






目的是什么?
将java文件编译成class文件.
编译过程做了什么?
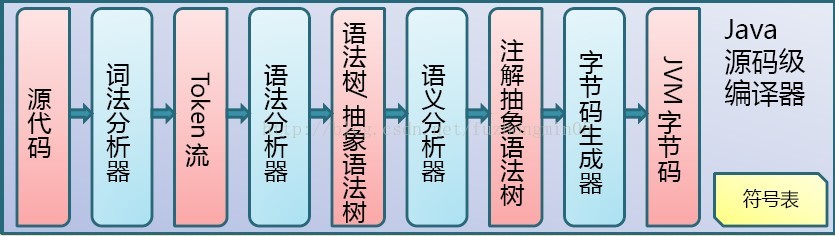
词法分析
词法分析主要是将字符串转成token序列;java文件终归来说,与文本文件的实质是一样的.而不同的是,它会将其词语进行编译转换,以达到:JVM能识别/占用空间更少/加载速度更快.
语法分析
将词法分析的token序列组织生成语法树.在这个过程,会检查编写的代码是否符合规范,如:类文件是否有class/interface这样的关键字;方法的代码是否有返回类型;逻辑符号是否使用规范等.
输入到符号表
enter是将符号输入到符号表.通常包括确定类的超类型和接口、根据需要添加默认构造器、将类中出现的符号输入类自身的符号表中等。
注解处理
注解是一个比较特殊的类,编译器会对它进行特殊的处理,然后再进行词法分析/语法分析/语义分析/生成字节码的过程.
语义分析
analyse是基于抽象语法树进行一系列的语义分析,包括将语法树中的名字、表达式等元素与变量、方法、类型等联系到一起;检查变量前是否申明;推导泛型方法的类型参数;检查类型匹配;进行常量折叠;检查所有语句都可到达;检查所有exception都被捕获或抛出;检查变量的确定性赋值;将泛型转为java;精减语法结构等.
生成字节码
在完成了语义分析后,开始生成class文件:首先将实例成员初始化器收集到构造器中,将静态成员初始化器收集为<clinit>();接着将抽象语法树生成字节码,采用的方法为后序遍历语法树,并进行最后的少量代码转换(如将string转变为stringBuffer操作);最后从符号表生成class文件。
编译后的结果是什么?
结构信息
包括 class 文件格式版本号及各部分的数量与大小的信息。
元数据
包含类/继承的超类/实现的接口的声明信息、域与方法声明信息和常量池,还有就是锁信息.
方法信息
对应 Java 源码中语句和表达式对应的信息。包含字节码、异常处理器表、求值栈与局部变量区大小、求值栈的类型记录、调试符号信息。
对于编码过程能做什么?
类文件不宜过大,因为这样编译过程会比较慢,而且class文件会比较大.从而影响到后面JVM的加载过程和内存分配.并且,class文件大小也是限制的.
方法的逻辑代码不宜太复杂,因为这样会让语法树更加复杂.比如:单个方法中的if/for等逻辑太多,会让方法语法树更复杂.因此,我们应该将这种方法分析成多个简洁的小方法.这样的话,单个语法树会很简单,同时方法的重用性更高. 通常我们在使用的类的时候,通常是以方法为使用单位.并且,方法的大小也是有限制的.
方法中使用的定义的常量来计算出另一个常量.而不是直接编码一个固定的数字或字符串.因为在编译的过程中,会对这类代码进行优化,在不影响性能的情况,使得代码更灵活.如:
static final int a = 3;
static final int b = 2;
void method(){
int c = a*b; // 编译后的结果int = 6;
}方法的重载,编译期的多态.
泛型的编译处理.在编译的过程中,会进行"类型擦出".泛型的目的是为了提高代码的重用性,而在具体的方法使用中,是需要指定泛型的类型.
检查异常也就是在编译期处理的,否则会不通过.
注: 通常编译期能出现的问题,基本上IDE都会提示,进而在编写时就会处理掉了.这也是我们对编译期过程并不太注重的一个原因.
转载于:https://blog.51cto.com/881206524/1901182















 493
493











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









