






Frequent Pattern Tree(频繁模式树)是Jiawei Han在2004年的文章《Mining Frequent Patterns without Candidate Generation 》中提出的。
————————————————————————————————————————————————————
以下给出一些定义:
设项集(set of items)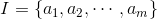
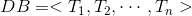
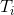
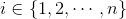
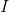
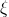
频繁模式树就是要找到交易数据库中的频繁模式。
————————————————————————————————————————————————————
样例:
设项集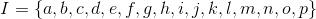
最小支持度阈值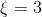
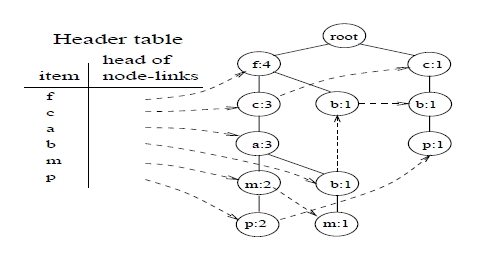
构造频繁模式树仅仅须要扫描(scan)交易数据库两次。
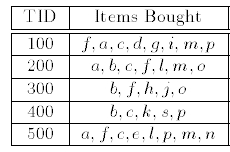
第一次:扫描数据库。对当中的每个项进行计数,得到一个list of frequent items(频繁项的列表) 。比如,项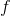
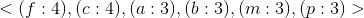
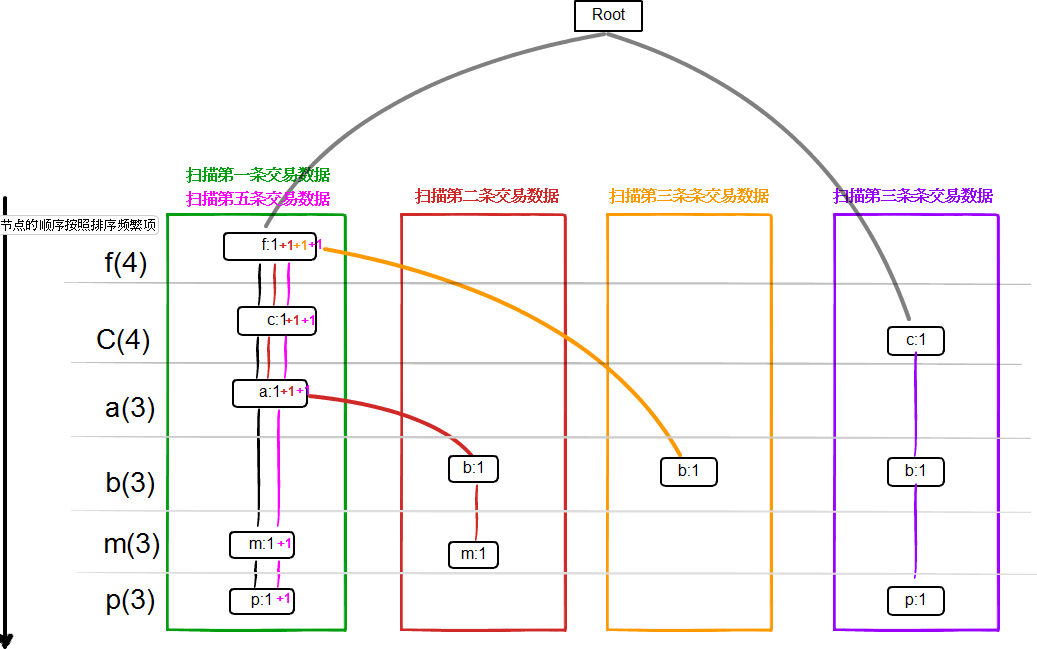
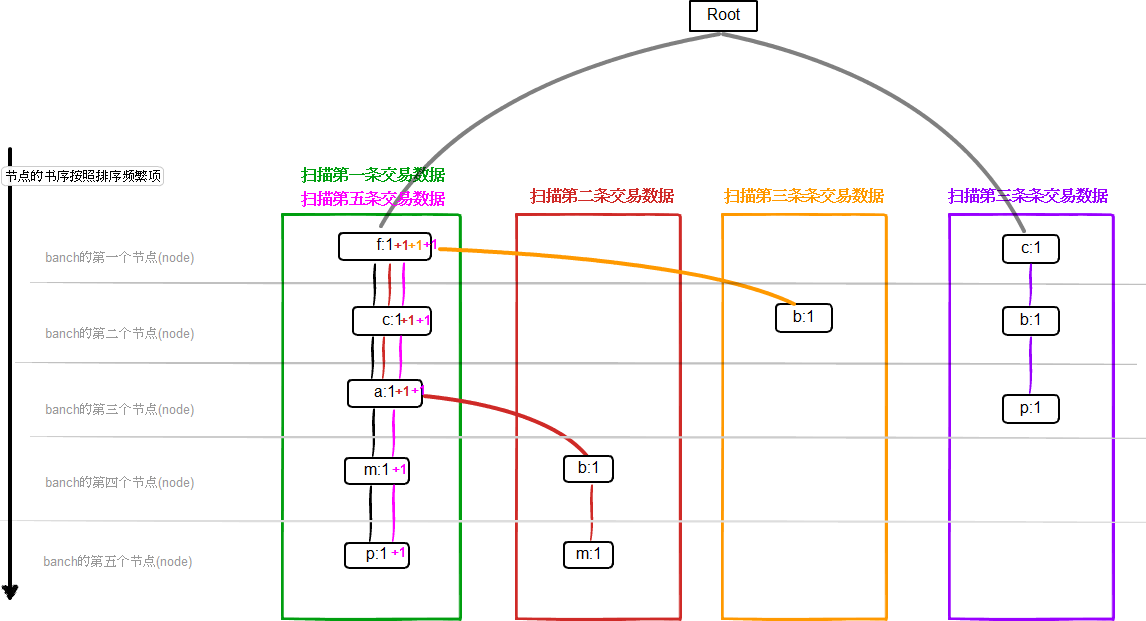
第二次:扫描数据库的每一交易,得到每个交易的排序频繁项(Ordered Frequent Items)构造频繁模式树(构造过程非常easy,原论文给出了具体的阐述):
我们对每个交易,仅仅保留大于3的项。并排序。然后我们得出下表。多出了一列就是排序频繁项(Ordered Frequent Items)
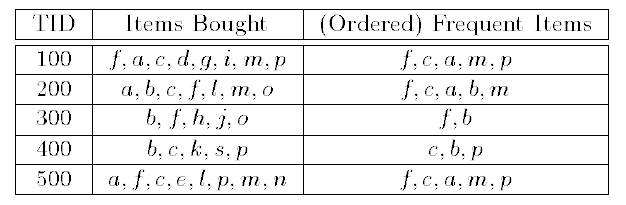
—————————————————————————————————————————————————————
依据上面的两步,我们已经构造出了频繁模式树,怎么样通过频繁模式树,找到频繁模式。
当中,我们拿和项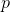
首先。我们找到全部
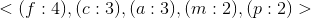
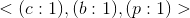
然后。我们能够得出出现的3次
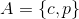
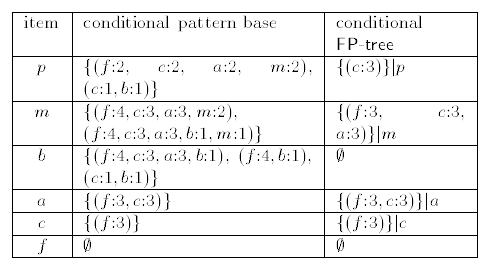
所以,通过频繁模式树找到了非常多频繁模式。
—————————————————————————————————————————————————————
对于频繁模式树的并行计算(MapReduce),文章
《Parallel FP-Growth for Query Recommendation》中给出了具体说明。
















 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









