







在 hue(02)、Hue集成Hadoop集群(HDFS和YARN) 中我们在hue中集成了hdfs和yarn,可以很方便的在hue中操作hdfs中的数据和查看MapReduce的作业执行情况。本文我们将在hue中集成hive数据仓库,用替代hive自己的hwi服务,可以很方便的在hue中进行hive的sql查询等操作。
一、环境准备
1.hadoop集群服务
2.hive-mysql元数据库服务
3.hive服务
4.hue4.1
二、集成配置
打开hue的/desktop/conf/目录下的 pseudo-distributed.ini文件
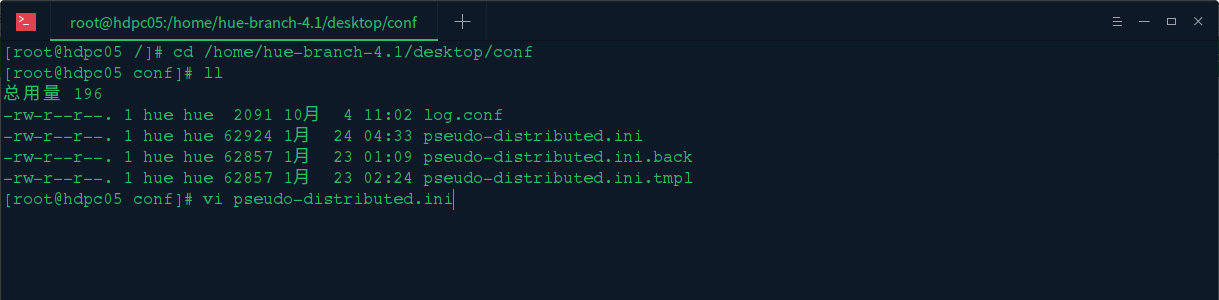
编辑pseudo-distributed.ini文件 ,找到[beeswax]这一节,修改信息连接为hdpc01的机器上的Hive数据仓库服务,修改信息如下:
hive_server_host=hdpc01
hive_server_port=10000
server_conn_timeout=120
list_partitions_limit=10000
query_partitions_limit=10
download_row_limit=100000
max_number_of_sessions=10
三、集成准备
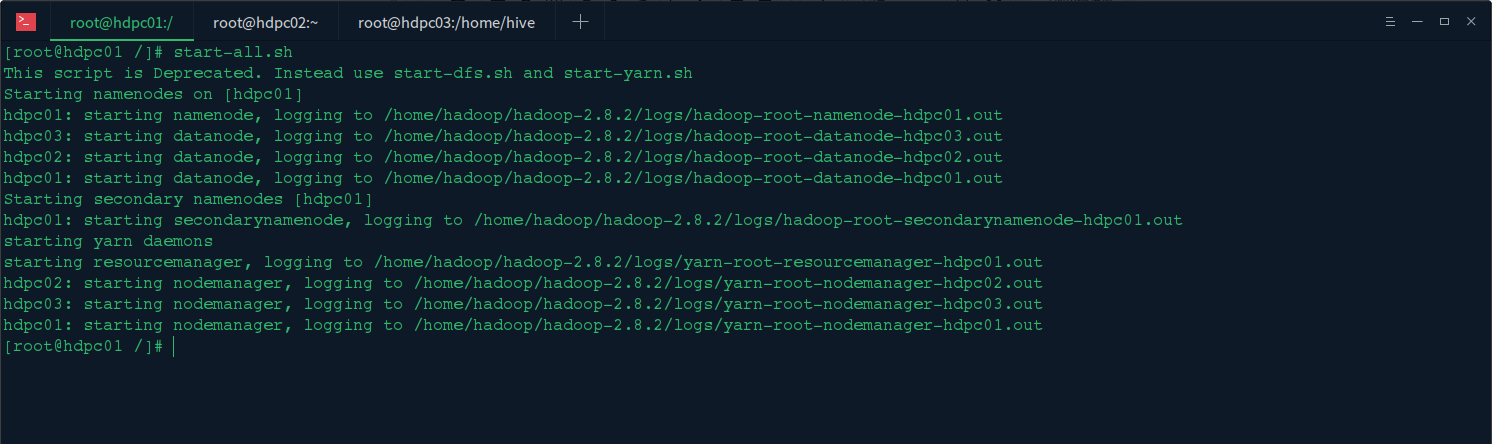
1.启动hadoop集群
启动hadoop三台机器,然后在主节点机器上启动hadoop集群:start-all.sh
2.启动Hiveserver服务
在hive机器上启动hiveserver服务:hive --service hiveserver2 或者hive --service hiveserver2 &
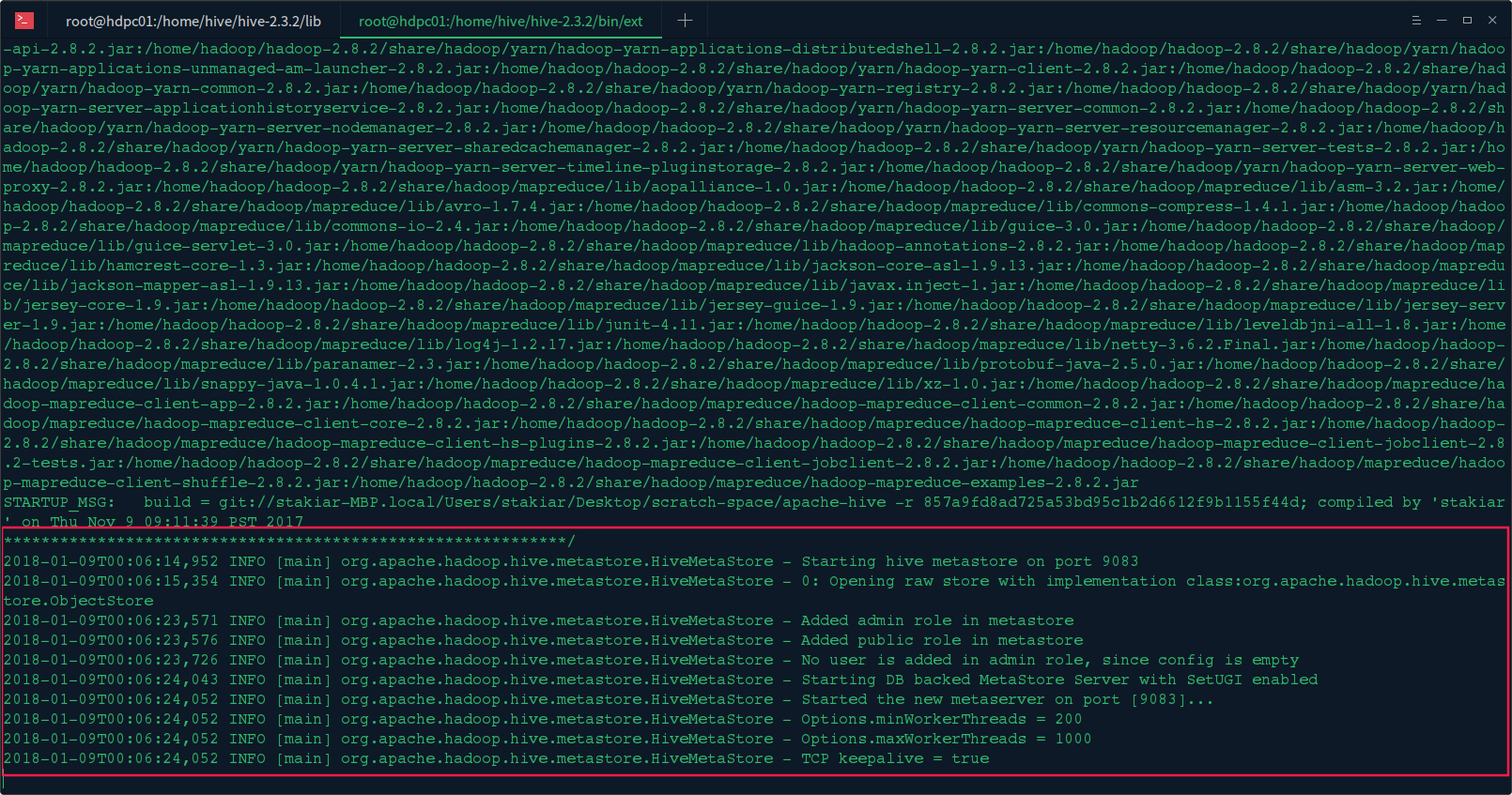
3.启动Hive Metastore服务
在hive机器上启动Hive Metastore服务:hive --service metastore或者hive --service metastore &

看到如下信息,说明启动完成:
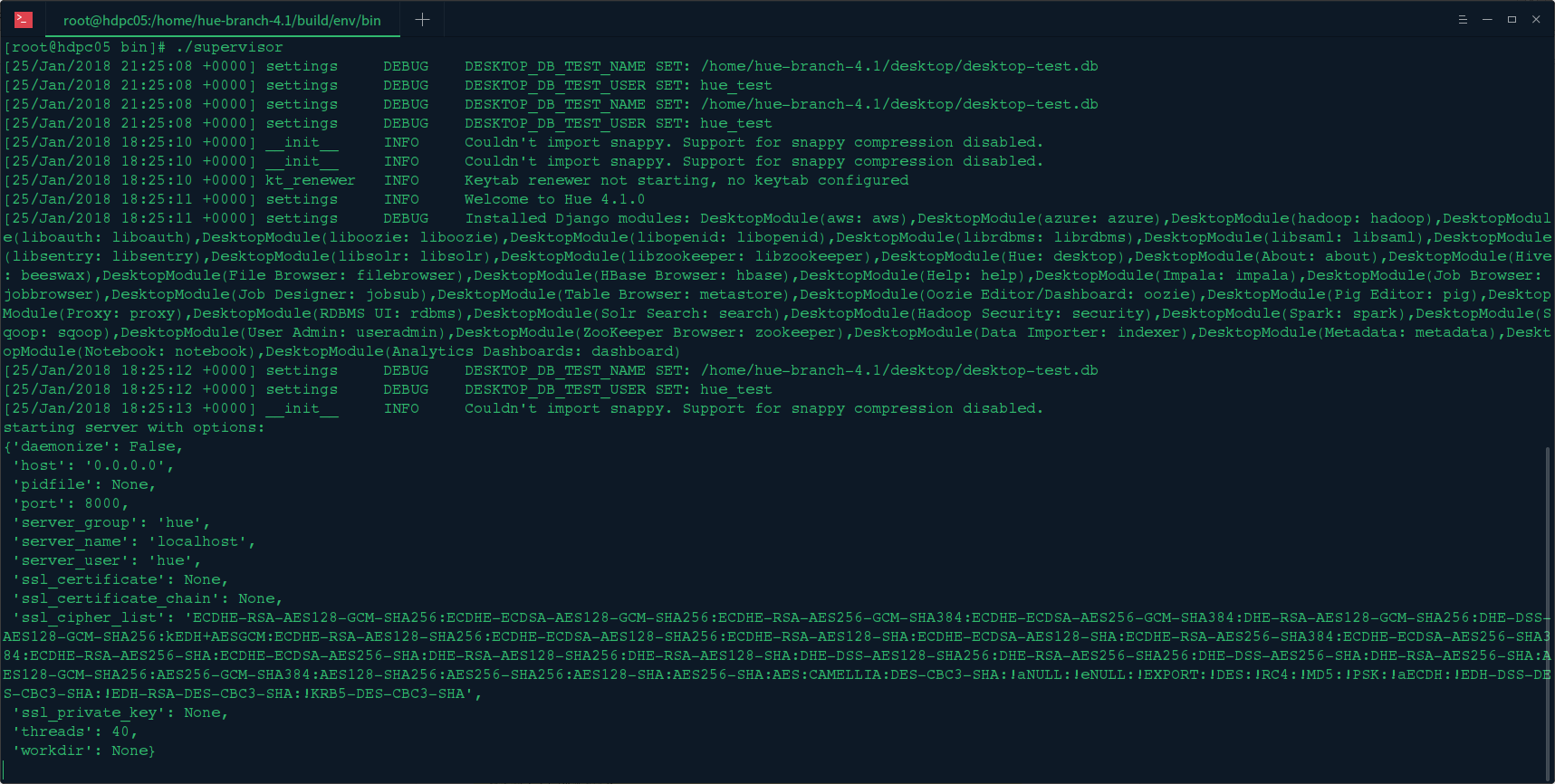
4.启动Hue服务
在hue的/bulid/env/bin/目录下执行./supervisor 命令启动hue服务
5.验证启动
在终端输入jps -ml查看:

可以看到hadoop集群个hive服务启动都正常
四、集成验证及简单使用
登陆Hue服务,点击hive可以看到hive的默认default的库,和我们之前使用hive时建的表
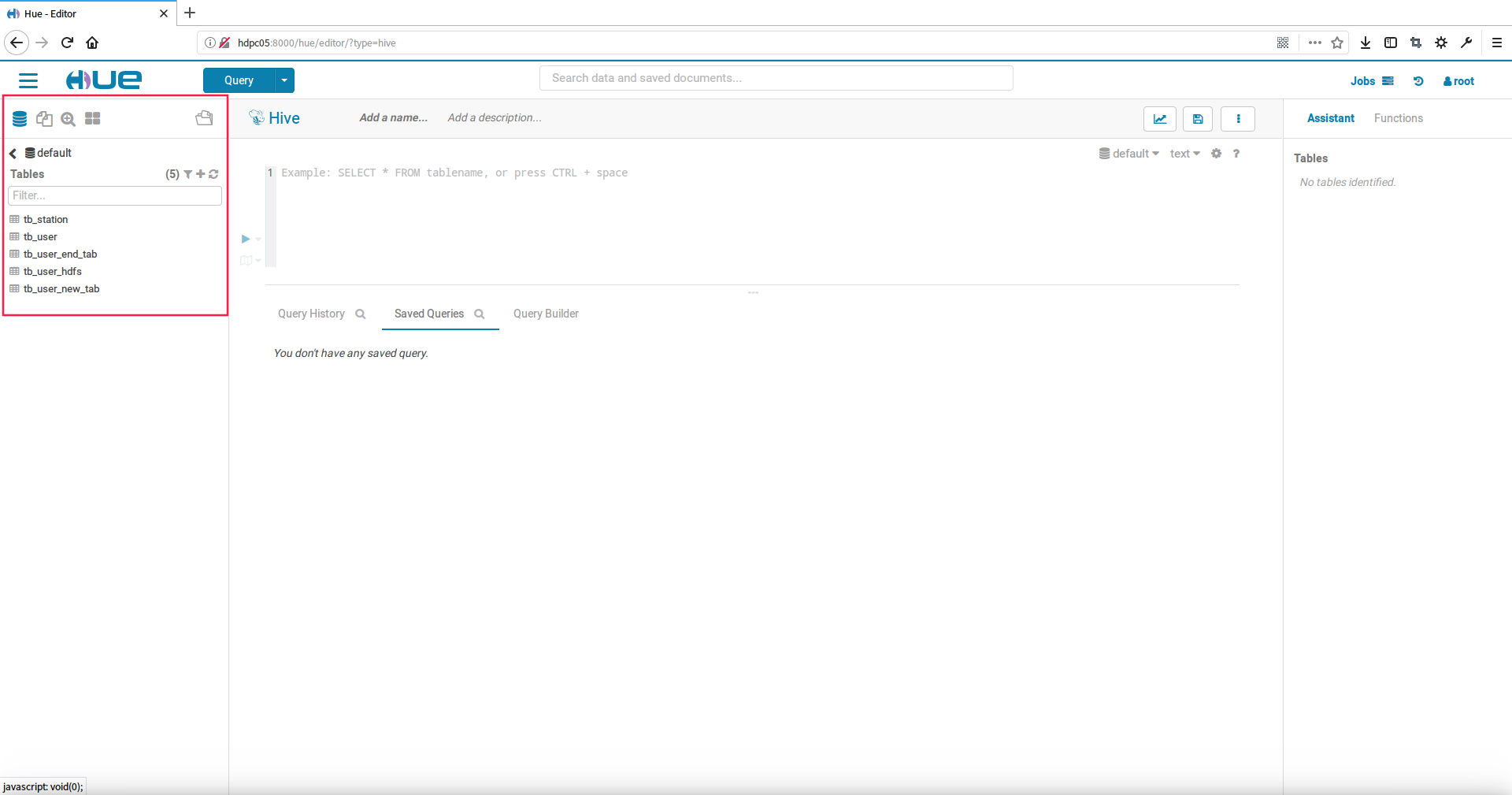
查看hive表的详细信息,右击表点击Open in Browser在右边的Table Browser视图中,可以看到表的结构及字段自定义、部分数据等
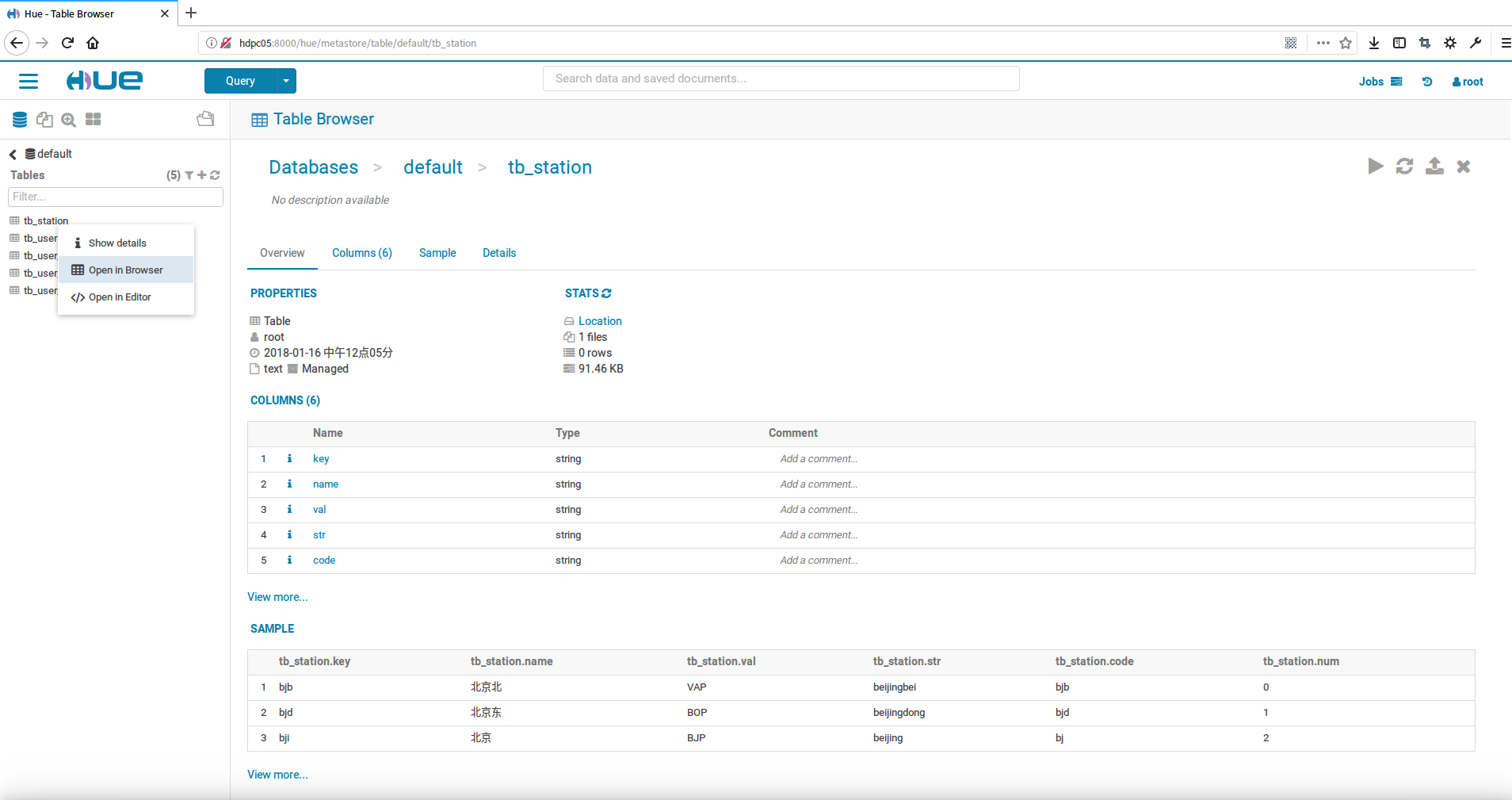
点击columns标签可以看到表字段的详细信息
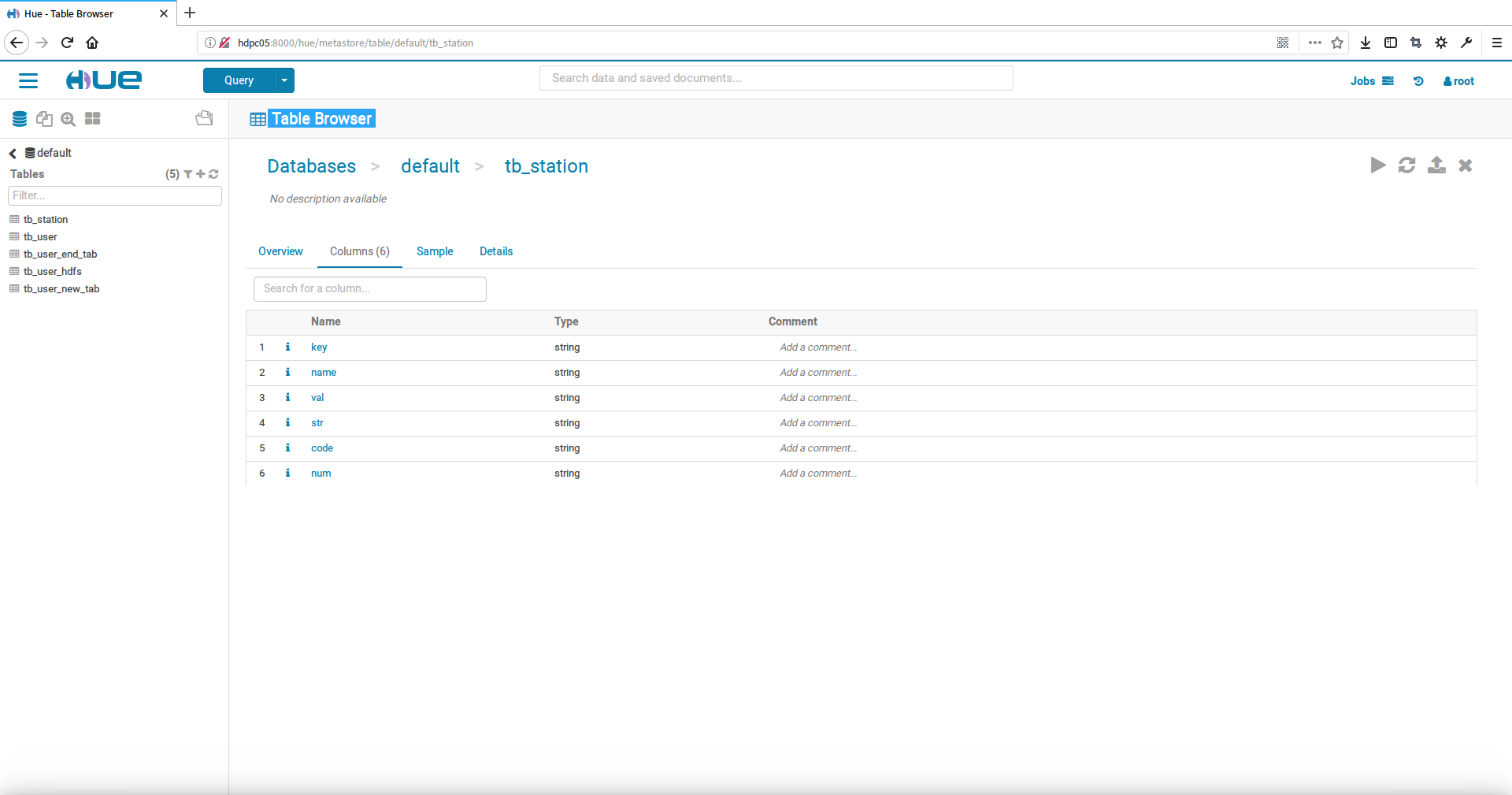
点击sample标签可以看到该表全部的数据信息
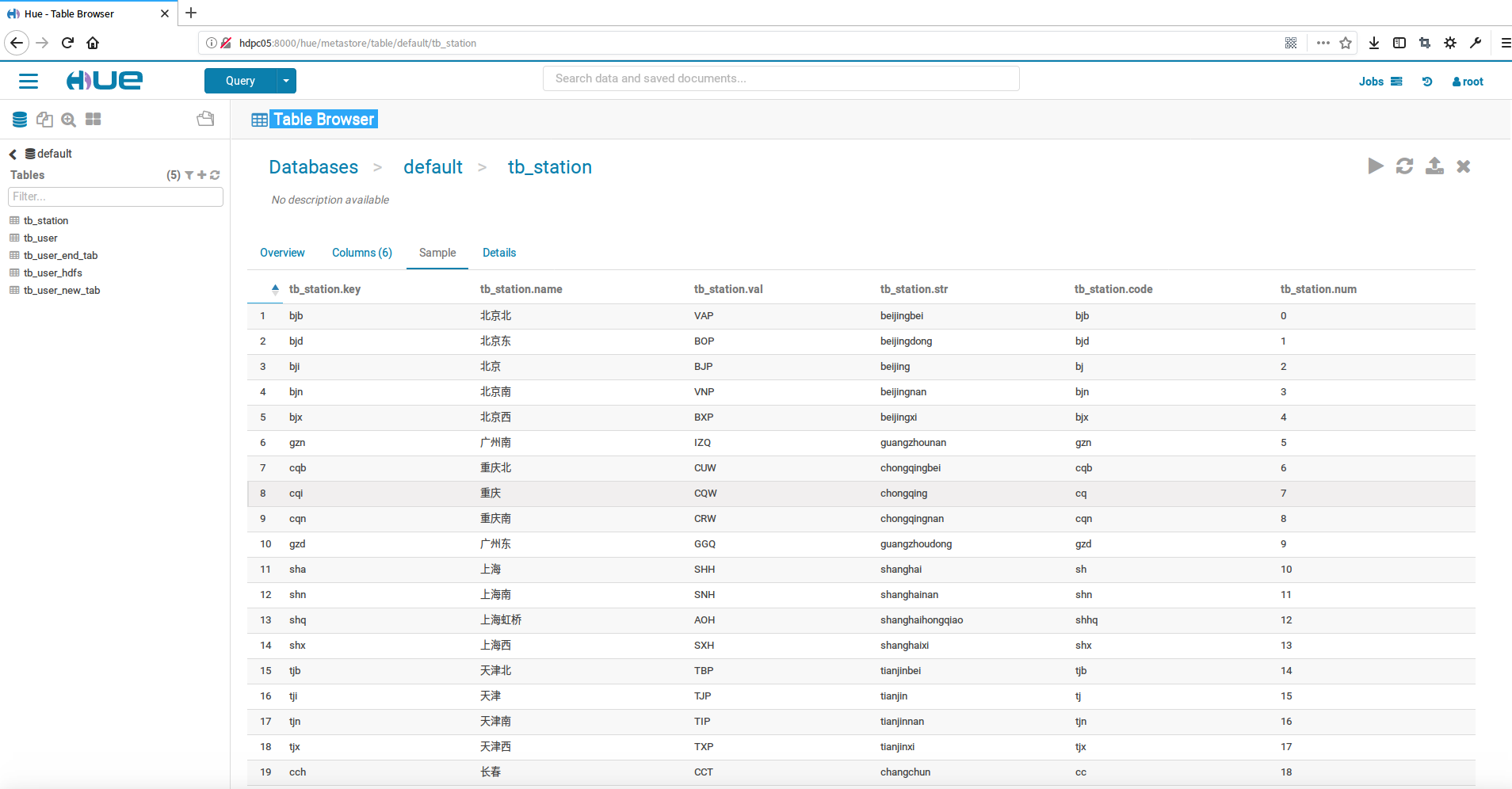
使用hue中的hive查询器查询hive表中的数据
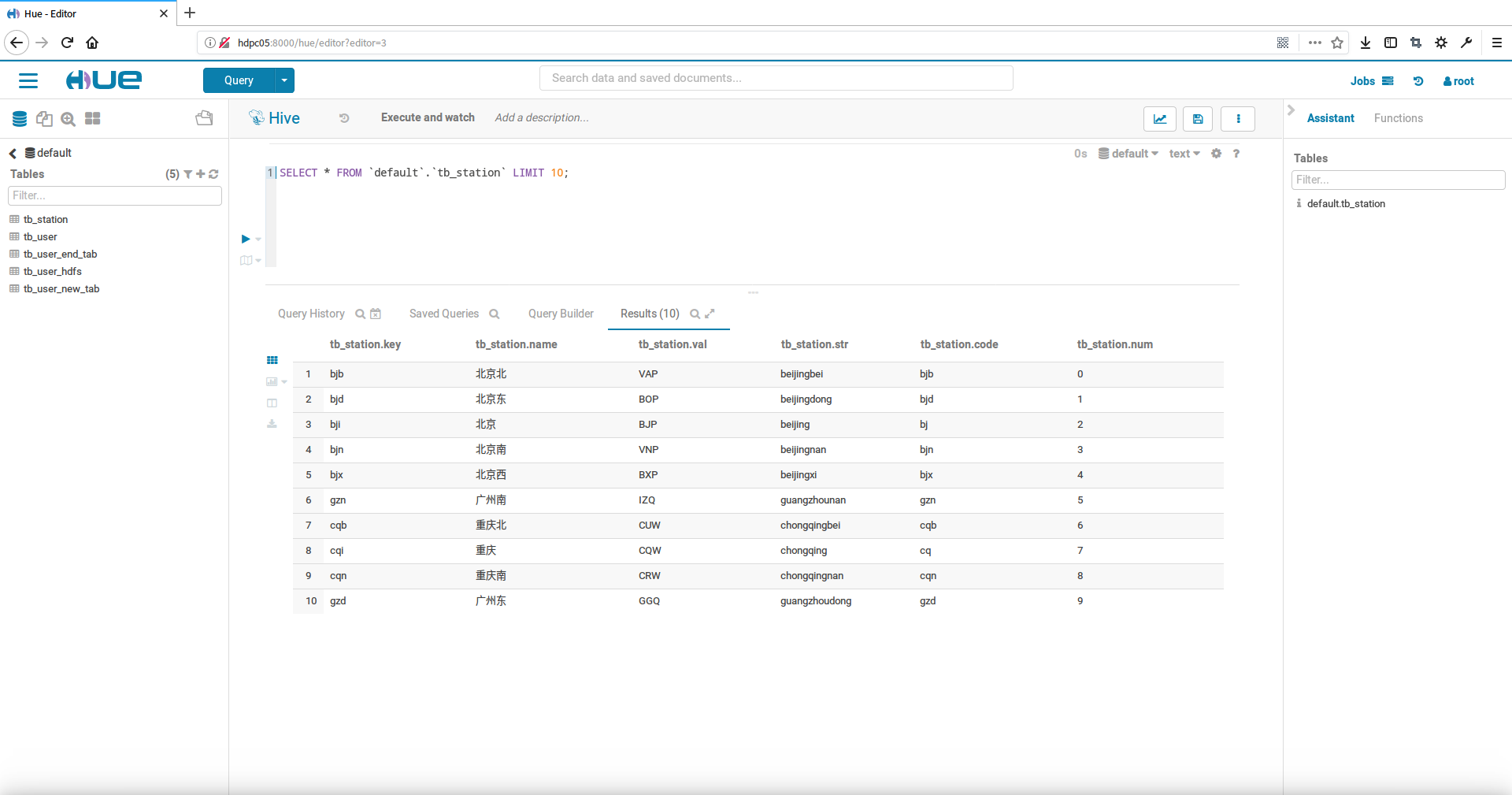
在hue中还有更多可以操作hive的方式,大家可以自己尝试别的,本文先这么多基本的操作
五、问题总结
1.hue提示Could not start SASL: Error in sasl_client_start (-4) SASL(-4)的异常

问题原因:因为系统缺少了相关的依赖
解决办法:我们在hue所在主机安装以下的依赖
yum install cyrus-sasl-plain cyrus-sasl-devel cyrus-sasl-gssapi

6、文末总结
文本的使用hue连接操作hive数据仓库比较之前hive自己的hwi功能更强大,同时hue支持更多的应用,集成在一起更像是一个操作、监控为一体的平台化的工具,在后面的文章我们还继续去使用hue集成HBase、mysql、oracle等

















 1421
1421

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









