







hdfs优点:
- -高容错性:多副本;副本丢失后可以自动恢复
- -适合批处理:移动计算而非数据;数据位置暴露给计算框架
- -适合大数据库处理:TB,PB量级数据处理;百万级以上的文件数量处理;10K+节点
- -可架构在廉价机器上:通过多副本提高可靠性;提供容错和恢复机制
缺点:
- -低延迟数据访问:毫秒级数据访问;低延迟与高吞吐率不适合
- -小文件存储:占用namenode大量内存,所有的元数据都放在namenode节点,这些数据都是加载到内存维护的;寻道时间超过读取时间
- -并发写入,文件随机修改:一个文件只能有一个写入;
- 仅支持append操作。
用户任何的操作都是直接访问namenode,namenode把请求的数据地址暴露给用户,用户去访问datanode.
hdfs存储范围(block):
- -文件被切分成固定大小的块,块大小可以配置,默认大小是64MB;如果文件大小不够64MB,也会占用一个block。
- -默认情况下每个block有3个副本,可配置。文件创建成功之后不可修改。当一个block数小于系统设置的副本数,那么系统会自动创建一个副本。
namenode(NN):
主要功能:
- 接受客户端读写服务;
- 保存元数据信息(文件名,文件属主和权限;文件包含块信息;block存放那个datanode由datanode启动时上报给namenode) namenode的元数据在集群启动时会全部加载到内存。
元数据还会存储到磁盘的文件名fsimage,block的位置不会保存到fsimage,为了提高速度 block位置信息不会保存到fsimage,block位置会一直在内存中加载读取。 如果修改一条数据,hdfs并不会马上修改fsimage,而是先记录到metadata操作日志,等到满足条件会写到fsimage中。我们可以这么理解,fsimage是对元数据的定期全备,edits是对元数据的实时记录,是对源数据库的增量备份,全备加上增量备份就是元数据的完整备份。
SecondarynameNode(SNN):
它不是nn的备份,只是nn的一部分数据备份。当然也可以作为备份,它的主要功能是协助nn合并editslog,减少nn启动时间。fsimage在跟edits合并的时候会删除,这个时候会有大量的IO操作,这个时候snn会协助nn完整这个动作。合并完成之后在snn上会生成一个新的fsimage,然后推送给nn. 以上动作会周而复始的进行。
snn合并时机:
- 根据配置文件定义的时间fs.checkpoint.period默认3600秒;
- 根据配置文件定义的的edits大小 fs.checkpoint.size规定edits的大小,默认64MB.
总结一下 edits和fsimage合并的流程:
1.在nn中存在edits文件和fsimage文件;
2.在满足合并时间(3600s)或者大小(64MB)的时候,会把edits文件和fsimage文件传送到snn,这个时候nn上的用户的操作会生成一个新的edits文件来记录操作,
3.接下来由snn协助完成edit和fsimage的合并操作,生成新的fsimage文件,
4.然后snn把新的fsimage文件推送给nn,替换nn的fsimage文件,等到下一次合并的时候还会做以上流程,,,,。
DataNode数据节点(DN):
DN在启动的时候会向NN汇报block信息; 通过主动向nn发送心跳保持一致(3s),如果NN 10分钟没有收到DN心跳信息,则认为其已经丢失,并拷贝其block到其他DN.
Block副本放置策略:
- 第一个副本 放置在上传文件的DN,如果是集群外提交则随意挑选一台磁盘空闲,cpu空闲的节点放置
- 第二个副本 放置在跟第一个副本不同机架的节点 -第三个副本 与第二个副本相同机架的节点 -更多副本 随机节点
读流程:
- 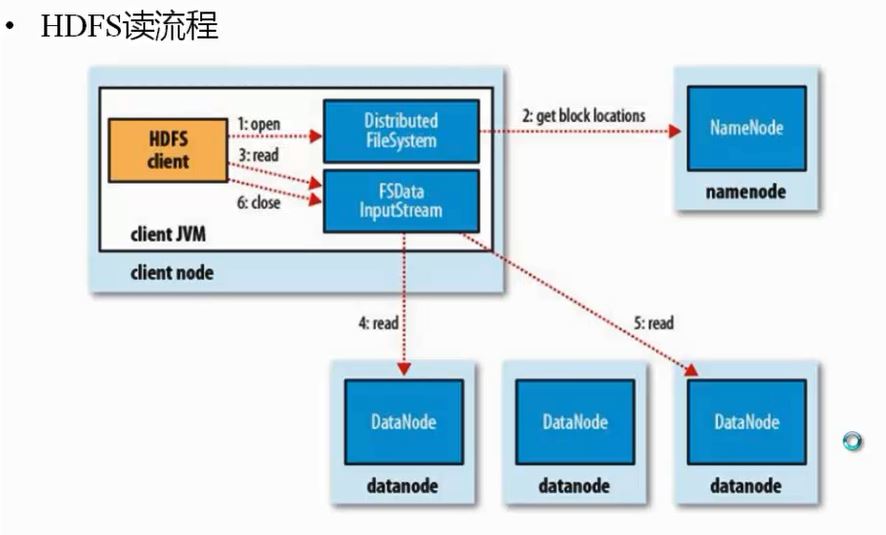
- 客户端打开dfs文件系统,读取nn节点得到block位置,然后返回给客户端;
- 客户端根据返回的block地址,通过inputStream 输入流并发去dn节点读取快数据(只读取其中一个副本就可以), 返回给客户端关闭输入流。
写流程:
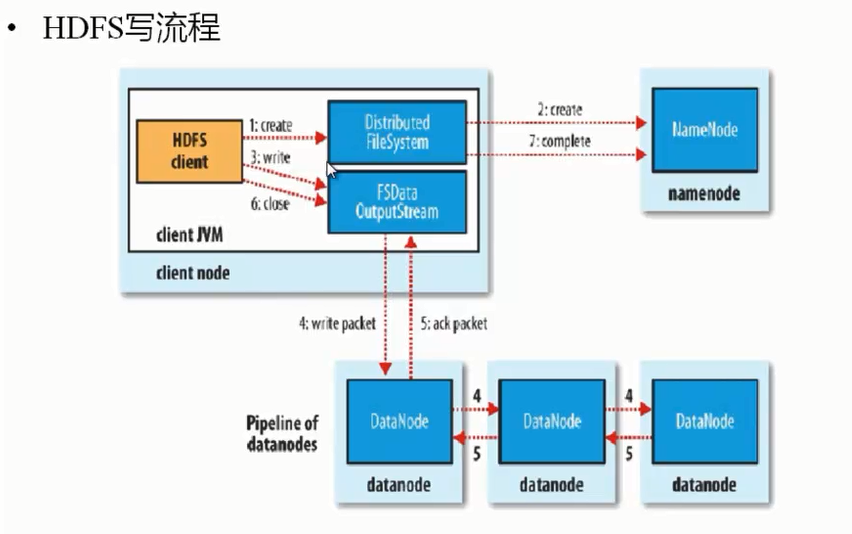
- 客户端调用dfs.create方法在nn创建元数据(文件名,属主,属组,大小,读写权限等),根据文件大小计算需要几个block,并为这几个block分配需要写到dn节点地址 返回给客户端。
- 然后由客户端 调用FSDataoutputStream.write方法去写数据,通过write packet方式去写往DN节点写一份数据,由DN节点根据副本放置规则去完成副本的拷贝,拷贝完成后返回给客户端一个ack packet信息,然后向NN节点汇报写操作完成信息。最终客户端关闭写入流。
注意:客户端有可能在远程,所以副本的拷贝由DN来完成,拷贝原则就近原则,这样可以极大提高速度。
hdfs 文件权限:
- 与linux权限类似,rwx -owner 即是文件所有者也就是文件创建者
- hdfs 不区分普通用户和超级用户,不做身份验证。
hadoop安全模式:
- nn启动时候,首先将fsimage载入内存,并执行编辑日志edits中的各项操作
- 当文件元数据到DN的映射关系建立之后,则会创建一个新的fsimage的文件和一个空的edits日志。
- nn运行在安全模式,这个时候文件系统对于客户端来说是只读的,写 删除 重命名操作都会失败
- 在此阶段,NN会收集各个DN的block 报告,当数据块达到最小副本数以上时,被认为是“安全的”,在一定比例的数据块被认为是安全之后,安全模式结束;当检查副本数小于最小副本数的时候,该块会被复制达到最小副本数。系统中的数据块位置不是由NN维护,而是以列表的形式存储在DN中。
hdfs安装:
-
伪分布安装
core.site.xml 定义nn主机和端口
<configuration>
<property>
<name>fs.defaultFS</name>
<value>hdfs://localhost:9000</value>
</property>
</configuration>hdfs.site.xml 定义datanode副本数
<configuration>
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
</configuration>注意:伪分布副本数不能大于datanode节点数,dfs.replication 默认为3,所以在部署伪分布模式的时候需要修改hdfs.site.xml副本数量。
slave 定义datanode主机;
-
分布式安装:
1. 安装jdk
注意:JAVA_HOME 环境变量需要配置,需要在hadoop/conf/hadoop-env.sh 配置JAVA_HOME
2.配置ssh免密登录
由于各个DN之间的副本需要拷贝,所以需要配置各个DN之间的免密登录;nn节点需要跟各个sn,dn之间同步心跳和fsimage,edits,所以集群内的所有节点需要配置免密登录。还有一个好处是在任意一个节点执行start-all.sh 其余的节点都能启动。
私钥是自己使用的凭证,公钥是提供给访问者的钥匙,只有访问者的钥匙匹配凭证才能免密访问。
3. 修改主机名,配置/etc/hosts 文件
4. 修改core-site.xml,hdfs-site.xml,修改masters和slave文件,格式化namenode。
HDFS 2.X :
解决了1.X中的单点故障和内存受限的问题。
- 解决单点故障:HDFS HA,一主多备NN来解决;
- 如果主NN发生故障,则切换到备NN。
解决内存受限问题。
- hdfs Federation(hdfs联邦,意思是把元数据分成独立的多份)
- 水平扩展,支持多个NN
- 每个NN分管一部分目录
- 所有NN共享所有NN存储资源
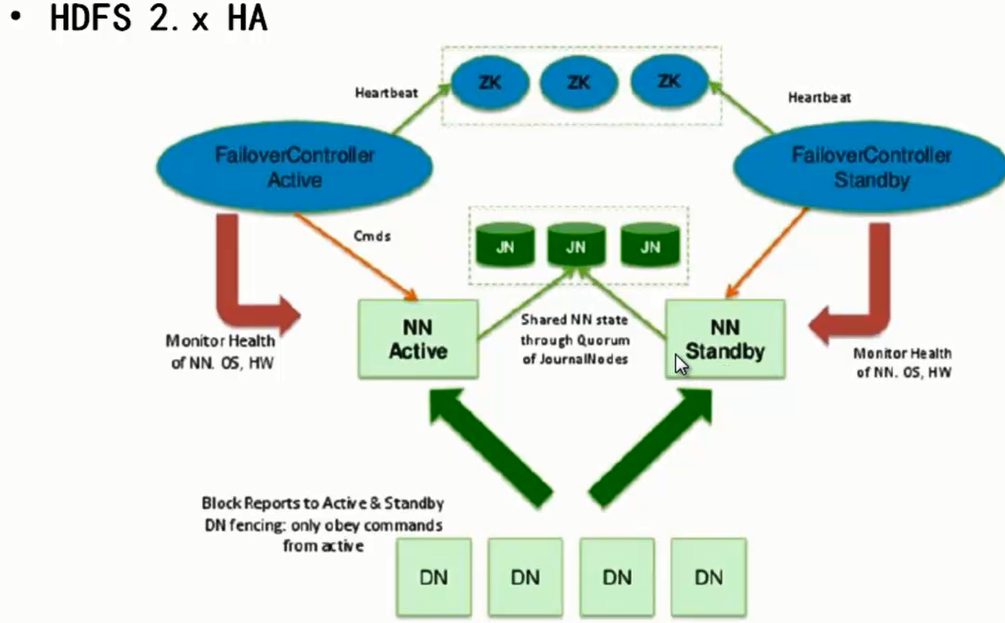
HDFS 2.X HA(ZKFC):
DN在启动的时候会把自己的block位置上报给NN,在HA架构下 DN会向所有的NN汇报信息,包括主备NN,有可能是一主多备。
NN元数据在这HA架构下存放到JN(JournaINodes) ,不管主备NN只要对元数据操作都会写到JN(Quorum Journal Manager http://hadoop.apache.org/docs/stable/hadoop-project-dist/hadoop-hdfs/HDFSHighAvailabilityWithQJM.html)里面,fsimage和edits则不会存放到NN本地了。
zooneKeeper针对所有的NN同步心跳和控制NN切换。任意一个NN不管是主还是备都对应一个failover controller。
总结:主NN对外提供服务,备NN同步主NN元数据,以待切换;所有DN在启的时候会向所有NN(包括主备NN)汇报block位置信息。
通过zookeeper实现自动切换NN,|Controller监控NN健康状态,并向zookeeper注册NN;当NN挂掉之后,ZKFC(zookeeperFailoverController)为NN竞争锁,获得锁之后的NN为Active状态。
yarn(Yet Another Resource Negotiator):资源管理利器
yarn的引入,使得多个计算框架可运行在一个集群中。每个应用程序对应一个applicationMaster。目前多个计算框架可以运行在yarn上。
基本功能:
- yarn 负责资源管理和调度;
- mrappmaster 负责任务切分,调度,监控和容错;
- maptask/reduceTask 任务驱动;
每一个mapreduce作业对应一个MRAppMaster:
- MRAppMaster负责作业调度,yarn将资源分配给MRAppMaster,MRAppMaster将资源分配给内部任务。
MRAppMaster容错 :
- 失败后由yarn重新启动;
- 任务失败后,MRAppMaster重新申请资源
HA 部署:
overview:
zkfc是针对NN做HA,至少需要2个实例,NN至少需要2个实例,DN 部署3个实例,JN需要3个实例,ZK 3个实例(官方推荐奇数个实例,投票机制)
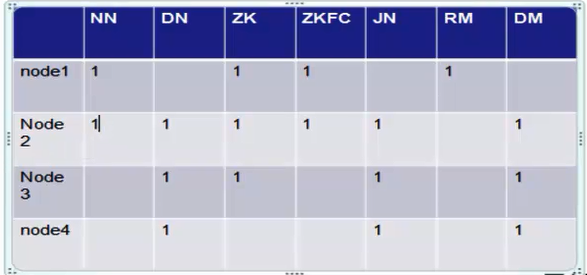
参考 http://hadoop.apache.org/docs/r2.7.1/hadoop-project-dist/hadoop-hdfs/HDFSHighAvailabilityWithQJM.html部署
Hardware resources:
NameNode machines - the machines on which you run the Active and Standby NameNodes should have equivalent hardware to each other, and equivalent hardware to what would be used in a non-HA cluster.
JournalNode machines - the machines on which you run the JournalNodes. Note: There must be at least 3 JournalNode daemons, since edit log modifications must be written to a majority of JNs. This will allow the system to tolerate the failure of a single machine. You may also run more than 3 JournalNodes, but in order to actually increase the number of failures the system can tolerate, you should run an odd number of JNs, (i.e. 3, 5, 7, etc.). Note that when running with N JournalNodes, the system can tolerate at most (N - 1) / 2 failures and continue to function normally.
Configuration details:
To configure HA NameNodes, you must add several configuration options to your hdfs-site.xml configuration file.
- dfs.nameservices - the logical name for this new nameservice
<property>
<name>dfs.nameservices</name>
<value>mycluster</value>
</property>- dfs.ha.namenodes.[nameservice ID] - unique identifiers for each NameNode in the nameservice
<property>
<name>dfs.ha.namenodes.mycluster</name>
<value>nn1,nn2</value>
</property>- dfs.namenode.rpc-address.[nameservice ID].[name node ID] - the fully-qualified RPC address for each NameNode to listen on
<property>
<name>dfs.namenode.rpc-address.mycluster.nn1</name>
<value>machine1.example.com:8020</value>
</property>
<property>
<name>dfs.namenode.rpc-address.mycluster.nn2</name>
<value>machine2.example.com:8020</value>
</property>注意:NN之间,NN和DN之间是通过rpc协议通讯,传递数据
- dfs.namenode.http-address.[nameservice ID].[name node ID] - the fully-qualified HTTP address for each NameNode to listen on
<property>
<name>dfs.namenode.http-address.mycluster.nn1</name>
<value>machine1.example.com:50070</value>
</property>
<property>
<name>dfs.namenode.http-address.mycluster.nn2</name>
<value>machine2.example.com:50070</value>
</property>- dfs.namenode.shared.edits.dir - the URI which identifies the group of JNs where the NameNodes will write/read edits
<property>
<name>dfs.namenode.shared.edits.dir</name>
<value>qjournal://node1.example.com:8485;node2.example.com:8485;node3.example.com:8485/mycluster</value>
</property>JN主机名,官方推荐奇数个JN节点 .客户端请求NN的时候都要去访问这个地址。
- dfs.client.failover.proxy.provider.[nameservice ID] - the Java class that HDFS clients use to contact the Active NameNode
<property>
<name>dfs.client.failover.proxy.provider.mycluster</name>
<value>org.apache.hadoop.hdfs.server.namenode.ha.ConfiguredFailoverProxyProvider</value>
</property>- dfs.ha.fencing.methods - a list of scripts or Java classes which will be used to fence the Active NameNode during a failover。Importantly, when using the Quorum Journal Manager, only one NameNode will ever be allowed to write to the JournalNodes, so there is no potential for corrupting the file system metadata from a split-brain scenario.
sshfence - SSH to the Active NameNode and kill the process。
<property>
<name>dfs.ha.fencing.methods</name>
<value>sshfence</value>
</property>
<property>
<name>dfs.ha.fencing.ssh.private-key-files</name>
<value>/home/exampleuser/.ssh/id_rsa</value>
</property>由于NN做主备,zk知道哪台是活动的,所以这步相当于做免密登录,让NN和DN之间免密登录。
Optionally, one may configure a non-standard username or port to perform the SSH. One may also configure a timeout, in milliseconds, for the SSH, after which this fencing method will be considered to have failed. It may be configured like so:
<property>
<name>dfs.ha.fencing.methods</name>
<value>sshfence([[username][:port]])</value>
</property>
<property>
<name>dfs.ha.fencing.ssh.connect-timeout</name>
<value>30000</value>
</property>
- shell - run an arbitrary shell command to fence the Active NameNode
The shell fencing method runs an arbitrary shell command. It may be configured like so:
<property>
<name>dfs.ha.fencing.methods</name>
<value>shell(/path/to/my/script.sh arg1 arg2 ...)</value>
</property>- fs.defaultFS - the default path prefix used by the Hadoop FS client when none is given
core-site.xml
<property>
<name>fs.defaultFS</name>
<value>hdfs://mycluster</value>
</property>客户端访问集群的入口
- dfs.journalnode.edits.dir - the path where the JournalNode daemon will store its local state
<property>
<name>dfs.journalnode.edits.dir</name>
<value>/path/to/journal/node/local/data</value>
</property>JN的edits工作目录,如果不指定则使用tmp临时目录。
启动步骤:
- hadoop-daemon.sh start journalnode
- initially synchronize the two HA NameNodes’ on-disk metadata
- hdfs namenode -format --格式化
- hdfs namenode -bootstrapStandby --NN同步数据
- hdfs namenode -initializeSharedEdits --增加NN节点
安全模式:
NN安全模式文件系统为只读模式,如果手工设置只读模式,则可以进行系统维护(迁移备份);安全模式可以手工设置
hdfs dfsadmin -safemode <wnter| leave |get|wait> 安全模式
hdfs损坏,NN节也会进入安全模式。
hDFS回收站机制:
| s.trash.interval | 0 | Number of minutes after which the checkpoint gets deleted. If zero, the trash feature is disabled. This option may be configured both on the server and the client. If trash is disabled server side then the client side configuration is checked. If trash is enabled on the server side then the value configured on the server is used and the client configuration value is ignored. |
| fs.trash.checkpoint.interval | 0 | Number of minutes between trash checkpoints. Should be smaller or equal to fs.trash.interval. If zero, the value is set to the value of fs.trash.interval. Every time the checkpointer runs it creates a new checkpoint out of current and removes checkpoints created more than fs.trash.interval minutes ago. |















 532
532

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









