







第一部分 使用GDataXML写XML文件
/*
<!-- 7.客户端请求通讯录信息 -->
<iq type="get" from="jaywon@localhost/3a5054e5" to="localhost" id="123456">
<query xmlns="jabber:iq:roster"/>
</iq>
type 属性,说明了该 iq 的类型为 get,与 HTTP 类似,向服务器端请求信息
from 属性,消息来源,这里是你的 JID
to 属性,消息目标,这里是服务器域名
id 属性,标记该请求 ID,当服务器处理完毕请求 get 类型的 iq 后,响应的 result 类型 iq 的 ID 与 请求 iq 的 ID 相同
<query xmlns="jabber:iq:roster"/> 子标签,说明了客户端需要查询 roster
*/
假设我有上面这样一段文字,需要写成XML文件,那么我们可以使用GDataXML去写,那么思路又是什么呢?
思路:
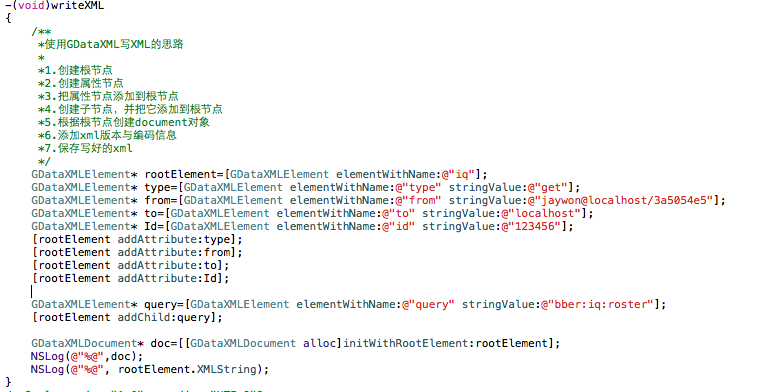
/**
*使用GDataXML写XML的思路
*
*1.创建根节点
*2.创建属性节点
*3.把属性节点添加到根节点
*4.创建子节点,并把它添加到根节点
*5.根据根节点创建document对象
*6.添加xml版本与编码信息
*7.保存写好的xml
*/
代码如下:
第二部分 解析XML文件
假设服务器返回的XML数据如下:
/*<?xml version="1.0" encoding="UTF-8"?>
<!-- 这是xml注释 -->
<catalog>
<cd country="USA">
<title>Empire Burlesque</title>
<artist>Bob Dylan</artist>
<price>10.90</price>
</cd>
<cd country="UK">
<title>Hide your heart</title>
<artist>Bonnie Tyler</artist>
<price>9.10</price>
</cd>
<cd country="USA">
<title>Greatest Hits</title>
<artist>Dolly Parton</artist>
<price>9.90</price>
</cd>
</catalog>
*/
需要解析出来,此时的思路又是什么了?
思路:
/**
*
*使用GDataXML解析XML的思路
*
*1.读取XML文件
*2.将xml文件转换成NSData
*3.将data一次性读取到document
*4.从document里面拿到根节点
*5.循环遍历子节点
*6.保存
*
*/
代码如下:
NSString* filepath=[[NSBundle mainBundle]pathForResource:@"xml" ofType:@"xml"];
NSData* data=[NSData dataWithContentsOfFile:filepath];
GDataXMLDocument* document=[[GDataXMLDocument alloc]initWithData:data error:nil];
GDataXMLElement* rootElement=[document rootElement];
NSArray* allNode=[rootElement children];
for (GDataXMLElement *element in allNode) {
GDataXMLNode* node=[element attributes][0];
NSString* namestring= [node name];
NSString* valueString=[node stringValue];
NSLog(@"namestring%@",namestring);
NSLog(@"valueString%@",valueString);
NSArray* Element= [element children];
for (GDataXMLElement* subElement in Element) {
NSString *nodeName = [subElement name];
NSString *nodeValue = [subElement stringValue];
NSLog(@"--- %@ ", nodeName);
NSLog(@"-%@",nodeValue);
}
}
结果如下:

第三部分 解析HTML语言
<html>
<head>
<meta name="audience" content="webmaster">
<meta name="robots" content="index,follow">
<meta name="generator" content="">
<link href="css_js/reset.css" rel="stylesheet" type="text/css" />
<link href="css_js/style.css" rel="stylesheet" type="text/css">
<!--[if IE 7]>
<link rel="stylesheet" type="text/css" href="css_js/ieseven.css" />
<![endif]-->
<!--[if IE 6]>
<link rel="stylesheet" type="text/css" href="css_js/ie.css" />
<![endif]-->
<link rel="SHORTCUT ICON" href="http://www.example.com/favicon.ico" type="image/x-icon">
</head>
<body>
<p><a href="abc.php">1 line<br>
<b>Bold line</b></a></p>
<hr />
<p><a href="123.php">2 line<br />
<b>Bold line</b></p>
<hr>
<p><a href="567.php">3 line<br >
<b>Bold line</p>
</body>
</html>
有HTML语言如上,解析思路和解析XML语言一样
/**
*使用GDataXML解析HTML的思路
*
*1.读取HTML文件
*2.将HTML文件转换成NSData
*3.将data一次性读取到document
*4.从document里面拿到根节点
*5.循环遍历子节点
*6.保存
*
*/
代码如下:
-(void)parseHTML
{
NSString *filePath = [[NSBundle mainBundle] pathForResource:@"html" ofType:@"html"];
NSData *htmlData = [NSData dataWithContentsOfFile:filePath];
GDataXMLDocument *document = [[GDataXMLDocument alloc] initWithHTMLData:htmlData error:NULL];
NSString *xPath = @"//a/@href";
NSArray *elementArr = [document nodesForXPath:xPath error:NULL];
for (GDataXMLElement *element in elementArr) {
NSString *nodeName = [element name];
NSString *nodeValue = [element stringValue];
NSLog(@"%@ - %@", nodeName, nodeValue);
}
}
结果如下:

第四部分 解析XML后通过xpath取文档中的节点
解析好XML文件之后,我们有时会需要从文件中取对我们有用的节点值,那么该怎么去了,答案是通过xpath.那么什么是XPath呢?
先看代码:
-(void)parseXMLForXPath
{
NSString *filePath = [[NSBundle mainBundle] pathForResource:@"xml" ofType:@"xml"];
NSData *xmlData = [NSData dataWithContentsOfFile:filePath];
GDataXMLDocument *document = [[GDataXMLDocument alloc] initWithData:xmlData error:NULL];
NSString *xPath = @"//price[1]";
NSArray *elementArr = [document nodesForXPath:xPath error:NULL];
for (GDataXMLElement *element in elementArr) {
NSString *nodeName = [element name];
NSString *nodeValue = [element stringValue];
NSLog(@"%@ - %@", nodeName, nodeValue);
}
printf("\n");
}
代码中的xpath那句表示:从匹配选择的当前节点选择文档中的节点,而不考虑它们的位置。

关于xpath语法的使用,请大家参考
http://www.w3school.com.cn/xpath/xpath_syntax.asp















 3万+
3万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









