







前言:
我们学习一个算法总是要有个指标或者多个指标来衡量一下算的好不好,不同的机器学习问题就有了不同的努力目标,今天我们就来聊一聊回归意义下的损失函数、正则化的前世今生,从哪里来,到哪里去。
一.L1、L2下的Lasso Regression和Ridge Regression
对于机器学习,谈到正则化,首先映入脑子的可能是L1正则化、L2正则化,接着又跑出来Lasso Regression、Ridge Regression,那么恭喜你,你已经走在了机器学习、人工智能的康庄大道上了,至少短期来看这条路还是不错滴。
下面我们就正式开聊,小板凳走起。
介于大家可能对L1、L2比较熟悉,我们就先从L1、L2这种特殊的正则化聊到他们的原始样貌,知道她从哪里来要到哪里去,走一条从特殊到一般的路,一条更加广阔看的更远的路。
But不同的方向,不同的学科领域对一些相同的知识点有着不同的爱称,为了交流方便,在这里简单啰嗦一下,L1、L2这种在机器学习方面叫做正则化,统计学领域的人喊她惩罚项,数学界会喊她范数。整体来说本质不变,源于数学。
L1使用的是绝对值距离,也叫做街区(City-Block)距离(曼哈顿距离),L2使用的是平方距离,也叫做欧式(Euclidean)距离。当盐啦,还有切比雪夫距离等等。
注意:敲黑板,不管是绝对值还是平方还是切比雪夫距离都是明氏距离(明考夫斯基距离)的特殊形式额已,大家感兴趣的自己查一下,不继续往下展开了,下一次可以具体写一写更多的别样式的距离。好像跑偏了,赶紧转回来。
耳熟能详的Lasso Regresssion是线性回归的一种,下面看看Lasso的简介:
Lasso是由1996年Robert Tibshirani首次提出,全称Least absolute shrinkage and selection operator。该方法是一种压缩估计。它通过构造一个罚函数得到一个较为精炼的模型,使得它压缩一些系数,同时设定一些系数为零。因此保留了子集收缩的优点,是一种处理具有复共线性数据的有偏估计。
Lasso Regresssion使用的就是L1正则化, 下面就是Lasso Regression 的Loss Function的样子,是不是很美丽:
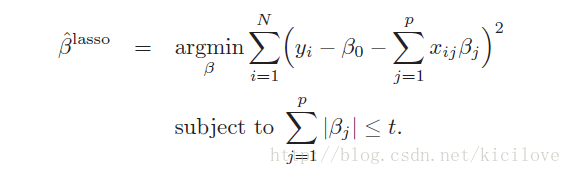
简单说一下,第一个SUM(∑)里面可以看出来是一个线性回归求损失平方,第二个SUM(∑)是线性回归中系数的服从条件,用来约束解的区域,凸优化中的约束求解一般都长这个样子。
此外,Lasso Regression的整体损失求极小的样子改成拉格朗日形式就是下面这个式子的模样:
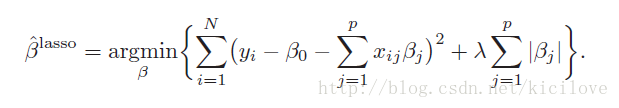
是不是找到了数学分析或者高等数学的感觉啦! 从式子里可以看到回归系数使用的是L1正则化,λ是惩罚参数或者叫做调节参数。L1范数的好处是当惩罚参数充分大时可以把某些待估的回归系数精确地收缩到0。
趁热打铁,我们再来看看Ridge Regression,也是线性回归的一个,看看简介:
RidgeRegression是一种专用于共线性的回归方法,对病态数据的拟合要强于最小二乘法(有想了解共线性问题,最小二乘的同学可以自己查资料了,如果对矩阵运算和矩阵性质熟悉的话会容易理解)。
岭回归使用的是L2正则化,下面的式子就是Ridge Regression的Loss Function 的美丽容颜:
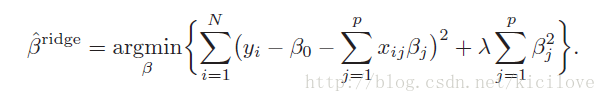
细心的同学眼睛已然盯上了式子的最后面,是不是传说中的L2正则项,系数的平方和。
上式的等价问题如下:
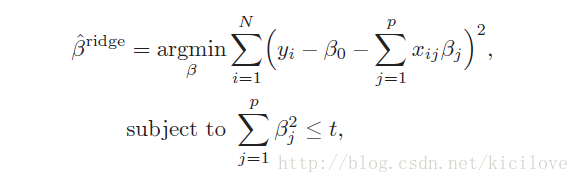
不管是Lasso Regression还是Ridge Regression 都有一个共同的参数,那就是惩罚参数λ,那么λ怎么来确定呢?
通常使用交叉验证法(CV)或者广义交叉验证(GCV),当然也可以使用AIC、BIC等指标。
我们学习Lasso Regression 或者Ridge Regression的时候,一定见过下面这张图:

下面从自己理解的角度和大家分享一下。
上面的图中实心的黑点也就是 β^是真实的损失函数(不带有正则项的部分)我们暂叫做原问题的最优解,然后红色的圈圈就是系数β1、β2在原问题下可能的解的范围,接着是蓝色的实心圈是正则项约束的可能的解的范围。我们都知道如果两个函数要是有共同的解,那么在几何意义下或者说从几何图形上来看,这两个函数的图像所在范围是要有共同交点或者要有交集。所以,由于Lasso Regression或者Ridge Regression的整个Loss Function也就是我们的目标函数是由原问题和正则项两部分构成的,那么如果这个目标函数要有解并且是最小解的话,原问题和正则项就要有一个切点,这个切点就是原问题和正则项都满足各自解所在范围下的共同的解,红圈圈从图中的实心黑点也就是原问题最优解出发不断往外变化与蓝色实心圈相切的时候,L1范数意义下可能得到有的维度上的系数为零(就是切点所在的坐标处,β1坐标为0),这也就是为什么说L1可以导致稀疏解,同理L2范数意义下,相切的点就不在坐标轴上,β1和β2都取0。
也许你已经发现,其实说L1范数下可以导致稀疏并不是说L1范数下一定导致稀疏,这还得看原问题的最优解到底在哪个地方取值。
二.Lq下的目标函数
其实看到这里你可能会问,既然有L1、L2会不会有Lq呢?答案是肯定的,有!
直接上图

上图中,可以明显看到一个趋势,即q越小,曲线越贴近坐标轴,q越大,曲线越远离坐标轴,并且棱角越明显。那么 q=0 和 q=oo 时极限情况如何呢?猜猜看。
聪明的你猜对了吧,答案就是十字架和正方形。
也许你又开始有问题了,既然L0是十字架,为什么不用L0作为正则项?
从理论来说,L0确实是求稀疏解的最好的正则项,但是机器学习中特征的维度往往很大,你也可以理解为系数很多很多,然后解L0又是个NP-hard问题,因此在实际工程应用中极有限制,不可行。
也许你又有问题了,为啥我们非得得到稀疏解呢?
其实这个问题并不绝对。从统计上来说,稀疏解可以舒缓模型的过拟合问题,毕竟可以使模型复杂度降低了嘛,然后你从一些应用场景上来说,比如医生看病,你一下让他看几百几千。。。个指标得出正确答案简单,还是就几个关键指标就可以正确断诊来的好。毕竟解决问题还是要先抓住主要矛盾的,对不。
在统计学中,相比较于L1、L2这种特殊意义下的Lasso Regression 、Ridge Regression,更普遍意义Lq范数下的关于求系数的目标Loss Function为如下形式:

从上式可以看到最后面关于系数的约束就变成了Lq范数。
这个时候你就可以探索一下原问题在q取不同的值得情况对应的Lq 为惩罚项组合而成的目标函数得到的问题的解有什么不同!!!
三、普遍意义下的目标函数
除了上面提到的不管是线性回归问题常用的最小二乘法的平方损失函数,还是加入了L1、L2正则项等问题的目标函数,还有很多很多的以损失函数为目标函数的种类,譬如说,Logistics Regression使用的Log对数损失函数、SVM 使用的Hinge损失函数、Adaboost使用的指数损失函数、0-1损失函数绝对值损失函数等等。
整体来说我们已经完成了要讲的内容,但是作为“吾将上下而求索”的新青年,还是想知道这些目标函数的祖宗到底是谁?想看一看我们的目标损失函数从何而来,当当当当,下面的式子就揭晓了答案:

上式中的L一长串表示的是一般原问题的的损失函数,后面的J表示的是由于想到的某些解的特殊性或者说由于条件限制而加入原问题损失函数的一个规范项,一个约束。
从这个式子来说,不管是线性回归问题,还是我们讲的L1、L2、Lq等问题都只是她的多少代徒子徒孙而已。
总结:本文我们从Lasso Regression、Ridge Regression为切入点引入了L1、L2范数,并且讲了L1、L2在Lasso Regression、Ridge Regression上为什么表现不同,L1为什么可以引起稀疏,哪些情况需要稀疏,接着引入了泛化的Lq范数,并且指出为啥不能用L0范数,最后给出了损失函数和正则化的最一般问题的来源,扒拉了下其他算法使用的目标函数的宗源。
有讲的不妥的地方还望各位客官指正。
更多信息请移步:
github:https://github.com/zhaohuicici?tab=repositories
在机器学习的概念中,我们经常听到L0,L1,L2正则化,本文对这几种正则化做简单总结。
1、概念
L0正则化的值是模型参数中非零参数的个数。
L1正则化表示各个参数绝对值之和。
L2正则化标识各个参数的平方的和的开方值。
2、先讨论几个问题:
1)实现参数的稀疏有什么好处吗?
一个好处是可以简化模型,避免过拟合。因为一个模型中真正重要的参数可能并不多,如果考虑所有的参数起作用,那么可以对训练数据可以预测的很好,但是对测试数据就只能呵呵了。另一个好处是参数变少可以使整个模型获得更好的可解释性。
2)参数值越小代表模型越简单吗?
是的。为什么参数越小,说明模型越简单呢,这是因为越复杂的模型,越是会尝试对所有的样本进行拟合,甚至包括一些异常样本点,这就容易造成在较小的区间里预测值产生较大的波动,这种较大的波动也反映了在这个区间里的导数很大,而只有较大的参数值才能产生较大的导数。因此复杂的模型,其参数值会比较大。
3、L0正则化
根据上面的讨论,稀疏的参数可以防止过拟合,因此用L0范数(非零参数的个数)来做正则化项是可以防止过拟合的。
从直观上看,利用非零参数的个数,可以很好的来选择特征,实现特征稀疏的效果,具体操作时选择参数非零的特征即可。但因为L0正则化很难求解,是个NP难问题,因此一般采用L1正则化。L1正则化是L0正则化的最优凸近似,比L0容易求解,并且也可以实现稀疏的效果。
4、L1正则化
L1正则化在实际中往往替代L0正则化,来防止过拟合。在江湖中也人称Lasso。
L1正则化之所以可以防止过拟合,是因为L1范数就是各个参数的绝对值相加得到的,我们前面讨论了,参数值大小和模型复杂度是成正比的。因此复杂的模型,其L1范数就大,最终导致损失函数就大,说明这个模型就不够好。
5、L2正则化
L2正则化可以防止过拟合的原因和L1正则化一样,只是形式不太一样。
L2范数是各参数的平方和再求平方根,我们让L2范数的正则项最小,可以使W的每个元素都很小,都接近于0。但与L1范数不一样的是,它不会是每个元素为0,而只是接近于0。越小的参数说明模型越简单,越简单的模型越不容易产生过拟合现象。
L2正则化江湖人称Ridge,也称“岭回归”
6、Lasso和Ridge对比
Lasso和Ridge可以分别表示为:
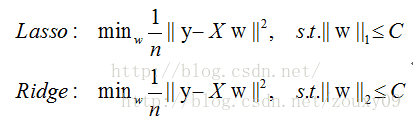
我们考虑两维的情况,在(w1, w2)平面上可以画出目标函数的等高线,而约束条件则成为平面上半径为C的一个 norm ball 。等高线与 norm ball 首次相交的地方就是最优解:
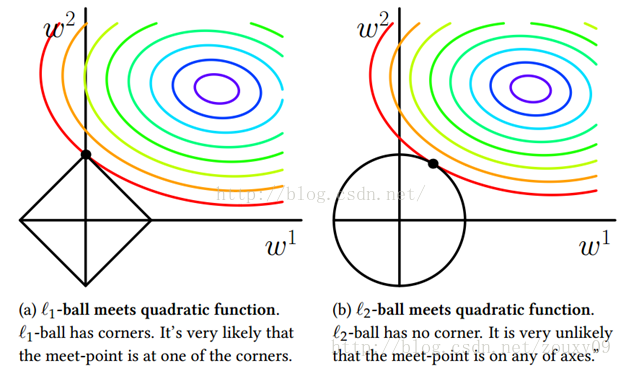
可以看到,L1-ball 与L2-ball 的不同就在于L1在和每个坐标轴相交的地方都有“角”出现,有很大的几率等高线会和L1-ball在四个角,也就是坐标轴上相遇,坐标轴上就可以产生稀疏,因为某一维可以表示为0。而等高线与L2-ball在坐标轴上相遇的概率就比较小了。
总结:L1会趋向于产生少量的特征,而其他的特征都是0,而L2会选择更多的特征,这些特征都会接近于0。Lasso在特征选择时候非常有用,而Ridge就只是一种规则化而已。在所有特征中只有少数特征起重要作用的情况下,选择Lasso比较合适,因为它能自动选择特征。而如果所有特征中,大部分特征都能起作用,而且起的作用很平均,那么使用Ridge也许更合适。
Reference:
正则化(Regularization)
机器学习中几乎都可以看到损失函数后面会添加一个额外项,常用的额外项一般有两种,一般英文称作ℓ1-norm和ℓ2-norm,中文称作L1正则化和L2正则化,或者L1范数和L2范数。
L1正则化和L2正则化可以看做是损失函数的惩罚项。所谓『惩罚』是指对损失函数中的某些参数做一些限制。对于线性回归模型,使用L1正则化的模型建叫做Lasso回归,使用L2正则化的模型叫做Ridge回归(岭回归)。下图是Python中Lasso回归的损失函数,式中加号后面一项α||w||1即为L1正则化项。
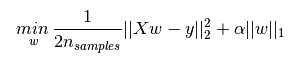
下图是Python中Ridge回归的损失函数,式中加号后面一项α||w||22即为L2正则化项。
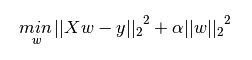
一般回归分析中回归w表示特征的系数,从上式可以看到正则化项是对系数做了处理(限制)。L1正则化和L2正则化的说明如下:
- L1正则化是指权值向量w中各个元素的绝对值之和,通常表示为||w||1
- L2正则化是指权值向量w中各个元素的平方和然后再求平方根(可以看到Ridge回归的L2正则化项有平方符号),通常表示为||w||2
一般都会在正则化项之前添加一个系数,Python中用α表示,一些文章也用λ表示。这个系数需要用户指定。
那添加L1和L2正则化有什么用?下面是L1正则化和L2正则化的作用,这些表述可以在很多文章中找到。
- L1正则化可以产生稀疏权值矩阵,即产生一个稀疏模型,可以用于特征选择
- L2正则化可以防止模型过拟合(overfitting);一定程度上,L1也可以防止过拟合
稀疏模型与特征选择
上面提到L1正则化有助于生成一个稀疏权值矩阵,进而可以用于特征选择。为什么要生成一个稀疏矩阵?
稀疏矩阵指的是很多元素为0,只有少数元素是非零值的矩阵,即得到的线性回归模型的大部分系数都是0. 通常机器学习中特征数量很多,例如文本处理时,如果将一个词组(term)作为一个特征,那么特征数量会达到上万个(bigram)。在预测或分类时,那么多特征显然难以选择,但是如果代入这些特征得到的模型是一个稀疏模型,表示只有少数特征对这个模型有贡献,绝大部分特征是没有贡献的,或者贡献微小(因为它们前面的系数是0或者是很小的值,即使去掉对模型也没有什么影响),此时我们就可以只关注系数是非零值的特征。这就是稀疏模型与特征选择的关系。
L1和L2正则化的直观理解
这部分内容将解释为什么L1正则化可以产生稀疏模型(L1是怎么让系数等于零的),以及为什么L2正则化可以防止过拟合。
L1正则化和特征选择
假设有如下带L1正则化的损失函数:
J=J0+α∑w|w|(1)
其中J0是原始的损失函数,加号后面的一项是L1正则化项,α是正则化系数。注意到L1正则化是权值的绝对值之和,J是带有绝对值符号的函数,因此J是不完全可微的。机器学习的任务就是要通过一些方法(比如梯度下降)求出损失函数的最小值。当我们在原始损失函数J0后添加L1正则化项时,相当于对J0做了一个约束。令L=α∑w|w|,则J=J0+L,此时我们的任务变成在L约束下求出J0取最小值的解。考虑二维的情况,即只有两个权值w1和w2,此时L=|w1|+|w2|对于梯度下降法,求解J0的过程可以画出等值线,同时L1正则化的函数L也可以在w1w2的二维平面上画出来。如下图:
图1 L1正则化
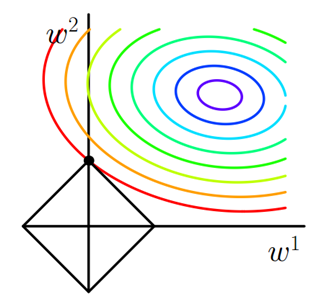
图中等值线是J0的等值线,黑色方形是L函数的图形。在图中,当J0等值线与L图形首次相交的地方就是最优解。上图中J0与L在L的一个顶点处相交,这个顶点就是最优解。注意到这个顶点的值是(w1,w2)=(0,w)。可以直观想象,因为L函数有很多『突出的角』(二维情况下四个,多维情况下更多),J0与这些角接触的机率会远大于与L其它部位接触的机率,而在这些角上,会有很多权值等于0,这就是为什么L1正则化可以产生稀疏模型,进而可以用于特征选择。
而正则化前面的系数α,可以控制L图形的大小。α越小,L的图形越大(上图中的黑色方框);α越大,L的图形就越小,可以小到黑色方框只超出原点范围一点点,这是最优点的值(w1,w2)=(0,w)中的w可以取到很小的值。
类似,假设有如下带L2正则化的损失函数:
J=J0+α∑ww2(2)
同样可以画出他们在二维平面上的图形,如下:
图2 L2正则化
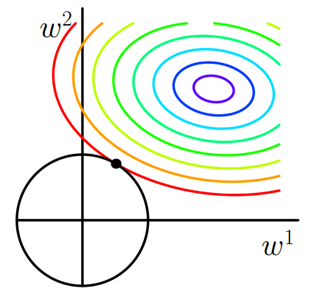
二维平面下L2正则化的函数图形是个圆,与方形相比,被磨去了棱角。因此J0与L相交时使得w1或w2等于零的机率小了许多,这就是为什么L2正则化不具有稀疏性的原因。
L2正则化和过拟合
拟合过程中通常都倾向于让权值尽可能小,最后构造一个所有参数都比较小的模型。因为一般认为参数值小的模型比较简单,能适应不同的数据集,也在一定程度上避免了过拟合现象。可以设想一下对于一个线性回归方程,若参数很大,那么只要数据偏移一点点,就会对结果造成很大的影响;但如果参数足够小,数据偏移得多一点也不会对结果造成什么影响,专业一点的说法是『抗扰动能力强』。
那为什么L2正则化可以获得值很小的参数?
以线性回归中的梯度下降法为例。假设要求的参数为θ,hθ(x)是我们的假设函数,那么线性回归的代价函数如下:
J(θ)=12m∑i=1m(hθ(x(i))−y(i))(3)
那么在梯度下降法中,最终用于迭代计算参数θ的迭代式为:
θj:=θj−α1m∑i=1m(hθ(x(i))−y(i))x(i)j(4)
其中 α是learning rate. 上式是没有添加L2正则化项的迭代公式,如果在原始代价函数之后添加L2正则化,则迭代公式会变成下面的样子:
θj:=θj(1−αλm)−α1m∑i=1m(hθ(x(i))−y(i))x(i)j(5)
其中 λ就是正则化参数。从上式可以看到,与未添加L2正则化的迭代公式相比,每一次迭代, θ j都要先乘以一个小于1的因子,从而使得 θ j不断减小,因此总得来看, θ是不断减小的。
最开始也提到L1正则化一定程度上也可以防止过拟合。之前做了解释,当L1的正则化系数很小时,得到的最优解会很小,可以达到和L2正则化类似的效果。
正则化参数的选择
L1正则化参数
通常越大的λ可以让代价函数在参数为0时取到最小值。下面是一个简单的例子,这个例子来自Quora上的问答。为了方便叙述,一些符号跟这篇帖子的符号保持一致。
假设有如下带L1正则化项的代价函数:
F(x)=f(x)+λ||x||1
其中x是要估计的参数,相当于上文中提到的w以及θ. 注意到L1正则化在某些位置是不可导的,当λ足够大时可以使得F(x)在x=0时取到最小值。如下图:
图3 L1正则化参数的选择
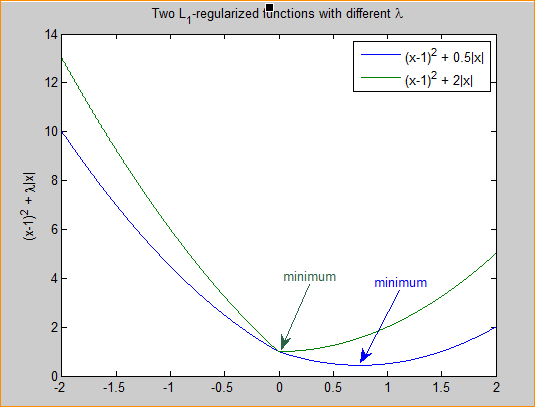
分别取λ=0.5和λ=2,可以看到越大的λ越容易使F(x)在x=0时取到最小值。
L2正则化参数
从公式5可以看到,λ越大,θj衰减得越快。另一个理解可以参考图2,λ越大,L2圆的半径越小,最后求得代价函数最值时各参数也会变得很小。
Reference
过拟合的解释:
https://hit-scir.gitbooks.io/neural-networks-and-deep-learning-zh_cn/content/chap3/c3s5ss2.html
正则化的解释:
https://hit-scir.gitbooks.io/neural-networks-and-deep-learning-zh_cn/content/chap3/c3s5ss1.html
正则化的解释:
http://blog.csdn.net/u012162613/article/details/44261657
正则化的数学解释(一些图来源于这里):
http://blog.csdn.net/zouxy09/article/details/24971995
















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









