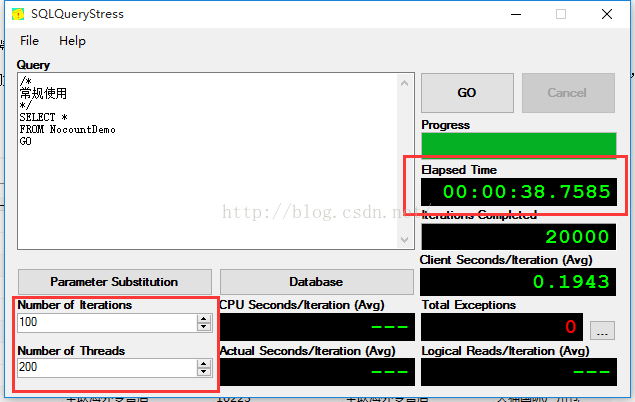
为了避免有人觉得測试没考虑并发问题,我使用SQLQueryStress工具分别对上面两套语句模拟200个线程运行100次(本机配置太低无法运行太多次):
默认情况重复运行多次:
开启NOCOUNT的情况下:
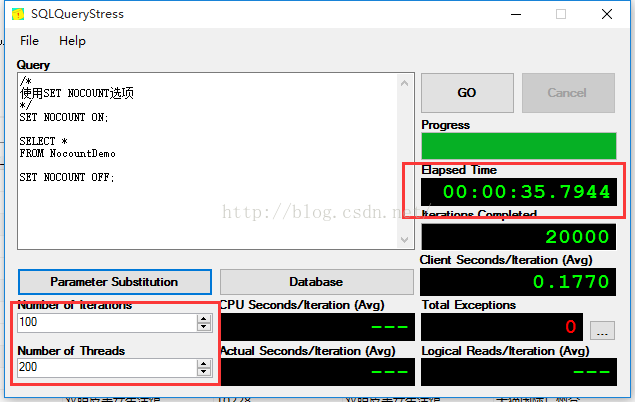
对照一下时间,差异时间不明显,假设多运行几次可能会出现反而更慢的情况。难道网上说的是假的?先别下定论,那问题在哪里?我们再回过头看看别人的描写叙述里面的keyword“网络传输”。貌似发现问题了,由于一直以来都在单机上面測试,并且检查一下SQL Server配置管理器中的网络协议,Shared Memory是开启了。也就是说数据都在内存中传输,跟“网络”没什么关系:
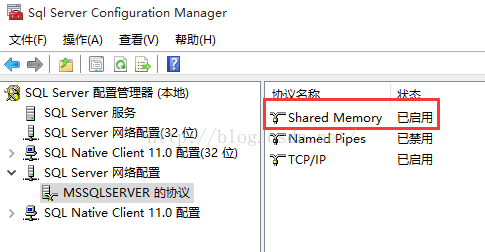
那么看来问题就是这个原因。如今随便找台机器再试一下,我在国际版的Azure上开了个SQL Azure(开VM再装SQL Server实在耗时并且费用不少)。假设没有条件的能够找些測试server甚至别人的电脑试试。
如今我在本机直接连到美国的SQL Azure上。然后再次分别运行上面的两个语句(为了避免时间过久,把100万次改为10万次):
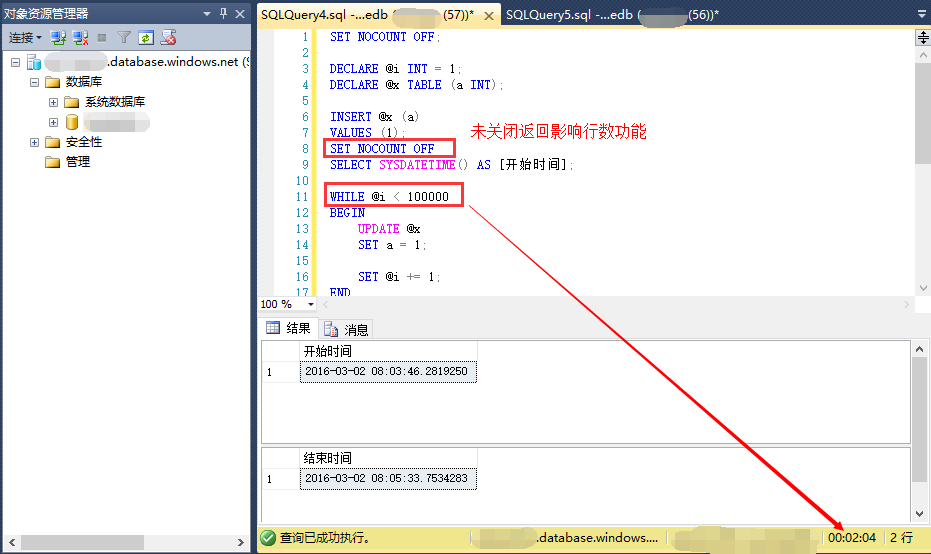
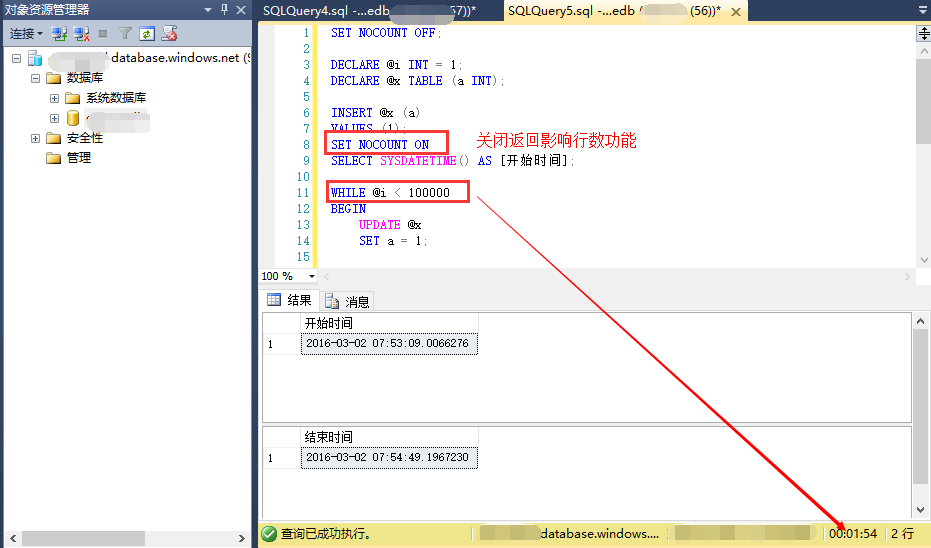
时间对照之后发现,事实上相差不大。我们最好还是静下来想一下,即使100万次,产生的数据也就几十上百Bytes或者KB,对今时今日的硬件来说不可能出现明显的性能提升,之所以网上有这个说法,非常可能是当初的硬件资源存在局限。无法满足今天看起来不算大的数据量。可是无论怎样。个人看来,这些确实也有一定的消耗。作为编程习惯,在非必要的情况下还是建议不返回。毕竟真的没什么人用。
问题提炼
对于这个问题,我想到了两件事情:怎样对待别人的“善意”和降低网络传输
1.怎样对待别人的“善意”
近期上下班路上在看一本书。看完再分享一下。书上多处地方提到一个句子:One thing doesn’t fit all。
说白了就是“放之四海而皆准”的反义词。我个人挺赞同这个观点。为什么非要用一个产品去实现全部功能呢?今时今日大量系统的架构都使用了非常多混合技术,这也证明了这个观点的可行性。那么回归这个问题。当初别人提出这个优化或编程建议时,确实可能存在网络性能问题、甚至client(本例中的SSMS)的内存资源压力从而造成性能压力。正如20年前Oracle优化书籍中提到的一个表索引数不要超过5个、索引叶子节点不要缓存到内存这类建议一样。当年的硬件资源确实没办法非常好支持这些特性。再看今天,软硬件已经有了长足的发展,非常多当初是对的设置今天看起来已经无关重要甚至是错误的。所以在对待非常多所谓的“军规”、“铁律”时,还是要自己实測一下或者论证一下。
从本例中看,它不会有什么严重的后果和风险。所以是能够測试的。可是有些风险比較大的最好谨慎測试。
我个人觉得,作为一些编程规范,最好还是保留下来。由于它和以下这个有关系。在编程的时候要有降低资源使用的惯性思维。
那什么时候实用呢?前面提到了——查错
在我初为DBA的时候,有一次一个开发问我:为什么明明插入了一条数据到一个表里面。并且成功了,表却没有数据。一開始我以为是回滚,问她要完整的语句,拿过来之后发现就一个简单的insert命令。没有显式事务。然后我自己运行了一下,确实没数据。再看一下影响行数。居然有两条(1 行受影响),这就引起我的注意了,检查表触发器。果然有一个触发器,并且功能就是一旦有插入动作,立即触发删除。
也就是来一个死一个。来两个死一双。
基于这些原因,我觉得详细问题详细分析才是最有意义的,哪来那么多所谓的意见建议,不考虑详细环境的建议都是耍流氓。
2.降低网络传输
之所以当初有这个说法。非常大程度是由于网络传输压力。那么我们借助这个问题,引申其它资源合理使用的场景。这里说的是网络问题,那就说网络问题吧,单纯从数据库层面来说。通常网络压力在哪里呢?据本人了解。大概在这些方面:
a) 须要传输的数据量,这是真正的网络压力。
量越大压力越明显,那么通常我们要做的就是在返回数据时,尽可能控制数据量,比方不要在非必要情况下使用SELECT *,尽可能在离开数据层的时候就把数据量控制下来。
b) 其它功能传输的信息,比方SQL Server一些高可用或者负载分离功能。就拿复制功能来说,为了使订阅server的数据与公布server的数据一致。公布server会依据实际配置实时或定时发送事务日志到订阅端重做,日志产生越多,须要传输的量就越多,对于这部分你能干预的地方就非常少。非要做的话。能够在配置公布项时仅仅选择须要同步的行与列。
c) SQL语句,这部分实际上也不大,可是正如非常多编码规范中说的,尽可能使用存储过程,当中一个理由就是直接传输SQL代码不仅不安全。并且量一大的话,也是有开销的,有些SQL代码有还几百KB,对于使用频繁的系统而言,这也是一笔开销。当然不是说禁用,详细情况详细分析吧。
另外多说一句,对于超过8KB的SQL代码,SQL Server不缓存运行计划,意味着你要每次重编译可能全然一样的SQL代码,从而造成CPU、内存的压力。
d) 须要导入、导出数据库的其它格式文件,如TXT、Excel等,某些系统须要传输一些文件到server再进行导入或者导出数据到文件然后通过某些方式传输出数据库server之外。这部分能够通过改动业务逻辑来降低。可是能降低程度可能不高,那么对于这样的情况。能够考虑把数据库server和应用程序放在一个局域网中,然后把文件终于须要传输的发生地从数据库server移到应用程序所在的server。由于应用程序easy横向扩展。所以能够通过一些技术把应用程序的负载降低。这样即使文件传输的量不能降低。最起码对数据库层server的资源争用能有一定的缓解。
总的来说,我个人建议保留这个功能的常态化关闭、排错时开启的说法。
最关键的数据实际还是警示。让使用者时刻注意对资源的合理使用。
















 262
262











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









