






logical operation:基于微软查询处理概念模型的逻辑操作。例如,联接运算符的physical operation属性表示联接算法(nested loops,merge ,hash)物理运算符
logical operation属性表示逻辑联接类型(Inner join,outer join,semi join 等等)逻辑运算符
如果没有与该运算符关联的逻辑操作,则这项度量的值与physical operation相同
actual number of rows:从该运算符实际返回的行数(只显示在实际的计划中)
estimated I/O cost和estimated cpu cost:运算符在特定资源上的估计成本(I/O或CPU)这两个度量将帮助你确定运算符是否是I/O密集或CPU密集的
例如,你可以看到clustered index seek运算符主要与I/O有关,而hash match运算符主要与cpu有关
estimated operator cost:执行该操作的成本
estimated subtree cost:如前所述,他表示到当前节点为止整个子树的累积成本
estimated number of rows:该运算符预计的返回行数。在有些情况下,通过观察实际行数和估计行数之间的差异,你可以找出因统计信息不足或其他原因而导致的成本问题
estimated row size:你可能会奇怪为什么在实际的查询计划中没有显示该属性的实际值。因为你的表可能包含可变长度类型,表中行的大小各异
actual rebinds和actual rewinds:这两个度量仅与作为nested loops联接内侧的运算符有关,在其他运算符中,rebinds将显示为1,rewinds将显示为0
他们表示内部init方法被调用的次数。重新绑定次数和重绕次数之和等于联接外侧所处理的行数。重新绑定意味着联接的一个或多个参数发生更改后,必须重新计划
联接的内侧。重绕意味着任何相关参数都没有发生更改,可以重用之前的内侧结果集
信息提示框的底部显示该运算符的其他信息,如关联的对象名称、输出、参数等
http://www.cnblogs.com/lyhabc/articles/3912608.html
预估执行计划 VS 实际执行计划
有两种类型的执行计划:预估和实际。预估的执行计划是在执行之前由查询优化器计算;它表明优化器信任为最低消耗的执行计划。通常大约在几秒之内返回给用户。实际执行计划,另一方面,处理查询过程中实际执行的步骤。在查询完成后实际的计划被返回。有时,预估和实际的值会不同。在执行计划中值为定量数据。查看图1对于一些执行计划值的一个示例。
为什么预估和实际执行计划值不同?
有三个原因来解释为什么执行计划值不同。
1.预估执行计划不能被创建
在查询优化器对查询创建预估的执行计划之前,Algebrizer组件会验证查询。如果一个对象在查询中不存在,验证失败并且没有创建预估的执行计划。这种情况,当一个创建语句位于使用这个创建对象的相同批中。
2.陈旧的统计信息
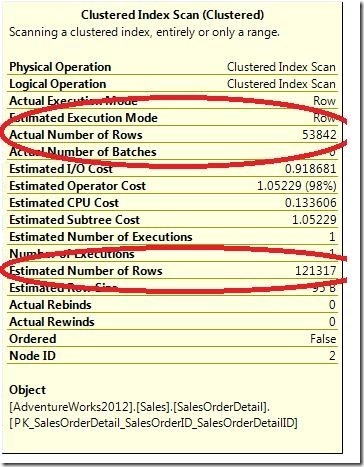
SQL Server对每个索引创建关于每个列值的分布的统计信息。当查询优化器预估从一个操作返回的行数的时候,使用该信息,并且完全使用一个特定索引的消耗来预估。当在表中数据改变时,这些统计信息过期。如果查询优化器使用坏的统计信息,它会错误的计算执行计划的消耗。通过比较预估行数和实际行数,你可以看到在实际执行计划中一个操作的差异(见图1)。图1中高亮显示的差异是对表执行一个删除操作产生的。
3.并行性
如果安装SQL Server的机器有多个CPU,查询优化器会完成两次寻找最低消耗执行计划的过程;创建一个执行计划使用一个处理器,第二个执行计划利用多个处理器(并行性)。直到执行时才会决定运行这两个执行计划中的哪个。当用户请求查看预估执行计划,只有一个执行计划被显示。这个执行计划可能是、也可能不是当执行查询时查询引擎所选择的那个。 (见下图) 图1 比较EstimatedNumber of Rows和Actual Number of Rows
哪个执行计划更好?
一个预估执行计划几乎立即被返回,而实际执行计划不能。实际的执行计划给出了一个更加完整的图片,但是在生产环境中,为了获得实际执行计划而等待一个长时间运行的语句执行完成是不切实际的。
只有在实际执行计划中找到的最频繁使用信息,是从每个操作返回的实际行数。实际行数可以与预估行数比较。如果差异巨大,那么统计信息很可能过时了。在这种情况下更新统计信息可能会提高查询性能(查看TechNet文章“统计信息”获得更多关于这个话题的信息)。
另一种获得实际行数的方式是,检查表的索引统计信息的最后时间已更新。将该信息与数据库的活动联系起来,将会表名统计信息的陈旧情况。以下查询运行在sys.indexes表返回已更新的统计信息的最后日期:
代码:
USE YourDatabase GO SELECT name AS index_name , STATS_DATE(OBJECT_ID, index_id) AS StatsUpdated FROM sys.indexes WHERE OBJECT_ID = OBJECT_ID('YourSchema.YourTable')
只在实际执行计划中找到的其他信息
Actual Rewinds和Rebinds的值只会应用到少数几个操作。这些值计数特定操作初始化的次数。大量的初始化可能导致高I/O使用。对于该话题更完整的涵盖,看看Grant Fritchey的书SQL Server执行计划。
除了Actual Rewinds和Rebinds,Number of Executions在SQL Server 2008中引入。该值是一个操作被执行次数的计数。对一些操作,执行次数和返回行数相关,预估和实际的执行次数会根据预估和实际行数的不同而不同。在某些情况下,SQL Server不能预估执行计数,将会在Estimated Number of Executions显示值为1。
预估的执行计划包含预估的消耗,逻辑上导致实际执行计划包含实际消耗。然而,情况并非如此。正如之前提到的,计数值只是表明一个操作时间消耗上的相对昂贵程度。它不与任何实际值如CPU和I/O时间相关。
2016-1-28 10:43
补充(1):
分析——》绑定——》优化
分析:检查,例如检查使用分隔标识符的表或列名称是否以数字开头,分析几乎是所有编程语言编译器的一项常规操作。
绑定:确定SQL语句所引用对象的特征检查请求语义是否有意义,例如检查From A join B的查询时,如果A是一个表B是一个存储过程,则绑定失败。
优化:类似于绑定,优化器一次只优化批处理中的一条语句,在编译器为该批处理生成执行计划并存储到plan cache之后将执行该计划的执行上下文(execute context)的特殊副本。sqlserver像缓存执行计划一样缓存执行上下文。sqlserver并不优化batch中的每条sql语句,他只优化那些访问表而且可能生成多个执行计划的语句,sqlserver优化所有的DML。只有被优化过的语句才会生成执行计划。
补充(2):
执行计划指标值
logical operation:基于微软查询处理概念模型的逻辑操作。例如,联接运算符的physical operation属性表示联接算法(nested loops,merge ,hash)物理运算符
logical operation属性表示逻辑联接类型(Inner join,outer join,semi join 等等)逻辑运算符
如果没有与该运算符关联的逻辑操作,则这项度量的值与physical operation相同
actual number of rows:从该运算符实际返回的行数(只显示在实际的计划中)
estimated I/O cost和estimated cpu cost:运算符在特定资源上的估计成本(I/O或CPU)这两个度量将帮助你确定运算符是否是I/O密集或CPU密集的
例如,你可以看到clustered index seek运算符主要与I/O有关,而hash match运算符主要与cpu有关
estimated operator cost:执行该操作的成本
estimated subtree cost:如前所述,他表示到当前节点为止整个子树的累积成本
estimated number of rows:该运算符预计的返回行数。在有些情况下,通过观察实际行数和估计行数之间的差异,你可以找出因统计信息不足或其他原因而导致的成本问题
estimated row size:你可能会奇怪为什么在实际的查询计划中没有显示该属性的实际值。因为你的表可能包含可变长度类型,表中行的大小各异
actual rebinds和actual rewinds:这两个度量仅与作为nested loops联接内侧的运算符有关,在其他运算符中,rebinds将显示为1,rewinds将显示为0
他们表示内部init方法被调用的次数。重新绑定次数和重绕次数之和等于联接外侧所处理的行数。重新绑定意味着联接的一个或多个参数发生更改后,必须重新计划
联接的内侧。重绕意味着任何相关参数都没有发生更改,可以重用之前的内侧结果集
















 830
830











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









