







Redis主要支持的数据类型有5种:String ,Hash ,List ,Set ,和 Sorted Set。
字符串类型
- 能存储任何形式的字符串,包括二进制数据
- 一个字符类型键允许存储的最大容量是512M
- 内部数据结构
- 通过 int、SDS(simple dynamic string)作为结构存储
- int用来存放整型数据,sds存放字节/字符串和浮点型数据
- redis3.2分支引入了五种sdshdr类型,
- 目的是为了满足不同长度字符串可以使用不同大小的Header,从而节省内存
- 通过 int、SDS(simple dynamic string)作为结构存储
列表类型
- 列表类型内部使用双向链表实现
- 内部数据结构
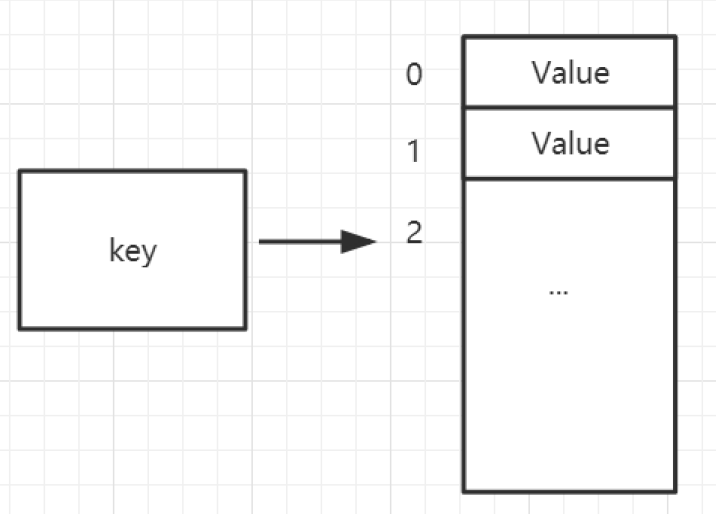
- value对象内部以linkedlist或者ziplist来实现
- 当list的元素个数和单个元素的长度比较小的时候,
- Redis会采用ziplist(压缩列表)来实现来减少内存占用。
- 否则就会采用linkedlist(双向链表)结构。
- 当list的元素个数和单个元素的长度比较小的时候,
- redis3.2之后,采用的一种叫quicklist的数据结构
- 二者结合
- quicklist仍然是一个双向链表,只是列表的每个节点都是一个ziplist
hash类型
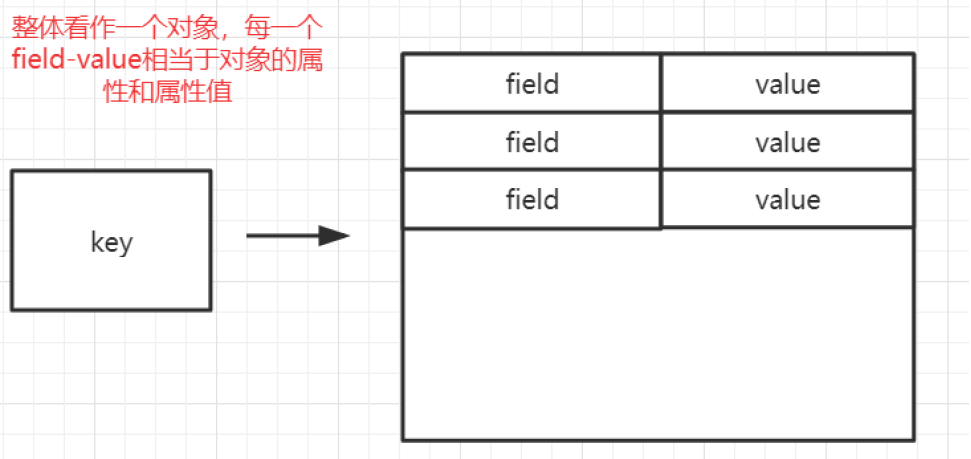
- 数据结构
- map提供两种结构来存储,
- 一种是hashtable、
- 另一种是前面讲的ziplist,
- 数据量小的时候用ziplist.
- 在redis中,哈希表分为三层
- dictEntry
- 管理一个key-value,
- 同时保留同一个桶(bucket)中相邻元素的指针,
- 用来维护哈希桶(bucket)的内部链;
-
typedef struct dictEntry { void *key; union { //因为value有多种类型,所以value用了union来存储 void *val; uint64_t u64; int64_t s64; double d; } v; struct dictEntry *next; //下一个节点的地址,用来处理碰撞,所有分配到同一索引的元素通过next指针 //链接起来形成链表key和v都可以保存多种类型的数据 } dictEntry;
- dictht
- 实现一个hash表会使用一个buckets存放dictEntry的地址
- 通过hash(key)%len得到的值就是buckets的索引
-
typedef struct dictht { dictEntry **table;//buckets的地址 unsigned long size;//buckets的大小,总保持为 2^n unsigned long sizemask;//掩码,用来计算hash值对应的buckets索引 unsigned long used;//当前dictht有多少个dictEntry节点 } dictht;
- dict
- dictht实际上就是hash表的核心
- 只有一个dictht还不够,比如rehash、遍历hash等操作,
- 所以redis定义了一个叫dict的结构以支持字典的各种操作,
- 当dictht需要扩容/缩容时,用来管理dictht的迁移
- dictEntry
- map提供两种结构来存储,
集合类型
- 不能有重复数据,
- 同时集合类型中的数据是无序的
- 集合类型和列表类型的最大的区别是
- 有序性
- 列表有序
- 唯一性
- 集合唯一
- 有序性
- 使用的值为空的散列表(hash table),
- 所以这些操作的时间复杂度都是O(1).
- 数据结构
- 底层数据结构以intset或者hashtable来存储
有序集合
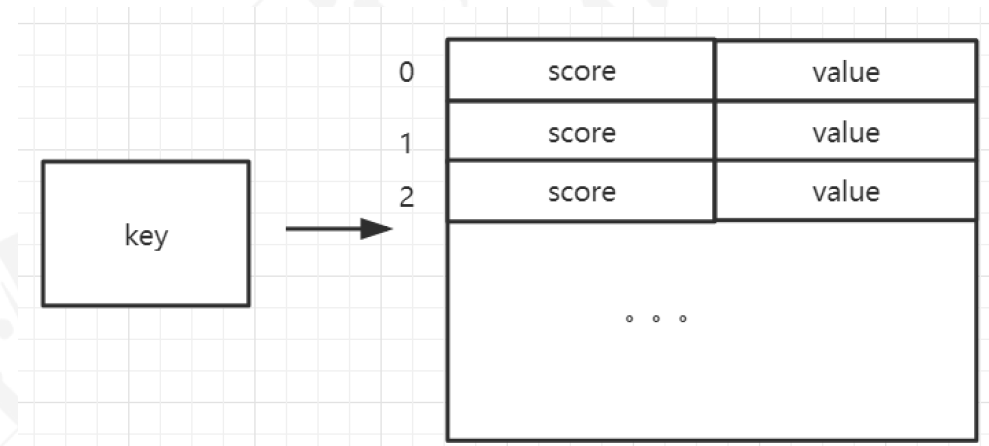
- 有序集合类型为集合中的每个元素都关联了一个分数
- 数据结构
- 内部是以ziplist或者skiplist+hashtable来实现
- skiplist,也就是跳跃表
-
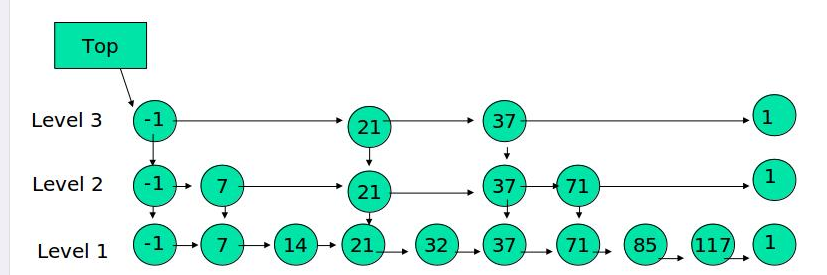
跳跃表
- 跳跃表是一种随机化的数据结构,
- 在查找、插入和删除这些字典操作上,
- 其效率可比拟于平衡二叉树(如红黑树)
- 在查找、插入和删除这些字典操作上,
- 跳跃表是一种随机化的数据结构,















 577
577

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









