







第一:常见问题解决集锦
1.shell脚本不执行
问题:某天研发同事找我说帮他看看他写的shell脚本,死活不执行,报错。我看了下,脚本很简单,也没有常规性的错误,报“:badinterpreter:Nosuchfileordirectory”错。
看这错,我就问他是不是在windows下编写的脚本,然后在上传到linux服务器的……果然。
原因:在DOS/windows里,文本文件的换行符为rn,而在*nix系统里则为n,所以DOS/Windows里编辑过的文本文件到了*nix里,每一行都多了个^M。
解决:
1)重新在linux下编写脚本;
2)vi:%s/r//g:%s/^M//g(^M输入用Ctrl+v,Ctrl+m)
附:sh-x脚本文件名,可以单步执行并回显结果,有助于排查复杂脚本问题。
2.crontab输出结果控制
问题:
/var/spool/clientmqueue目录占用空间超过100G
原因:
cron中执行的程序有输出内容,输出内容会以邮件形式发给cron的用户,而sendmail没有启动所以就产生了/var/spool/clientmqueue目录下的那些文件,日积月累可能撑破磁盘。
解决:
1)直接手动删除:ls | xargs rm -f;
2)彻底解决:在cron的自动执行语句后加上>/dev/null2>&1
3.telnet很慢/ssh很慢
问题:
某天研发 同事说10.50访问10.52 memcached服务异常,让我们检查下看网络/服务/系统是否有异常。检查发现系统正常,服务正常,10.50 ping 10.52也正常,但10.50 telnet10.52很慢。同时发现该机器的namesever是不起作用的。
原因:
because your PC doesn’t doareverse DNS look up on your IP then…when you telnet/ftp into your linux box , it’ll doadns look up on you。
解决:
1)修改/etc/hosts使hostname和ip对应;
2)在/etc/resolv.conf注释掉nameserver或者找一个“活的”nameserver。
4.Read-onlyfilesystem
问题:
同事在mysql里建表建不成功,提示如下:
mysql>createt able wos on test(colddname1char(1));
ERROR1005(HY000):Can’t creat etable ‘wosontest’ (errno:30)
经检查mysql用户权限以及相关目录权限没问题;用perror30提示信息为:OS error code 30 : Read-only filesystem
可能原因:
1)文件系统损坏;
2)磁盘又坏道;
3)fstab文件配置错误,如分区格式错误错误(将ntfs写成了fat)、配置指令拼写错误等。
解决:
1)由于是测试机,重启机器后恢复;
2)网上说用mount可解决。
5.文件删了磁盘空间没释放
问题:
某天发现某台机器df -h已用磁盘空间为90G,而du -sh /*显示所有使用空间加起来才30G,囧。
原因:
可能某人直接用rm删除某个正在写的文件,导致文件删了但磁盘空间没释放的问题
解决:
1)最简单重启系统或者重启相关服务。
2)干掉进程
/usr/sbin/ lsof | grep deleted
ora25575data33uREG65,654294983680/oradata/DATAPRE/UNDOTBS009.dbf(deleted)
从lsof的输出中,我们可以发现pid为25575的进程持有着以文件描述号(fd)为33打开的文件/oradata/DATAPRE/UNDOTBS009.dbf。在我们找到了这个文件之后可以通过结束进程的方式来释放被占用的空间:echo>/proc/25575/fd/33
3)删除正在写的文件一般用cat/dev/null>file
6.find文件提升性能
问题:
在tmp目录下有大量包含picture_*的临时文件,每天晚上2:30对一天前的文件进行清理。之前在crontab下跑如下脚本,但是发现脚本效率很低,每次执行时负载猛涨,影响到其他服务。
#!/bin/sh
find /tmp -name “picture_*” -mtime +1 -exec rm-f {};
原因:
目录下有大量文件,用find很耗资源。
解决:
#!/bin/sh
cd /tmp
time=`date -d “2 day ago”“ + %b%d”`
ls -l | grep “picture” | grep “$time” | awk ‘{print$NF}’ | xargs rm -rf
7.获取不了网关mac地址
问题:
从2.14到3.65(映射地址2.141)网络不通,但是从3端的其他机器到3.65网络OK。
原因:
#arp
Address HW type HW address Flags Mask Iface
192.168.3.254 etherincompletCMbond0
表面现象是机器自动获取不了网关MAC地址,网络工程师说是网络设备的问题,具体不清。
解决:
arp绑定,arp -ibond0 -s 192.168.3.25400:00:5e:00:01:64
8.http服务无法启动一例
问题:某天研发同事说网站前端环境http无法启动,我上去看了下。报如下错:
/etc/init.d/httpd start
Starting httpd : [SatJan2917:49:002011] [warn] module antibot_moduleis already loaded,skipping
Useproxy forwardas remoteip:true.
Antibot exclude pattern:.*.[(js|css|jpg|gif|png)]
Antibotseedcheckpattern:login
(98)Address alreadyinuse : make_sock : could not bindto address [::] : 7080
(98)Address alreadyinuse : make_sock : could not bindto address 0.0.0.0 : 7080
nolistening socket savailable,shutting down
Unableto openlog [FAILED]
原因:
1)端口被占用:表面看是7080端口被占用,于是netstat-npl|grep7080看了下发现7080没有占用;
2)在配置文件中重复写了端口,如果在以下两个文件同时写了Listen7080
/etc/httpd/conf/http.conf
/etc/httpd/conf.d/t.10086.cn.conf
解决:
注释掉/etc/httpd/conf.d/t.10086.cn.conf的Listen7080,重启,OK。
9.too many openfile
问题:
报too many openfile错误
解决:
终极解决方案
echo“”>>/etc/security/limits.conf
echo“*softnproc65535″>>/etc/security/limits.conf
echo“*hardnproc65535″>>/etc/security/limits.conf
echo“*softnofile65535″>>/etc/security/limits.conf
echo“*hardnofile65535″>>/etc/security/limits.conf
echo“”>>/root/.bash_profile
echo“ulimit-n65535″>>/root/.bash_profile
echo“ulimit-u65535″>>/root/.bash_profile
最后重启机器或者执行ulimit-u655345&&ulimit-n65535
10.ibdata1和mysql-bin致磁盘空间问题
问题:
2.51磁盘空间报警,经查发现ibdata1和mysql-bin日志占用空间太多(其中ibdata1超过120G,mysql-bin超过80G)
原因:
ibdata1是存储格式,在INNODB类型数据状态下,ibdata1用来存储文件的数据和索引,而库名的文件夹里的那些表文件只是结构而已。
innodb存储引擎有两种表空间的管理方式,分别是:
1)共享表空间(可拆分为多个小的表空间文件),这个是我们目前多数数据库使用的方法;
2)独立表空间,每一个表有一个独立的表空间(磁盘文件)
对于两种管理方式,各有优劣,具体如下:
①共享表空间:
优点:可以将表空间分成多个文件存放到不同的磁盘上(表空间文件大小不受表大小的限制,一个表可以分布在不同步的文件上)
缺点:所有数据和索引存放在一个文件中,则随着数据的增加,将会有一个很大的文件,虽然可以把一个大文件分成多个小文件,但是多个表及索引在表空间中混合存储,这样如果对于一个表做了大量删除操作后表空间中将有大量空隙。对于共享表空间管理的方式下,一旦表空间被分配,就不能再回缩了。当出现临时建索引或是创建一个临时表的操作表空间扩大后,就是删除相关的表也没办法回缩那部分空间了。
②独立表空间:在配置文件(my.cnf)中设置:innodb_file_per_table
特点:每个表都有自已独立的表空间;每个表的数据和索引都会存在自已的表空间中。
优点:表空间对应的磁盘空间可以被收回(Droptable操作自动回收表空间,如果对于删除大量数据后的表可以通过:altertabletbl_nameengine=innodb;回缩不用的空间。
缺点:如果单表增加过大,如超过100G,性能也会受到影响。在这种情况下,如果使用共享表空间可以把文件分开,但有同样有一个问题,如果访问的范围过大同样会访问多个文件,一样会比较慢。如果使用独立表空间,可以考虑使用分区表的方法,在一定程度上缓解问题。此外,当启用独立表空间模式时,需要合理调整innodb_open_files参数的设置。
解决:
1)ibdata1数据太大:只能通过dump,导出建库的sql语句,再重建的方法。
2)mysql-binLog太大:
①手动删除:
删除某个日志:mysql>PURGEMASTERLOGSTO‘mysql-bin.010′;
删除某天前的日志:mysql>PURGEMASTERLOGSBEFORE’2010-12-2213:00:00′;
②在/etc/my.cnf里设置只保存N天的bin-log日志
expire_logs_days=30//BinaryLog自动删除的天数
二、故障排查汇总表
| 序号 | 故障点 | 分析与解决 |
| 1 | Linux系统安装初始状态时,找不到硬盘,并无法进入下一步安装 | 进入COMS设置,找到硬盘设置的相关选项,并设置为兼容模式 |
| 2 | Linux系统安装时,在硬盘分区完成后,无法继续安装 | 硬盘分区不符合安装要求,你可能忘记创建根分区或swap交换分区了,这一点与Windows系统的安装有区别 |
| 3 | Linux系统安装时,制定安装中,软件包的选择感觉困惑,安装完成后发现不符合我们的要求,有些组件没有安装,而不需要的组件却装上了 | 对Linux系统的了解还太少,反复安装多次后,自然掌握自如 |
| 4 | 代理服务器的配置过程中,发现有些过滤规划未起作用 | (1)先检查对应的功能模块是否加载成功(2)默认策略是否设置恰当(3)iptables命令语法是否有错(4)过滤规划顺序可能不当,需调整 |
| 5 | 代理服务器和防火墙的配置完成后,启动服务,可以访问Internet,但不能访问DMZ区的服务 | (1)关闭iptables服务,看是否可以访问,如果不能,检查连通性,若能访问,说明iptables规则有问题,集中检查过滤规则的配置与顺序 |
| 6 | 再次配置好iptables过滤规则后,重启iptables服务后,发现原有的规则全部丢失 | (1)修改/etc/sysconfig/iptables-config配置文件,将IPTABLES_SAVE_ON_RESTART=”no”改为yes(2)用iptables-save > /etc/sysconfig/iptables命令保存 |
| 7 | 在交换机上划分VLAN后,不能访问外网 | VLAN的网关未设置或设置不正确 |
| 8 | 在配置DNS服务中,named服务无法启动 | 造成问题可能性:(1)/etc/named目录下缺少必要文件(2)/var/named目录下缺少必要文件(3)named账户权限问题。解决方法:缺少的文件必须复制到位,启动文件必须将权限设置为named账户和组账户 |
| 9 | 在配置DNS服务中,无法正确解析域名或IP地址 | (1)检查并修改/var/named下的正向解析区文件和反向解析区文件中的语法与记录设置(2)检查/etc/named.conf配置中的zone区域声明编写是否有误(3)检查是否安装了bind-chroot软件包,如安装了,区域数据库文件应在/var/named/chroot/var/named目录中(4)检查/etc/resolv.conf配置文件是否设定了正确的nameserver |
| 10 | dhcpd服务启动时,提示“No subnet declaration for eth0(10.10.10.2)” | 说明eth0的IP地址设置不对,不在dhcp服务的作用域范围内,必须将eth0的IP设置为作用域范围内的IP地址 |
| 11 | 在配置DHCP服务时,配置了多个作用域,结果只有一个作用域的地址可以分配,其他不能分配成功 | 说明主机的网络接口卡只有一个,如有3个作用域,需配置3个网卡接口eth0、eth1和eth2,分别对应3个作用域。这是使用超级作用域的一种配置方法 |
| 12 | MySQL数据库的安装不能成功,总是提示软件的依赖关系,造成所要安装的软件包不能顺利安装 | 说明所要安装的软件包需要其他组件或共享库的支持,MySQL的rpm包安装方式本身就繁琐一些,要求安装的软件包比较多,包之间的依赖关系非常明显,根据提示找到需要的组件包并安装,安装时要注意软件包顺序 |
| 13 | 测试Web服务,访问主站点时,无网页出现,但已经连接上服务器 | 在httpd.conf主配置文件中的“DocumentRoot”选项的设置不当,如/var/www/html/,最后的“/”不能加 |
| 14 | 远程客户端无法访问samba共享目录,共享目录在本地测试成功 | 关闭iptables服务 |
| 15 | Samba的smb服务已经启动成功,访问samba某个共享目录时,提示错误信息“NT_STATUS_BAD_NETWORK_NAME” | 说明共享目录没有创建或不存在 |
| 16 | Samba的smb服务已经启动成功,提示错误信息“NT_STATUS_ACCESS_DENIED” | 提示访问被拒绝,可能是登录的用户名或密码有误,或是iptables启动了,关闭防火墙 |
| 17 | Samba的smb服务已经启动成功,提示错误信息“NT_STATUS_LOGON_FAILURE” | 不允许当前用户访问当前共享目录,说明此共享目录设置只允许特定用户访问 |
| 18 | FTP服务配置了本地用户上传,但在上传数据到对应目录时,提示被拒绝 | 可能该用户账户对上传目录没有写权限 |
| 19 | 配置允许本地账户登录FTP后,root账户无法登录,并提示“500 OOPS:cannot change directory:/root”的错误信息,而其他本地账户可以登录FTP | 检查是否启用了SELinux安全系统,并禁止SELinux,可以编辑/etc/selinux/config文件,将配置项SELINUX=enforcing改为disabled |
| 20 | 使用邮件客户端可以发送邮件,但不能接收邮件 | 检查pop3服务是否启动 |
| 21 | mount命令挂载NFS服务的共享目录,很久也没有响应,NFS服务是正常的 | portmap服务没有启动,必须启动该服务 |
| 22 | 本地测试mount挂载NFS共享成功,但在其他客户主机mount连接时不成功 | 关闭iptables服务,再测试 |
三、Linux 4.1内核热补丁成功实践
11、问题现象
现象一:CPU监控非0即100%
该问题现象表现在Redis进程CPU监控的峰值时而100% 时而为0,有的甚至是几十分钟都为0,突发1秒100%后又变为0,如下图。
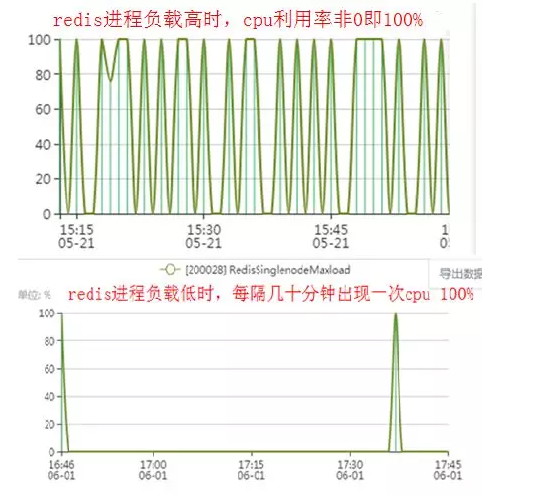
而从大量机器的统计规律看,这个现象在2.6.32 内核不存在,在4.1内核存在几例。2.6.32是我们较早期采用的版本,为平台的稳定发展做了有力支撑,4.1 可以满足很多新技术需求,如新款CPU、新板卡、RDMA、NVMe和binlog2.0等。后台无缝维护着两个版本,并为了能力提升和优化而逐步向4.1及更高版本过渡。
现象二:top显示非0即300%
登录到机器上执行top -b -d 1 –p <pid> | grep<pid> , 可以看到进程的CPU利用率每隔几分钟到几十分钟出现一次300%,这意味着该进程3个线程占用的3个CPU都跑满了,跟监控程序呈现同样的异常。
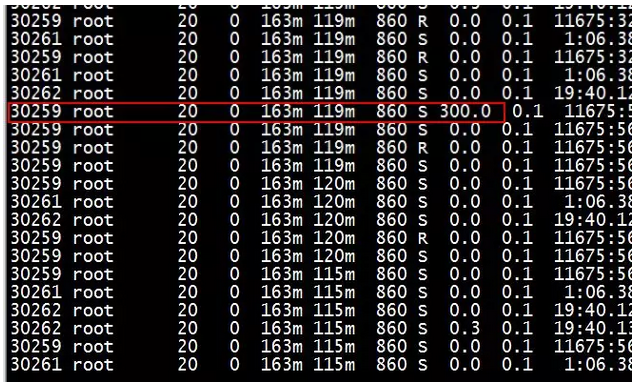
问题分析
上述异常程序使用的是同样的数据源:/proc/pid/stat中进程运行占用的用户态时间utime和内核态时间stime。我们抓取utime和stime更新情况后,发现utime或者stime每隔几分钟或者几十分钟才更新,更新的步进值达到几百到1000+,而正常进程看到的是每几秒更新,步进值是几十。
定位到异常点后,还要找出原因。排除了监控逻辑、IO负载、调用瓶颈等可能后,确认是4.1内核的CPU时间统计有 bug。
cputime统计逻辑
检查/proc/pid/stat中utime和stime被更新的代码执行路径,在cputime_adjust()发现了一处可疑的地方:

当utime+stime>=rtime的时候就直接跳出了,也就是不更新utime和stime了!这里的rtime是runtime,代表进程运行占用的所有CPU时长,正常应该等于或近似进程用户态时间+内核态时间。 但内核配置了CONFIG_VIRT_CPU_ACCOUNTING_GEN选项,这会让utime和stime分别单调增长。而runtime是调度器里统计到的进程真正运行总时长。
内核每次更新/proc/pid/stat的utime和stime的时候,都会跟rtime对比。如果utime+stime很长一段时间都大于rtime,那代码直接get out了, /proc/pid/stat就不更新了。只有当rtime持续更新追上utime+stime后,才更新utime和stime。
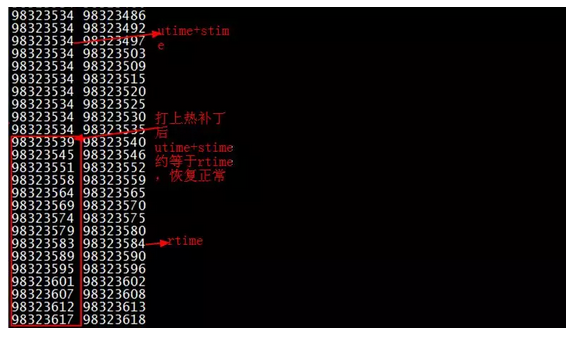
解决办法 :
冷补丁和热补丁
第一回合:冷补丁
出现问题的代码位置已经找到,那就先去内核社区看看有没有成熟补丁可用,看一下kernel/sched/cputime.c的 changelog,看到一个patch:确保stime+utime=rtime。再看描述:像top这样的工具,会出现超过100%的利用率,之后又一段时间为0,这不就是我们遇到的问题吗?真是踏破铁鞋无觅处,得来全不费工夫!(patch链接:https://lore.kernel.org/patchwork/patch/609410/)
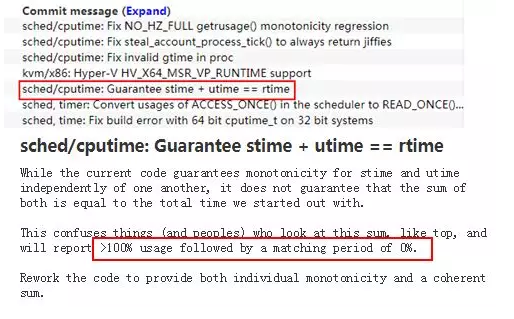
该补丁在4.3内核及以后版本才提交, 却并未提交到4.1稳定版分支,于是移植到4.1内核。打上该补丁后进行压测,再没出现cputime时而100%时而0%的现象,而是0-100%之间平滑波动的值。
至此,你可能觉得问题已经解决了。但是,问题才解决了一半。而往往“但是”后边才是重点。
第二回合:热补丁
给内核代码打上该冷补丁只能解决新增服务器的问题,但公司还有数万存量服务器是无法升级内核后重启的。
如果没有其它好选择,那存量更新将被迫采用如下的妥协方案:监控程序修改统计方式进行规避,不再使用utime和stime,而是通过runtime来统计进程的执行时间。
虽然该方案快速可行,但也有很大的缺点:
1. 很多业务部门都要修改统计程序,研发成本较高;
2. /proc/pid/stat的utime和stime是标准统计方式,一些第三方组件并不容易修改;
3. 并没有根本解决utime和stime不准的问题,用户、研发、运维使用ps、top命令时还会产生困惑,产生额外的沟通协调成本。
幸好,我们还可以依靠UCloud已多次成功应用的技术:热补丁技术。
所谓热补丁技术,是指在有缺陷的服务器内核或进程正在运行时,对已经加载到内存的程序二进制打上补丁,使得程序实时在线状态下执行新的正确逻辑。可以简单理解为像关二爷那样不打麻药在清醒状态下刮骨疗伤。当然,对内核刮骨疗伤内核是不会痛的,但刮不好内核就会直接死给你看,没有丝毫犹豫,非常干脆利索又耿直。
热补丁修复
而本次热补丁修复存在两个难点:
难点一: 热补丁制作
这次热补丁在结构体新增了spinlock成员变量,那就涉及新成员的内存分配和释放,在结构体实例被复制和释放时,都要额外的对新成员做处理,稍有遗漏可能会造成内存泄漏进而导致宕机,这就加大了风险。
再一个就是,结构体实例是在进程启动时初始化的,对于已经存在的实例如何塞进新的spinlock成员?所谓兵来将挡水来土掩,我们想到可以在原生补丁使用spinlock成员的代码路径上拦截,如果发现实例不含该成员,则进行分配、初始化、加锁、释放锁。
要解决问题,既要攀登困难的山峰,又得控制潜在的风险。团队编写了脚本进行几百万次的加载、卸载热补丁测试,并无内存泄漏,单机稳定运行,再下一城。
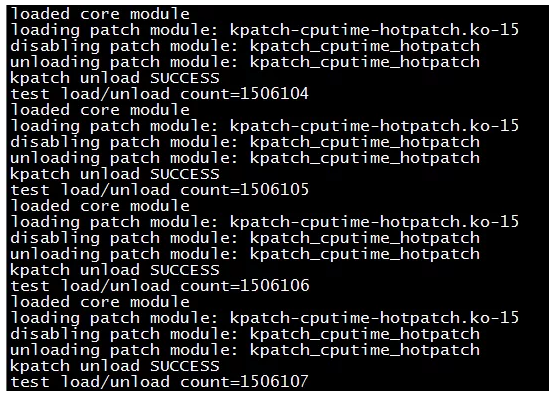
难点二:难以复现
另一个难题是该问题难以复现,只有在现网生产环境才有几个case可验证热补丁,而又不可以拿用户的环境去冒险。针对这种情况我们已经有标准化处理流程去应对,那就是设计完善的灰度策略,这也是UCloud内部一直在强调的核心理念和能力。经过分析,这个问题可以拆解为验证热补丁稳定性和验证热补丁正确性。于是我们采取了如下灰度策略:
1. 稳定性验证:先拿几台机器测试正常,再拿公司内部500台次级重要的机器打热补丁,灰度运行几天正常,从而验证了稳定性,风险尽在掌控之中。
2. 正确性验证:找到一台出现问题的机器,同时打印utime+stime以及rtime,根据代码的逻辑,当rtime小于utime+stime时会执行老逻辑,当rtime大于utime+stime时会执行新的热补丁逻辑。如下图所示,进入热补丁的新逻辑后,utime+stime打印正常且与rtime保持了同步更新,从而验证了热补丁的正确性。
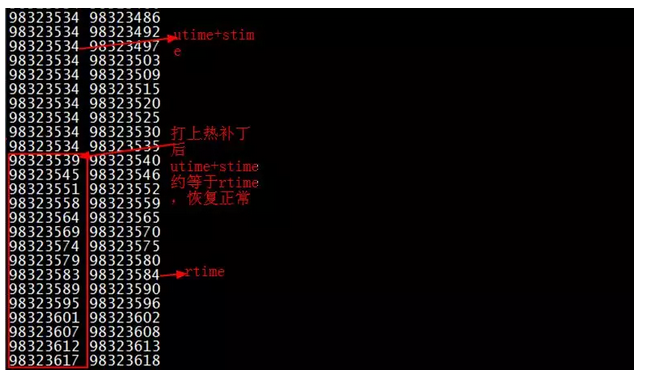
3. 全网变更:最后再分批在现网环境机器上打热补丁,执行全网变更,问题得到根本解决。
四、Linux 管理员10 个常见问题
1、卸载无响应的 DVD 驱动器
按下服务器(运行基于 Redmond 的操作系统)DVD 驱动器上的 Eject 按钮时,它会立即弹出。在大多数企业 Linux 服务器中,如果在那个目录中运行某个进程,弹出就不会发生。
下面介绍如何找到保持 DVD 驱动器的进程,并轻松弹出 DVD 驱动器:首先进行模拟。在 DVD 驱动器中放入磁盘,打开一个终端,装载 DVD 驱动器:
# mount /media/cdrom
# cd /media/cdrom
# while [ 1 ]; do echo "All your drives are belong to us!"; sleep 30; done
现在打开第二个终端并试着弹出 DVD 驱动器:
# eject
将得到以下消息:
umount: /media/cdrom: device is busy
在释放该设备之前,让我们找出谁在使用它
# fuser /media/cdrom
进程正在运行,无法弹出磁盘其实是我们的错误。现在,如果您是根用户,可以随意终止进程:
# fuser -k /media/cdrom
现在终于可以卸载驱动器了:
# eject
fuser 很正常。
2、恢复出现问题的屏幕
以下操作:
# cat /bin/cat
注意!终端就想垃圾一样。输入的所有内容非常零乱。那么该怎么做呢?
输入 reset。但是,输入 reset 与 输入 reboot 或 shutdown 太接近了。
在进行此操作时,机器不会重启。继续操作:
# reset
现在屏幕恢复正常了。这比关闭窗口后再次登陆好多了,特别是必须经过 5 台机器和 SSH 才能到达这台机器时。
3、屏幕协作
来自产品工程的高级维护用户 David 打电话说:“为什么我不能在您部署的这些新机器上编译 supercode.c”。
运行的是Posh机器
(这个虚够的公司将它的 5 台生产服务器以纪念 Spice Girls 的方式命名)。这下您可以大显身手了,另一台机器由 David 操作:
# su - david
转到 posh:
# ssh posh
到达之后,运行以下代码:
# screen -S foo
然后呼叫 David:“David,在终端运行命令 # screen -x foo”。
问题原因 :David 的编译脚本对一个不在此新服务器上的旧目录进行了硬编码。将它装载后再次编译即可解决问题
注意 :双方需要以同一用户登录。screen 命令还可以:实现多个窗口和拆分屏幕。
方法:Ctrl-A D
(即按住 Ctrl 键并点击 A 键。然后按 D 键)。然后通过再次运行 screen -x foo 命令可以重新拼接起来。
4、找回根密码
如果忘记根密码,就必须重新安装整台机器。
首先重启系统。重启时会跳出如图 1 所示的 GRUB 屏幕。移动箭头键,这样可以保留在此屏幕上,而不是进入正常启动。
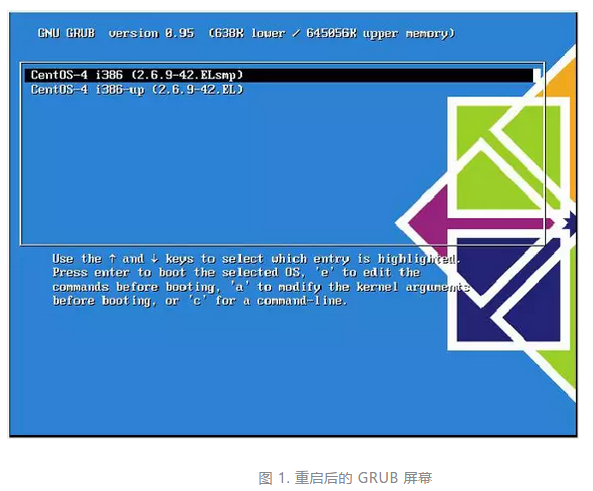
然后,使用箭头键选择要启动的内核,并输入 E 编辑内核行。然后便可看到如图 2 所示的屏幕:

图 2:准备编辑内核行
再次使用箭头键突出显示以 kernel 开始的行,按 E 编辑内核参数。到达如图 3 所示的屏幕时,在图 3 中所示的参数后追加数字 1 即可:
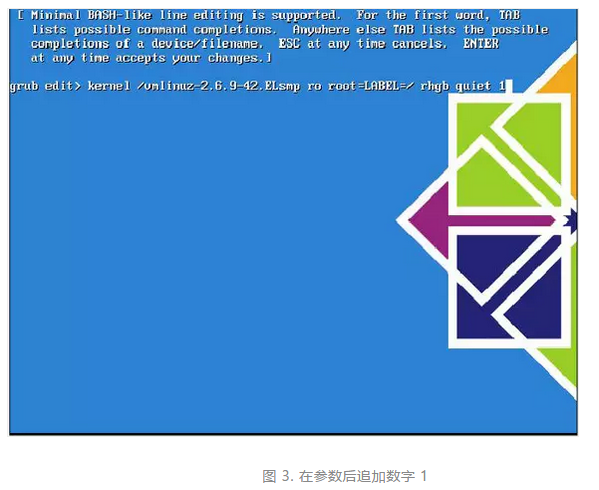
然后按 Enter 和 B,内核会启动到单用户模式。然后运行 passwd 命令,更改用户根密码:
sh-3.00# passwd
New UNIX password:
Retype new UNIX password:
passwd: all authentication tokens updated successfully
现在可以重启了,机器将使用新密码启动。
5、SSH 后门
我所在的站点需要某人的远程支持,而他却被公司防火强阻挡在外。很少有人意识到,如果能通过防火墙到达外部,那么也能轻松实现让外部的信息进来。 从本意讲,这称为 “在防火墙上砸一个洞”。我称之为 SSH 后门。为了使用它,必须有一台作为中介的连接到 Internet 的机器。 在本例中,将这样台机器称为 blackbox.example.com。公司防火墙后面的机器称为 ginger。此技术支持的机器称为 tech。图 4 解释了设置过程。
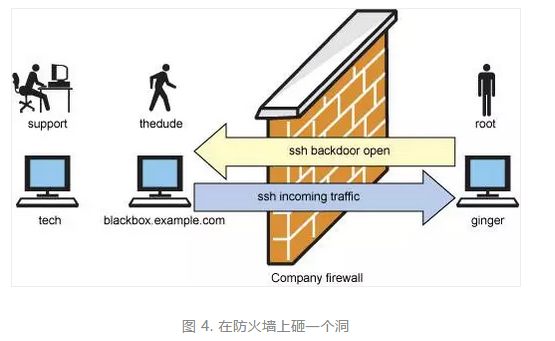
操作步骤:
检查什么是允许做的,但要确保您问对了人。大多数人都担心您打开了防火墙,但他们不明白这是完全加密的。而且,必须破解外部机器才能进入公司内部。不过,您可能属于 “敢作敢为” 型的人物。自己进行判断应该选择的方式,但不如意时不抱怨别人。
使用 -R 标记通过 SSH 从 ginger 连接到 blackbox.example.com。假设您是 ginger 上的根用户,tech 需要根用户 ID 来帮助使用系统。使用 -R 标记将 blackbox 上端口 2222 的说明转发到 ginger 的端口 22 上。这就设置了 SSH 通道。注意,只有 SSH 通信可以进入 ginger:您不会将 ginger 放在无保护的 Internet 上。可以使用以下语法实现此操作:
~# ssh -R 2222:localhost:22 thedude@blackbox.example.com
进入 blackbox 后,只需一直保持登录状态。我总是输入以下命令:
thedude@blackbox:~$ while [ 1 ]; do date; sleep 300; done
使机器保持忙碌状态。然后最小化窗口。
现在指示 tech 上的朋友使用 SSH 连接到 blackbox,而不需要使用任何特殊的 SSH 标记。但必须把密码给他们:
root@tech:~# ssh thedude@blackbox.example.com
tech 位于 blackbox 上后,可以使用以下命令从 SSH 连接到 ginger:
thedude@blackbox:~$: ssh -p 2222 root@localhost
Tech 将提示输入密码。应该输入 ginger 的根密码。现在您和来自 tech 的支持可以一起工作并解决问题。甚至需要一起使用屏幕!
6、通过 SSH 通道进行远程 VNC 会话
通常,当远程服务器上的某类图形程序只能在此服务器上使用时,才需要 VNC。
假设在 技巧 5 中,ginger 是一台存储服务器。许多设备都使用 GUI 程序来管理存储控制器。这些 GUI 管理工具通常需要通过一个网络直接连接到存储服务器,而这个网络有时保存在专用的子网络中。因此,只能通过 ginger 访问这个 GUI。
可以尝试使用 -X 选项通过 SSH 连接到 ginger 并启动它,但这对带宽要求很高,您需要忍受等待的痛苦。VNC 是一个网络友好的工具,几乎适用于所有操作系统。
假设设置与技巧 5 中的一样,但希望 tech 能访问 VNC 而不是 SSH。对于这种情况,需要进行一些类似的操作,不过转发的是 VNC 端口。执行以下操作步骤:
在 ginger 上启动一个 VNC 服务器会话。运行以下命令:
root@ginger:~# vncserver -geometry 1024x768 -depth 24 :99
这些选项指示启动服务器,分辨率为 1024×768,像素深度为每像素 24 位。如果使用较慢的连接设置,8 也许是更好的选项。使用 :99 指定可访问 VNC 服务器的端口。VNC 协议在 5900 处启动,因此 :99 表示服务器可从端口 5999 访问。
启动该会话时,要求您指定密码。用户 ID 与启动 VNC 服务器时的用户相同(本例中就是根用户)。
从 ginger 连接到 blackbox.example.com 的 SSH 将 blackbox 上的端口 5999 转发到 ginger。这通过运行以下命令在 ginger 中完成:
root@ginger:~# ssh -R 5999:localhost:5999 thedude@blackbox.example.com
运行此命令后,需要将此 SSH 会话保持为打开状态,以便保留转发到 ginger 的端口。此时,如果在 blackbox 上,那么运行以下命令即可访问 ginger 上的 VNC 会话:
thedude@blackbox:~$ vncviewer localhost:99
这将通过 SSH 将端口转发给 ginger,但我们希望通过 tech 让 VNC 访问 ginger。为此,需要另一个通道。在 tech 中,打开一个通道,通过 SHH 将端口 5999 转发到 blackbox 上的端口 5999。这通过运行以下命令完成:
root@tech:~# ssh -L 5999:localhost:5999 thedude@blackbox.example.com
这次使用的 SSH 标记为 -L,它不是将 5999 放到 blackbox,而是从中获取。到达 blackbox 后,需要保持此会话为打开状态。现在即可在 tech 中使用 VNC 了!
在 tech 中,运行以下命令使 VNC 连接到 ginger:
root@tech:~# vncviewer localhost:99
Tech 现在将拥有一个直接到 ginger 的 VNC 会话。设置虽然有点麻烦,但比为修复存储阵列而四处奔波强多了。不过多实践几次这就变得容易了。
对此技巧我还要补充一点:如果 tech 运行的是 Windows® 操作系统,并且没有命令行 SSH 客户端,那么 tech 可以运行 Putty。Putty 可以设置为通过查找侧栏中的选项来转发 SSH 端口。如果端口是 5902 而不是本例中的 5999,则可以输入图 5 中的内容。

如果进行了此设置,那么 tech 就可以使用 VNC 连接到 localhost:2,如同 tech 正在 Linux 操作系统上运行一样。
7、检查带宽
设想:公司 A 有一个名为 ginger 的存储服务器,并通过名为 beckham 的客户端节点装载 NFS。公司 A 确定他们需要从 ginger 得到更多的带宽,因为有大量的节点需要 NFS 装载 ginger 的共享文件系统。
实现此操作的最常用和最便宜的方式是将两个吉比特以太网 NIC 组合在一起。这是最便宜的,因为您通常会有一个额外的可用 NIC 和一个额外的端口。
所以采取此这个方法。不过现在的问题是:到底需要多少带宽?
吉比特以太网理论上的限制是 128MBit/s。这个数字从何而来?看看这些计算:
1Gb = 1024Mb;1024Mb/8 = 128MB;”b” = “bits,”、”B” = “bytes”
但实际看到的是什么呢,有什么好的测量方法呢?我推荐一个工具 iperf。可以按照以下方法获得 iperf:
# wget http://dast.nlanr.net/Projects/Iperf2.0/iperf-2.0.2.tar.gz
需要在 ginger 和 beckham 均可见的共享文件系统上安装此工具,或者在两个节点上编译并安装。我将在两个节点均可见的 bob 用户的主目录中编译它:
tar zxvf iperf*gz
cd iperf-2.0.2
./configure -prefix=/home/bob/perf
make
make install
在 ginger 上,运行:
# /home/bob/perf/bin/iperf -s -f M
这台机器将用作服务器并以 MBit/s 为单位输出执行速度。
在 beckham 节点上,运行:
# /home/bob/perf/bin/iperf -c ginger -P 4 -f M -w 256k -t 60
两个屏幕上的结果都指示了速度是多少。在使用吉比特适配器的普通服务器上,可能会看到速度约为 112MBit/s。这是 TCP 堆栈和物理电缆中的常用带宽。通过以端到端的方式连接两台服务器,每台服务器使用两个联结的以太网卡,我获得了约 220MBit/s 的带宽。
事实上,在联结的网络上看到的 NFS 约为 150-160MBit/s。这仍然表示带宽可以达到预期效果。如果看到更小的值,则应该检查是否有问题。
我最近碰到一种情况,即通过连接驱动程序连接两个使用了不同驱动程序的 NIC。这导致性能非常低,带宽约为 20MBit/s,比不连接以太网卡时的带宽还小!
8、命令行脚本和实用程序
Linux 系统管理员通过使用权威的命令行脚本会变得更高效。这包括巧妙使用循环和知道如何使用 awk、grep 和 sed 等的实用程序解析数据。通常这可以减少击键次数,降低用户出错率。
例如,假设需要为即将安装的 Linux 集群生成一个新的 /etc/hosts 文件。一般的做法是在 vi 或文本编辑器中添加 IP 地址。不过,可以通过使用现有 /etc/hosts 文件并将以下内容追加到此文件来实现。在命令行上运行:
# P=1; for i in $(seq -w 200); do echo "192.168.99.$P n$i"; P=$(expr $P + 1);
done >>/etc/hosts
200 个主机名(n001 到 n200)将由 IP 地址(192.168.99.1 到 192.168.99.200)来创建。手动填充这样的文件有可能会创建重复的 IP 地址或主机名,因此这是使用内置命令行消除用户错误的好例子。请注意,这是在 bash shell(大多数 Linux 发行版的默认值)内完成的。
再举一个例子,假设要检查 Linux 集群中的各个计算节点中的内存大小是否一样。通常,拥有一个发行版或类似的 shell 是最好的。但是为了演示,以下使用 SSH。假设 SSH 设置为不使用密码验证。然后运行:
# for num in $(seq -w 200); do ssh n$num free -tm | grep Mem | awk '{print $2}';
done | sort | uniq
这样的命令行相当简洁。(如果在其中放入正则表达式情况会更糟)。让我们对它进行细分,详细讨论各部分。
首先从 001 循环到 200。使用 seq 命令的 -w 选项在前面填充 0。 然后替换 num 变量,创建通过 SSH 连接的主机。有了目标主机后,向它发出命令。本例中是:
free -m | grep Mem | awk '{print $2}'
1、这个命令的意思是:使用 free 命令获取以兆字节为单位的内存大小。
2、获取这个命令的结果,并使用 grep 获取包含字符串 Mem 的行。
3、获取那一行并使用 awk 输出第二个字段,它是节点中的总内存,在每个节点上执行这个操作。
在每个节点上执行命令后,200 个节点的整个输出就传送(|d)到 sort 命令,以对所有内存值进行排序。最后,使用 uniq 命令消除重复项。这个命令会导致以下情况中的一种:
1、如果所有节点(n001 到 n200)拥有相同的内存大小,则只显示一个数字。这个数字就是每个操作系统看到的内存大小。
2、如果节点内存大小不同,将会看到几个内存大小的值。
3、最后,如果某个节点上的 SSH 出现故障,则会看到一些错误消息。
这个命令并不是完美无缺的。如果发现与预期不同的内存值,您就不知道是哪一个节点出了问题,或者有多少个节点。为此需要发出另一个命令。
这个技巧提供了一种查看某些内容的快速方式,而且如果发生错误,您可以立刻知道。其价值在于快速检查。
9、控制台侦察
有些软件会向控制台输出错误消息,而控制台不一定会显示在 SHH 会话中。使用 vcs 设备可以进行检查。在 SSH 会话中,在远程服务器 # cat /dev/vcs1 上运行以下命令。这将显示第一个控制台中的内容。也可以使用 2、3 等查看其他虚拟终端。如果某个用户在远程系统上输入,您将看到他输入的内容。
在大多数数据场中,使用远程终端服务器、KVM 甚至 Serial Over LAN 是查看这类信息的最好方式;它也提供了带外查看功能的一些好处。使用 vcs 设备能够提供一种快速带内方法,这能节省去机房查看控制台的时间。
10、随机系统信息收集
在 技巧 8 中,介绍了一个使用命令行获取有关系统中总内存信息的例子。在这个技巧中,我将介绍几个其他方法,用于从需要进行验证、故障诊断或给予远程支持的系统收集重要信息。
首先,收集关于处理器的信息。通过以下命令很容易实现:
# cat /proc/cpuinfo
这个命令给出关于处理器的速度、数量和型号的信息。在许多情况下使用 grep 可以得到需要的值。我经常做的检查是确定系统中处理器的数量。因此,如果我买了一台带双核处理器的四核服务器,我可以运行以下命令:
# cat /proc/cpuinfo | grep processor | wc -l
然后我看到值应该是 8。如果不是,我会打电话给供应商,让他们给我派送另一台处理器。
我需要的另一条信息是磁盘信息。可以使用 df 命令获得。我总是添加 -h 标记,以便看到以十亿字节或兆字节为单位的输出。# df -h 还会显示磁盘的分区情况。
列表最后是查看系统固件的方式 —— 一个获取 BIOS 级别和 NIC 上的固件信息的方法。
要检查 BIOS 版本,可以运行 dmidecode 命令。遗憾的是,不能轻易使用 grep 获取信息,所以这不是一个很有效的方法。对于我的 Lenovo T61 laptop,输出如下:
#dmidecode | less
...
BIOS Information
Vendor: LENOVO
Version: 7LET52WW (1.22 )
Release Date: 08/27/2007
...
这比重启机器并查看 POST 输出有效得多。要检查以太网适配器的驱动程序和固件版本,请运行 ethtool:
# ethtool -i eth0
driver: e1000
version: 7.3.20-k2-NAPI
firmware-version: 0.3-0
参考链接 :UCloud内核团队 : Linux 4.1内核热补丁成功实践:https://mp.weixin.qq.com/s/Nutdl9Wfva1TyAGDwR9QOg
高效的 Linux 管理员都会的 10 个关键技巧 :https://mp.weixin.qq.com/s/ldgJtNA4l4VAuRvra3TGcw
线上服务 CPU 100%?一键定位 so easy! : https://mp.weixin.qq.com/s/8LtKKWNeNvsbBQ6MEy42kg
开发导致的内存泄露问题,这样排查不背锅(彩蛋)! : https://mp.weixin.qq.com/s/m69lvkTLbV65szQPpL0NdA
使用atop排查 谁引起了CPU小尖峰 : http://bean-li.github.io/CPU-sharp-pulse/
深入理解iostat : http://bean-li.github.io/dive-into-iostat/
给网络注入点延迟 : http://bean-li.github.io/import-network-delay/
Linux 磁盘爆满故障排查 (命令): https://blog.csdn.net/luohuaruxue/article/details/44225863















 1203
1203

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









