






最小二乘线性回归,感知机,逻辑回归的比较:
| 最小二乘线性回归 Least Squares Linear Regression | 感知机 Perceptron | 二分类逻辑回归 Binary Logistic Regression | 多分类逻辑回归 Multinomial Logistic Regression | |
| 特征x | x=([x1,x2,...,xn,1])T | |||
| 权重w | w=([w1,w2,...,wn,b])T | |||
| 目标y | 实数(负无穷大到正无穷大) | 两个类别 1,-1 | 两个类别 0,1 | 多个类别 c=0,1,...,k-1 |
| 目标函数 | 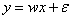 |  |
(类别1的概率) |
for c=0,1,...,k-1 (全部类别的概率) |
| 对y的估计 | 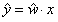 | 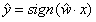 | (类别1的概率) |
for c=0,1,...,k-1 (全部类别的概率) |
| 映射函数 | 无 | sign函数 | sigmoid函数 | softmax函数 |
| 算法的作用 | 预测 | 分类 | 分类 | 分类 |
| 损失函数 | 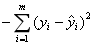 | 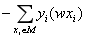 | 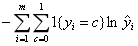 | 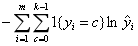 |
| 损失函数的含义 | 观测值与估计值之间的欧式距离平方和 | 错误分类点距离分类超平面的总长度 | 估计的概率分布与真实的概率分布之间的相似程度,对于样本(xi,yi),它的正确分类类别是c,那么如果它计算出的目标属于类别c的分类概率的值为1,则说明分类完全正确,这种情况下对损失函数没有贡献(ln1=0);而如果分类错误,则它计算出的目标属于类别c的的分类概率将是一个小于1的值,这种情况下将对损失函数有所贡献 | 估计的概率分布与真实的概率分布之间的相似程度,对于样本(xi,yi),它的正确分类类别是c,那么如果它计算出的目标属于类别c的分类概率的值为1,则说明分类完全正确,这种情况下对损失函数没有贡献(ln1=0);而如果分类错误,则它计算出的目标属于类别c的的分类概率将是一个小于1的值,这种情况下将对损失函数有所贡献 |
| 损失函数的本质 | 目标y的条件概率P(y|x)在高斯分布下的极大似然估计(取对数) | / | 目标y的条件概率P(y|x)在伯努利分布下的极大似然估计(取负数和自然对数) | 目标y的条件概率P(y|x)在多项分布下的极大似然估计(取负数和自然对数) |
| 最优解方法 | 解析解(closed form),梯度下降法,牛顿法,拟牛顿法 | 随机梯度下降法,牛顿法,拟牛顿法 | 梯度下降法,牛顿法,拟牛顿法 | 梯度下降法,牛顿法,拟牛顿法 |
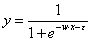
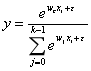
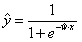















 1497
1497











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









