







创建数据库
Create database ‘database_name’;
查看数据库
show database_name;
查看数据库创建语句
show create database db_name;
删除数据库
drop database db_name;
修改数据库
Alter database db_name new options;
For example
aleter database db1 default charset GBK;
创建表
create table student(
name varchar(20),
gender enum(‘male’, ‘female’, ’secret’),
age tinyint,
height float
);
查看表
show tables;
模糊匹配查询
关键字: like
%:可以代表任意字符
_:下划线,可以代表任意的当个字符
表名模糊匹配
show tables like ‘class_%’;(所有以class开头的表面)
内容模糊匹配
select * from student where name like ‘周%’;(所有以周开头的名字)
select * from student where name like ‘%国%’;(所有包含国自的名字)
select * from student where name like ‘%%军’;(所有军字结尾的名字)
删除表
drop table table_name;
Drop table if exists table_name;(如果表存在则删除)
修改数据表
改名关键字:rename
增加:add
删除:drop
重命名:change
修改:modify
关键字alter
alter table 表名 子命令语句
修改表名
alter table table_name rename to new_table_name;
新方法
rename table table_name to new_table_name;
新增加一列
alter table table_name add 新字段名 字段类型
alter table student add score tinyint;
删除一列
alter table table name drop field_name
修改字段类型
alter table table_name modify field_name 新的字段类型
alter table student modify name varchar(50);
修改字段的枚举值
alter table student change gender sex enum(‘male’, ‘female’) after score;
修改表选项
alter table 表名 新的表选项
alter table mg_teacher default charset utf8;
数据操作
插入数据
Insert into 表名(字段列表) values(值列表) #当插入全部值的时候字段列表可以省略
一次插入多条数据
insert into student(field1, field2, field3) values
(value1, value2, value3),
(value1, value2, value3),
(value1, value2, value3);
删除数据
delete from 表名[删除条件]
delete from student where score<=90;
修改数据
update table_name set 字段1=新值1,字段2=值2…[修改条件];
Update student set age. = age + 1;
特殊查询
什么是索引?
先来看一条select语句:
select * from student where score >= 97.5;
此时,如果数据库从第1条记录开始遍历查询,直到一个一个的找到分数为97.5分的学生,效率很显然很低下!但是,此时如果在score字段上加上一个索引,此时就可以极大的加快数据表的查询速度!
索引分类:
普通索引
语法为:
key(字段名1,字段名2……)或index(字段名1,字段名2……)
唯一键索引
其实就是唯一键
unique key(字段名1,字段名2……)
主键索引
其实就是主键
primary key(字段名1,字段名2……)
例子
create table suoyin(
a int,
b int,
c int,
key(a), — 普通索引
unique key(b), —唯一索引
primary key(c) — 主键索引
);
缺点?
- 占用一定的磁盘空间
- 索引在提高查询速度的同时,也降低了增删改的速度
联合查询
union
select 语句1
union[union选项]
select 语句2
所谓的联合查询就是将多个查询结果纵向上拼接,所有查询语句的字段数量应该是一致,比如,不能一个3列,一个5列!
用于相同的两个表相同的字段进行拼接查询
交叉连接查询
cross join
交叉连接是最容易理解的,就是从一张表的每一条记录去连接另外一张表的每一条记录,并且所有的记录都会被保存下来,就是对两张表做笛卡尔积!
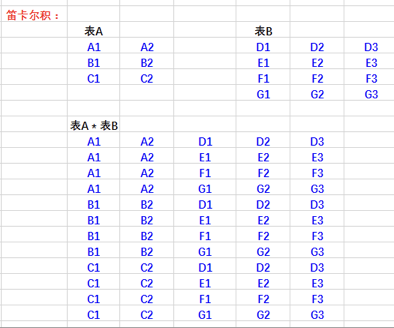
假如表A有m条记录,表B有n条记录,它们做笛卡尔积(交叉连接)的结果一共就有m*n条记录!
Select * from A cross join B;
内连接查询
inner join
内连接的含义就是:
数据在左表存在,同时在右表又有相对应的匹配的结果才会被保存,如果没有匹配上,我们就认为该条记录没有意义,就不会被保存![如果有一方的字段的值是空的时候会忽略]
上面叫匹配?就是存在某种关系能够使得两张表彼此识别自己,体现在语法上,往往就是两张表中具有相同的某个字段值!
select * from 左表 [inner] join 右表 on 左表名.字段 = 右表名.字段名
左外连接
left join
跟内连接一样,同样是拿左表的每一个记录按照on后面的条件去匹配右表的每一条记录,如果匹配成功,就保存两个表的所有的记录,如果匹配失败(这里的匹配失败是指左表的某条记录跟右表的所有记录进行匹配的时候,没有一条是成功的!),此时,依然保留左表的这条记录,右表的记录全部为NULL,此时左表也叫做主表!
右外连接
right outer join,其中这里的outer可以省略!所以,右外连接也通常简称右连接
跟内连接一样,同样是拿左表的每一个记录按照on后面的条件去匹配右表的每一条记录,如果匹配成功,就保存两个表的所有的记录,如果匹配失败(这里的匹配失败是指左表的某条记录跟右表的所有记录进行匹配的时候,没有一条是成功的!),此时,依然保留右表的这条记录,左表的记录全部为NULL,此时右表也叫做主表!
子查询
select * from student where score = (select max(score) from student);
select * from student where home in (select name from home_in_sky);
select * from student where (age, score) = (select max(age), max(score) from student);
exists 子查询
exists子查询主要是用来判断,返回一个布尔值:true或false!
如果exists后面的查询语句有结果集返回(查询到了记录),返回真,否则就返回假!
所以,exists子查询的目的不是为了得到结果集,而是为了判断后面的查询语句是否查询到了记录!
select exists(select * from user where name= ‘abc’ and password = ‘123456’)














 220
220











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









