






不知阁下是否都听说过赶集网,我想对大多数人来说,应该不会太陌生,有时无聊之时,还是可以去逛逛,了解社会百态,熟悉人间风情,品味生活精彩,呵呵。
赶集网基本是按照全国城市分类的,每一个城市是相同界面,不同内容。你可以在不同城市中切换,以便关注该城市的各种信息。

对应每个城市,赶集网又有不同的分类,基本上涵盖了生活的方方面面。

进入一个特定的分类,你可以看到相关的用户文章,有些事经纪人发的,有些是普通老百姓发的,各取所需,各观所好。

好了,说到这里,请不要以为我是给赶集网做广告,呵呵,肯定不是。
我是先解剖赶集网的内容结构,为做内容采集做准备,下面先Show一下我做的赶集网采集程序先,先有一个感性的认识,也为下面的代码找一个实在的宿主,而并非纯理论的研究,哈哈。
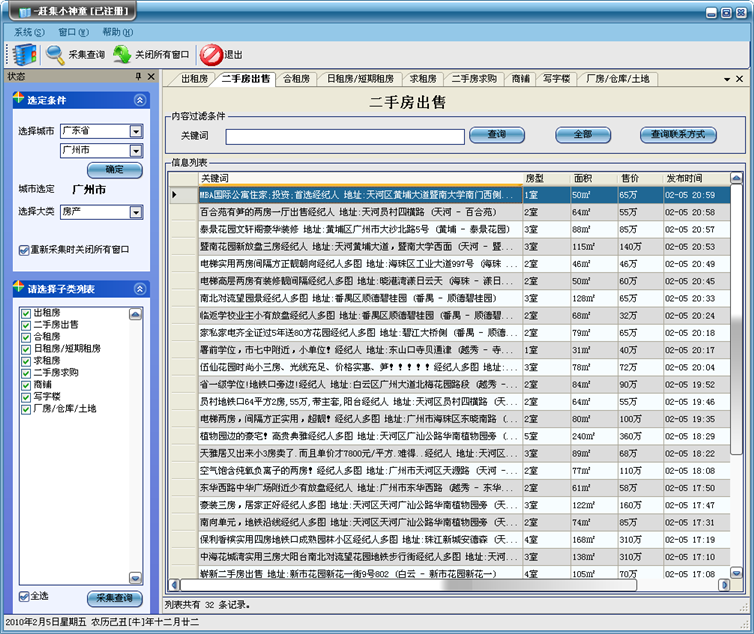
下面分析赶集网的内容获取及程序的工作方式:
首先第一步,我们要拿到全国省市的的划分名称,这部可以去国家统计局那里找找,哈哈,我是说真的哦。
赶集网每个城市,对应一个编号,如北京对应bj,广州对应gz, 你从上面的城市划分的源码中可以找到:<dd><a href="http://bj.ganji.com/" class="redLink">北京</a></dd>,这里面的内容就包含了bj的内容,后面加上ganji.com就是北京赶集网的链接地址了,花点功夫把它找出来吧。
第二个是网站内容的分类,我查过不同城市的分类好像是一样的,因此只需要获取一个城市的分类就可以了,其他的就一样。
把分类的内容保存成html,然后放到VS格式化一通,得到了内容如下所示:

下面你根据内容,编写一个正则表达式来把分类提取出来,就可以了。献上拙例,供参考。
首先我们把分类分级,一级分类是房产、二手物品、招聘等大类,二级分类表示大分类(如房产)下面的小分类,如出租房、二手房等内容类别。
下面代码是大类的获取:
 代码
代码
{
string mainUrl = " http://gz.ganji.com " ;
string DataRegex = " <dt><a\\s*?href=\ " ( ?< value > . *? )\ " \\s*?target=\ " _blank\ " >(?<key>.*?)»</a></dt> " ;
string itemString = "" ;
itemString = CSocket.GetHtmlByUrl(mainUrl);
Database db = DatabaseFactory.CreateDatabase();
DbCommand command = null ;
if ( ! string .IsNullOrEmpty(itemString))
{
Regex re = new Regex(DataRegex, RegexOptions.IgnoreCase | RegexOptions.Multiline | RegexOptions.IgnorePatternWhitespace);
Match mc = re.Match(itemString);
if (mc.Success)
{
MatchCollection mcs = re.Matches(itemString);
foreach (Match me in mcs)
{
string strKey = me.Groups[ " key " ].Value;
string strValue = me.Groups[ " value " ].Value;
try
{
string sql = string .Format( " insert into GanjiCategory(CategoryName,CategoryUrl) values('{0}','{1}{2}') " ,
strKey, mainUrl, strValue);
command = db.GetSqlStringCommand(sql);
db.ExecuteNonQuery(command);
string tips = string .Format( " 正在处理 {0} " , strKey);
CallCtrlWithThreadSafety.SetText < Label > ( this .lblSchoolTips, tips, this );
}
catch (Exception ex)
{
LogHelper.Error(ex);
}
}
}
}
}
下面代码是小分类的获取:
 代码
代码
{
string mainUrl = " http://gz.ganji.com " ;
Database db = DatabaseFactory.CreateDatabase();
DbCommand command = null ;
string content = CSocket.GetHtmlByUrl(mainUrl);
try
{
#region 获得各项列表字符串
List < string > itemHtmlList = new List < string > ();
string itemRegex = " <dl\\s*?class=\ " list_. *? \ " >\\s*(.*?)\\s*</dl> " ;
Regex re = new Regex(itemRegex, RegexOptions.IgnoreCase | RegexOptions.Singleline | RegexOptions.IgnorePatternWhitespace);
Match mc = re.Match(content);
if (mc.Success)
{
MatchCollection mcs = re.Matches(content);
foreach (Match me in mcs)
{
string strValue = me.Groups[ 1 ].Value;
itemHtmlList.Add(strValue);
}
}
#endregion
#region 对每项内容进行解析
foreach ( string itemString in itemHtmlList)
{
string cateDataRegex = " <dt><a\\s*?href=\ " ( ?< value > . *? )\ " \\s*?target=\ " _blank\ " >(?<key>.*?)»</a></dt> " ;
string itemNameRegex = " <dd>\\s*<a\\s*href=\ " ( ?< value > . *? )\ " \\s*target=\ " _blank\ " >(?<key>.*?)</a>\\((?<id>.*?)\\)</dd> " ;
re = new Regex(cateDataRegex, RegexOptions.IgnoreCase | RegexOptions.Singleline | RegexOptions.IgnorePatternWhitespace);
mc = re.Match(itemString);
string categoryName = "" ;
if (mc.Success)
{
Match me = re.Matches(itemString)[ 0 ];
categoryName = me.Groups[ " key " ].Value;
}
re = new Regex(itemNameRegex, RegexOptions.IgnoreCase | RegexOptions.Multiline | RegexOptions.IgnorePatternWhitespace);
mc = re.Match(itemString);
if (mc.Success)
{
MatchCollection mcs = re.Matches(itemString);
foreach (Match me in mcs)
{
string strKey = CText.GetTxtFromHtml(me.Groups[ " key " ].Value);
string strValue = me.Groups[ " value " ].Value;
try
{
// 保存内容代码
string tips = string .Format( " 正在处理 {0} " , strKey);
CallCtrlWithThreadSafety.SetText < Label > ( this .lblSchoolTips, tips, this );
}
catch (Exception ex)
{
LogHelper.Error(ex);
}
}
}
}
#endregion
}
catch (Exception ex)
{
LogHelper.Error(ex);
}
}
完成上面两步后,我们就可以继续第三部,采集赶集网的内容等信息了。
















 1097
1097

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









