







简介
grep (global search regular expression(RE) and print out the line,全面搜索正则表达式并把行打印出来)是一种强大的文本搜索工具,它能使用正则表达式搜索文本,并把匹配的行打印出来。
Unix的grep家族包括grep、egrep和fgrep。egrep和fgrep的命令只跟grep有很小不同。egrep是grep的扩展,支持更多的re元字符, fgrep就是fixed grep或fast grep,它们把所有的字母都看作单词,也就是说,正则表达式中的元字符表示回其自身的字面意义,不再特殊。linux使用GNU版本的grep。它功能更强,可以通过-G、-E、-F命令行选项来使用egrep和fgrep的功能。
grep命令
常用选项
-
-c行数 -
-i不区分大小写 -
-n显示行号 -
-v取反 -
-r遍历所有子目录 -
-A后面跟数字,过滤出符合要求的行以及下面的n行 -
-B同上,过滤出符合要求的行以及上面的n行 -
-C同上,过滤出符合要求的行以及上下各n行
基本正则表达式元字符 :
字符匹配 :
.:匹配任意单个字符;
[]:匹配指定范围内的任意单个字符;
[^]:匹配指定范围外的任意单个字符;
[:digit:]、[:lower:]、[:upper:]、[:alpha:]、[:alnum:]、[:punct:]、[:space:]
匹配次数 : 用在要指定其出现的次数的字符的后面,用于限制其前面字符出现的次数;默认工作于贪婪模式;
*:匹配其前面的字符任意次;0,1,多次;
例如 : grep "x*y"
abcd
acbd
*: 匹配任意长度的任意字符
\?: 匹配其前面的字符0次或1次;即其前面的字符是可有可无的;
\+: 匹配其前面的字符1次或多次;即其面的字符要出现至少1次;
\{m\} : 匹配其前面的字符m次;
\{m,n}\ : 匹配其前面的字符至少m次,至多n次;
\{0,n\} : 至多n次;
\{m,\} : 至少n次;
位置锚定 :
^:行首锚定 : 用于模式的最左侧;
$:行尾锚定 : 用于模式的最右侧;
^PATTERN$ :用于PATTERN来匹配整行;
单词 : 非特殊字符组成的连续字符(字符串)都称为单词;
\<或\b:词首锚定,用于单词模式的左侧;
\<或\b:词尾锚定,用于单词模式的右侧;
\<PATTERN\>:匹配完整单词;
分组及引用
\(\) : 将一个或多个字符捆绑在一起,当作一个整体进行处理;
\(xy\)*ab
Note : 分组括号中的模式匹配到的内容会被正则表达式引型自动记录于内部的变量中,这些变量为:
\1 : 模式从左侧起,第一个左括号以及与之匹配的右括号之间的模式所匹配到的字符;
\2 : 模式从左侧起,第一个左括号以及与之匹配的右括号之间的模式所匹配到的字符;
\3 :
后向引用 : 引用前面的分组括号中的模式所匹配到的字符;
使用示例
grep -n 'root' /etc/passwd
grep -nv 'nologin' /etc/passwd
grep '[0-9]' /etc/passwd
grep -v '[0-9]' /etc/passwd
grep -v '^#' /etc/passwd
grep '^[^a-zA-Z]' /etc/passwd
grep 'r.o' /etc/passwd
grep '00*' /etc/passwd
grep '.*' /etc/passwd
grep 'o\{2\}' /etc/passwd
grep -E 'o{2}' /etc/passwd
grep -E 'o+' /etc/passwd
grep -E 'oo?' /etc/passwd
grep -E 'root|nologin' /etc/passwd
grep -E '(oo){2}' /etc/passwd使用案例 :
1、显示/etc/passwd文件中不以/bin/bash结尾的行;
# grep -v "/bin/bash$" /etc/passwd
2、找出/etc/passwd文件中的两位数或三位数;
#grep "\]<[0-9\{2,3\}\>" /etc/passwd
3、找出/etc/rc.d/rc.sysinit或/etc/grub2.cfg文件中,以至少一个空白字符开头,且后面非空白字符的行;
# grep "^[[:space:]]\+[^[:space:]]" /etc/grub2.cfg
4、找出“netstat -tan” 命令的结果中以'LISTEN'后跟0、1或多个空白字符结尾的行;
# netstat -tan | grep "LISTEN[[:space:]]*$"
5、找出以root开头 、root结尾的行;
# grep "^root$" /etc/passwd
6、找出文档中包含l..e.*l..e的在love.txt中
# grep "l..e.*l..e" love.txt

# grep "\(l..e).*\1" love.txt

7、搜索含有root,hadoop的行
grep -E “root|hadoop” /etc/passwd
8、只搜索行首含有root,hadoop的行
grep -E “^(root|hadoop)\>” /etc/passwd
9、只搜索行首含有root,hadoop的行,并重定向到/mnt/sysroot/etc/passwd
grep -E “^(root|hadoop)\>” /etc/passwd > /mnt/sysroot/etc/passwd
10、查看磁盘大小,并查找以“Disk /dev/[sh]d[a-z]”开头,只显示第一行。
答 : disk -l 2> /dev/null | grep "^Disk /dev/[sh]d[a-z]”" | awk -F:'(print $1)'
11、在用户目录下查找文件名后缀为.yml的文件
find ~ -name '*.yml' | grep '\.yml' --color=always
12、查找当前目录下权限为644的所有文件
find . -perm 644
13、整个语句是在当前目录下查找名为feed.xml的文件,同时需要忽略./_site*路径的文件。-a -o 实际为逻辑与逻辑或,当路径匹配时将执行-prune,那么将不会查找匹配路径中的文件,当路径不匹配时则不执行-prune,-o后的语句始终执行。
find . -path './_site*' -a -prune -o -name 'feed.xml' -print
14、控制查找的深度
find .-maxdepth 2 -size 3
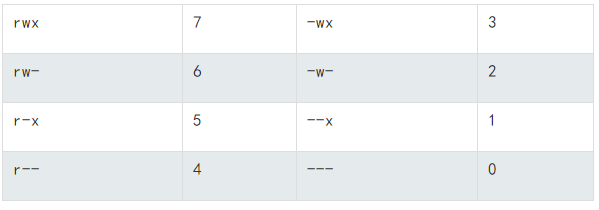
补充:Linux的权限模式为三元组“owner”,“group”,“other”,权限对应表如下

15、tail文本查看命令,可以看文本的最后几行。tail命令的优点在于其内容能够与输入同步更新,非常适用于查看实时日志。
基本格式 tail [option] [filename]
-
-n number定位参数,+5表示从第五行开始显示,10或-10表示显示最后10行 -
-f监控文本变化,更新内容 -
-k number从number所指的KB处开始读
范例一:tail -n -5 catalina.out 输出最后5行
16、范例二:tail -f catalina.out 监听catalina.out最后行的变化并显示
17、范例三:du -ah --max-depth=1显示递归的层次为1,显示所有文件和文件夹大小
18、sort -t - -k 1.7 -nk 3,3 sort_k.txt-k start,end中end可以省略,上面的1.7表示分割后第一个域的第7个字符,由于没有end,则表示对第一个域中第7字符及其之后的字符排序。而3,3则表示在前面排序的基础上,再对第三个域进行排序。
-
sort -nk 2 -t - sort.txt以-进行分割,对分割后的第二个域进行排序; -
sort -nrk 2 -t - sort.txt逆序排序
19、more命令用于显示文件的内容,与cat和tail等命令不同的是,more命令是按页显示文件内容,同时具有搜寻字符串的功能。(由于more具有向前翻页功能,因此该命令会加载整个文件)
基本格式 more [option] [filename]
-
+n从第n行开始显示 -
-n定义屏幕大小为n行 -
+/pattern再显示前按pattern匹配子串并显示 -
-s把连续的多个空行显示为一行常用操作命令:
-
Enter 向下n行,默认为1行
-
Ctrl+F 跳过一屏
-
Ctrl+B 返回上一屏
-
空格键 向下滚动一屏
-
= 输出当前行的行号
-
在more模式中回车,输入
/pattern可以持续向下搜索
-
-
more +/Deploy catalina.out
在catalina.out文件中查找“Deploy字符第一次出现的位置”,并从该处的前两行开始显示输出 -
more +10 -10 catalina.out
从第10行开始,每页10行
20、less命令与more命令对应,既可以前后翻看文件,同时还有前后搜索功能,除此之外,less在查看前不会加载整个文件。
基本格式 less [option] [filename]
-
-N显示每行的行号 -
-i忽略搜索时的大小写 -
-s将连续空行显示为一行 -
-m显示百分比常用操作命令:
-
/字符串 向下搜索“字符串”功能
-
?字符串 向上搜索“字符串”功能
-
n 重复前一个搜索
-
空格键 滚动一页
-
d 滚动半页
-
b 回溯一页
-
y 回溯一行
-
q 退出less命令
-
-
范例一:
less -Nm catalina.out
显示行号和百分比 -
范例二:
/detail或者?detail向前向后搜索”detail”
21、find命令实用实例总结
一、基于name查询文件
# find . -name tecmint.txt
# find /home -name tecmint.txt
# find /home -iname tecmint.txt
# find / -type d -name Tecmint
# find . -type f -name tecmint.php
# find . -type f -name "*.php"
22、二、基于权限查询文件
# find . -type f -perm 0777 -print
# find / -type f ! -perm 777
# find / -perm 2644
# find / -perm 1551
# find / -perm /u=s
# find / -perm /g+s
# find / -perm /u=r
# find / -perm /a=x
# find / -type f -perm 0777 -print -exec chmod 644 {};
# find / -type d -perm 777 -print -exec chmod 755 {};
# find . -type f -name "tecmint.txt" -execrm -f {} ;
# find . -type f -name "*.txt" -exec rm -f{} ;
# find . -type f -name "*.mp3" -exec rm -f{} ;
# find /tmp -type f -empty
# find /tmp -type d -empty
# find /tmp -type f -name ".*"
23、三、基于用户和组查询文件
# find / -user root -name tecmint.txt
# find /home -user tecmint
# find /home -group developer
# find /home -user tecmint -iname "*.txt"
24、基于时间查询文件或目录
# find / -mtime 50
# find / -atime 50
# find / -mtime +50 –mtime -100
# find / -cmin -60
# find / -mmin -60
# find / -amin -60
25、基于大小查询文件或目录
# find / -size 50M
# find / -size +50M -size -100M
# find / -size +100M -exec rm -rf {} ;
# find / -type f -name *.mp3 -size +10M -exec rm {} ;
26、使用mindepth和maxdepth限定搜索指定目录的深度
在root目录及其1层深的子目录中查找passwd. (例如root —level 1, and one sub-directory — level 2)
# find -maxdepth 2-name passwd
在root目录下及其最大两层深度的子目录中查找passwd文件. (例如 root — level 1, and two sub-directories — level 2 and 3 )
# find / -maxdepth 3-name passwd
在第二层子目录和第四层子目录之间查找passwd文件。
# find -mindepth 3-maxdepth 5 -name passwd
27、查找5个最大的文件
find . -type f -execls -s {} ; | sort -n -r | head -5
查找5个最小的文件
find . -type f -execls -s {} ; | sort -n | head -5
find . -not -empty-type f -exec ls -s {} ; | sort -n |head -5
28、查找所有的隐藏文件
find . -type f -name".*"
查找所有的隐藏目录
find -type d -name".*
29、下面的命令删除大于100M的*.zip文件。
find / -type f -name*.zip -size +100M -exec rm -i {} ;"
用别名rm100m删除所有大雨100M的*.tar文件。使用同样的思想可以创建rm1g,rm2g,rm5g的一类别名来删除所有大于1G,2G,5G的文件。
aliasrm100m="find / -type f -name *.tar -size +100M -exec rm -i {} ;"
# aliasrm1g="find / -type f -name *.tar -size +1G -exec rm -i {} ;"
# aliasrm2g="find / -type f -name *.tar -size +2G -exec rm -i {} ;"
# aliasrm5g="find / -type f -name *.tar -size +5G -exec rm -i {} ;"
30、将/etc/passwd,有出现 root 的行取出来
# grep root /etc/passwd
root:x:0:0:root:/root:/bin/bash
operator:x:11:0:operator:/root:/sbin/nologin
或
# cat /etc/passwd | grep root
root:x:0:0:root:/root:/bin/bash
operator:x:11:0:operator:/root:/sbin/nologin
31、将/etc/passwd,有出现 root 的行取出来,同时显示这些行在/etc/passwd的行号
# grep -n root /etc/passwd1:root:x:0:0:root:/root:/bin/bash30:operator:x:11:0:operator:/root:/sbin/nologin
32、将/etc/passwd,将没有出现 root 和nologin的行取出来
# grep -v root /etc/passwd | grep -v nologin root:x:0:0:root:/root:/bin/bash operator:x:11:0:operator:/root:/sbin/nologin
33、用 dmesg 列出核心信息,再以 grep 找出内含 eth 那行,要将捉到的关键字显色,且加上行号来表示:
[root@localhost ~]# dmesg | grep -n --color=auto 'eth'247:eth0: RealTek RTL8139 at 0xee846000, 00:90:cc:a6:34:84, IRQ 10248:eth0: Identified 8139 chip type 'RTL-8139C'294:eth0: link up, 100Mbps, full-duplex, lpa 0xC5E1305:eth0: no IPv6 routers present # 你会发现除了 eth 会有特殊颜色来表示之外,最前面还有行号喔!
34、根据文件内容递归查找目录
# grep ‘energywise’ * #在当前目录搜索带'energywise'行的文件 # grep -r ‘energywise’ * #在当前目录及其子目录下搜索'energywise'行的文件# grep -l -r ‘energywise’ * #在当前目录及其子目录下搜索'energywise'行的文件,但是不显示匹配的行,只显示匹配的文件
35、找出空白行:
[root@localhost ~]# grep -n '^$' regular_express.txt22:
36、不想要开头是英文字母
[root@localhost ~]# grep -n '^[^a-zA-Z]' regular_express.txt1
37、想要找出来,行尾结束为小数点 (.) 的那一行:
[root@localhost ~]# grep -n '\.$' regular_express.txt1
38、『至少两个 o 以上的字串』时,就需要 ooo* ,亦即是:
[root@localhost ~]# grep -n 'ooo*' regular_express.txt1
39、想要字串开头与结尾都是 g,但是两个 g 之间仅能存在至少一个 o ,亦即是 gog, goog, gooog.... 等等,那该如何?
[root@localhost ~]# grep -n 'goo*g' regular_express.txt18
40、如果我想要找出 g 开头与 g 结尾的行,当中的字符可有可无
[root@localhost ~]# grep -n 'g.*g' regular_express.txt1
41、要找出 g 后面接 2 到 5 个 o ,然后再接一个 g 的字串,他会是这样:
[root@localhost ~]# grep -n 'go\{2,5\}g' regular_express.txt18:google is the best tools for search keyword.
42、想要的是 2 个 o 以上的 goooo....g 呢?除了可以是 gooo*g ,也可以是:
[root@localhost ~]# grep -n 'go\{2,\}g' regular_express.txt18
43、打印所有包含NW或EA的行。如果不是使用egrep,而是grep,将不会有结果查出。
# egrep 'NW|EA' testfile
44、搜索所有包含一个或多个3的行。
# egrep '3+' testfile # grep -E '3+' testfile # grep '3\+' testfile
45、搜索所有包含0个或1个小数点字符的行。
# egrep '2\.?[0-9]' testfile # grep -E '2\.?[0-9]' testfile # grep '2\.\?[0-9]' testfile
46、搜索一个或者多个连续的no的行。
# egrep '(no)+' testfile # grep -E '(no)+' testfile # grep '\(no\)\+' testfile #3个命令返回相同结果,
47、如果你想在一个文件或者输出中找到包含星号字符的行
fgrep '*' /etc/profile for i in /etc/profile.d/*.sh ; do 或 grep -F '*' /etc/profile for i in /etc/profile.d/*.sh ; do
48、将/etc/passwd,有出现root的行取出来
# grep root /etc/passwd
或
# cat /etc/passwd | grep root
49、将/etc/passwd,有出现 root 的行取出来,同时显示这些行在/etc/passwd的行号
# grep -n root /etc/passwd1:root:x:0:0:root:/root:/bin/bash30:operator:x:11:0:operator:/root:/sbin/nologin
50、将/etc/passwd,将没有出现 root 的行取出来
# grep -v root /etc/passwdroot:x:0:0:root:/root:/bin/bash operator:x:11:0:operator:/root:/sbin/nologin
将/etc/passwd,将没有出现 root 和nologin的行取出来
# grep -v root /etc/passwd | grep -v nologin root:x:0:0:root:/root:/bin/bash operator:x:11:0:operator:/root:/sbin/nologin
用 dmesg 列出核心信息,再以 grep 找出内含 eth 那行,要将捉到的关键字显色,且加上行号来表示:
[root@localhost ~]# dmesg | grep -n --color=auto 'eth'247:eth0: RealTek RTL8139 at 0xee846000, 00:90:cc:a6:34:84, IRQ 10248:eth0: Identified 8139 chip type 'RTL-8139C'294:eth0: link up, 100Mbps, full-duplex, lpa 0xC5E1305:eth0: no IPv6 routers present # 你会发现除了 eth 会有特殊颜色来表示之外,最前面还有行号喔!
用 dmesg 列出核心信息,再以 grep 找出内含 eth 那行,在关键字所在行的前两行与后三行也一起捉出来显示
[root@localhost ~]# dmesg | grep -n -A3 -B2 --color=auto 'eth'245-PCI: setting IRQ 10 as level-triggered246-ACPI: PCI Interrupt 0000:00:0e.0[A] -> Link [LNKB] ...247:eth0: RealTek RTL8139 at 0xee846000, 00:90:cc:a6:34:84, IRQ 10248:eth0: Identified 8139 chip type 'RTL-8139C'249-input: PC Speaker as /class/input/input2250-ACPI: PCI Interrupt 0000:00:01.4[B] -> Link [LNKB] ...251-hdb: ATAPI 48X DVD-ROM DVD-R-RAM CD-R/RW drive, 2048kB Cache, UDMA(66) # 如上所示,你会发现关键字 247 所在的前两行及 248 后三行也都被显示出来! # 这样可以让你将关键字前后数据捉出来进行分析啦!
51、根据文件内容递归查找目录
# grep ‘energywise’ * #在当前目录搜索带'energywise'行的文件 # grep -r ‘energywise’ * #在当前目录及其子目录下搜索'energywise'行的文件# grep -l -r ‘energywise’ * #在当前目录及其子目录下搜索'energywise'行的文件,但是不显示匹配的行,只显示匹配的文件
52、字符类
符类的搜索:如果我想要搜寻 test 或 taste 这两个单字时,可以发现到,其实她们有共通的 't?st' 存在~这个时候,我可以这样来搜寻:
[root@localhost~]# grep -n 't[ae]st' regular_express.txt8:I can't finish the test.9:Oh! The soup taste good.
字符类的反向选择 [^] :如果想要搜索到有 oo 的行,但不想要 oo 前面有 g,如下 :
[root@localhost ~]# grep -n '[^g]oo' regular_express.txt2:apple is my favorite food.3:Football game is not use feet only.18:google is the best tools for search keyword.19:goooooogle yes!
53、行首与行尾字节 ^ $
行首字符:如果我想要让 the 只在行首列出呢? 这个时候就得要使用定位字节了!我们可以这样做:
[root@ocalhost ~]# grep -n '^the' regular_express.txt12:the symbol '*' is represented as start.
想要开头是小写字节的那一行就列出呢?可以这样:
[root@ocalhost ~]# grep -n '^[a-z]' regular_express.txt
2:apple is my favorite food.
4:this dress doesn't fit me.
10:motorcycle is cheap than car.
12:the symbol '*' is represented as start.
18:google is the best tools for search keyword.
19:goooooogle yes!
20:go! go! Let's go.
不想要开头是英文字母,则可以是这样:
[root@localhost ~]# grep -n '^[^a-zA-Z]' regular_express.txt1:"Open Source" is a good mechanism to develop programs.21:# I am VBird
想要找出来,行尾结束为小数点 (.) 的那一行:
[root@www ~]# grep -n '\.$' regular_express.txt1:"Open Source" is a good mechanism to develop programs.2:apple is my favorite food.3:Football game is not use feet only.4:this dress doesn't fit
找出空白行:
[root@www ~]# grep -n '^$' regular_express.txt22:
因为只有行首跟行尾 (^$),所以,这样就可以找出空白行啦!
需要找出 g??d 的字串,亦即共有四个字节, 起头是 g 而结束是 d ,我可以这样做:
[root@localhost ~]# grep -n 'g..d' regular_express.txt1:"Open Source" is a good mechanism to develop programs.9:Oh! The soup taste good.16:The world <Happy> is the same with "glad".
需要『至少两个 o 以上的字串』时,就需要 ooo* ,亦即是:
[root@www ~]# grep -n 'ooo*' regular_express.txt1:"Open Source" is a good mechanism to develop
想要字串开头与结尾都是 g,但是两个 g 之间仅能存在至少一个 o ,亦即是 gog, goog, gooog.... 等等,那该如何?
[root@localhost ~]# grep -n 'goo*g' regular_express.txt18:google is the best tools for search keyword.19:goooooogle yes!
想要找出 g 开头与 g 结尾的行,当中的字符可有可无
[root@localhost ~]# grep -n 'g.*g' regular_express.txt1:"Open Source" is a good mechanism to develop programs.14:The gd software is a library for drafting programs.18:google is the best tools for search keyword.19:goooooogle yes!20:go! go! Let's go.
想要找出『任意数字』的行?因为仅有数字,所以就成为:
[root@www ~]# grep -n '[0-9][0-9]*' regular_express.txt5:However, this dress is about $ 3183 dollars.15:You are the best is mean you are the no. 1.
假设要找到两个 o 的字串,可以是:
[root@www ~]# grep -n 'o\{2\}' regular_express.txt1:"Open Source" is a good mechanism to develop programs.2:apple is my favorite food.3:Football game is not use feet only.9:Oh! The soup taste good.18:google is the best tools for search ke19:goooooogle yes!
假设要找出 g 后面接 2 到 5 个 o ,然后再接一个 g 的字串,他会是这样:
[root@www ~]# grep -n 'go\{2,5\}g' regular_express.txt18:google is the best tools for search keyword.
如果想要的是 2 个 o 以上的 goooo....g 呢?除了可以是 gooo*g ,也可以是:
[root@www ~]# grep -n 'go\{2,\}g' regular_express.txt18:google is the best tools for search keyword.19:goooooogle yes!
54、扩展grep(grep -E 或者 egrep):
打印所有包含NW或EA的行。如果不是使用egrep,而是grep,将不会有结果查出。
# egrep 'NW|EA' testfile northwest NW Charles Main 3.0 .98 3 34 eastern EA TB Savage 4.4 .84 5 20
对于标准grep,如果在扩展元字符前面加\,grep会自动启用扩展选项-E。
#grep 'NW\|EA' testfile northwest NW Charles Main 3.0 .98 3 34eastern EA TB Savage 4.4 .84 5 20
搜索所有包含一个或多个3的行。
# egrep '3+' testfile # grep -E '3+' testfile # grep '3\+' testfile #这3条命令将会 northwest NW Charles Main 3.0 .98 3 34western WE Sharon Gray
搜索所有包含0个或1个小数点字符的行。
# egrep '2\.?[0-9]' testfile # grep -E '2\.?[0-9]' testfile # grep '2\.\?[0-9]' testfile #首先含有2字符,其后紧跟着0个或1个点,后面再是0和9之间的数字。 western WE Sharon Gray 5.3 .97
搜索一个或者多个连续的no的行。
# egrep '(no)+' testfile # grep -E '(no)+' testfile # grep '\(no\)\+' testfile #3个命令返回相同结果, northwest NW Charles Main 3.0 .98
如果你想在一个文件或者输出中找到包含星号字符的行
fgrep '*' /etc/profile for i in /etc/profile.d/*.sh ; do 或 grep -F '*' /etc/profile for i in /etc/profile.d/*.sh ; do
55、
56、
57、
58、
59、
60、
61、
62、
63、
64、
65、
66、
67、
68、
69、
70、
71、
72、
参考链接 : https://mp.weixin.qq.com/s/6VYDEf8Wbd28T2QMVEMp1g















 1684
1684











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









