







ID的特性
id是唯一标识一条数据的,它一般没有什么业务含义,是系统内部的标识,那么它往往有这样一些特性。
- 全局唯一性。这个是强制的,往往id会被设置成主键,肯定不允许重复。
- 顺序性。这个一般不强制,但是某些业务可能会依赖id进行排序,表示数据创建的先后顺序。
- 简单高效性。非强制特性。id往往会被作为主键,如果过于复杂,则对查询效率不好。
- 连续性。这个是指产生的id是连续的。
全局id生成服务解决方案
总结一下,大概有下面这几种。
数据库自增实现
这种放方案是这样的,还是利用MySQL数据库自身的autoincrement特性实现的,只不过每个分库(或者分表)的起始值不同,增长步长等于分库数量,这样各分库的ID就不会出现重复的。这种实现方案的特点是这样。
优点:
- 实现较简单。
- 可保证单库的严格顺序性。
- 简单高效。
- 可靠性高。
缺点:
- 并发性受数据库限制。
- 分库变化之后维护复杂。
- 灵活性差。
客户端应用实现
客户端实现,就是在应用程序中通过一种算法来生成一个全局唯一的ID,这个算法的选择非常关键。比如 snowflake 算法。
优点:
- 实现较简单。
- 性能高。
- 可靠性最高。
缺点:
- 生产的ID往往较为复杂。
- 不合适的算法可能产生重复值。
- 生成的id的有序性差。
- id生成的可控性差。
- 与现有数据生成的id不兼容,改动较大。
独立服务实现
通过一个微服务来实现全局id生成服务,这个微服务的实现要做到不能生成重复值,尽肯能保持有序,生成的值尽可能简单。这种方案的特点是。
优点:
- 可确保全局唯一。
- 生成的值简单高效。
- 灵活性大。
- 分库变化影响不大。
缺点:
- 连续性不严谨。
- 开发运维复杂。
- 增加网络调用性能损耗。
- 可用性严重依赖微服务。
总结
我们最终选择了“独立服务实现”方案来生成全局唯一id,下面详细介绍这种方案的设计和实现。
全局id生成微服务设计和实现
设计图
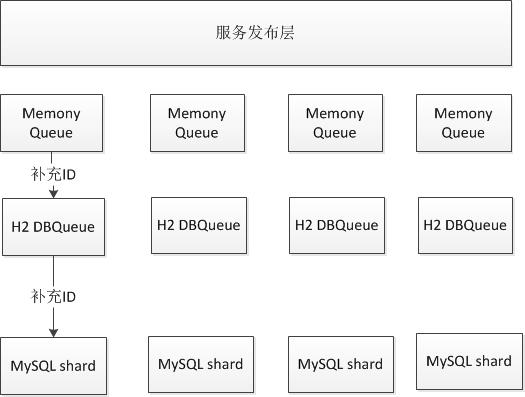
该方案是这样的。
该服务由三级ID队列组成,分别是MySQL数据库,H2嵌入式数据库,内存队列。下面分别介绍着三级的详细设计。
MySQL数据库ID队列设计实现
该即是由一张sequence表组成,这个表就三个字段,分别是:
seqName:序列名,通过这个来获取ID值。
currentValue:当前值,这个是一直增长的。这个值的安全增长才能保障不生成重复的值。
increment:增长步长。
该表的表引擎必须是innodb,以支持行锁。
该表实际上模拟实现了Oracle数据的sequence特性。
这个表本身也可以支持分库分表,以提升它的扩展性,不过我觉得多数场景是不需要的,但是如果是大规模集中部署则需要支持该特性。
支持单个或者批量获取ID,获得到对应的id之后就将currentValue值往后增加。
H2内存数据库id队列
为了做到完全不依赖于MySQL数据库,我们引入了h2内存数据库,它的表结构非常简单,就是每个sequence是一张表,表中就一个字段ID,并且它是主键。
当服务启动的时候若数据库中没有足够的ID,则会从mysql数据中补充大量的id插入到表中。这样h2数据库就能够支持长时间的提供服务。并且有后台线程不断的向h2的id队列中补充id,避免没有读取的时候才去补充id,降低性能。
内存ID队列
内存id队列才是正式提供id获取服务的,因为它直接从内存队列中返回队首的id值,则可以保障极高的性能。它也会在需要补充的时候从H2内存数据库队列中补充一定数量的ID,也有后台线程定时补充。它的实现是基于BlockingDeque的。
实现
通过多级队列我们发现有很多逻辑是通用的,我们是可以抽象出一个实现自动补全队列和范围限定的全能队列的,我们命名为AutoSuppliedAndBoundedQueue。它将一些实现了一些公共特性。包括这些内容。
- 限制队列数。
- 有上级队列。
- 可以自动长上级队列补充数据。
这样就有非常强的可扩展性,我们可以用redis实现,也可以再增加几级队列,增加的级数越多,总体可靠性增加,但是复杂度也就越高。需要根据实际情况来设计。
特点
该id生成服务具有这样的特点。
- 极高的性能。在获取id的时候完全是无锁设计,直接从准备好的数据中读取。
- 极高的可用性。MySQL数据不可用,完全不影响可用性。
- 极高的可扩展性。MySQL数据库支持分库分表扩展,服务实例可以任意增加。















 439
439

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









