






最近在写龙龙第二版网络风行者。网络风行者引入了规则体系,简介如下:
规则主要分成两部分,一是数据匹配规则,二是数据提取规则。本文详述数据匹配规则,数据提取规则只简单提及。
我认为好的规则应该具备以下两点:
(1)实用,能适用于大部分应用场合
(2)易用,容易编写与调试
我看了几个国内现有的网络信息提取软件,主要是通过制定正则表达式进行提取,适用的场景有限,主要适用于1对1的数据提取场景,既从1个页面提取一条或多条数据,插入1个表中。用户需要熟练使用正则表达式,规则的直观性差。
网络风行者的规则类似于XML文档的schema,通过这样的规则匹配出html页面中的节点(当然首先需要将html转换为标准的树性结构,如xhtml或其它),然后再结合正则表达式及其它转换规则,进行数据提取(结合部分还没做)。
一、编写规则
编写规则文件很简单,对于一般的网站,打开你想要的页面,保存下来,使用dreamweaver或其它什么编辑器直接把包含你想要数据项的html代码提取出来存成一个文件就是规则了。当然,复杂的页面的规则稍微复杂一点,需要在html代码中加一些规则参数。
先看Demo(吸引眼球先),Demo之后是规则体系结构。
二、Demo
(1)样本――中国专利数据库摘要页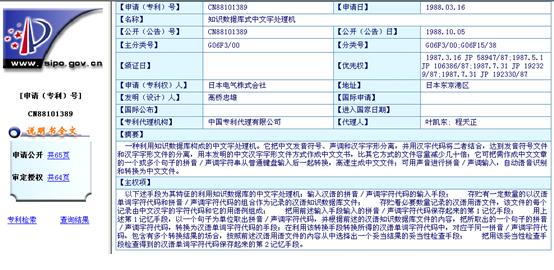
(2)制定规则――截取我需要的html代码作为规则,并在我需要提取项加上kdistill属性:
< table bordercolordark =#ffffff width ="778" bordercolorlight =#4787b8 border =1 cellspacing =0 style ="WORD-BREAK: break-all" >
< tbody >
< tr height ="22" >
< td width ="20%" bgcolor ="#D9F0FD" > 【申请(专利)号】 </ td >
< td width ="30%" kdistill ="专利号" > CN88101389 </ td >
< td width ="20%" bgcolor ="#D9F0FD" > 【申请日】 </ td >
< td width ="30%" kdistill ="申请日" > 1988.03.16 </ td >
</ tr >
< tr height ="22" >
< td width ="20%" bgcolor ="#D9F0FD" > 【名称】 </ td >
< td width ="80%" colspan ="3" kdistill ="名称" > 知识数据库式中文字处理机 </ td >
</ tr >
< tr height ="22" >
< td width ="20%" bgcolor ="#D9F0FD" > 【公开(公告)号】 </ td >
< td width ="30%" kdistill ="公开号" > CN88101389 </ td >
< td width ="20%" bgcolor ="#D9F0FD" > 【公开(公告)日】 </ td >
< td width ="30%" kdistill ="公开日" > 1988.10.05 </ td >
</ tr >
< tr height ="25" >
< td width ="20%" height ="25" bgcolor ="#D9F0FD" wrap > 【主分类号】 </ td >
< td width ="30%" height ="25" kdistill ="主分类号" > G06F3/00 </ td >
< td width ="20%" height ="25" bgcolor ="#D9F0FD" wrap > 【分类号】 </ td >
< td width ="30%" height ="25" kdistill ="分类号" > G06F3/00;G06F15/38 </ td >
</ tr >
<!-- tr height="22">
<td width="20%" bgcolor="#D9F0FD">【分案原申请号】 </td>
<td width="30%"> </td>
</tr -->
< tr height ="22" >
< td width ="20%" bgcolor ="#D9F0FD" > 【颁证日】 </ td >
< td width ="30%" kdistill ="颁证日" > </ td >
< td width ="20%" bgcolor ="#D9F0FD" > 【优先权】 </ td >
< td width ="30%" kdistill ="优先权" > 1987.3.16 JP 58947/87;1987.5.1 JP 106386/87;1987.7.31 JP 192329/87;1987.7.31 JP 192330/87 </ td >
</ tr >
< tr height ="22" >
< td width ="20%" bgcolor ="#D9F0FD" > 【申请(专利权)人】 </ td >
< td width ="30%" kdistill ="申请(专利权)人" > 日本电气株式会社 </ td >
< td width ="20%" bgcolor ="#D9F0FD" > 【地址】 </ td >
< td width ="30%" kdistill ="地址" > 日本东京港区 </ td >
</ tr >
< tr height ="22" >
< td width ="20%" bgcolor ="#D9F0FD" > 【发明(设计)人】 </ td >
< td width ="30%" kdistill ="发明(设计)人" > 高桥忠雄 </ td >
< td width ="20%" bgcolor ="#D9F0FD" > 【国际申请】 </ td >
< td width ="30%" kdistill ="国际申请" > </ td >
</ tr >
< tr height ="22" >
< td width ="20%" bgcolor ="#D9F0FD" > 【国际公布】 </ td >
< td width ="30%" kdistill ="国际公布" > </ td >
< td width ="20%" bgcolor ="#D9F0FD" > 【进入国家日期】 </ td >
< td width ="30%" kdistill ="进入国家日期" > </ td >
</ tr >
< tr height ="22" >
< td width ="20%" bgcolor ="#D9F0FD" > 【专利代理机构】 </ td >
< td width ="30%" kdistill ="专利代理机构" > 中国专利代理有限公司 </ td >
< td width ="20%" bgcolor ="#D9F0FD" > 【代理人】 </ td >
< td width ="30%" kdistill ="代理人" > 叶凯东; 程天正 </ td >
</ tr >
< tr bgcolor ="#D9F0FD" height ="22" >
< td width ="100%" colspan ="4" >< a name ="biref" ></ a > 【摘要】 </ td >
</ tr >
< tr >
< td width ="100%" colspan ="4" kdistill ="摘要" >
一种利用知识数据库构成的中文字处理机。它把中文发音符号、声调和汉字字形分离,并用汉字代码将二者结合,达到发音符号文件和汉字字形文件的分离,用本发明的中文汉字字形文件方式作成中文文书,比其它方式的文件容量减少几十倍;它可把需作成中文文章的一个或多个句子的拼音/声调字符串从普通键盘输入后一起转换,高速生成中文文件;可用声音进行拼音/声调输入,自动语音识别和转换为中文文件。 </ td >
</ tr >
< tr bgcolor ="#D9F0FD" height ="22" >
< td width ="100%" colspan ="4" >< a name ="biref" ></ a > 【主权项】 </ td >
</ tr >
< tr >
< td width ="100%" colspan ="4" kdistill ="主权项" >
以下述手段为其特征的利用知识数据库的中文字处理机:
输入汉语的拼音/声调字符代码的输入手段; 存贮有一定
数量的以汉语单词字符代码和拼音/声调字符代码的组合作为
记录的汉语知识数据库文件; 存贮着必要数量记录的汉语
用语文件,该文件的每个记录由中文汉字的字符代码和它的用
语例组成; 把用前述输入手段输入的拼音/声调字符代码
保存起来的第1记忆手段; 用上述第1记忆手段,以一个
句子为单位取出拼音/声调字符代码,并根据前述的汉语知识
数据库文件的内容,把所取出的一个句子的拼音/声调字符代
码,转换为汉语单词字符代码的手段;在利用该转换手段转换
所得的汉语单词字符代码中,对应于同一拼音/声调字符代码
,包含有多个转换结果的场合,按照前述汉语用语文件的内容
从中选择出一个妥当结果的妥当性检查手段; 把用该妥当
性检查手段检查得到的汉语单词字符代码保存起来的第2记忆
手段。 </ td >
</ tr >
</ tbody >
</ table >
</ center ></ div >
(3)规则文件是可视化的。用浏览器查看规则――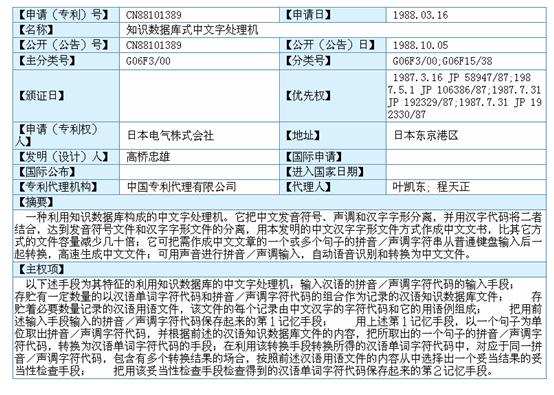
(4)网络风行者内部将上面的规则翻译成自己的模型:
< TABLE (Simple)BORDER (Simple)STYLE (Simple)CELLSPACING (Simple)WIDTH (Simple)BORDERCOLORLIGHT (Simple)BORDERCOLORDARK >
< TR (Simple)HEIGHT >
< TD (Simple)WIDTH (Simple)BGCOLOR >
</ TD >
< TD (Simple)WIDTH (Simple)KDISTILL >
</ TD >
< TD (Simple)WIDTH (Simple)BGCOLOR >
</ TD >
< TD (Simple)WIDTH (Simple)KDISTILL >
</ TD >
</ TR >
< TR (Simple)HEIGHT >
< TD (Simple)WIDTH (Simple)BGCOLOR >
</ TD >
< TD (Simple)COLSPAN (Simple)WIDTH (Simple)KDISTILL >
</ TD >
</ TR >
< TR (Simple)HEIGHT >
< TD (Simple)WIDTH (Simple)BGCOLOR >
</ TD >
< TD (Simple)WIDTH (Simple)KDISTILL >
</ TD >
< TD (Simple)WIDTH (Simple)BGCOLOR >
</ TD >
< TD (Simple)WIDTH (Simple)KDISTILL >
</ TD >
</ TR >
< TR (Simple)HEIGHT >
< TD (Simple)WIDTH (Simple)HEIGHT (Simple)BGCOLOR (Simple)WRAP >
</ TD >
< TD (Simple)WIDTH (Simple)HEIGHT (Simple)KDISTILL >
</ TD >
< TD (Simple)WIDTH (Simple)HEIGHT (Simple)BGCOLOR (Simple)WRAP >
</ TD >
< TD (Simple)WIDTH (Simple)HEIGHT (Simple)KDISTILL >
</ TD >
</ TR >
< TR (Simple)HEIGHT >
< TD (Simple)WIDTH (Simple)BGCOLOR >
</ TD >
< TD (Simple)WIDTH (Simple)KDISTILL >
</ TD >
< TD (Simple)WIDTH (Simple)BGCOLOR >
</ TD >
< TD (Simple)WIDTH (Simple)KDISTILL >
</ TD >
</ TR >
< TR (Simple)HEIGHT >
< TD (Simple)WIDTH (Simple)BGCOLOR >
</ TD >
< TD (Simple)WIDTH (Simple)KDISTILL >
</ TD >
< TD (Simple)WIDTH (Simple)BGCOLOR >
</ TD >
< TD (Simple)WIDTH (Simple)KDISTILL >
</ TD >
</ TR >
< TR (Simple)HEIGHT >
< TD (Simple)WIDTH (Simple)BGCOLOR >
</ TD >
< TD (Simple)WIDTH (Simple)KDISTILL >
</ TD >
< TD (Simple)WIDTH (Simple)BGCOLOR >
</ TD >
< TD (Simple)WIDTH (Simple)KDISTILL >
</ TD >
</ TR >
< TR (Simple)HEIGHT >
< TD (Simple)WIDTH (Simple)BGCOLOR >
</ TD >
< TD (Simple)WIDTH (Simple)KDISTILL >
</ TD >
< TD (Simple)WIDTH (Simple)BGCOLOR >
</ TD >
< TD (Simple)WIDTH (Simple)KDISTILL >
</ TD >
</ TR >
< TR (Simple)HEIGHT >
< TD (Simple)WIDTH (Simple)BGCOLOR >
</ TD >
< TD (Simple)WIDTH (Simple)KDISTILL >
</ TD >
< TD (Simple)WIDTH (Simple)BGCOLOR >
</ TD >
< TD (Simple)WIDTH (Simple)KDISTILL >
</ TD >
</ TR >
< TR (Simple)HEIGHT (Simple)BGCOLOR >
< TD (Simple)COLSPAN (Simple)WIDTH >
</ TD >
</ TR >
< TR >
< TD (Simple)COLSPAN (Simple)WIDTH (Simple)KDISTILL >
</ TD >
</ TR >
< TR (Simple)HEIGHT (Simple)BGCOLOR >
< TD (Simple)COLSPAN (Simple)WIDTH >
</ TD >
</ TR >
< TR >
< TD (Simple)COLSPAN (Simple)WIDTH (Simple)KDISTILL >
</ TD >
</ TR >
</ TABLE >
</ DIV >
(5)数据提取结果:
- < KDISTILL >
- < DATATABLE >
< DATA ID ="专利号" > CN88101389 </ DATA >
< DATA ID ="申请日" > 1988.03.16 </ DATA >
< DATA ID ="名称" > 知识数据库式中文字处理机 </ DATA >
< DATA ID ="公开号" > CN88101389 </ DATA >
< DATA ID ="公开日" > 1988.10.05 </ DATA >
< DATA ID ="主分类号" > G06F3/00 </ DATA >
< DATA ID ="分类号" > G06F3/00;G06F15/38 </ DATA >
< DATA ID ="颁证日" > </ DATA >
< DATA ID ="优先权" > 1987.3.16 JP 58947/87;1987.5.1 JP 106386/87;1987.7.31 JP 192329/87;1987.7.31 JP 192330/87 </ DATA >
< DATA ID ="申请(专利权)人" > 日本电气株式会社 </ DATA >
< DATA ID ="地址" > 日本东京港区 </ DATA >
< DATA ID ="发明(设计)人" > 高桥忠雄 </ DATA >
< DATA ID ="国际申请" > </ DATA >
< DATA ID ="国际公布" > </ DATA >
< DATA ID ="进入国家日期" > </ DATA >
< DATA ID ="专利代理机构" > 中国专利代理有限公司 </ DATA >
< DATA ID ="代理人" > 叶凯东; 程天正 </ DATA >
< DATA ID ="摘要" > 一种利用知识数据库构成的中文字处理机。它把中文发音符号、声调和汉字字形分离,并用汉字代码将二者结合,达到发音符号文件和汉字字形文件的分离,用本发明的中文汉字字形文件方式作成中文文书,比其它方式的文件容量减少几十倍;它可把需作成中文文章的一个或多个句子的拼音/声调字符串从普通键盘输入后一起转换,高速生成中文文件;可用声音进行拼音/声调输入,自动语音识别和转换为中文文件。 </ DATA >
< DATA ID ="主权项" > 以下述手段为其特征的利用知识数据库的中文字处理机:输入汉语的拼音/声调字符代码的输入手段; 存贮有一定数量的以汉语单词字符代码和拼音/声调字符代码的组合作为记录的汉语知识数据库文件; 存贮着必要数量记录的汉语用语文件,该文件的每个记录由中文汉字的字符代码和它的用语例组成; 把用前述输入手段输入的拼音/声调字符代码保存起来的第1记忆手段; 用上述第1记忆手段,以一个句子为单位取出拼音/声调字符代码,并根据前述的汉语知识数据库文件的内容,把所取出的一个句子的拼音/声调字符代码,转换为汉语单词字符代码的手段;在利用该转换手段转换所得的汉语单词字符代码中,对应于同一拼音/声调字符代码,包含有多个转换结果的场合,按照前述汉语用语文件的内容从中选择出一个妥当结果的妥当性检查手段; 把用该妥当性检查手段检查得到的汉语单词字符代码保存起来的第2记忆手段。 </ DATA >
</ DATATABLE >
</ KDISTILL >
三、规则体系结构
树性结构基本元素是节点。
节点包括以下方面:
(1)节点名称
(2)节点属性集合
(3)节点的elements集合
规则体系的主要概念是单节点匹配和多节点匹配。
1 单节点匹配
包括数种不同严格程度的节点匹配规则。
(1)简单匹配
忽略节点属性,只对节点名称及节点的elements进行匹配。如果规则中设置忽略elements匹配,则只对节点名称进行匹配。
以样本1和规则1为例,规则写在节点的kspider属性中。样本1肯定能匹配规则1。规则1如果删掉elements:ignore,代表不忽略子节点,这样就不能匹配样本1。
样本1:
< tr >
< td >
</ td >
</ tr >
</ table >
规则1:
< tr >
< td >
</ td >
</ tr >
< tr >
< td >
</ td >
</ tr >
</ table >
规则1中的<tr>...</tr>等部分看起来是多余的,因为规则规定忽略这些子节点。它们实际上也是多余的,删掉它们(见规则2)规则不会发生变化。不过放在这里我有我的道理,这个后面会说明。
规则2:
</ table >
当然也可以加上对节点值进行匹配的规则,但似乎很多应用不怎么需要这个,需要时再加上吧。
(2)完全匹配
对节点及节点属性进行匹配,如果设定忽略elements,则只匹配节点和节点属性。
规则3:
< tr >
< td >
</ td >
</ tr >
< tr >
< td >
</ td >
</ tr >
</ table >
规则3是一个完全匹配规则,不能匹配样本1。因为规则中table节点的height属性样本1没有。
默认的节点属性匹配仅仅匹配节点属性名称,不对节点属性值进行匹配。如果需要对节点属性进行完全匹配,需要在规则节点上加上attribute:full,如果想自定义属性值规则,则需要写上attribute:full[attribute1="pattern1", attribute2="pattern2",...] attribute1, attribute2...是属性名称。pattern1, pattern2......是以正则表达式表示的属性值的规则。
对于样本节点中有,而规则节点中没有的属性,目前我是认为不违反规则的,这样程序实现简单一些,一般应用也够了,如果实在需要加上约束要求属性一一对应匹配,到时候再加上也不迟。
2 多节点匹配
以上说的是单节点匹配,但很多情况有些数据项是可变的,单节点匹配不适用。就像字符串匹配经常采用的%,*,$等通配符一样,节点匹配也需要这样的机制。
也即验证节点序列:
<node1>
<node2>
<node3>
是否符合规则序列:
<node pattern1>
<node pattern2>
<node pattern3>
目前我采用这样的方案:节点规则中可设定该节点是否的最大连续出现数目和最小连续出现数目。这样可以使用于大多数应用场景。
具体设定为:kspider="...;min=xxx;max=xxx;..."
目前我没设通配节点(类似于%,*,$等通配符),需要时再设定吧。
与多节点匹配对应的概念是完全多节点匹配和部分节点匹配。完全的多节点匹配指节点序列完全符合规则序列。部分节点匹配指节点序列中的一个部分节点序列能够符合规则序列,但是全部序列不符合规则序列。如规则4不完全匹配样本2。
样本2:
< table >
< div >
</ div >
< div >
</ div >
< table >
< table >
规则 4 :
</ div >
完全的多节点匹配一般用于节点的elements的比较。我对节点的elements的规则匹配采用的是完全匹配。非完全多节点匹配一般用于数据提取,如一个页面中存在多条数据,则通过不完全匹配将这些数据一一提取出来。
单节点匹配是多节点匹配的实例。
3 规则制定
默认的话,对节点来说是完全匹配,匹配节点的名称,属性名称和子节点序列的完全匹配。节点最大连续发生数和最小连续发生数都是1。
因为有默认项,看起来挺复杂的规则用起来很简单。尽管规则文件存在冗余信息,但何必费劲删除它呢,留着又不碍事。如果数据项中存在可变数目的子项,最简单的方法就是在父节点上采用elements:ignore,或者采用max,min。极其个别的应用,才会用到其它的规则选项。
另外,可以设置TriggerTag,只有属于TriggerTag的节点,才作为比较项。不属于TriggerTag的节点,就当它是父节点的一段值。
需要提取的项用kdistill属性标注。kdistill属性目前规则很简单,因为我还要加上复杂的规则(主要是存储规则),实现后再详细介绍吧。
本文转自xiaotie博客园博客,原文链接http://www.cnblogs.com/xiaotie/archive/2006/03/07/344621.html如需转载请自行联系原作者
xiaotie 集异璧实验室(GEBLAB)














 501
501











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









