







前言:
SQL语句的解析顺序
1. FROM FROM后面的表标识了这条语句要查询的数据源。和一些子句如,(1-J1)笛卡尔积,(1-J2)ON过滤,(1-J3)添加外部列,所要应用的对象。FROM过程之后会生成一个虚拟表VT1。
(1-J1)笛卡尔积 这个步骤会计算两个相关联表的笛卡尔积(CROSS JOIN) ,生成虚拟表VT1-J1。
(1-J2)ON过滤 这个步骤基于虚拟表VT1-J1这一个虚拟表进行过滤,过滤出所有满足ON 谓词条件的列,生成虚拟表VT1-J2。
(1-J3)添加外部行 如果使用了外连接,保留表中的不符合ON条件的列也会被加入到VT1-J2中,作为外部行,生成虚拟表VT1-J3。
2. WHERE 对VT1过程中生成的临时表进行过滤,满足where子句的列被插入到VT2表中。
3. GROUP BY 这个子句会把VT2中生成的表按照GROUP BY中的列进行分组。生成VT3表。
4. HAVING 这个子句对VT3表中的不同的组进行过滤,满足HAVING条件的子句被加入到VT4表中。
5. SELECT 这个子句对SELECT子句中的元素进行处理,生成VT5表。
(5-1)计算表达式 计算SELECT 子句中的表达式,生成VT5-1
(5-2)DISTINCT 寻找VT5-1中的重复列,并删掉,生成VT5-2
(5-3)TOP 从ORDER BY子句定义的结果中,筛选出符合条件的列。生成VT5-3表ORDER BY 从VT5-3中的表中,根据ORDER BY 子句的条件对结果进行排序,生成VC6表。1.连接查询
数据库中的连接分为:内连接、自然连接、外连接;(外连接又分为:左外连接,右外连接和全外连接)
自然连接(natural join):
自然连接是一种特殊的等值连接,他要求两个关系表中进行比较的必须是相同的属性列,无须添加连接条件,并且在结果中消除重复的属性列。
内连接(inner join):
指连接结果仅包含符合连接条件的行,参与连接的两个表都应该符合连接条件。
(内连接基本与自然连接相同,不同之处在于自然连接要求是同名属性列的比较,而内连接则不要求两属性列同名,可以用on来指定某两列字段相同的连接条件)
自然连接,内连接时某些属性值不同则会导致这些元组会被舍弃,那如何保存这些会被丢失的信息呢,外连接就解决了相应的问题。
外连接:
连接结果不仅包含符合连接条件的行同时也包含自身不符合条件的行。包括左外连接、右外连接和全外连接。
左外连接:
左边表数据行全部保留,右边表保留符合连接条件的行
右外连接:
右边表数据行全部保留,左边表保留符合连接条件的行
全外连接:
左外连接 union右外连接
例子:
表TESTA,TESTC,TESTD各有A, B两列
TESTB有A,C两列
首先做个全表查询(笛卡尔积)
SELECT * FROM TESTA,TESTB;

一、自然连接
SELECT * FROM TESTA NATURAL JOIN TESTB;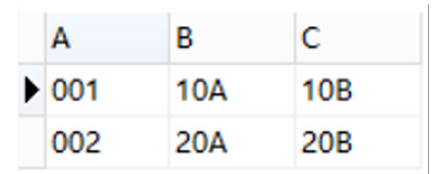
二、内连接:这边我们演示的是等值连接
方式一:SELECT * FROM TESTA a ,TESTC c WHERE a.A=c.A;
方式二:SELECT * FROM TESTA a INNER JOIN TESTC c ON (a.A=c.A);结果表如下:

三、外连接:
1.左外连接 left outer join 或者 left join
左外连接就是在等值连接的基础上加上主表中的未匹配数据,例:
写法一:SELECT * FROM TESTA a LEFT OUTER JOIN TESTC c ON (a.A=c.A);
写法二:SELECT * FROM TESTA a LEFT JOIN TESTC c ON (a.A=c.A);
ORACLE特有写法:SELECT * FROM TESTA a,TESTC c WHERE a.A=c.A(+);结果表如下:

2.右外连接 right outer join 或者 right join
右外连接是在等值连接的基础上加上被连接表的不匹配数据
写法一:SELECT * FROM TESTA a RIGHT OUTER JOIN TESTC c ON (a.A=c.A);
写法二:SELECT * FROM TESTA a RIGHT JOIN TESTC c ON (a.A=c.A);
ORACLE特有写法:SELECT * FROM TESTA a,TESTC c WHERE a.A(+)=c.A;结果表如下:

3.全外连接 full outer join 或者 full join
全外连接是在等值连接的基础上将左表和右表的未匹配数据都加上
写法一:SELECT * FROM TESTA a FUll OUTER JOIN TESTC c ON (a.A=c.A);
写法二:SELECT * FROM TESTA a FUll JOIN TESTC c ON (a.A=c.A);
等价写法:
SELECT * FROM TESTA a LEFT JOIN TESTC c ON (a.A=c.A)
UNION
SELECT * FROM TESTA a RIGHT JOIN TESTC c ON (a.A=c.A);结果表如下:


2.连接原理
1.排序 - - 合并连接(Sort Merge Join, SMJ)
内部连接过程:
1) 首先生成row source1需要的数据,然后对这些数据按照连接操作关联列进行排序。
2) 随后生成row source2需要的数据,然后对这些数据按照与sort source1对应的连接操作关联列进行排序。
3) 最后两边已排序的行被放在一起执行合并操作,即将2个row source按照连接条件连接起来
2.嵌套循环(Nested Loops, NL)
这个连接方法有驱动表(外部表)的概念。其实,该连接过程就是一个2层嵌套循环,所以外层循环的次数越少越好,这也就是我们为什么将小表或返回较小 row source的表作为驱动表(用于外层循环)的理论依据。但是这个理论只是一般指导原则,因为遵循这个理论并不能总保证使语句产生的I/O次数最少。有时 不遵守这个理论依据,反而会获得更好的效率。如果使用这种方法,决定使用哪个表作为驱动表很重要。有时如果驱动表选择不正确,将会导致语句的性能很差。
内部连接过程:
Row source1的Row 1 —— Probe ->Row source 2
Row source1的Row 2 —— Probe ->Row source 2
……
Row source1的Row n —— Probe ->Row source 2
3.哈希连接(Hash Join, HJ)
这种连接是在oracle 7.3以后引入的,从理论上来说比NL与SMJ更高效,而且只用在CBO优化器中。
较小的row source被用来构建hash table与bitmap,第2个row source被用来被hansed,并与第一个row source生成的hash table进行匹配,以便进行进一步的连接。Bitmap被用来作为一种比较快的查找方法,来检查在hash table中是否有匹配的行。特别的,当hash table比较大而不能全部容纳在内存中时,这种查找方法更为有用。这种连接方法也有NL连接中所谓的驱动表的概念,被构建为hash table与bitmap的表为驱动表,当被构建的hash table与bitmap能被容纳在内存中时,这种连接方式的效率极高。
RBO: Rule-Based Optimization 基于规则的优化器
CBO: Cost-Based Optimization 基于代价的优化器
RBO自ORACLE
6以来被采用,一直沿用至ORACLE 9i. ORACLE
10g开始,ORACLE已经彻底丢弃了RBO,它有着一套严格的使用规则,只要你按照它去写SQL语句,无论数据表中的内容怎样,也不会影响到你的“执行计划”,也就是说RBO对数据不“敏感”。
CBO优化器根据SQL语句生成一组可能被使用的执行计划,估算出每个执行计划的代价,并调用计划生成器(Plan
Generator)生成执行计划,比较执行计划的代价,最终选择选择一个代价最小的执行计划。查询优化器由查询转换器(Query
Transform)、代价估算器(Estimator)和计划生成器(Plan Generator)组成。4.总结
排序 - - 合并连接(Sort Merge Join, SMJ):
a) 对于非等值连接,这种连接方式的效率是比较高的。
b) 如果在关联的列上都有索引,效果更好。
c) 对于将2个较大的row source做连接,该连接方法比NL连接要好一些。
d) 但是如果sort merge返回的row source过大,则又会导致使用过多的rowid在表中查询数据时,数据库性能下降,因为过多的I/O.
嵌套循环(Nested Loops, NL):
a) 如果driving row source(外部表)比较小,并且在inner row source(内部表)上有唯一索引,或有高选择性非唯一索引时,使用这种方法可以得到较好的效率。
b) NESTED LOOPS有其它连接方法没有的的一个优点是:可以先返回已经连接的行,而不必等待所有的连接操作处理完才返回数据,这可以实现快速的响应时间。
哈希连接(Hash Join, HJ):
a) 这种方法是在oracle7后来引入的,使用了比较先进的连接理论,一般来说,其效率应该好于其它2种连接,但是这种连接只能用在CBO优化器中,而且需要设置合适的hash_area_size参数,才能取得较好的性能。
b) 在2个较大的row source之间连接时会取得相对较好的效率,在一个row source较小时则能取得更好的效率。
c) 只能用于等值连接中
3.连接建议
3.1、建议大方向
1.减小I/O次数
2.不必要的情况下,尽量避免全表扫描3.2、如何避免全表扫描:
1.应考虑在 where 及 order by 涉及的列上建立索引
2.避免在 where 子句中对字段进行 null 值判断(设置默认值)
3.避免在 where 子句中使用!=或<>操作符
4.避免在 where 子句中使用 or 来连接条件(可以使用s1 union all s2)
5.避免在 where 子句中使用like '%a%'
6.避免在where子句中对字段进行函数操作
其他:
1.索引并不是越多越好,会降低了 insert 及 update 的效率
2.尽量使用数字型字段,若只含数值信息的字段尽量不要设计为字符型,这会降低查询和连接的性能,并会增加存储开销。这是因为引擎在处理查询和连接时会逐个比较字符串中每一个字符,而对于数字型而言只需要比较一次就够了














 1478
1478

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









