







一、自定义轮询分片
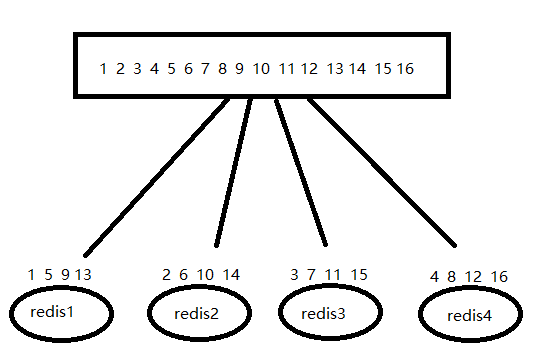
按照上图所示,自己写一段逻辑,根据客户端请求循环写入不同Redis服务器
优点:
- 理解简单
- 数据分布平均
缺点:
- 如果增加redis内存数据库服务器,需要改代码,需要发布代码,很麻烦,有风险
- 数据迁移量较多
二、哈希取余分片
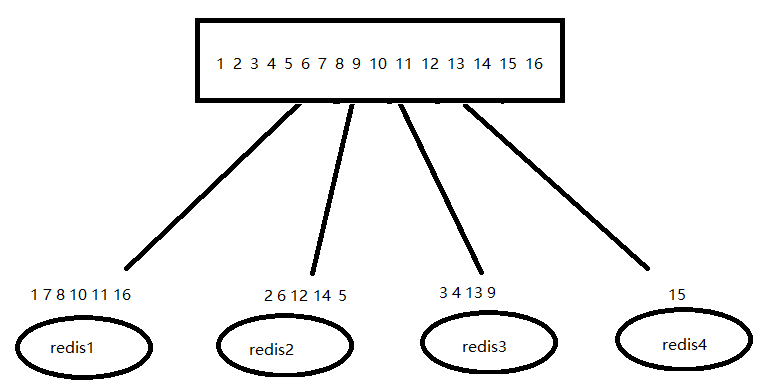
哈希取余就是一种特殊的自定义分片方式
优点:这里介绍的三种方式最差的
缺点:
- 如果增加redis内存数据库服务器,需要改代码,需要发布代码,很麻烦,有风险
- 数据迁移量多,理论是old/new,new = old+increase
- 数据倾斜,从上图中可以看出最左侧的redis1服务器上存放的数据最多,最右侧的redis4服务器存放最少,如果数据都是几十亿的级别,那么倾斜就相当严重,单台服务器压力会过载
三、哈希一致性分片
它是Jedis采用的分片方式,并提供了JedisShardInfo、JedisPoolConfig、ShardedJedisPool、ShardedJedis 相关API做成redis连接池,分片逻辑对程序员透明
用图来直观了解一下哈希一致性的分片算法,看到下面的图不要害怕,根据后面的文字描述搭配着看
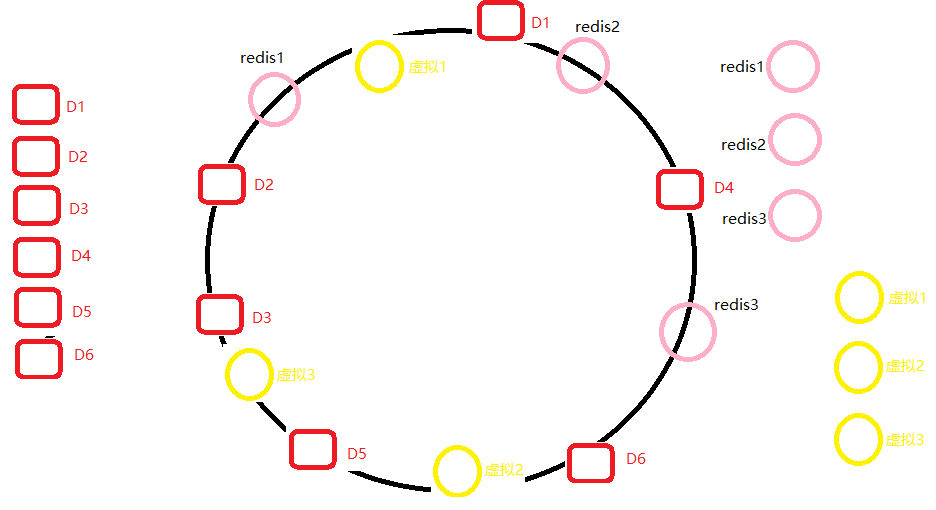
 代表真实的redis服务器
代表真实的redis服务器
 代表虚拟的redis服务器,虚拟服务器隶属于真实服务器,比如虚拟2服务器需要存放的数据被真实的存放到redis2服务器上
代表虚拟的redis服务器,虚拟服务器隶属于真实服务器,比如虚拟2服务器需要存放的数据被真实的存放到redis2服务器上
![]() 代表数据
代表数据
说明:
1.图中最大的圆是由2^32个点组成的圆,每个点是1到2^32中的一个数
算法:
1.jedis根据redis服务器的ip+port+其他输入信息计算出一个哈希值,并将该哈希值映射到圆上
2.jedis根据key计算出一个哈希值,并将该哈希值映射到圆上
3.jedis根据key在圆上的位置顺时针找第一个redis服务器哈希值映射的点,该点对于的服务器就是key-value存储的服务器
4.如果只存在redis服务器的点,数据倾斜还是会经常发生,为了解决这一问题,jedis根据真是服务器的信息虚拟出n*1000个虚拟服务器,将整个圆分段更多,数据(key-value)存放便更均匀,解决数据倾斜的问题,其中n是真实redis服务器的台数
图中没法画出4000个虚拟服务器,只是给每一台真实redis服务器虚拟一台服务器,且画的最理想哈希结果,最终每台服务器存放两个数据。















 2878
2878











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









