







 本文深入探讨了R语言中三种常用的高维数据降维方法:主成分分析(PCA)、核PCA(KPCA)和t-SNE,通过威士忌数据集的案例展示了它们在数据探索和机器学习中的应用。PCA和KPCA提供了线性和非线性降维,而t-SNE在可视化方面表现出色。研究发现,PCA和t-SNE能够有效揭示威士忌的区域特征和味道属性,而KPCA则需要谨慎处理超参数。
本文深入探讨了R语言中三种常用的高维数据降维方法:主成分分析(PCA)、核PCA(KPCA)和t-SNE,通过威士忌数据集的案例展示了它们在数据探索和机器学习中的应用。PCA和KPCA提供了线性和非线性降维,而t-SNE在可视化方面表现出色。研究发现,PCA和t-SNE能够有效揭示威士忌的区域特征和味道属性,而KPCA则需要谨慎处理超参数。
维度降低有两个主要用例:数据探索和机器学习。它对于数据探索很有用,因为维数减少到几个维度(例如2或3维)允许可视化样本。然后可以使用这种可视化来从数据获得见解(例如,检测聚类并识别异常值)。对于机器学习,降维是有用的,因为在拟合过程中使用较少的特征时,模型通常会更好地概括。
在这篇文章中,我们将研究三维降维技术:
- 主成分分析(PCA):最流行的降维方法
- 内核PCA:PCA的一种变体,允许非线性
- t-SNE t分布随机邻域嵌入:最近开发的非线性降维技术
这些方法之间的关键区别在于PCA输出旋转矩阵,可以应用于任何其他矩阵以转换数据。另一方面,诸如t分布随机邻居嵌入(t-SNE)的基于邻域的技术不能用于此目的。
加载威士忌数据集
我们可以通过以下方式加载数据集:
df <- read.csv(textConnection(f), header=T)
# select characterics of the whiskeys
features <- c("Body", "Sweetness", "Smoky",
"Medicinal", "Tobacco", "Honey",
"Spicy", "Winey", "Nutty",
"Malty", "Fruity", "Floral")
feat.df <- df[, c("Distillery", features)]关于结果的假设
在我们开始减少数据的维度之前,我们应该考虑数据。我们期望具有相似味道特征的威士忌在缩小的空间中彼此接近。
由于来自邻近酿酒厂的威士忌使用类似的蒸馏技术和资源,他们的威士忌也有相似之处。
为了验证这一假设,我们将测试来自不同地区的酿酒厂之间威士忌特征的平均表达是否不同。为此,我们将进行MANOVA测试:
## Df Pillai approx F num Df den Df Pr(>F)
## Region 5 1.2582 2.0455 60 365 3.352e-05 ***
## Residuals 80
## ---
## Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1检验统计量在5%水平上是显着的,因此我们可以拒绝零假设(区域对特征没有影响)。这意味着适当的降维应该在一定程度上保持酿酒厂的地理位置。
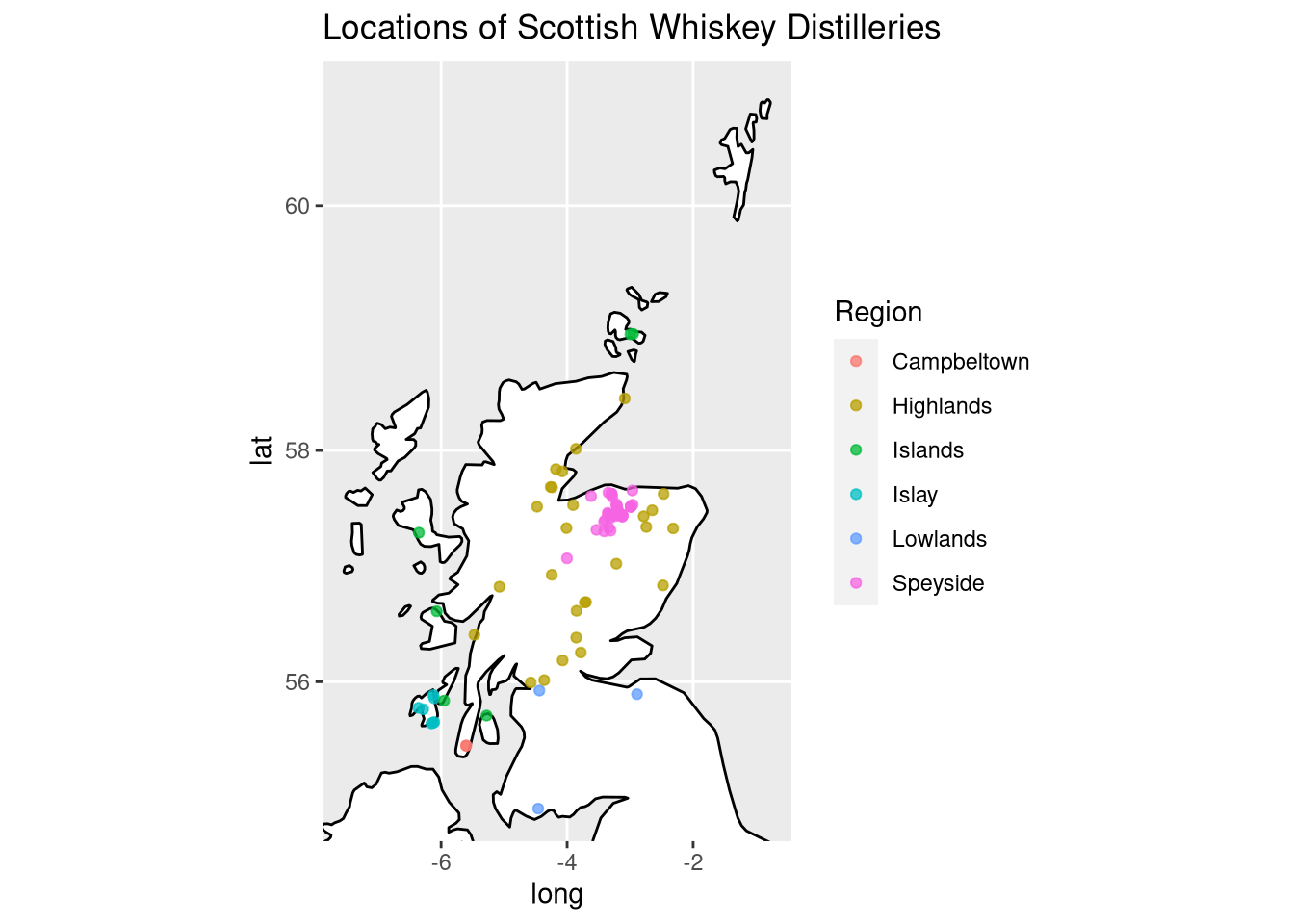
酿酒厂的地理位置
由于区域性对威士忌起着重要作用,我们将通过绘制其纬度和经度来探索数据集中的酿酒厂所在的位置。以下苏格兰威士忌地区存在:

![]()
苏格兰地区(根据CC BY-SA 3.0许可,并从https://commons.wikimedia.org/wiki/File:Scotch_regions.svg检索)
![]()
PCA
使用PCA可视化威士忌数据集
PCA通常使用该prcomp功能执行。在这里,我们使用,autoplot因为我们主要对可视化感兴趣。
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 486
486

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言










{kind=link}