






本文介绍使用八爪鱼采集词库网内长尾关键词的方法。长尾关键词挖掘对于站长来说是非常重要的一项技能, 长尾理论中的尾巴作用是不能忽视的。在搜索引擎营销中运用长尾理论来制定关键词策略是十分有效的。
虽然核心关键词或者比较热门的关键词带来的流量会超过总流量的一半,但是那些搜索人数不多,但是又比较明确的关键词(长尾关键词)综合也能为网站带了一笔很大的访问量,然而正是这些长尾的关键词带来的顾客的转化率更高。
采集网站:
本文就以一组(100个B2B行业有指数的关键词)为例,来采集关于这一组关键词的所有相关长尾关键词。
采集的内容包括:搜索后的长尾关键词,360指数,该长尾关键词搜索量以及搜索量的第一位网站(页面)这四个有效字段。
使用功能点:
l循环文本输入
/tutorialdetail-1/wbxh_7.html
lXpath
l数字翻页
步骤1:创建词库网采集任务
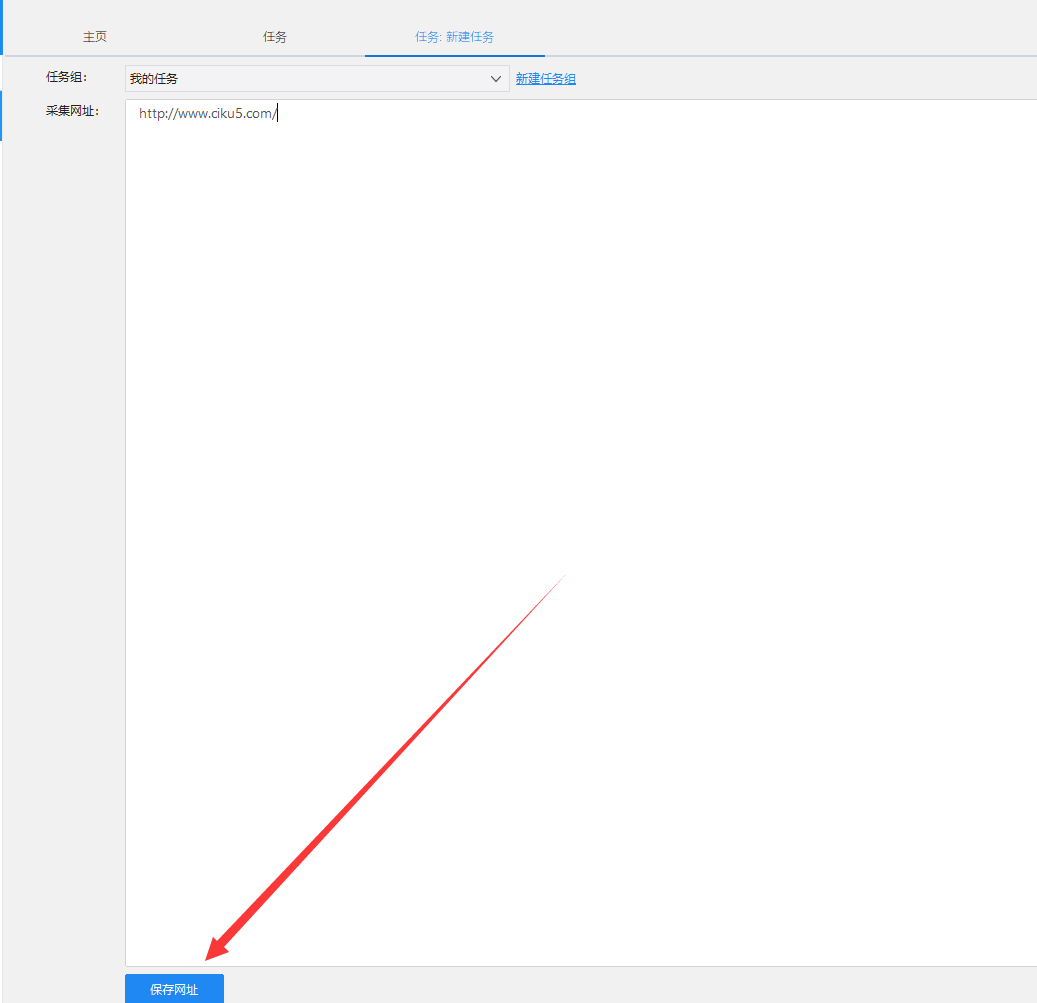
1)进入主界面,选择“自定义采集”

2)将要采集的网址URL复制粘贴到网站输入框中,点击“保存网址”
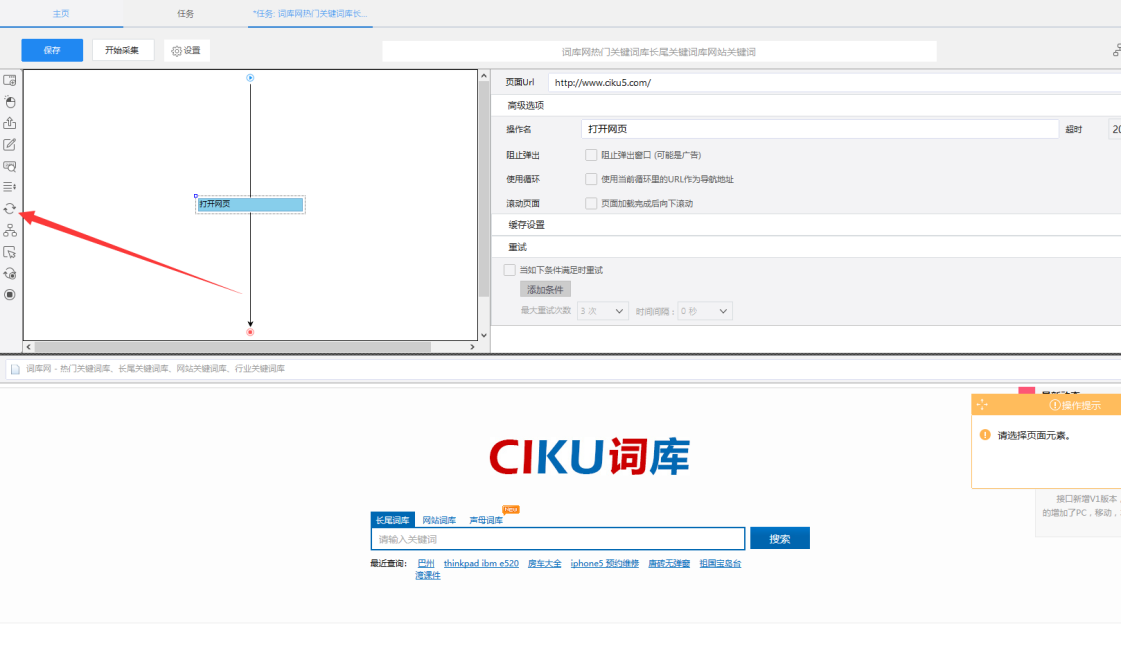
步骤2:创建循环输入文本
1)打开网页之后,点开右上角的流程,然后从左侧拖一个循环进来
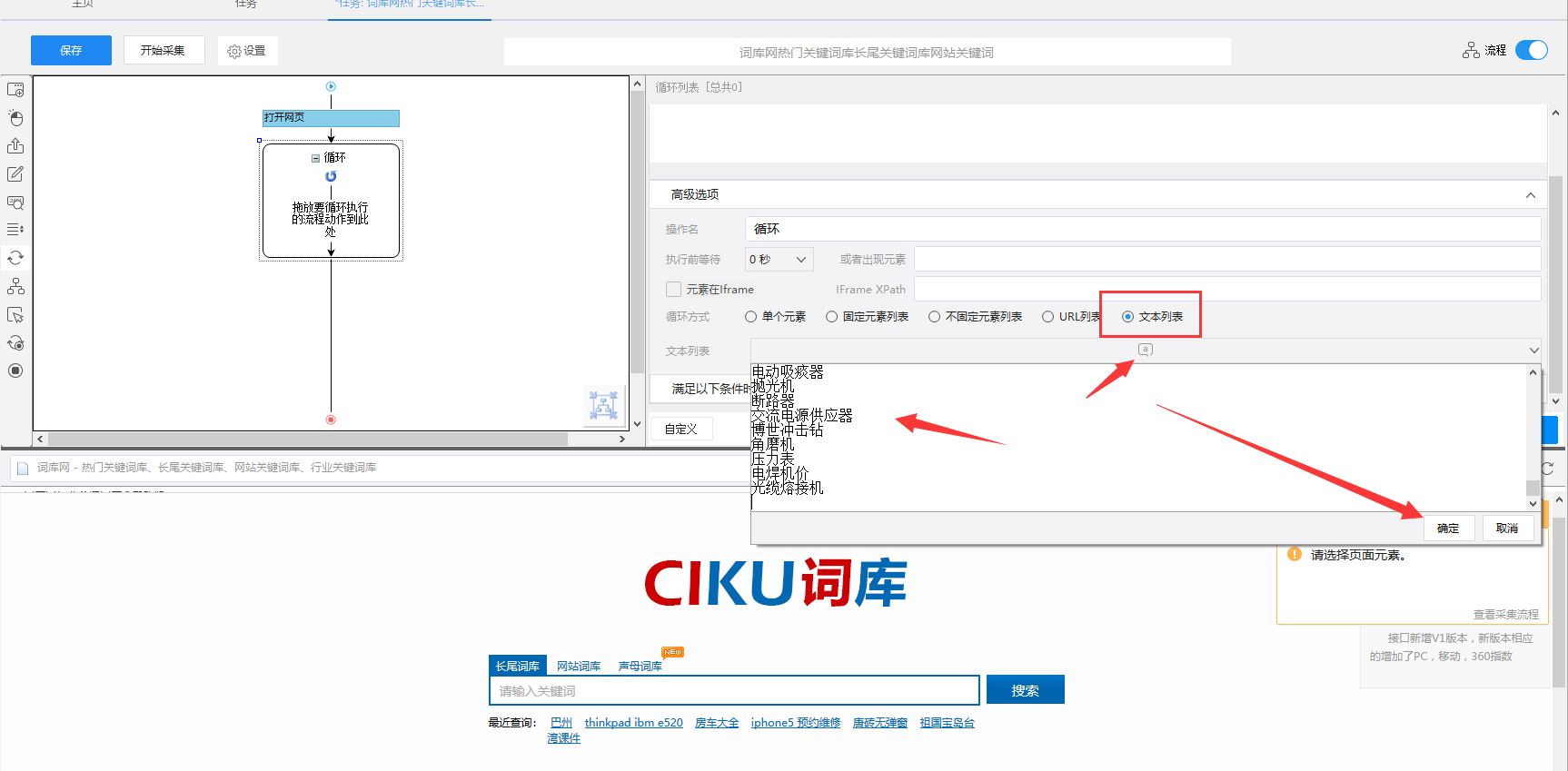
2)点击循环步骤,在它的高级选项那里选择文本列表,再点开下面的A,把复制好的关键词全部粘贴进去,注意换行,再点击确定保存。
3)创建好循环文本输入后,点击页面上的搜索框,创建输入文本的步骤,注意,不需要输入任何文本即可,若是自动生成的是在循环外面,拖入进去,再勾选循环即可。
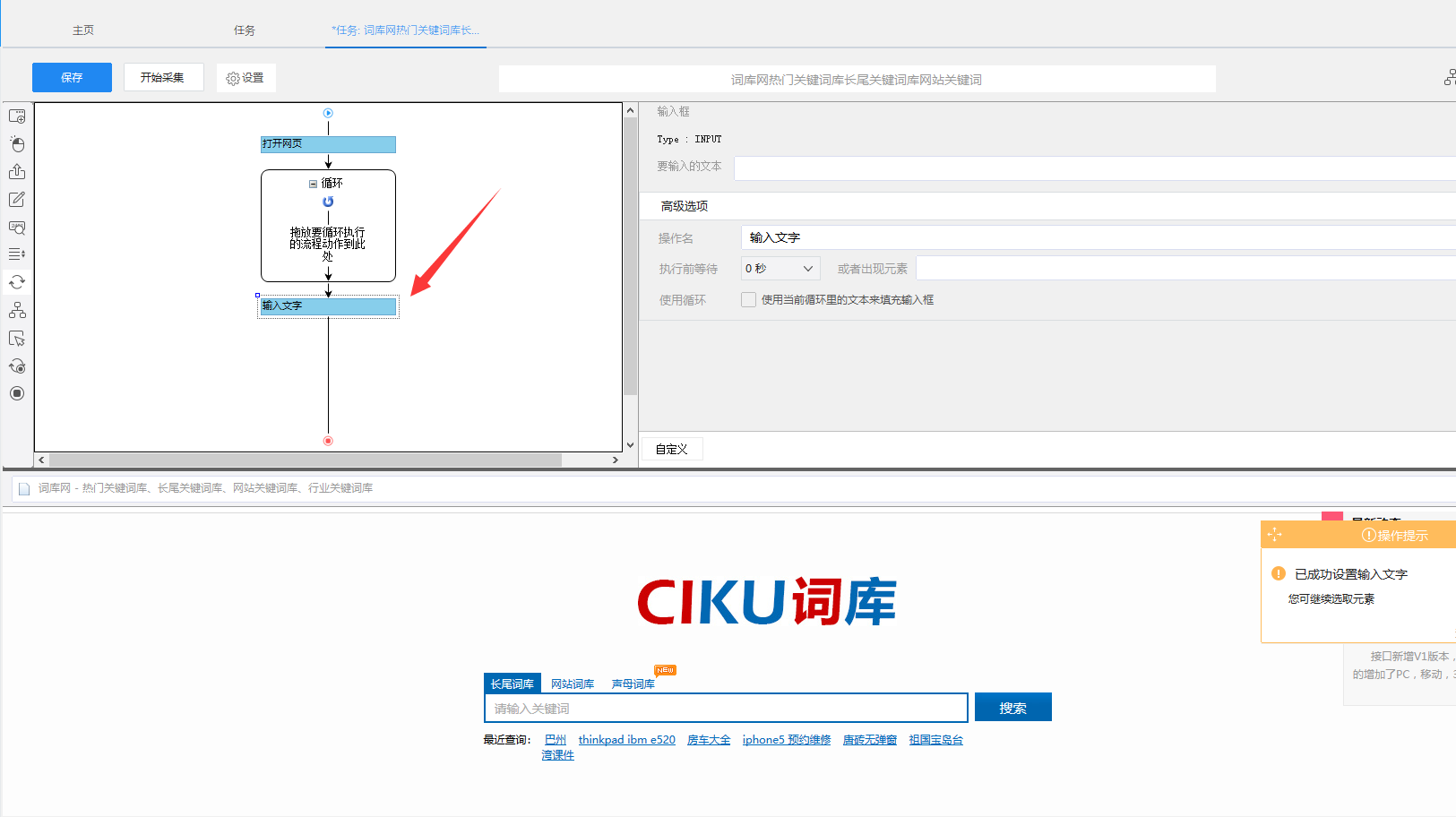
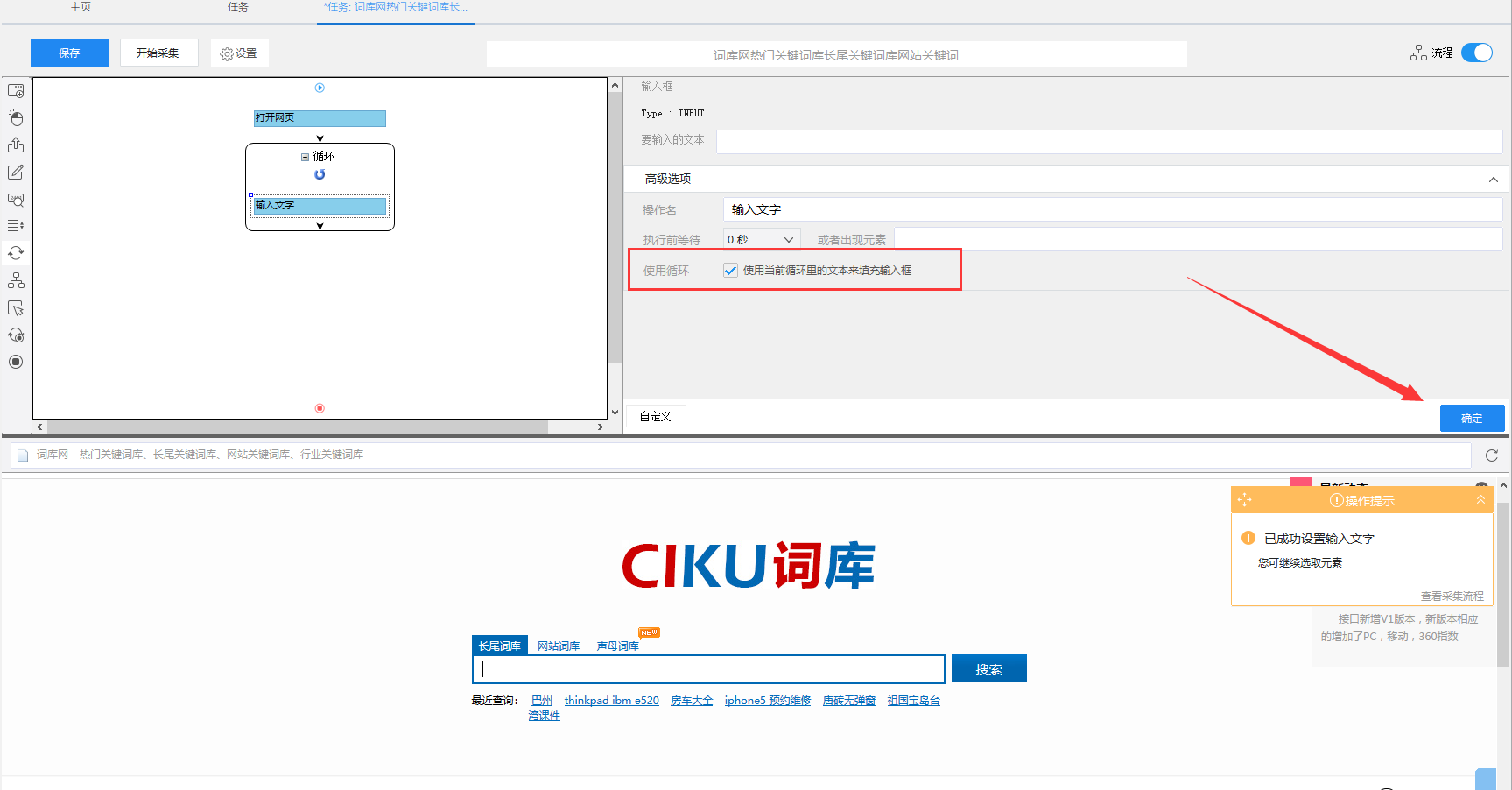
4)右键选择页面上的搜索按钮,设置好点击元素,这样,循环文本输入就设置好了,流程下方就是搜索出来的长尾关键词。
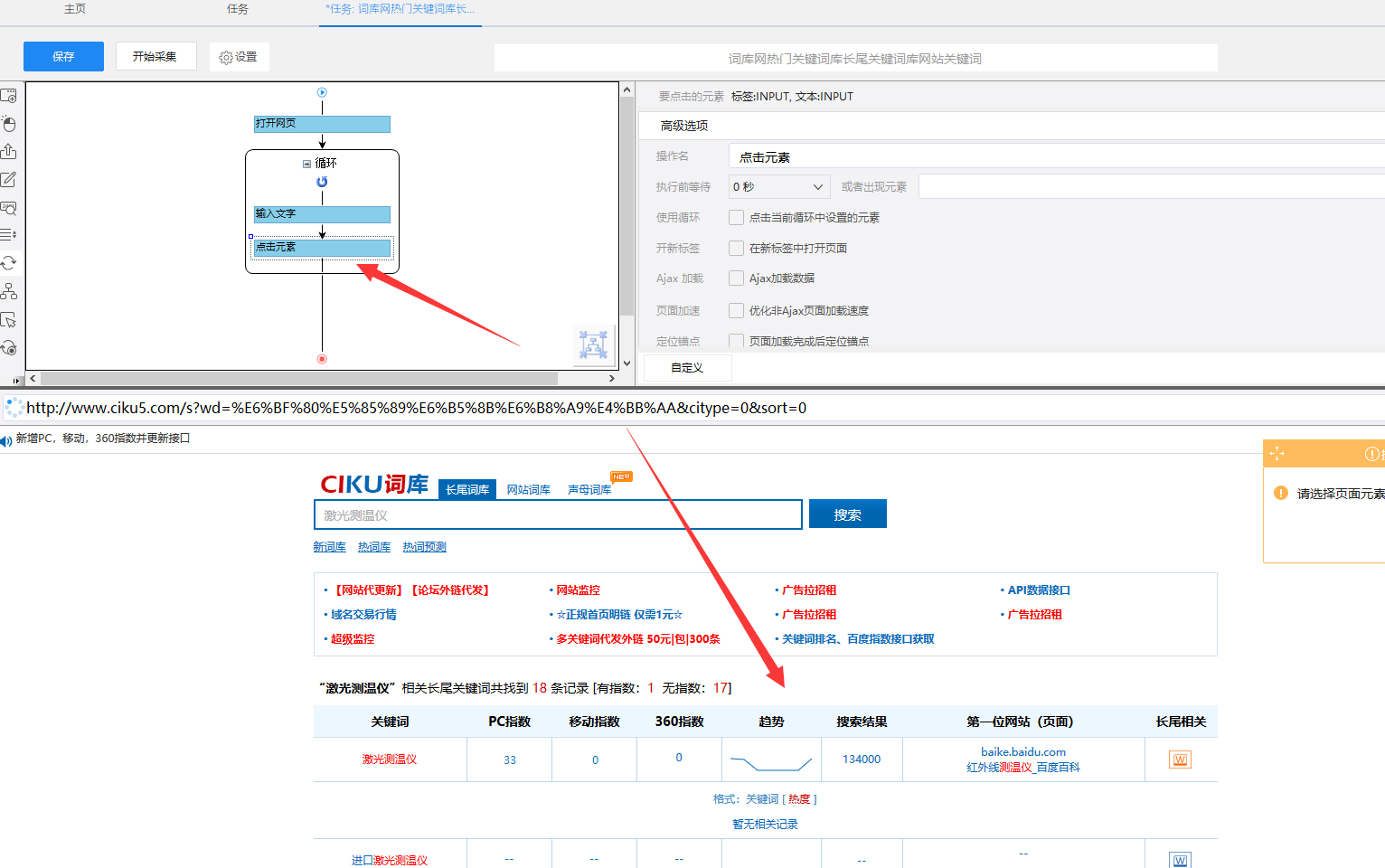
步骤3:创建数字翻页
1)由于该搜索结果页面没有下一页按钮,只有数字页数,所以我们需要用到xpath的一些相关知识,来设置特殊的数字翻页。首先去火狐浏览器里把该网页打开并搜索相应关键词后,打开浏览器右上角的firebug工具--小瓢虫(不懂的同学可以去官网教程看一下相应的xpath教程)
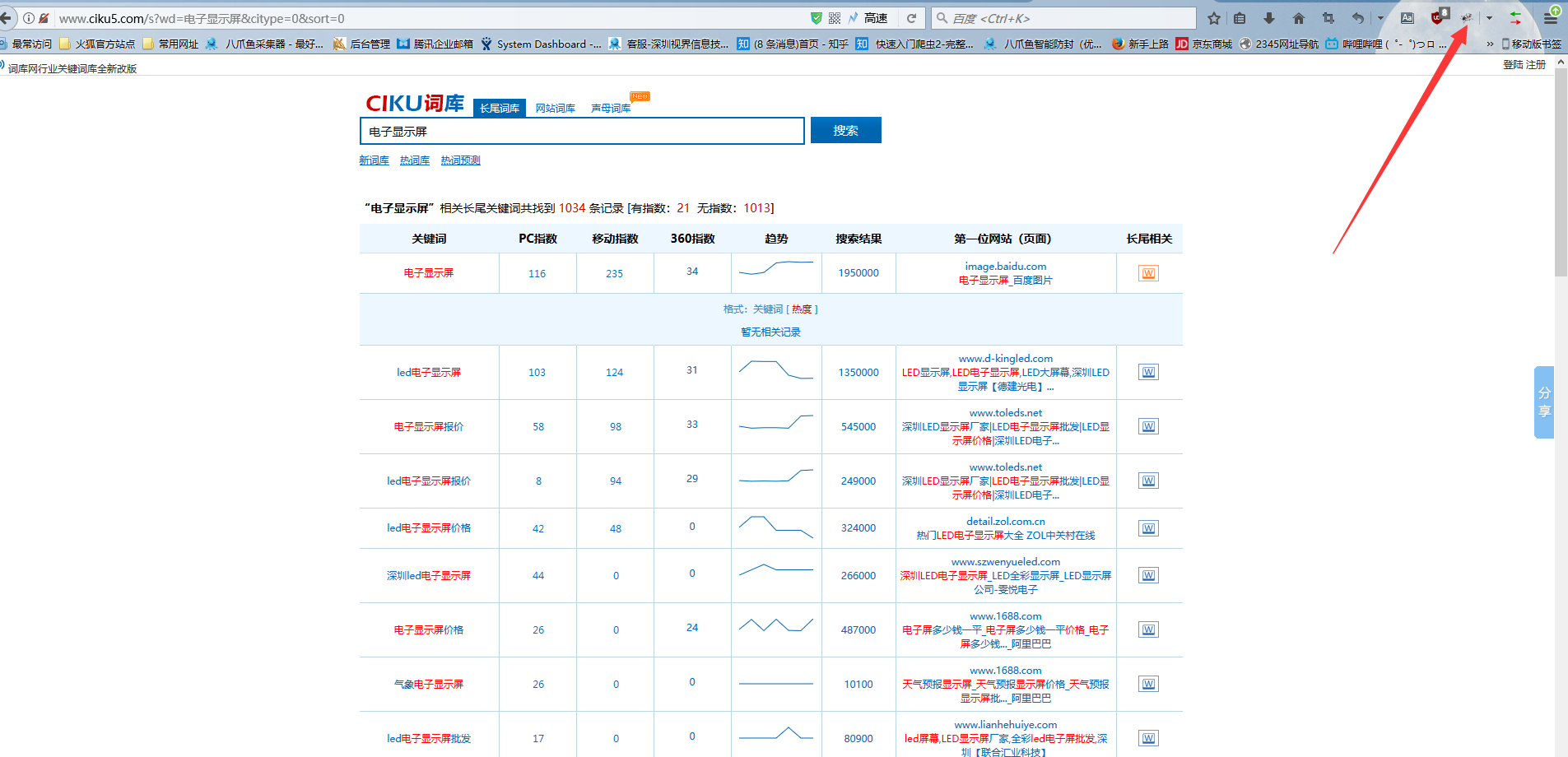
2)翻到页面下方,找到数字位置的源码,可以看到当前页面的数字跟其他数字,在源码里节点的属性class是有所不同的
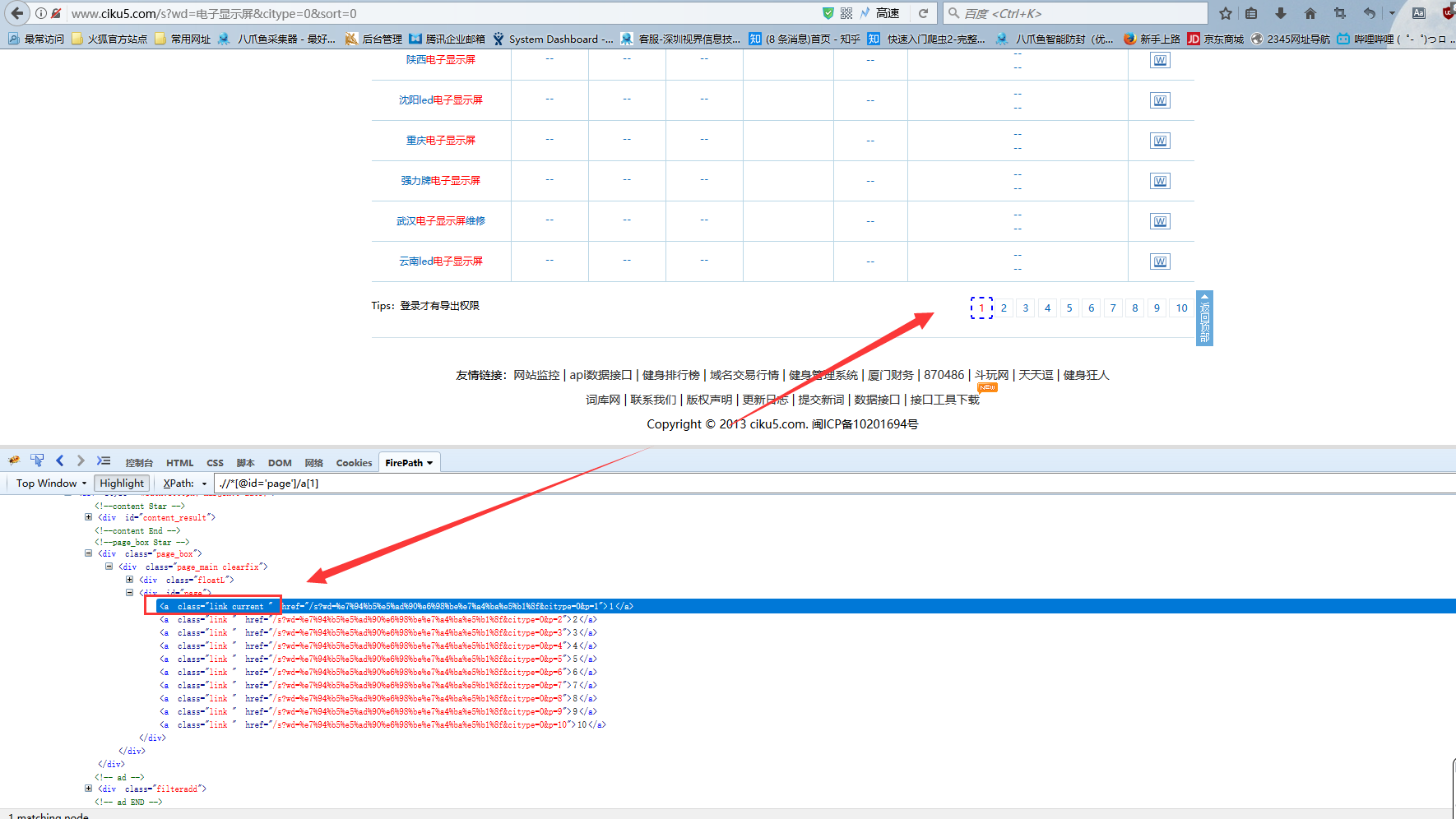
3)收益我们首先定位到该页面的数字位置,手写xpath://div[@id="page"]/a[contains(@class,'current')]

4)再利用固定函数following-sibling来定位到该节点后的第一个同类节点,注意,该函数后面接::是固定格式,a[1]是指该节点后的第一个同类节点
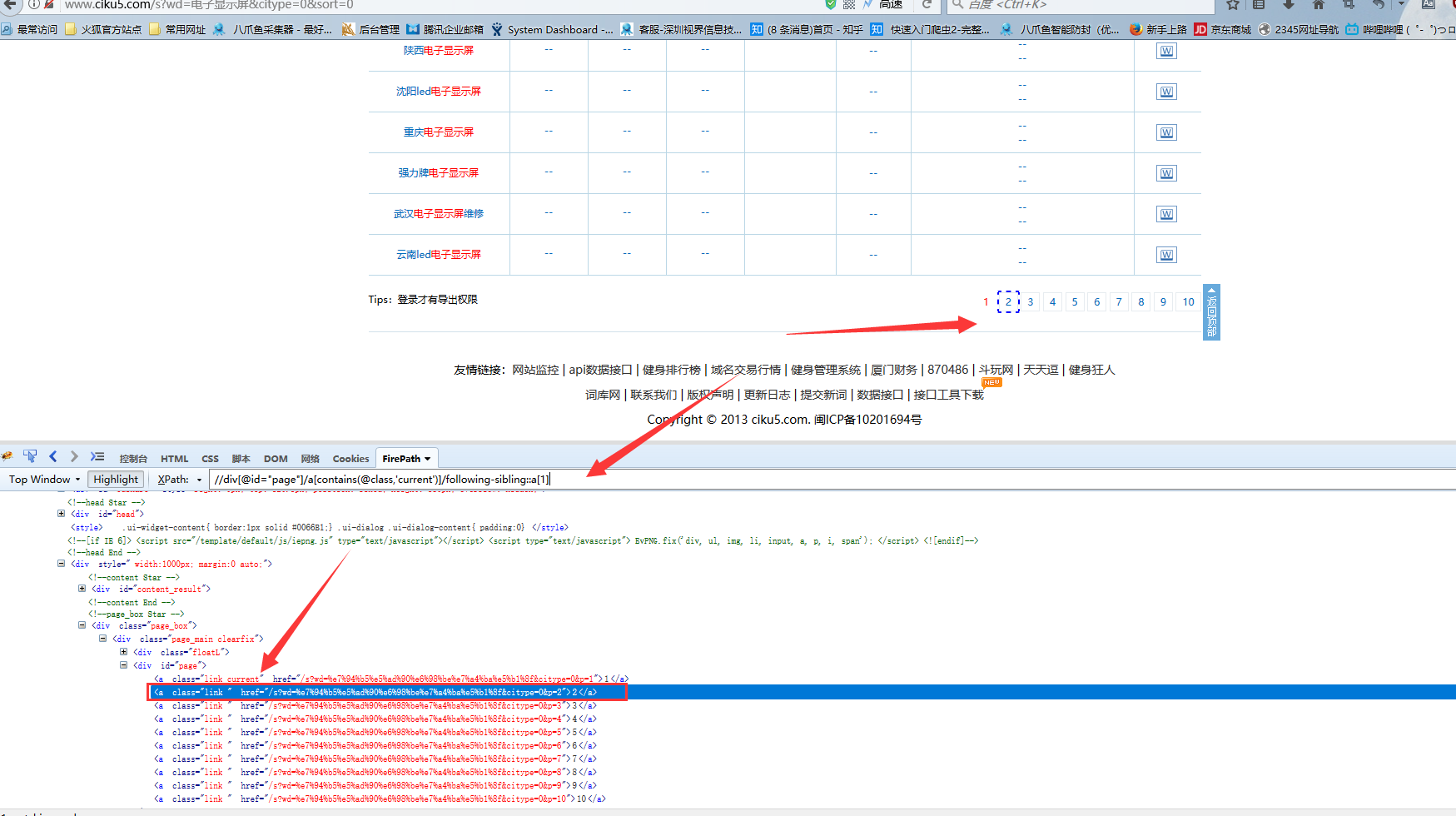
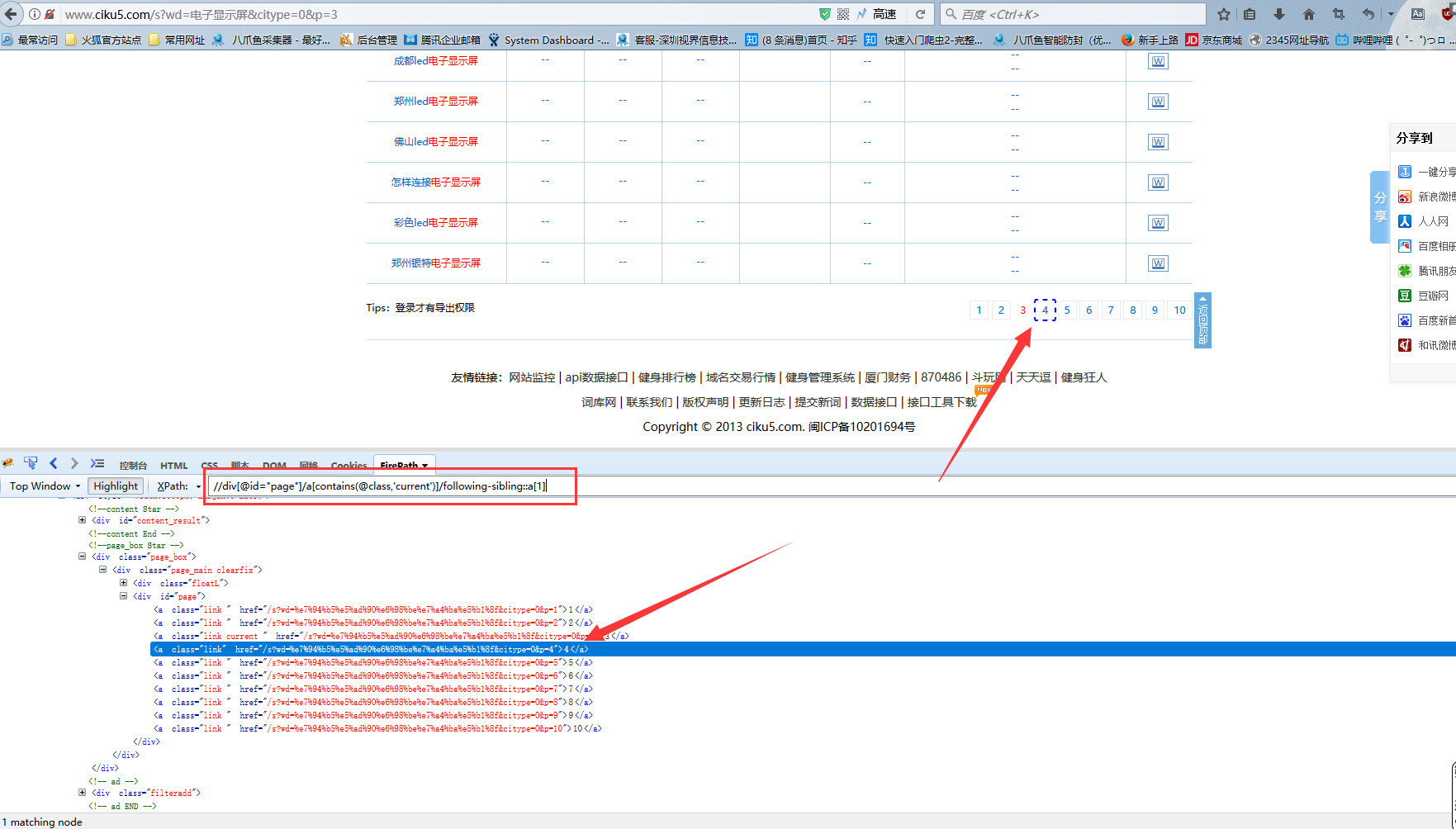
5)可以查看翻页后还是正常定位到下一页的数字上,说明该xpath没有问题
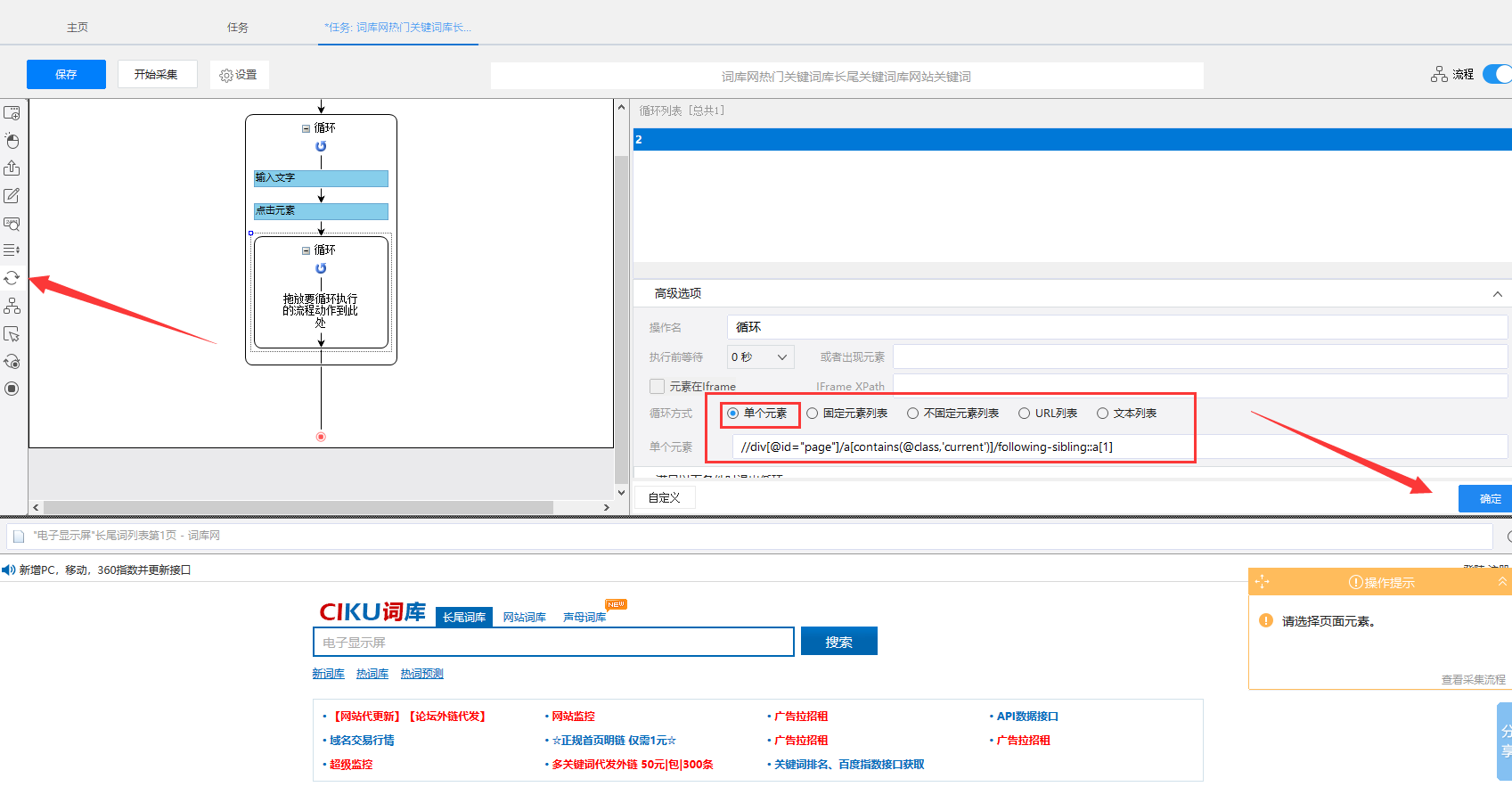
6)再回到八爪鱼,在左侧流程页面拖一个循环进来,高级选项里选择单个元素,并把xpath放入进去,点确定保存好
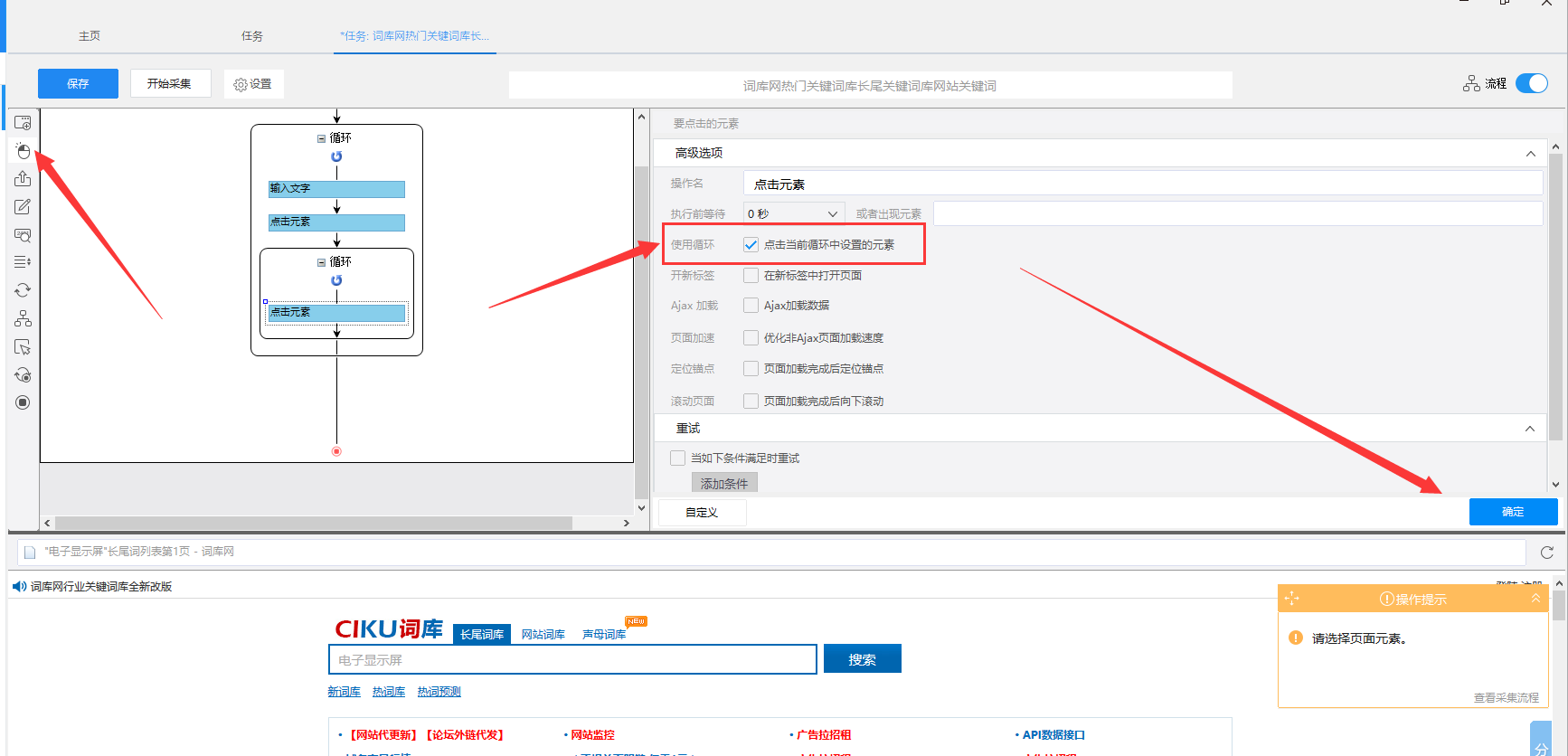
7)再从左侧拖一个点击元素进来,并在高级选项里勾选好循环,特殊数字翻页循环就创建好了
步骤4:创建循环列表
1)我们安装常规方法创建循环列表,发现,由于搜索结果后的表格中出现了这个无用的一整行信息。

2)于是在八爪鱼里面是无法正常的创建好循环列表的,因为这个无用的信息导致八爪鱼自动生成的列表会定位不准
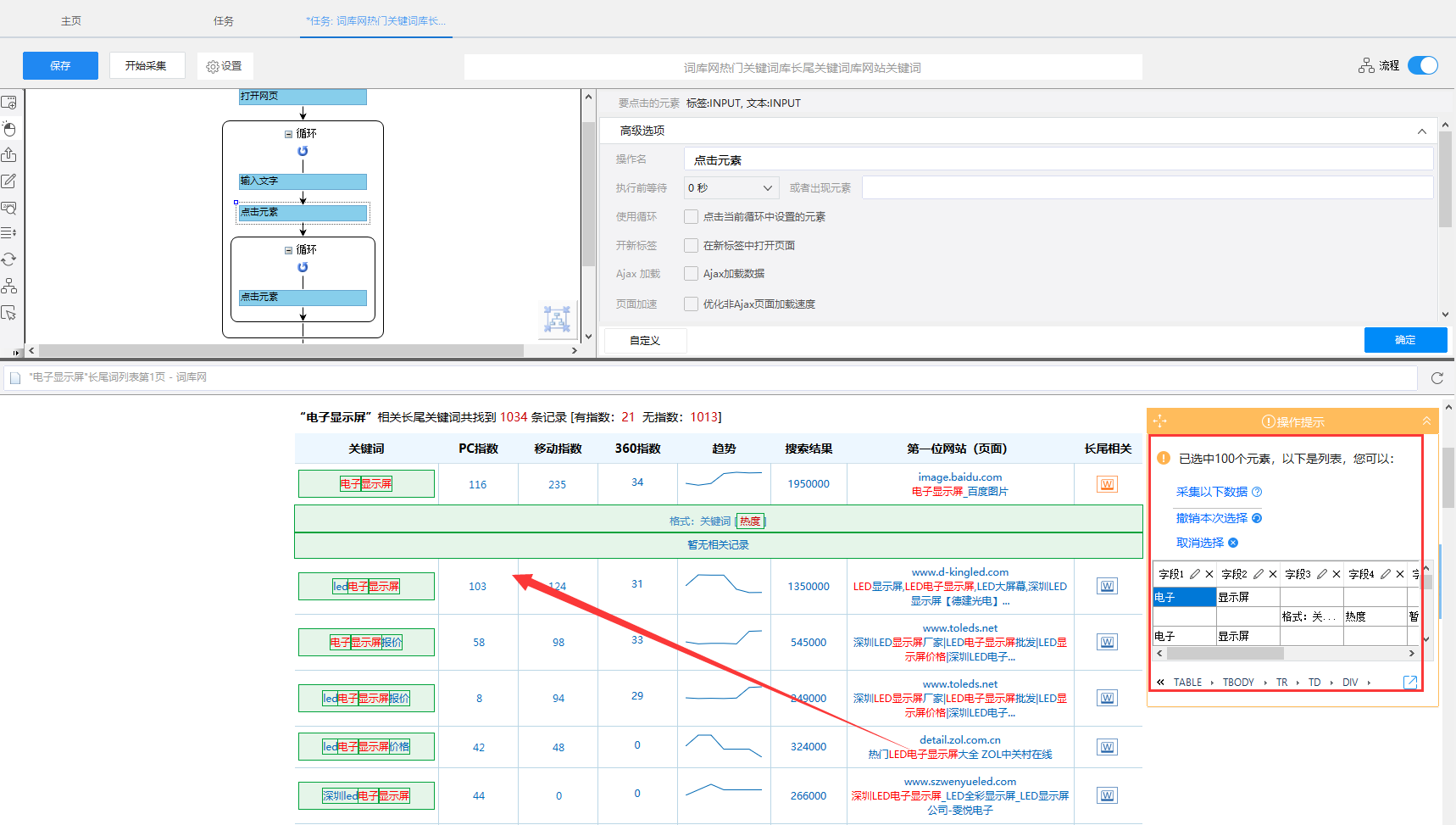
3)所以我们还是得用到xpath的知识,去火狐浏览器里面手动创建一个循环列表的xpath。首先定位到第一行第一列的源码位置
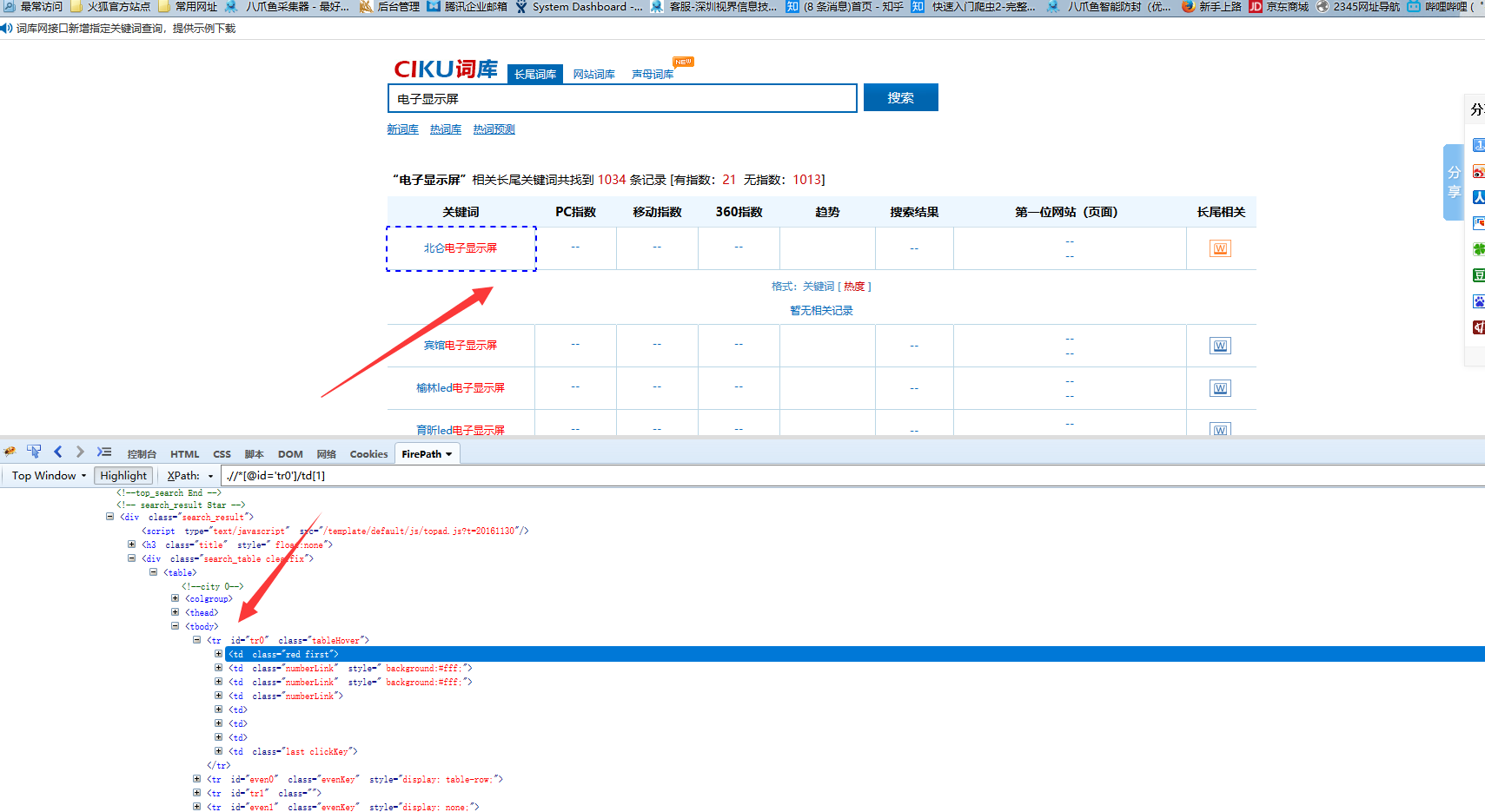
4)再找到每一行的源码位置,发现他们都是tbody父节点下相同的tr标签
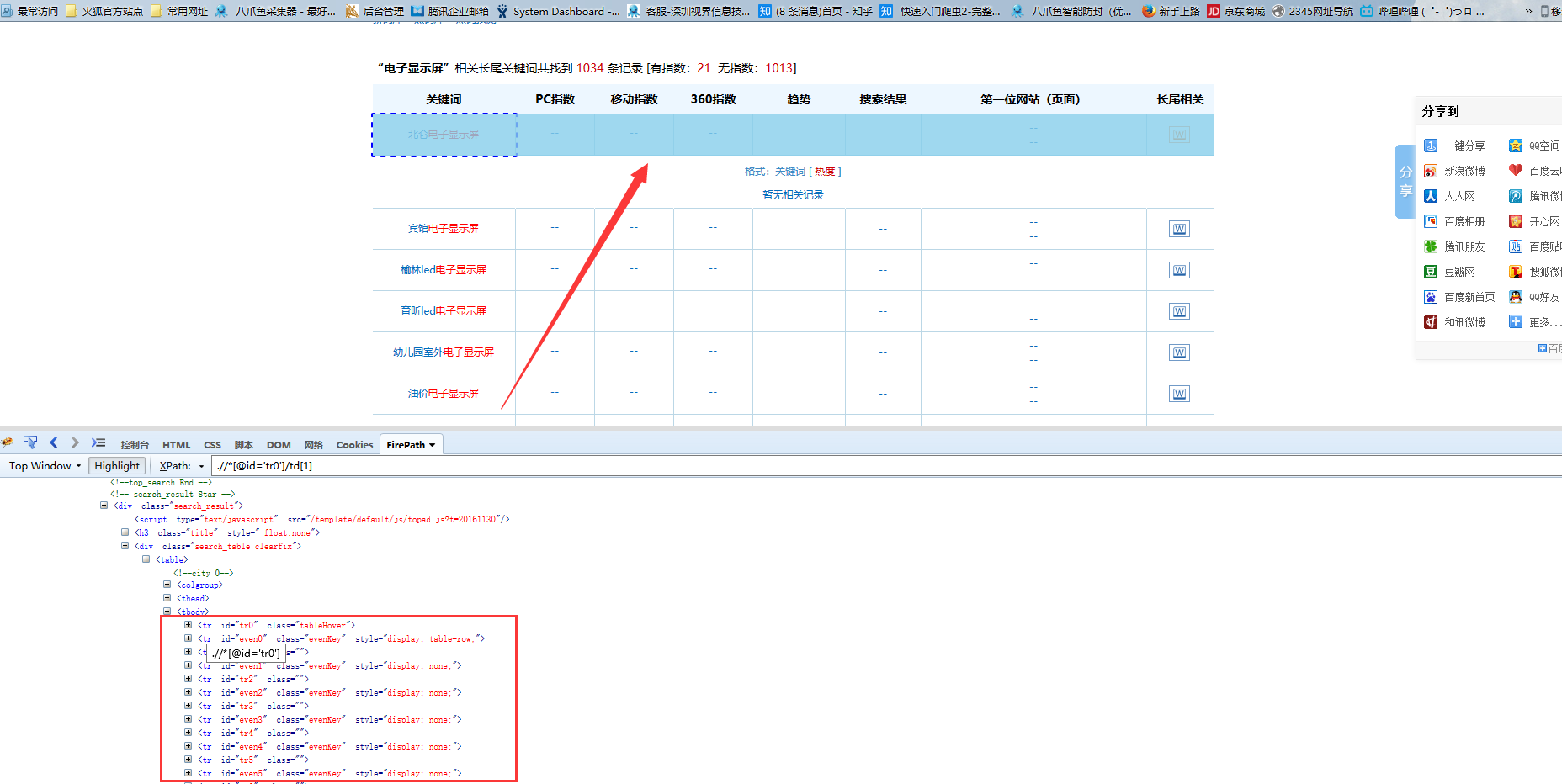
5)再观察每一行真正的tr节点里都有一个共同的属性“id”,并且id属性都有一个共同的tr值,所以我们以此为共同点,手写该xpath:.//tbody/tr[contains(@id,'tr')],来定位到所有的tr节点,并把所有无用的tr给过滤掉,这样,循环列表的xpath就创建好了

6)再从左侧拖一个循环进去,循环方式选择不固定元素,把该xpath放入八爪鱼里,并以第一个循环为例,设置相应的采集字段(由于部分字段源码里是没有的,所以采集不到)
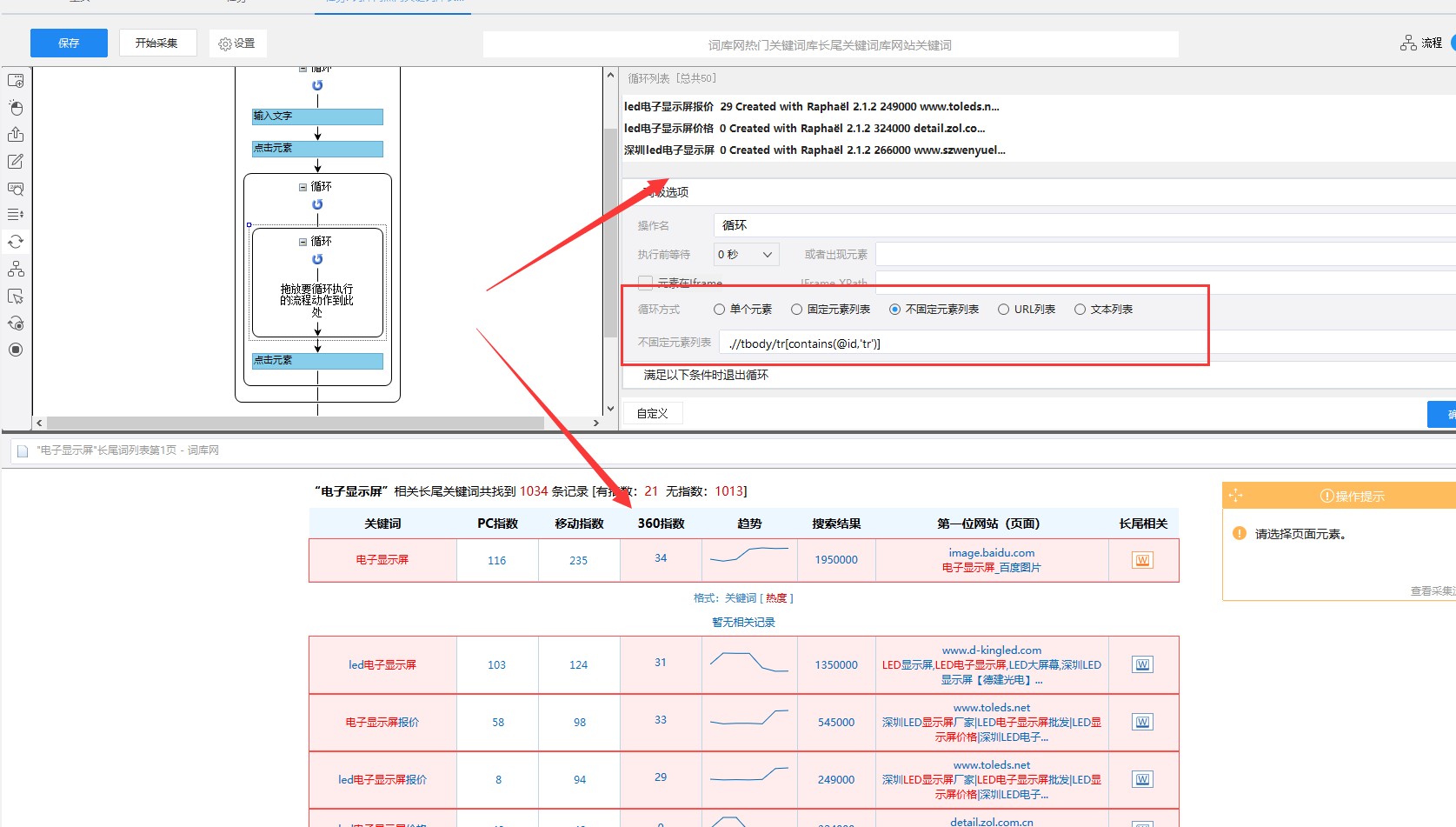
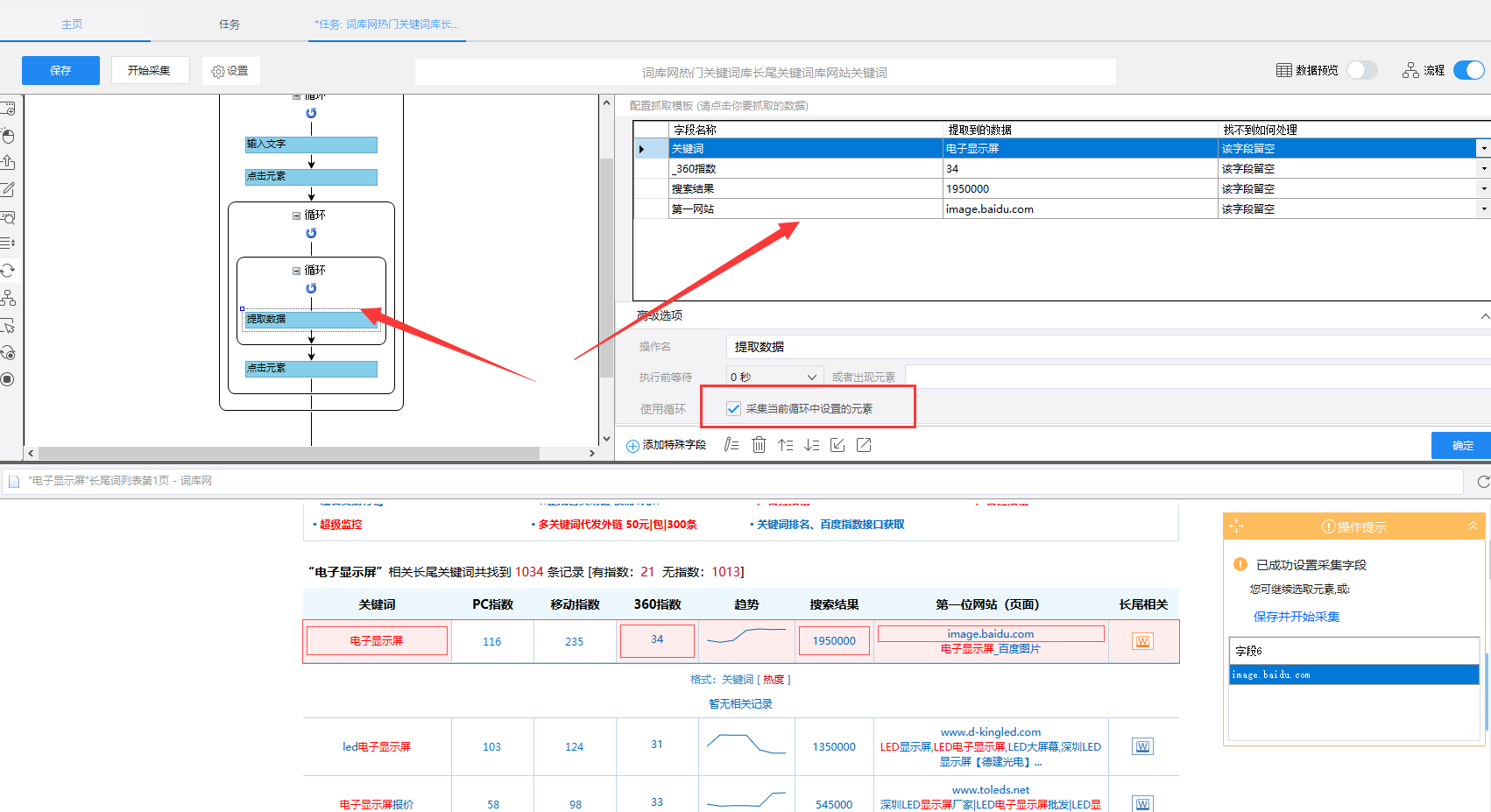
步骤5:启动采集
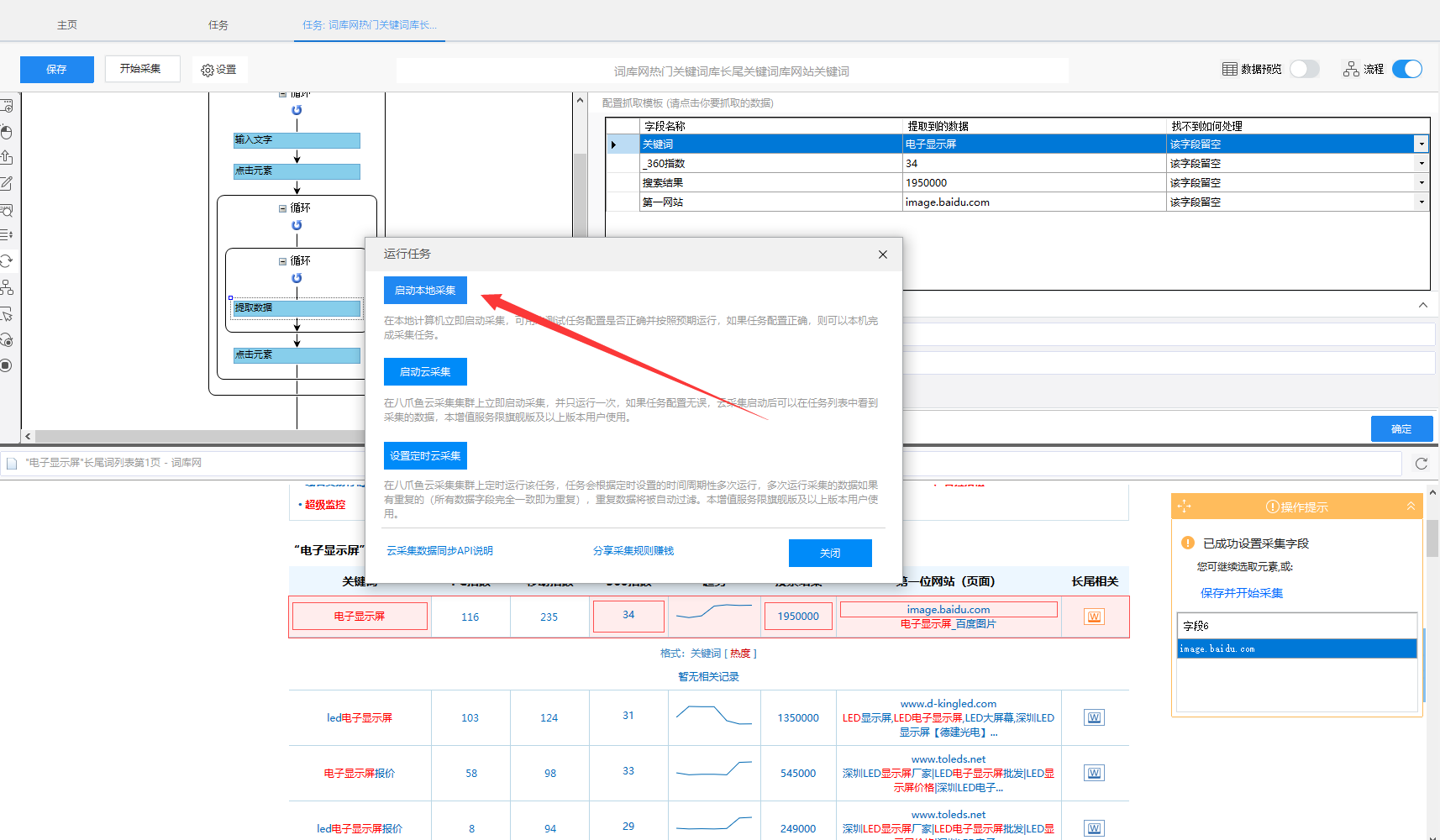
1)点击保存任务后,运行采集,以本地采集为例
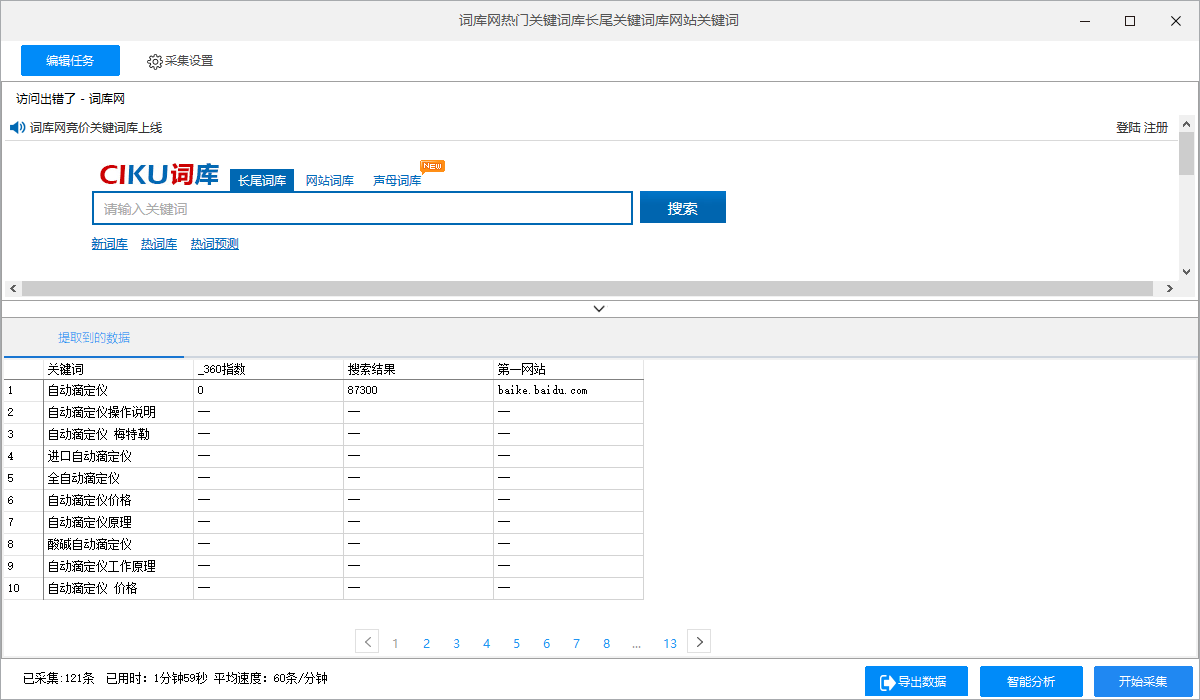
2)采集完成后,会跳出提示,选择“导出数据”。选择“合适的导出方式”,将采集好的数据导出。















 69
69











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









