






串(String)—–零个或多个字符组成的有限序列
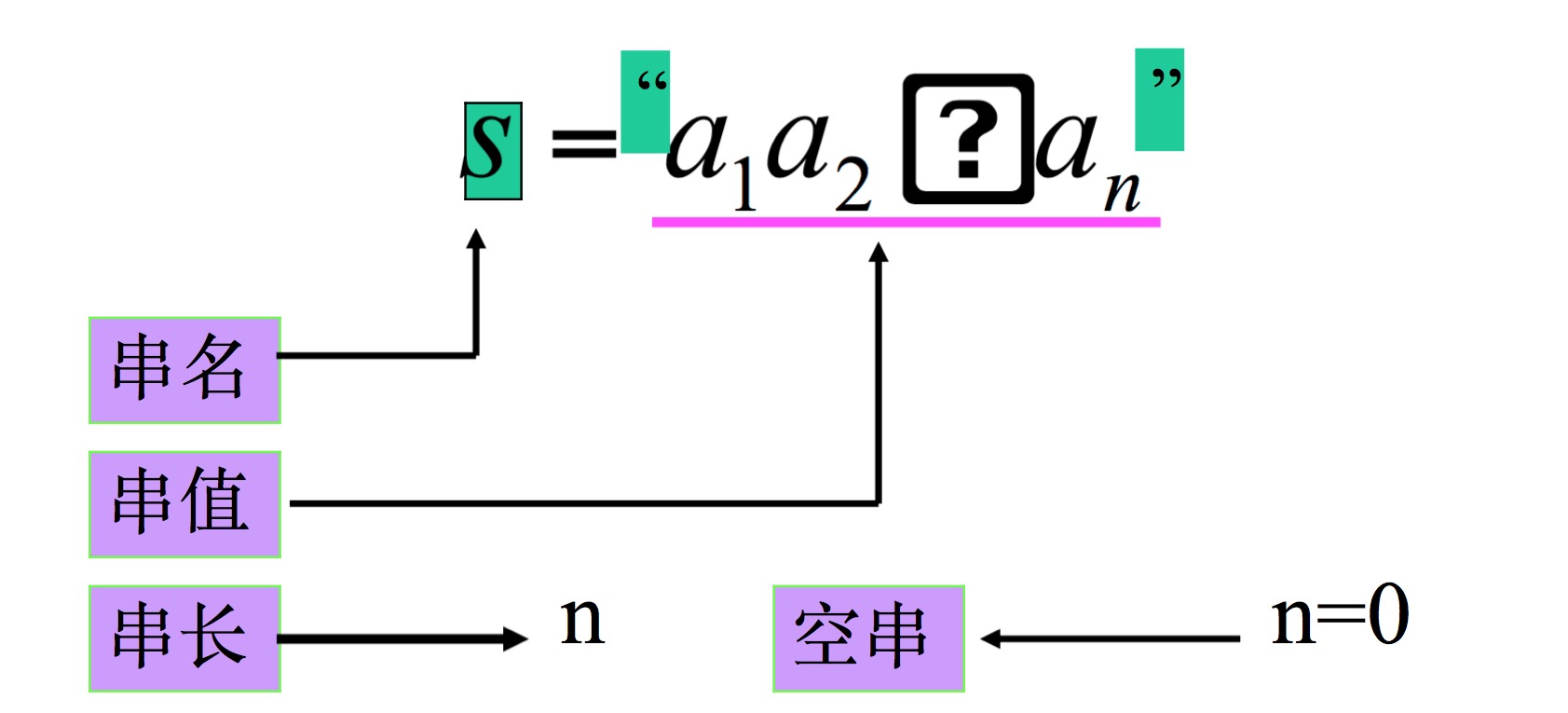
a="beijinghuanyingni"
b="beijinghuanying"
c="beijin"
d=""
子串:串中任意个连续的字符组成的子序列称为该串的子串。
比如上面的b是a的子串、c是a或者b的子串。
空串:零个字符的串。注意是”“而不是” “。空串是任意串的子串,任意串是其自身的子串。
串的抽象数据类型
ADT String{
数据对象: D={ai|ai∈CharacterSet,i=1,2,…,n,n≥0}
数据关系:R1={ <\ai-1,ai>|ai-1,ai-1,ai∈D,i=2,…,n}
StrAssign(T,*chars): 生成一个其值等于字符常量chars的串T.
StrCopy(T,S): 串S存在,由S复制得到T.
ClearString(S): 串S存在,将串清空.
StringEmpty(S): 若串为空,返回true,否则返回false.
StrLentgth(S) : 返回串S的元素个数,即串的长度.
StrCompare(S,L): 比较S和T,若S>T,返回>0,S==T返回0,
S
SubString(Sub, S, pos, len): 串S存在,1<=pos<=StrLentgth(S),且 0<=len<=StrLentgth(S)-pos+1,用Sub返回串S的第pos个起
长度为len的子串.
Index(S,T,pos)
Replace(S,T,V) 串S,T,V存在,T是非空串,用V替换S中出现的所有与T相等的不重叠的子串.
StrInsert(S,T,pos): 在串S的第pos个字符之前插入串T.
StrDelete(S,pos,len): 从串S中删除第pos个字符起的长度为len的子串.
}
串的存储结构
- 顺序存储
- 链式存储
顺序存储表示
typedef struct{
char *ch;//若串非空,则按照串长分配存储区,否则ch为NULL
int length;//串长度
}String;
链式存储表示#define CHUNKSIZE 80
typedef struct Chunk{
char ch[CHUNKSIZE];
struct Chunk *next;
}Chunk;
typedef struct{
Chunk *head,*tail;
int curled;
}String;
链式存储优点:操作方便
缺点:存储密度较低
存储密度=串值所占的存储位/实际分配的存储位
BF算法
BF(Brute-Force)算法的基本思路:
1)从目标串s的第一个字符起和模式串的第一个字符进行比较,若相等。则继续逐个比较后续字符,否则从串s的第二个字符起再重新和串t进行比较。
2)依次类推,直至串t中的每个字符依次和串s的一个连续的字符序列相等,则模式匹配成功,此时串t的第一个字符在串s的位置就是t在s中的位置,否则模式匹配不成功。

#include <stdio.h>
#include "stdlib.h"
//宏定义
#define TRUE 1
#define FALSE 0
#define OK 1
#define ERROR 0
#define MAXSTRLEN 100
typedef char SString[MAXSTRLEN + 1];
//返回子串T在主串S中第pos位置之后的位置,若不存在,返回0
int BFindex(SString S, SString T, int pos)
{
if (pos <1 || pos > S[0] ) exit(ERROR);
int i = pos, j =1;
while (i<= S[0] && j <= T[0])
{
if (S[i] == T[j])
{
++i; ++j;
} else {
i = i- j+ 2;
j = 1;
}
}
if(j > T[0]) return i - T[0];
return ERROR;
}
void main(){
SString S = {13,'a','b','a','b','c','a','b','c','a','c','b','a','b'};
SString T = {5,'a','b','c','a','c'};
int pos;
pos = BFindex( S, T, 1);
printf("%d",pos);
}
BF算法特点:
通过上面的例子可以看到BF算法思路直接简明。但当匹配失败时,主串的指针i总是要回到i-j+2位置,模式串的指针总是恢复到首字符的位置j=1,因此,算法时间复杂度高。
KMP算法
KMP算法是改进了BF算法,小编对这个算法也是似懂非懂,今后学习后会为大家讲解















 5万+
5万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









