







做互联网业务免不了和数据打交道,数据量一大各种问题层出不穷,磁盘空间是个问题吧,传输带宽是个问题吧,分析挖掘是个问题吧,增删改查是个问题吧。数据量大就算了,重复冗余带来存储传输计算压力也大幅度增长,所以数据排重很重要,方法很多,挑了几个有行业代表性、效果说得过去、简单易懂易实现的算法聊一聊,今儿个先谈谈基于TF向量和TF-IDF向量两种相似度计算的算法、实现与比较。
第一步词表:将待计算相似度的文档分词后汇总成总词表,以便统计每篇文档的词频;
第二步词频:以分词作为key,以词频作为val,将每个文档分别数字化到各自的向量空间中;
第三步计算:将向量空间中的值逐一带入下面的公式,计算两个向量空间的夹角余弦值;
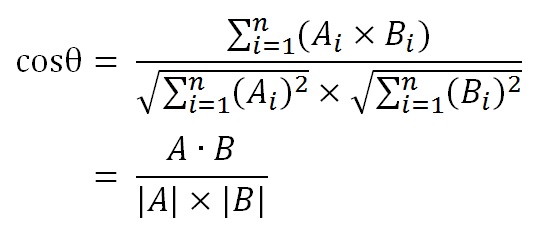
点评:这个方法简单粗暴好理解好实现工作量小分分钟搞定,缺点是没有考虑到每个词语在语句中的位置、权重等因素,频次高的未必权重高,缺乏对同义词近义词的容忍,适合硬相似度计算,对于软相似度计算没有效果。
接下来对TF值进行调整,将向量值换成TF-IDF,并对该值设置阈值,低于阈值的项丢弃不参与余弦运算,这样做的目的是为了提升词语在语句权重中的价值,修正硬相似度计算中所导致的误差。
初始化IDF配置:
private static void CompInitTfIdf(Map<String, Double> c) throws Exception {
String buf = new String();
BufferedReader br = new BufferedReader(new FileReader(XX_FIDF));
while (null != (buf = br.readLine())) {
String[] arr = buf.split("\t");
c.put(arr[0], new Double(arr[1]));
}
br.close();
}获取TF-IDF并排序:
private static void SimilDocTfIdf(Map<String, Double> c, Map<String, Double> b, String s) {
Double val = null;
String wds[] = null;
Map<String, Double> doc = new HashMap<>();
Vector<Map.Entry<String, Double>> rst = new Vector<>();
for (String w : (wds = s.split(" "))) {
doc.put(w, null != (val = doc.get(w)) ? val + 1 : 1);
}
for (Map.Entry<String, Double> v : doc.entrySet()) {
if (null != (val = c.get(v.getKey()))) {
v.setValue(v.getValue() / wds.length * val);
rst.add(v);
}
}
Collections.sort(rst, new Comparator<Map.Entry<String, Double>>() {
public int compare(Map.Entry<String, Double> n, Map.Entry<String, Double> m) {
return m.getValue().compareTo(n.getValue());
}
});
for (int idx = 0; idx < rst.size() / 2; ++ idx) {
b.put(rst.get(idx).getKey(), 0d);
}
}余弦相似度计算:
private static double SimilCosine(Vector<XxTfIdf> m, Vector<XxTfIdf> n) {
double nmr = 0, dn1 = 0, dn2 = 0;
int len = Math.min(m.size(), n.size()) - 1;
/* 分子计算 */
for (int idx = 0; idx < len; ++ idx) {
nmr += m.get(idx).val * n.get(idx).val;
}
/* 左向量计算 */
for (int idx = 0; idx < len; ++ idx) {
dn1 += m.get(idx).val * m.get(idx).val;
}
dn1 = Math.sqrt(dn1);
/* 右向量计算 */
for (int idx = 0; idx < len; ++ idx) {
dn2 += n.get(idx).val * n.get(idx).val;
}
dn2 = Math.sqrt(dn2);
/* 余弦值计算 */
return nmr / (dn1 * dn2);
}点评:这两种方法对相似度计算中自然语言的语义因素的考量都显得过于粗放,TF-IDF也仅是在TF基础上有小幅提升,都适合各种长短尺寸的语句,并未因语句长度增加造成效果衰减,反之同理,显然要想进一步提升相似度计算的效果还需要换个思路。
预告:《机学走起第六式:箭船分离》之局部哈希算法与实现。
















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









