






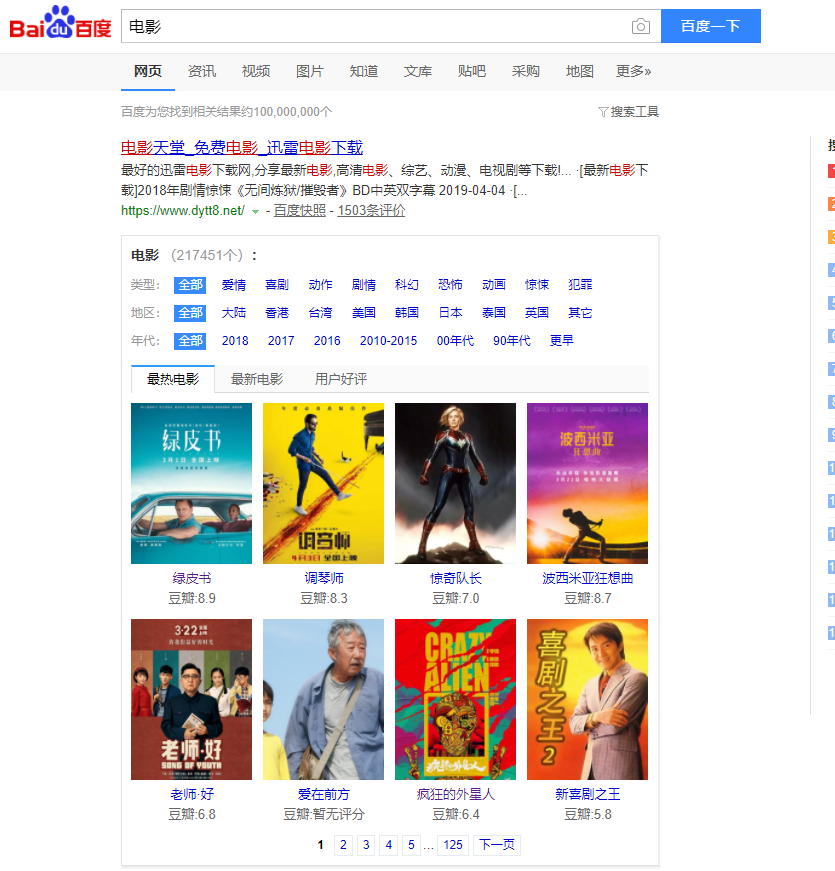
目标是利用python爬取百度搜索的电影
在类型 地区 年代各个标签下 电影的名字 评分 和图片连接 以及 电影连接
首先我们先在mysql中建表
create table liubo4( id int not null auto_increment, score VARCHAR(50) DEFAULT 0, name VARCHAR(50) DEFAULT 0, Pic VARCHAR(200) DEFAULT 0, dianyingurl VARCHAR(200) DEFAULT 0, leixing VARCHAR(50) DEFAULT 0, niandai VARCHAR(50) DEFAULT 0, diqu VARCHAR(50) DEFAULT 0, PRIMARY KEY (id))
其中 图片地址列和电影地址列的 字段名要设置长一点 否则插入时不够,最好为每一列设置默认值。

我们在切换页数时会发现,浏览器地址栏中是没有变化的,这就使得无法直接用地址栏的url变化和xpath来获取标签进行爬取。
那么我们就用另外一种-----解析json字符串。
首先打开f12
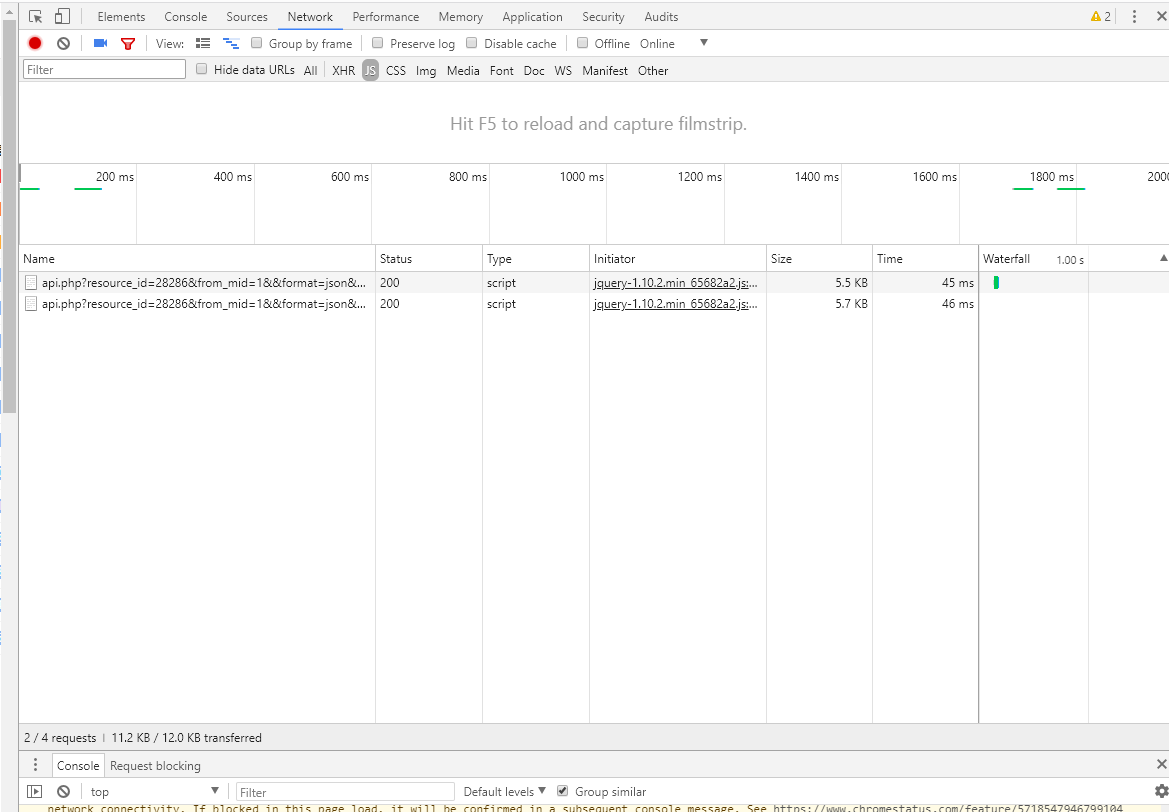


我们在切换页数时,会出现两个记录。
点开1.2两个行的行踪记录,能看到他们的Request URL
仔细看会发现这两个request的url主要不同在在于:第二页比第一页的pn多了8,那么我们就可以根据这个规律,在python中利用for 循环来请求125页的爬取。
找到了页面的规律,我们再去寻找具体的标签。
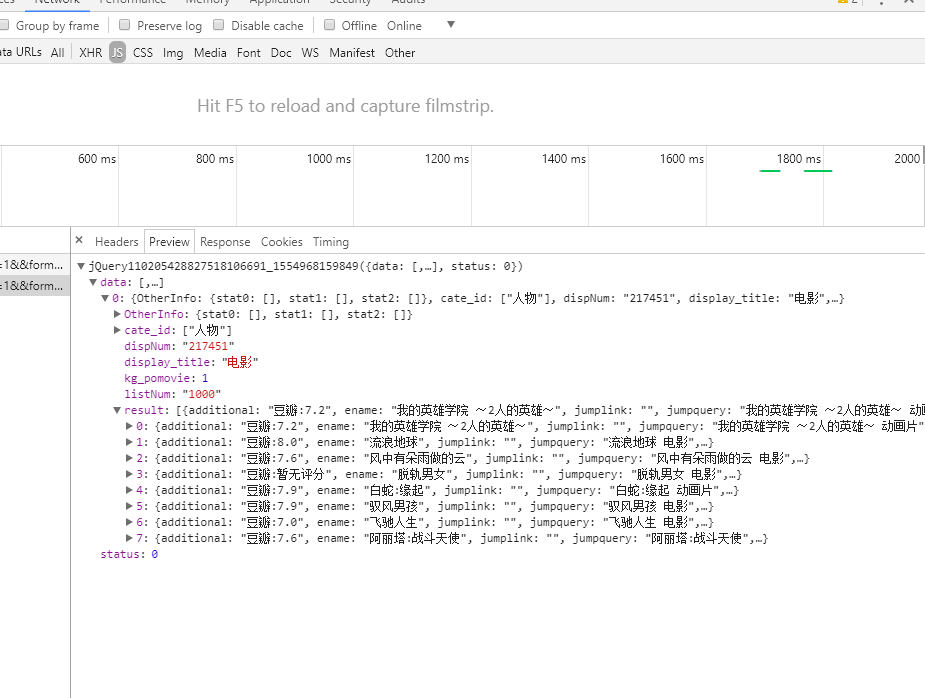
我们可以看到我们需要的 评分 名字 都被分别存放在 1.[data]-[result]-[additional] 2.[data]-[result]-[ename] 之中 。 而且每一页八部电影,分别被存在在result中的排序0-7。
那么图片url和电影url在哪呢 我们直接打开request url

在json字符串中 我们可以找到 picurl 而电影名字点开一部电影可以发现前部分的域名都是一样的 再加上不同的电影名字。
代码
import requests import json import re import os import pickle import pymysql db = pymysql.connect('localhost', 'root', '123456', 'languid')连接mysql urlbase = "https://sp0.baidu.com/8aQDcjqpAAV3otqbppnN2DJv/api.php?resource_id=28286&from_mid=1&&format=json&ie=utf-8&oe=utf-8&query=%E7%94%B5%E5%BD%B1&sort_key=16&sort_type=1&stat0=&stat1=&stat2=&stat3=&pn=" urllist =[] for i in range(1,125): url = urlbase+str(8*i) urllist.append(url) listxixi=[] for uri in urllist: headers = {"User-Agent": "Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/65.0.3325.181 Safari/537.36)"} response = requests.get(uri,headers=headers).text json_str = json.loads(response) 解析json字符串 aa=json_str['data'][0]['result'][0]['additional'] bb=json_str['data'][0]['result'][0]['ename'] cc=json_str['data'][0]['result'][0]['kg_pic_url'] dd='https://www.baidu.com/s?rsv_idx=1&tn=44004473_1_oem_dg&wd='+json_str['data'][0]['result'][0]['ename'] listxixi.append([aa, bb, cc, dd]) cursor =db.cursor() sql = "insert into liubo4(name,score,Pic,dianyingurl) Values(%s,%s,%s,%s)"#这里使用格式化字符串,用占位符 cursor.executemany(sql ,listxixi) db.commit() db.close()
这里使用insert语句中的 executemany 批量插入到mysql中 。首先要创建一个list 然后再插入mysql。
然后用第二种遍历commit 逐条提交
import requests import json import re import os import pickle import pymysql db = pymysql.connect('localhost', 'root', '123456', 'languid') urlbase = "https://sp0.baidu.com/8aQDcjqpAAV3otqbppnN2DJv/api.php?resource_id=28286&from_mid=1&&format=json&ie=utf-8&oe=utf-8&query=%E7%94%B5%E5%BD%B1&sort_key=16&sort_type=1&stat0=&stat1=&stat2=&stat3=&pn=" urllist =[] for i in range(1,124): url = urlbase+str(8*i) urllist.append(url) for uri in urllist: headers = {"User-Agent": "Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/65.0.3325.181 Safari/537.36)"} response = requests.get(uri,headers=headers).text json_str = json.loads(response) aa=json_str['data'][0]['result'][0]['additional'] bb=json_str['data'][0]['result'][0]['ename'] cc=json_str['data'][0]['result'][0]['kg_pic_url'] dd='https://www.baidu.com/s?rsv_idx=1&tn=44004473_1_oem_dg&wd='+json_str['data'][0]['result'][0]['ename'] cursor = db.cursor() sql = "insert into liubo3(score,name,Pic,dianyingurl,leixing,niandai,diqu) VALUES ('%s','%s','%s','%s','犯罪','大陆','2016')" %(aa,bb,cc,dd) cursor.execute(sql) db.commit()
这里的标签中的类型、地区、年代是直接写死的 ,暂且没有找到好的办法去寻找规律。
附上一个用beautifulsoup简单爬取标签的代码
import requests from bs4 import BeautifulSoup import pymysql headers = {"User-Agent": "Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/65.0.3325.181 Safari/537.36)"} url='https://www.baidu.com/s?ie=utf-8&f=8&rsv_bp=1&rsv_idx=1&tn=44004473_1_oem_dg&wd=%E7%94%B5%E5%BD%B1&rsv_pq=c30325e3000821d1&rsv_t=a23ejDCMhrNpbUK9fSZYvGt62pChqFxtcBIduHebPB%2BFDC%2BPosF8jTkgd1ZiL4KWiuTzBg5rtwY&rqlang=cn&rsv_enter=1&rsv_sug3=5&rsv_sug1=4&rsv_sug7=100' req = requests.get(url, headers=headers) soup = BeautifulSoup(req.text,'lxml') #xml = soup.find_all('p',class_='op_exactqa_tag_stat0') #ddd = soup.find_all ('p',class_='op_exactqa_tag_stat1') ccc = soup.find_all('p',class_='op_exactqa_tag_stat2') leixin =[] for name in ccc: niandai=name.get_text() db = pymysql.connect('localhost', 'root', '123456', 'languid') cursor = db.cursor() sql = "insert into liubo2(niandai)VALUES ('%s')"%(niandai) cursor.execute(sql) db.commit()
但是爬取到表中是整个list传入到表格,还没有学习透彻。
在整个爬虫制作过程中,学习网上爬取豆瓣电影的xpath办法失败了。
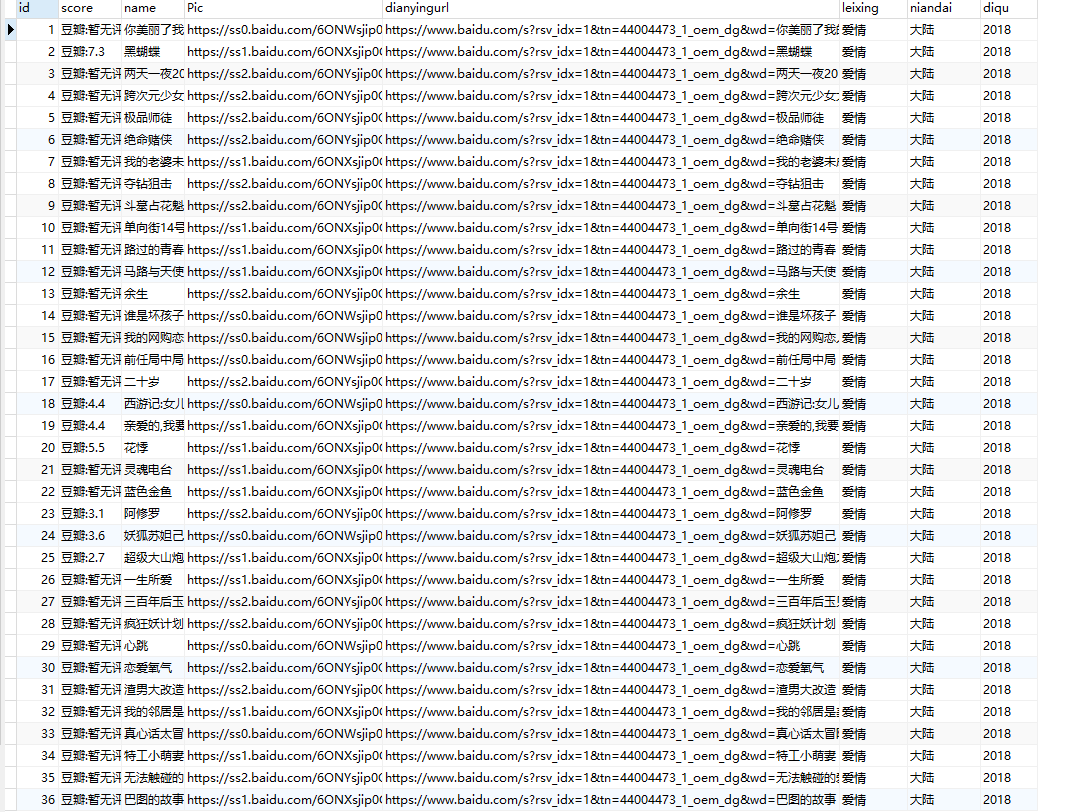
存入到mysql中的构架。
将爬取到的数据写入txt或者csv中
with open('wozuishuai5.txt', 'a+') as f: f.write('\n'+aa+'\n'+bb+'\n'+cc+'\n'+dd)














 942
942











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









