






本文根据DBAplus社群第110期线上分享整理而成,文末还有好书送哦~
讲师介绍

丁俊
新炬网络首席性能优化专家
SQL审核产品经理
-
DBAplus社群联合发起人、《剑破冰山-Oracle开发艺术》副主编
-
Oracle ACEA,ITPUB开发版资深版主,十年电信行业从业经验
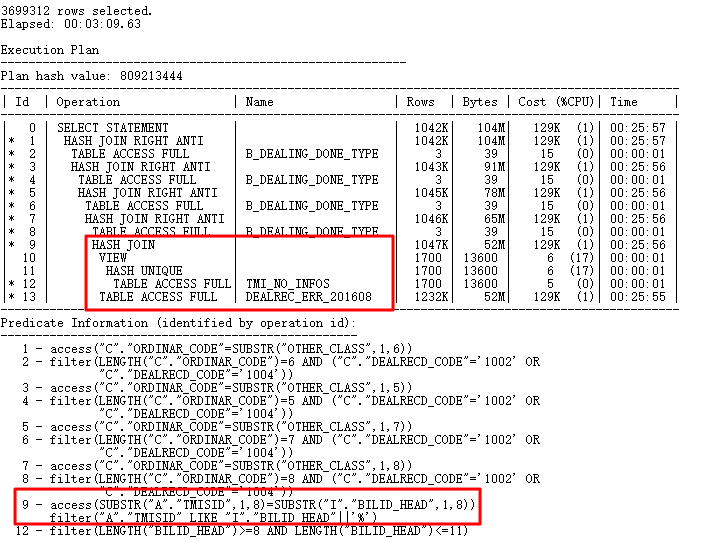
本次分享的内容是基于Oracle的SQL优化,以一条巨慢的SQL为例,从快速解读SQL执行计划、如何从执行计划中找到SQL执行慢的Root Cause、统计信息与cardinality问题、探索性能杀手Filter操作、如何进行逻辑重写让SQL起飞等多个维度进行解析,最终优化巨慢SQL语句,希望能够抛砖引玉,和大家一起探讨SQL优化方法。
另外,还简单介绍了两种解决疑难SQL优化问题的工具:10053和SQLT,特别是SQLT,往往在无计可施过程中,可能建立奇功,建议大家抽空研究下SQLT工具。最后对本次分享进行总结和思考:分享SQL Tuning RoadMap以及SQL Tuning最佳实践的相关内容。
大纲如下:
从一条巨慢的SQL开始
这条巨慢SQL执行预计耗时12小时以上,返回百万行数据。首先我们接手一条SQL优化问题,至少需要做以下两件事:
-
了解SQL结构:SQL中使用了哪些语法,这些语法是不是经常会导致性能问题,比如标量子查询的滥用。
-
获取执行计划:执行计划反应了SQL的执行路径,直接影响了SQL的执行效率。如何从执行计划中找出问题,是SQL Tuning的关键。
言归正传,先揭开巨慢SQL的神秘面纱:

这条语句其实就是查询DEALREC_ERR_201608表,有各种复杂的子查询,初看此子查询,我基本已经了解问题大概出在什么地方了,先卖个关子,看执行计划先:
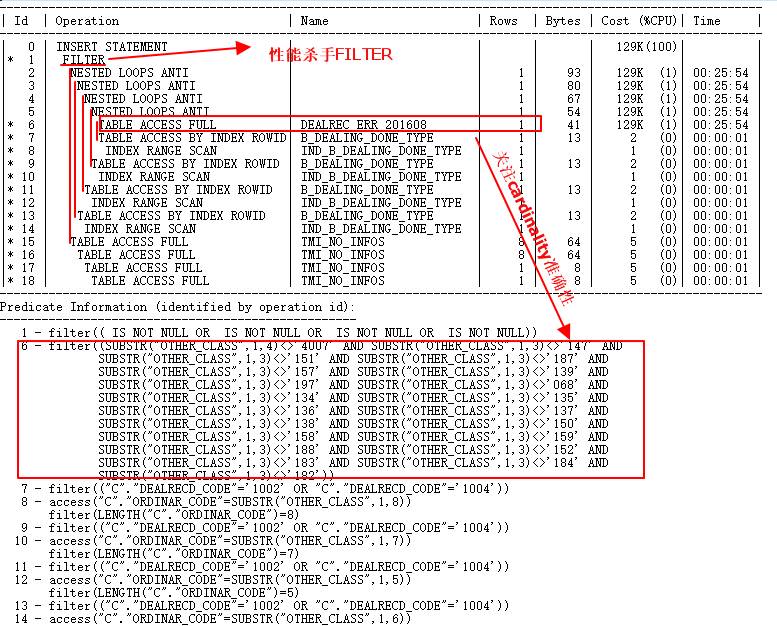
这种执行计划拿到手,其实很容易找出问题:
(1)分析指标问题:Rows,也就是每步骤的cardinality很小,说明每步返回的结果行数很少。这点值得怀疑。
(2)由于cardinality很少导致了Operation走了一系列Nested Loops操作,我们知道,NL操作,一般是驱动表返回的结果行数很少,被驱动表走索引,返回的最终结果比较少(一般最多几千行),效率会很高。
以上两点值得注意:如果cardinality是准确的,那么这个执行计划中走一系列Nested Loops的部分应该没有多大问题,但是,如果cardinality不是准确的呢?那就是大问题。这也就是一些初级开发人员的思维一样,经常喜欢对数据的处理使用循环,如果循环的次数少那还好,如果循环次数很多,那就会很慢。循环操作完全依赖于循环的次数,从SQL执行计划里看,也就是依赖于驱动表返回的结果行数,很显然,这种不适合大量数据运算。
(3) 在ID=1中有个Filter,这个Filter的子操作是ID=15~18的全表扫描。Filter可是执行计划里的一个大问题,当然,这里的问题Filter必须有2个或2个以上子节点的操作,如果是单节点,那只是简单的过滤条件而已。
对于一般的SQL优化,必须得分析SQL的语法结构,语义以及解读SQL执行计划,以SQL执行计划为基准,分析执行计划中的问题,来进行SQL Tuning,基本能解决大部分SQL优化问题了。
当然,以我的理解,SQL优化不仅需要很强的逻辑思维、正确的理论指导、各种SQL语法的精通、熟悉index的使用、了解CBO相关内容,甚至还需从大局观进行把控:物理模型的设计以及对具体的业务分析。
快速解读执行计划
1
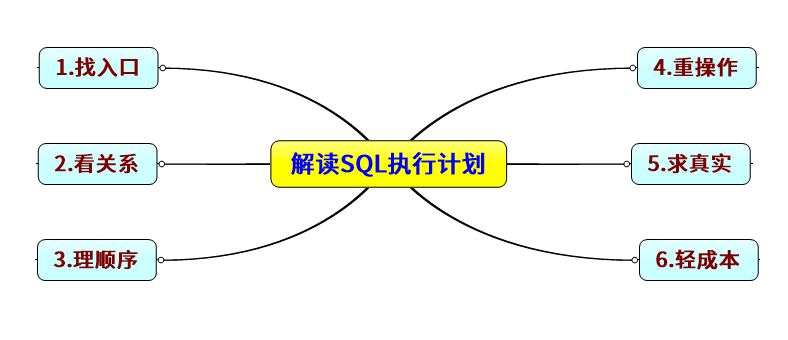
快速解读执行计划要点
SQL执行计划作为SQL优化的一把钥匙,必须要很好地利用起来。经常看到开发人员喜欢用PL/SQL Developer之类的工具来看执行计划。这里我得提醒下,这种内部调用的是Explain Plan For,可能不够准确,特别是有绑定变量的情况下,最重要的一点,对于长的SQL执行计划,简直没法进行分析。个人还是喜欢文本类型的执行计划,特别是真实的执行计划,能获取A-ROWS,E-ROWS这些指标的执行计划,让我对执行计划中的问题一览无余,特别对于巨慢的SQL,也可以运行个几分钟中断后获取部分信息来协助判断。
执行计划要点如下:
-
找入口:通过最右最上最先执行原则找出执行计划入口操作。对于巨长执行计划Copu到UE里使用光标缩进下探法则可找出入口,由于执行计划是锯齿状结构,父节点的子操作是向右缩进的,因此,从ID=0开始,光标向下向右缩进下探,直到缩进不了停止,然后按照同级别的,也就是格式的垂直线是同一级的,上面的是入口。
-
看关系:各操作之间的关系:Nesed Loops、HASH JOIN、Filter等是否准确,以及操作的顺序是否准确,直接关系此操作甚至影响整个SQL的执行效率。
-
理顺序:一步走错,满盘皆输。通过理清执行计划顺序找出key steps。
-
重操作:执行计划中的Operation和Predicate部分是需要关注的核心内容,从操作中看出不合理部分,以此建立正确索引等优化措施。
-
求真实:执行计划中指标是估算的,估算的指标和实际情况很可能不匹配。所以优化SQL需要了解每步骤真实的基数、真实执行时间和Buffer gets等,从而准确找出问题Root cause。(可以根据谓词手动计算、建议采用display_cursor方式获取A-ROWS、A-TIME等信息,工具有很多,也可以使用sql monitor等),如果采用Explain Plan For、SET AUTOTRACE之类的看执行计划,由于指标信息是不准的,要获取真实的信息,还需要手动根据谓词去计算,然后比较估算的和真实的差别,从而判断问题。
-
轻成本:COST虽然是CBO的核心内容,但因为执行计划中COST不一定准确反应SQL快慢,因此不要唯COST论,COST只是一个参考指标,当然可以通过执行计划判断一些COST是否明显存在问题,比如COST非常小,但是SQL执行很慢,可能就是统计信息不准确了。
2
快速解读执行计划实例
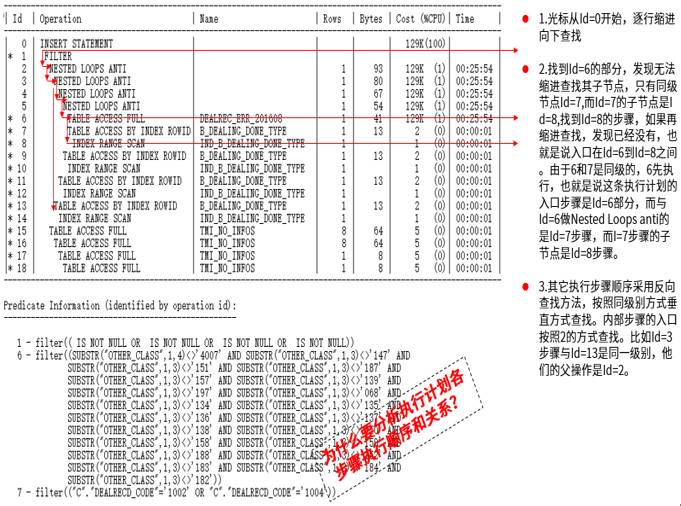
以上执行计划入口是ID=6(全表扫描),返回行数1,之后与ID=7的做Nested Loops操作。详细见分析部分。
-
问题:为什么要寻找执行计划入口?为什么要分析执行计划各步骤顺序和关系?
各种操作之间的关系是由cardinality等各种因素触发的,不正确的cardinality会导致本来应该走HASH JOIN的走了Nested loops Join。往往入口处就有问题,导致后续执行计划全部错误,所以明确各种步骤的关系,有助于找出影响问题的根源步骤。
理清执行计划顺序,有助于理解SQL内部的执行路径,通过执行的实际情况判断出不合理步骤操作。
-
重操作、求真实、轻成本是通过执行计划优化SQL的重要方法。
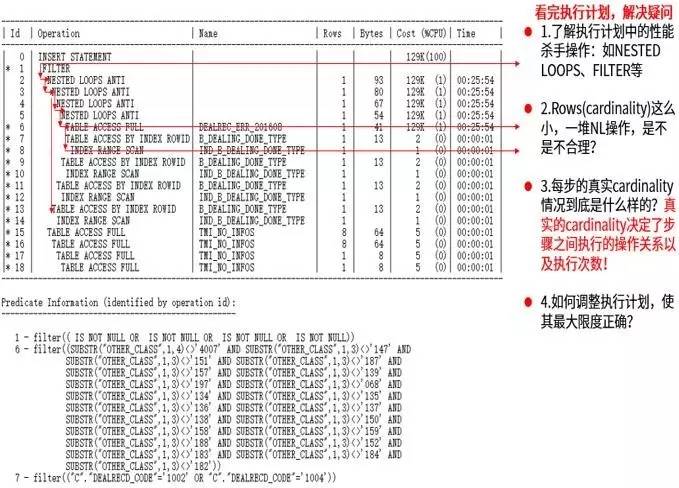
这里的入口是ID=6的全表扫描,返回行是1行,不是准确的,很显然,找到入口的问题,已经可以解决一部分问题了。
从执行计划看SQL低效根源
-
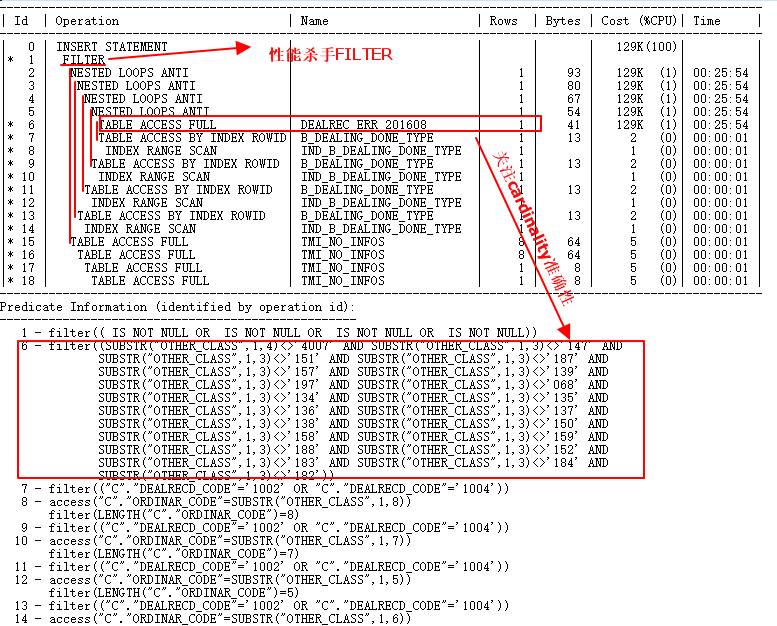
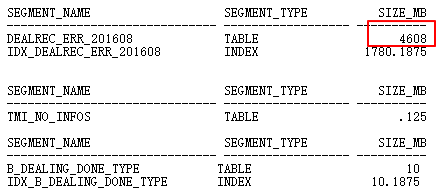
主表DEALREC_ERR_201608在ID=6查询条件中经查要返回2000w行,计划中估算只有1行,因此,会导致Nested Loops次数实际执行千万次,导致效率低下。应该走HASH JOIN,需要更新统计信息。
-
另外ID=1是Filter,它的子节点是ID=2和ID=15、16、17、18,同样的ID 15-18也被驱动千万次。
找出问题根源后,逐步解决。
第一次分析:解决ID=6步骤估算的cardinality不准确问题。
统计信息与cardinality
1
解决cardinality估算不准确问题
-
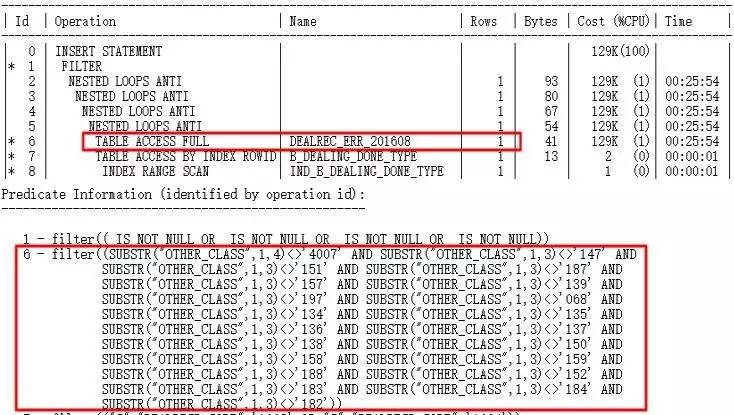
找出入口操作ID=6,由于ID=6操作的cardinality估算为1导致后续走一系列Nested Loops影响效率。
-
cardinality的计算与谓词紧密相关,所以要找出ID=6的谓词,根据谓词手动计算真实card与估算card之间的区别。
-
尝试收集统计信息,检验效果。
现在的问题,也就是转为对表DEALREC_ERR_201608统计信息准确性的问题,特别是统计信息对谓词计算的准确性。
2
解决cardinality估算不准确问题-扩展统计信息收集
-
尝试更新统计信息:
发现使用size auto,size repeat,对other_class收集直方图均无效果,执行计划中对other_class的查询条件返回行估算还是1(实际返回2000w行)。如何解决?card的计算和谓词紧密相关,查看谓词:
substr(other_class, 1, 3) NOT IN (‘147’,‘151’, …)
怎么办?思绪万千,灵光乍现!
Hints:cardinality(a,20000000),use_hash等可以。
还有更好的办法吗?
突然想起11g有个统计信息收集新特性:扩展统计信息收集。
exec DBMS_STATS.GATHER_TABLE_STATS(ownname=>‘xxx',tabname=>‘DEALREC_ERR_201608',method_opt=>'for columns (substr(other_class, 1, 3)) size skewonly',estimate_percent=>10,no_invalidate=>false,cascade=>true,degree => 10);
扩展统计信息一收集,执行计划如下:
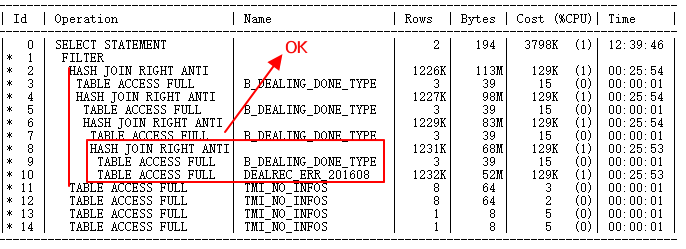
-
DEALREC_ERR_201608与B_DEALING_DONE_TYPE原来走NL的现在正确走HASH JOIN。Build table是小结果集,probe table是ERR表大结果集,正确。
-
但是ID=2与ID=11到14,也就是与TMI_NO_INFOS的OR子查询,还是FILTER,驱动数千万次子节点查询,下一步优化要解决的问题。
-
性能从12小时到2小时。到这里结束了吗?
统计信息的问题还是很多的,一个表的统计信息收集,特别是自动收集,不一定能让所有相关SQL找到最佳执行路径,特别是SQL条件复杂、数据倾斜、表类型定义不准确等情况,特别是使用了复杂条件,CBO无法准确计算对应谓词的card,或者类型定义不准确,本来是日期的用了VARCHAR2,内部全部要转为数字来计算选择性,很显然,乱定义列类型也是有问题的。所以有针对性地修正收集的统计信息,是很有必要的。
3
解决cardinality估算不准确问题-有关统计信息的那些疑问
-
疑问1:100%收集为什么还没有走正确执行计划?
统计信息收集比例高不代表就可以翻译对应谓词的特征,而且统计信息内部有很多算法限制以及不完善的情况,比如11g的扩展统计信息来继续完善,12c也有很多统计信息完善的特性。所以并不是比例低就不好,比例高就好!统计信息的收集要满足核心SQL的执行效率,对于非核心SQL一定程度上可以不用过度关注,因为统计信息很难满足所有相关SQL的最佳执行。
-
疑问2:统计信息各种维度收集了包括直方图都收集了怎么不起作用?
直方图有很多限制,12c之前,只有频度直方图和等高直方图两种,对很多值的分布不能精确表示,所以有很多限制。因此,12c又增加了2种直方图:顶级频度直方图和混合直方图。另外直方图还有只存储前32位字符的限制。
-
疑问3:直方图只对走索引的有作用?
很显然不对,直方图只是反应数据的分布,数据的分布正确,对应谓词可以查询出比较准确的cardinality,从而影响执行计划,所以对全表也是有用的。
-
疑问4:收集或更新了统计信息,执行计划怎么变得更差了?
很有可能,比如把原来的直方图给去掉了可能导致执行计划变差。因此,一般更新使用size repeat,除非是确认需要修改某些直方图,另外谓词和统计信息紧密相关,某些谓词条件一旦收集统计信息,可能就计算不准确了。
-
疑问5:执行计划中cardinality显示的和已有统计信息计算不一致?
Oracle CBO内部算法很复杂,而且Bug众多,遇到问题要大胆怀疑。
-
疑问6:统计信息应该按照Oracle建议自动收集?
具体问题具体分析,是让Oracle自动还是自己写脚本收集,都需要长期实践总结,对于一个复杂系统来说采样比例和method_opt很多需要定制设置。
-
疑问7:为什么唯一性很好的列,还需要收集直方图?
选择性的内部计算是要转成数字的:CBO内部计算选择性会先将字符串转为RAW,然后RAW转为数字,左起ROUND15位。如果字符串的唯一性好, 但是计算成数字后唯一性不好,则会导致执行计划错误,这时候也需要收集直方图。
-
疑问8:我需要根据统计信息以及CBO公式去计算COST吗?
不需要,除非你很喜欢研究,这样做只会得不偿失。了解各种JOIN算法、查询转换特性、索引等效率和哪些有关即可,COST不是最需要关心的指标,我们应该关心SQL高效运行所需的执行路径和执行方法,是否可以达到及早过滤大量数据,JOIN方法和顺序是否正确,是否可以建立高效访问对象等。
探索性能杀手Filter
1
性能杀手Filter形成机制
-
为什么会形成Filter操作?(多子节点,单子节点纯粹过滤操作)
Filter形成于查询转换期间,如果对于子查询无法进行unnest转换来消除子查询,则会走Filter。走Filter说明子查询是受外表结果驱动,类似循环操作!很显然,如果驱动的次数越多,效率越低!
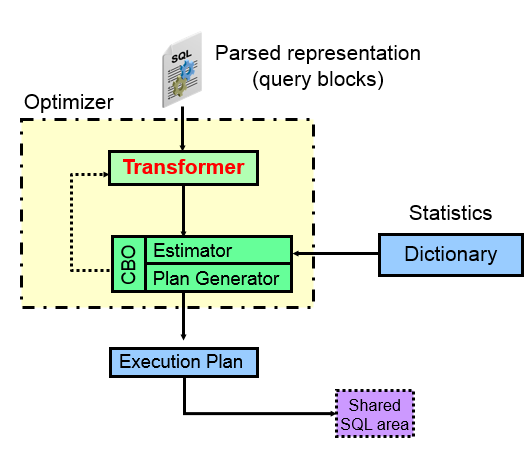
查询转换是能够生成高效SQL执行计划的重要步骤,查询转换不能做好,后面的很多执行路径就没法走了。掌握查询转换机制,对如何写高效的SQL,调优SQL至关重要,了解的越深,对CBO就越了解。
下面是CBO组件图,熟悉对应组件是SQL优化必须的内容:
-
Filter什么时候高效?
Filter本身会构建HASH表来保存输入/输出对,以备后续减少子查询执行次数,这是与纯粹Nesed Loops操作的典型区别,比如from a where a.status In(select b.staus from b…)。 如果status前面已经查过,则后续不需要再次执行子查询,而是直接从保存的HASH表中获取结果,这样减少了子查询执行次数,从而提高效率。也就是说,如果子查询关联条件的重复值很多,Filter还是有一定的优势,否则就是灾难!
-
Filter与push_subq hints
如果走Filter则子查询是受制于子查询外结果集驱动,也就是子查询是最后执行,但是实际有时候子查询应该先执行效率更好,这时候可以使用push_subq hints。
2
性能杀手Filter形成机制实例
-
简化前面的语句关键部分如下:

-
Oracle内部改写如下,无法unnest,如果unnest:
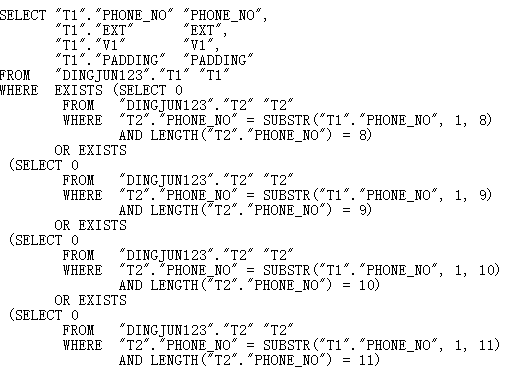
执行计划如下:
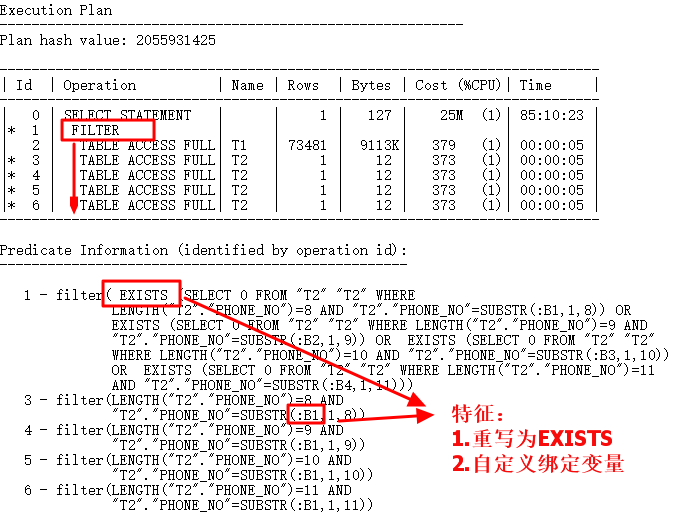
从执行计划里可以看到,Filter多子节点一般有如下特点:
-
自动生成的绑定变量:B1,因为需要执行循环操作
-
转为EXISTS
所以,以后看到有自动生成的绑定变量的执行计划,都是类似Filter的操作,比如标量子查询,UPDATE关联子查询,优化的话,都需要干掉(类)Filter来优化。
这里的例子其实是一个CBO的限制:
-
含有OR的子查询,经常性无法unnest,Oracle大多无法给转换成UNION/UNION ALL形式的查询
-
所以,针对这样的语句优化:
1)改写为UNION/UNION ALL形式
2)根据语义、业务含义彻底重写
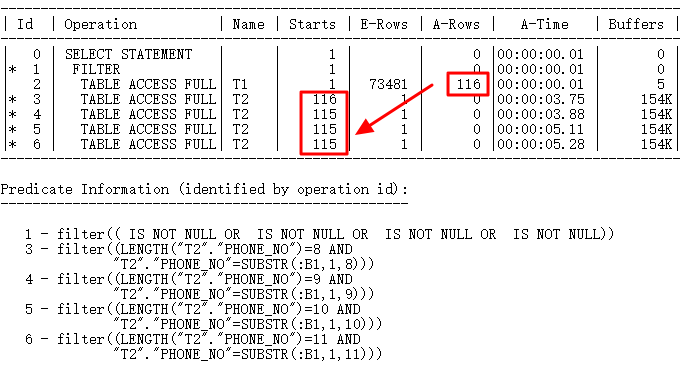
也就是说,需要重构查询,消除Filter!慢的根源如下,这里7万多行,只执行了116行打印的执行计划!ID=3~6的执行次数依赖于ID=2的结果行数,ID=3~6全表扫描次数太多。
逻辑重写让SQL起飞
1
逻辑改写-构造高效HASH JOIN代替低效Filter
-
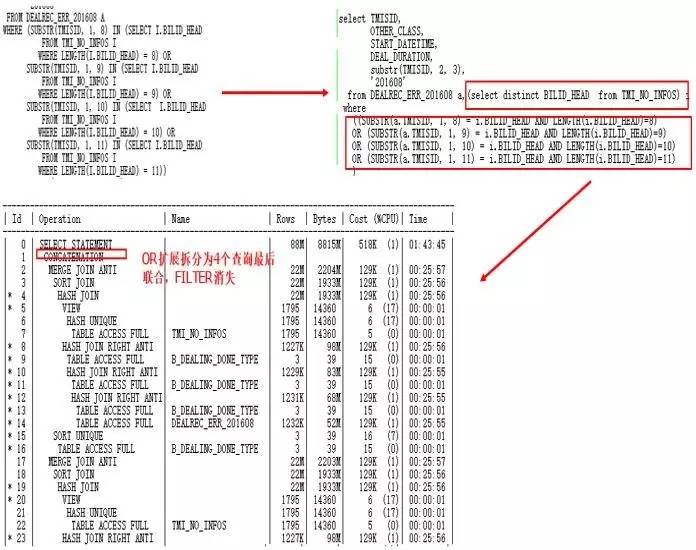
回到原来的SQL中,看如何改写,通过分析,可以改为JOIN形式:
-
改写后执行时间从2小时到8分钟,返回360w行+。虽然执行计划更复杂了,但是充分利用了HASH JOIN、MERGE JOIN这种大数据量处理算法代替原来的Filter,更高效。如果不走OR扩展走什么?(走Nested Loops,对IMS_NUM_INFO扫描从4次到1次,也很慢)。
-
OR扩展存在缺点,大表还是多次被访问,还能继续优化吗?
2
彻底重写-消除OR扩展的HASH JOIN重写思路
-
上一次重写,等于使用了第一种方法,用UNION/UNION ALL消除Filter,那么如何消除UNION/UNION ALL呢,也就是要将OR语句合并为AND!
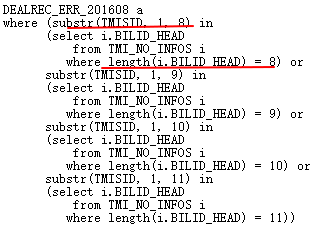
追本溯源,从SQL含义出发,上面含义是ERR表的TMISID截取前8,9,10,11位与TMI_NO_INFOS.BILLID_HEAD匹配,对应匹配BILLID_HEAD长度正好为8,9,10,11。很显然,语义上可以这样改写:
ERR表与TMI_NO_INFOS表关联,ERR.TMISID前8位与ITMI_NO_INFOS.BILLID_HEAD长度在8-11之间的前8位完全匹配,在此前提下,TMISID like BILLID_HEAD||’%’。
现在就动手彻底改变多个OR子查询,让SQL更加精简,效率更高。
3
彻底重写-消除OR扩展的HASH JOIN让SQL起飞
通过上一节的思路,改写SQL如下:
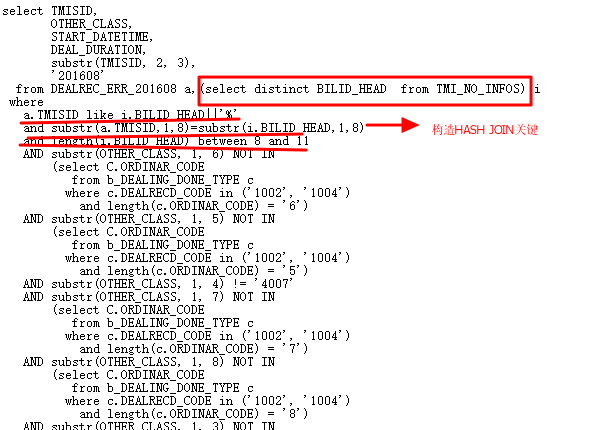
执行计划如下:
-
现在的执行计划终于变的更短,更易读,通过逻辑改写走了HASH JOIN,那速度,杠杠的,最终一条返回300多万行数据的SQL原先需要12小时运行的SQL,现在3分钟就执行完了。
-
思考:结构良好,语义清晰的SQL编写,有助于优化器选择更合理的执行计划,看来编写SQL真的有很多值得注意的地方。
两个工具提升疑难SQL优化效率
1
两个工具提升疑难SQL优化效率-10053分析执行计划生成原因
-
一条SQL执行12分钟没有结果:其中object_id有索引,从查询结构来看,内层查询完全可以独立执行(最多100行),然后与外层的表进行关联,走NL,这样可以利用到object_id索引,然而,事与愿违,ID=4出现Filter,这样内层查询会驱动N次,问题出在何处?
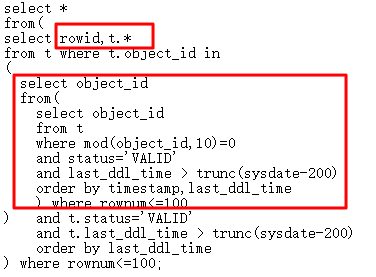
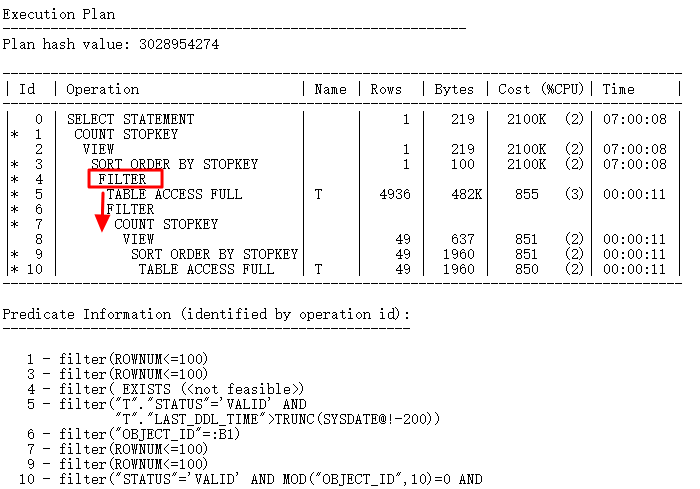
下面就使用10053探索优化器行为来研究此问题。
*****************************
Cost-Based Subquery Unnesting
*****************************
SU: Unnesting query blocks in query block SEL$1 (#1) that are valid to unnest.
Subquery removal for query block SEL$3 (#3)
RSW: Not valid for subquery removal SEL$3 (#3)
Subquery unchanged.
Subquery Unnesting on query block SEL$2 (#2)SU: Performing unnesting that does not require costing.
SU: Considering subquery unnest on query block SEL$2 (#2).
SU: Checking validity of unnesting subquery SEL$3 (#3)
SU: SU bypassed: Subquery in a view with rowid reference.
SU: Validity checks failed.
-
从10053中可以看出,查询转换失败,因为遇到了rowid,当然把Rowid改别名是可以,但是此SQL要求必须用Rowid名字。
-
通过改写消除Filter运算如下:

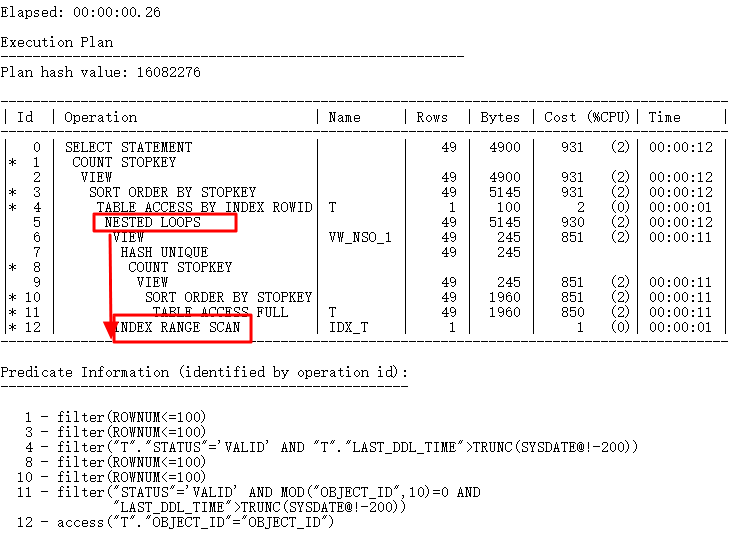
2
两个工具提升SQL优化效率-SQLT找出正确执行计划需设置的参数
-
SQL能否生成正确执行计划,不光和统计信息、索引等有关,能否正确执行查询转换是至关重要的,由于各种复杂的查询转换机制导致Bug很多,Oracle对这些已知Bug通过fix control参数管理,有的默认打开,有的默认关闭。所以,如果遇到复杂的SQL,特别包含复杂视图的SQL,比如谓词无法推入这种查询转换,收集统计信息无效,这时候可以考虑是否遇到了Bug。
-
Bug那么多,我怎么知道是哪个?SQLT神器来帮你!使用SQLT里面的XPLORE工具,可以把参数打开关闭一遍,并且生成对应执行计划,这样通过生成的报告,可以一眼定位问题。(当然,是已知Bug,比如前面的Rowid问题,也是定位不到的)
-
问题背景:11.2.0.2升级到11.2.0.4出现此问题,性能杀手Filter操作,SQL跑不出来,Filter产生原因,无法unnest subquery,其中11g _optimizer_null_aware_antijoin参数为true。
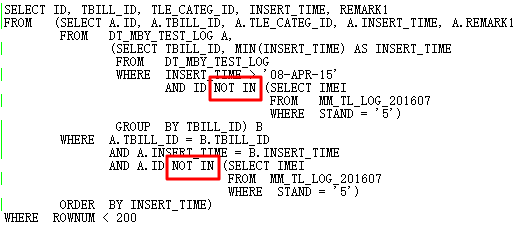
执行计划如下所示:
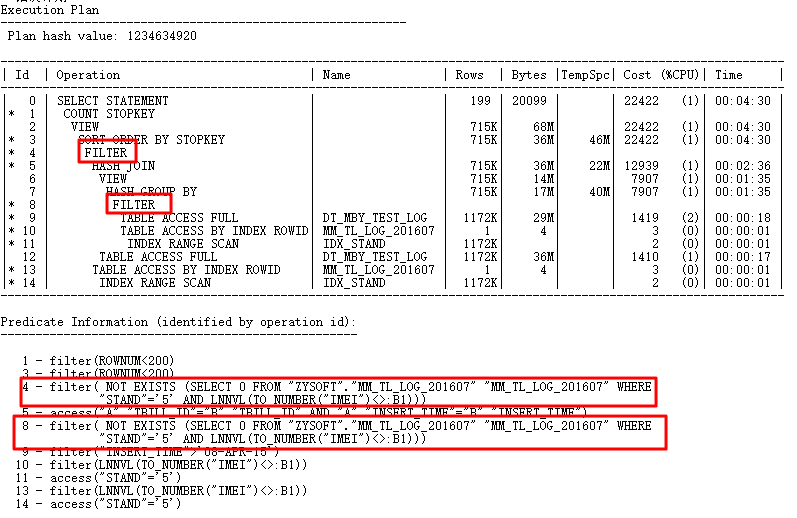
很显然,这两个Filter有问题,按理说应该走ANTI JOIN。
下面看看使用SQLT的XPLORE来找出问题,先来看下SQLT介绍:


跑一下XPLORE,只需要调用XPLAIN方法即可,提高效率,不实际执行SQL:
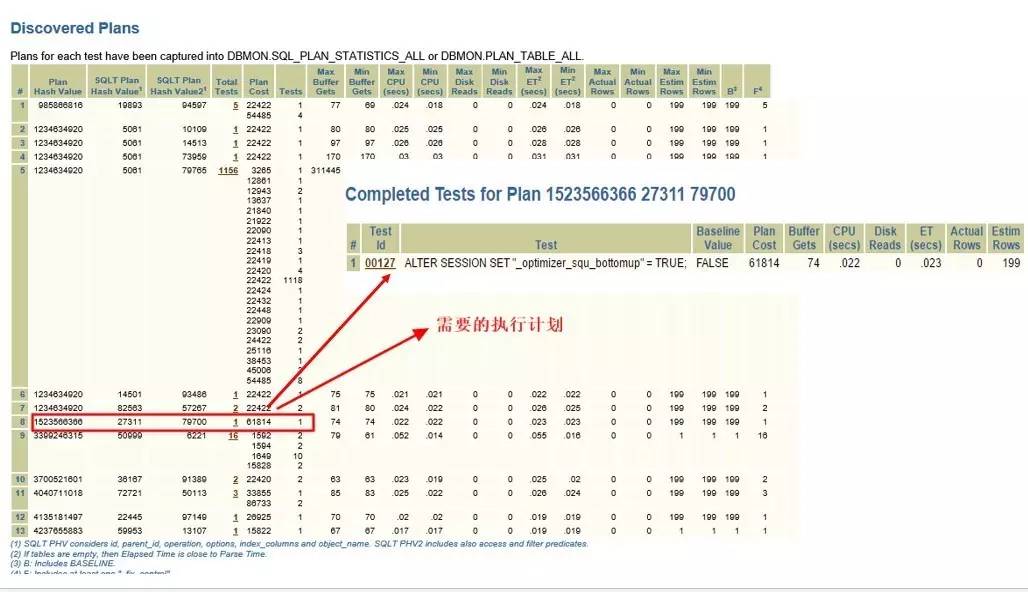
可以看到和对应的隐含参数_optimizer_squ_bottomup设置有关,这是一个和子查询的查询转换有关的隐含参数。
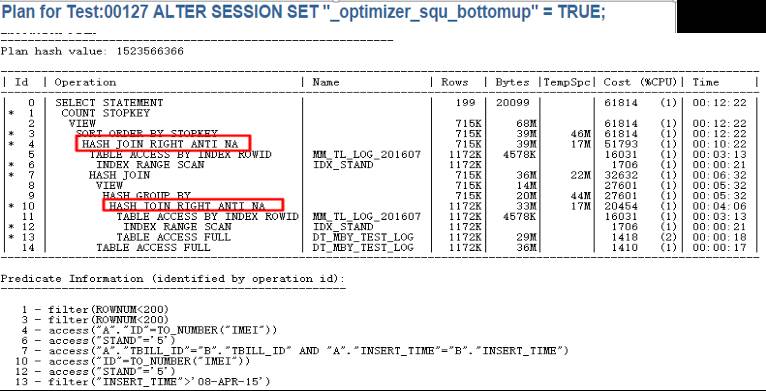
修正之后的执行计划:
走回ANTI JOIN,正确了。终于从跑不出来到几秒搞定,其实还可以优化,但是那已经不是最重要的事了!
SQLT XPLORE的一些限制:
-
只能单个参数测试是否有效;
-
做XPLORE使用XPLAIN方法,内部调用explain plan for,不需要执行从而提高效率和避免修改数据;
-
只有是已知参数或者Bug fix control才会有用,对于未知Bug无用,当然修改参数需要做足测试,如果非批量问题,建议找出原因,使用SQL PROFILE搞定,批量问题需要做足测试再实施修改!
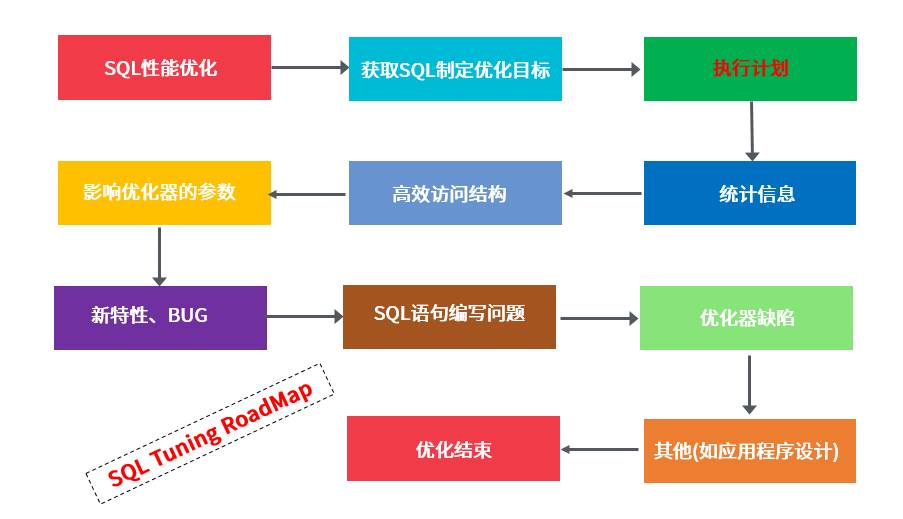
SQL Tuning思考之RoadMap
-
获取问题SQL制定优化目标
从AWR、ASH、SQL CHECK S等主动发现有问题的SQL、用户报告有性能问题时DBA介入等,通过对SQL的执行情况分析,制定SQL的优化目标。
-
检查执行计划
explain工具、sql*plus autotrace、dbms_xplan、10046、10053、awrsqrpt.sql等。
-
检查统计信息
Oracle使用DBMS_STATS包对统计信息进行管理,涉及系统统计信息、表、列、索引、分区等对象的统计信息,统计信息是SQL能够走正确执行计划的保证。
-
检查高效访问结构
重要的访问结构,诸如索引、分区等能够快速提高SQL执行效率。表存储的数据本身,如碎片过多、数据倾斜严重、数据存储离散度大,也会影响效率。
-
检查影响优化器的参数
optimizer_mode、optimizer_index_cost_adj、optimizer_dynamic sampling、_optimizer_mjc_enabled、_optimizer_cost_based_transformation、hash_join_enable等对SQL执行计划影响较大。
-
优化器新特性、Bug
如11g的ACS、cardinality feedback、automatic serial direct path、extended statistics、SQL query result cache等。有的新特性会导致问题,需谨慎使用。
-
SQL语句编写问题
SQL语句结构复杂、使用了不合理的语法,比如UNION代替UNION ALL可能导致性能低下。
-
优化器限制
无法收集准确的统计信息、无法正确进行查询转换操作等,如SEMI JOIN、ANTI JOIN与or连用会走Filter操作。
-
其他
主要涉及设计问题,如应用在业务高峰期运行,实际上可以放到较空闲状态运行。表、索引、分区等设计不合理。
SQL Tuning最佳实践:
SQL性能管理平台
应用系统SQL众多,如果总是作为救火队员角色解决线上问题,显然不能满足当今IT系统高速发展的需求,基于数据库的系统,主要性能问题在于SQL语句,如果能在开发测试阶段就对SQL语句进行审核,找出待优化SQL,并给予智能化提示,快速辅助优化,则可以避免众多线上问题。另外,还可以对线上SQL语句进行持续监控,及时发现性能存在问题的语句,从而达到SQL的全生命周期管理目的。
针对以上种种,我们新炬网络以多年运维和优化经验自主研发出了一款SQL审核工具,通过SQL采集—SQL分析—SQL优化—上线跟踪这四步SQL审核法则, 极大地提升了SQL审核优化和性能监控处理效率。有别于传统的SQL优化方法,它是着眼于系统上线前的SQL分析和优化,重点解决SQL问题于系统上线之前,将性能问题扼杀于襁褓之中。
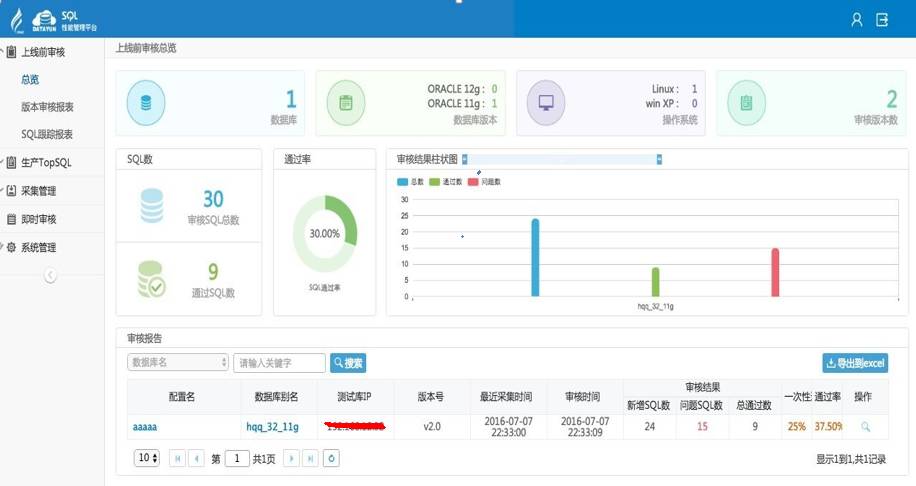
首页审核总体情况一览无余:
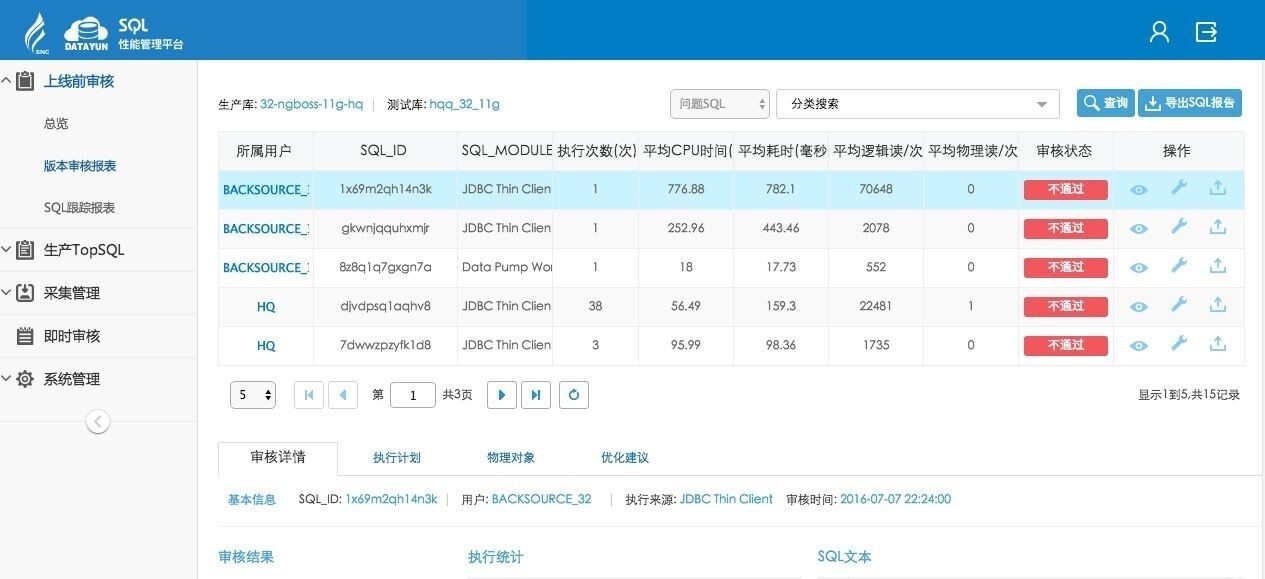
审核页面展现详细SQL审核情况:
SQL审核结果多维护分析:
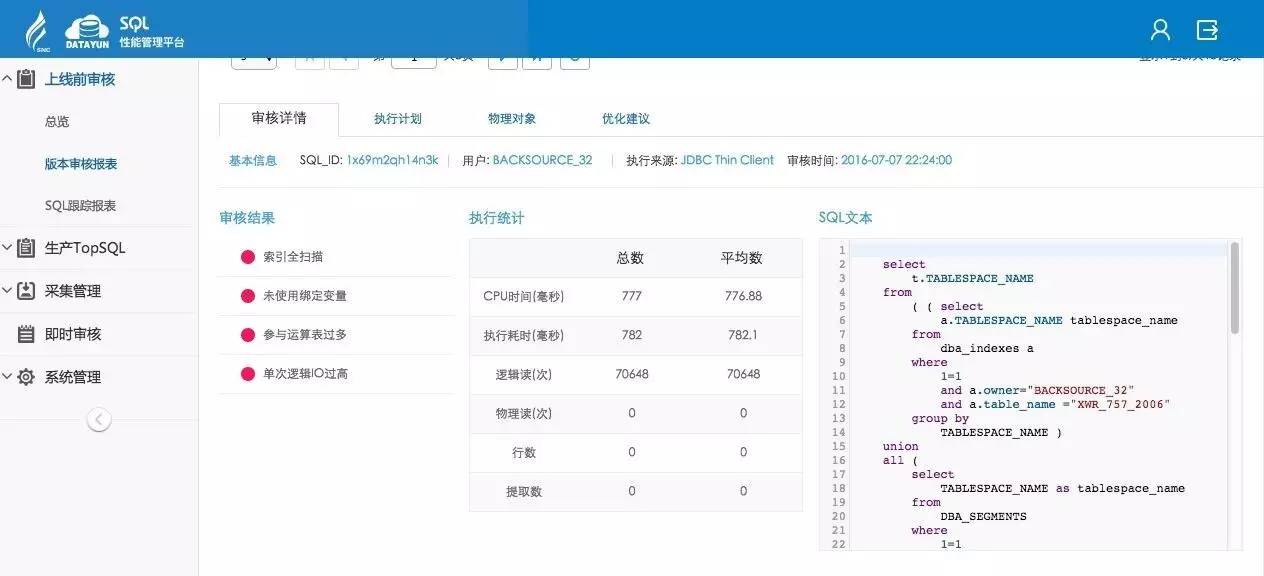
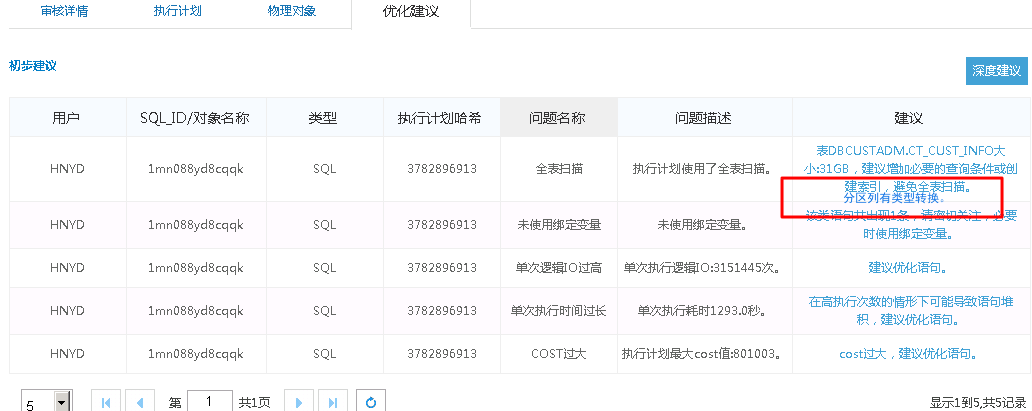
优化建议详细准确:
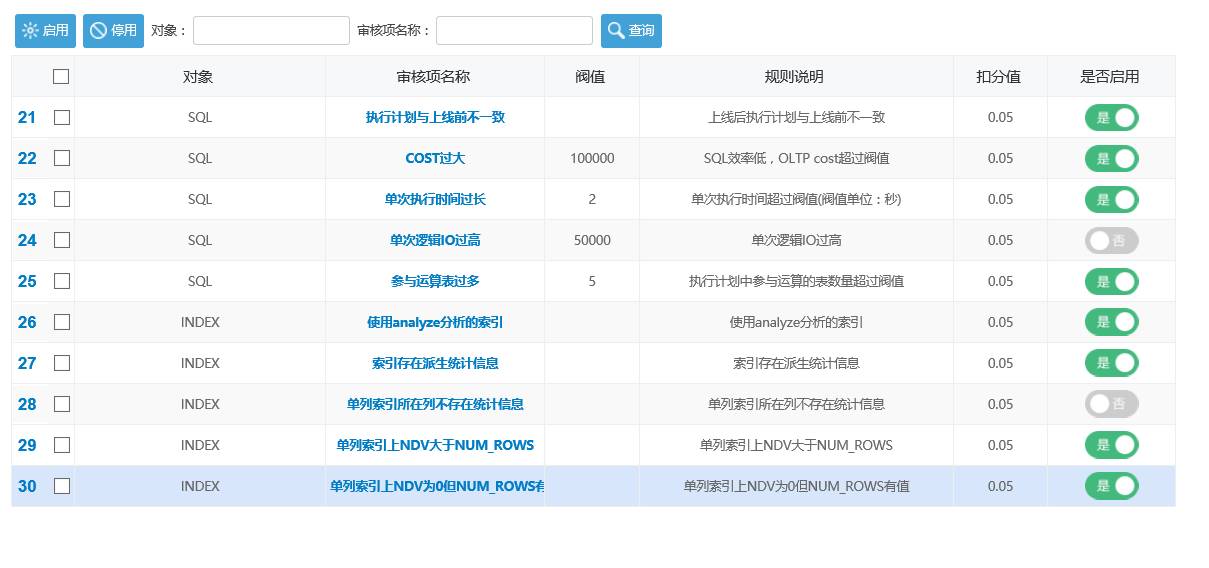
内置上百种规则集,可按需选择:
SQL性能管理平台必须解决事前事中事后的SQL全生命周期管理问题。
-
事前:上线前SQL性能审核,扼杀性能问题于襁褓之中。
-
事中:SQL性能监控处理,及时发现上线后SQL性能发生的变化,在SQL性能变化并且没有引起严重问题时,及时解决。
-
事后:核心SQL监控,及时告警处理。
SQL性能管理平台实现了SQL性能的360度全生命周期管控,并且通过各种智能化提示和处理,将绝大多数本来因SQL引发的性能问题,解决在问题发生之前,提高系统稳定度。
另外对SQL性能的分析,从SQL写法、SQL执行信息、执行计划、统计信息等多方面定义规则,多维度进行分析,提供智能化的建议,提升优化速度和准确性。
SQL性能管理平台特点-自动化采集、分析、跟踪,减少DBA分析时间,提高管控效率:

SQL审核是新炬网络数据库性能管理平台DPM的一个模块,大家若想了解更多关于DPM的信息,可加邹德裕大师微信carydy交流探讨。
Q&A
Q1:merge join、nested loops、hash join什么时候走什么样的连接呢?
A1:Nested loops适合各种关联条件的查询,=,<>,>,<等等,主要是驱动行数少,被驱动的如果有高效索引,返回结果集不大的情况下高效,侧重于CPU消耗。
HASH JOIN是必须要等值连接的,侧重于大数据量运算,本次分享的巨慢SQL就是通过将OR子查询通过SUBSTR函数构造等值连接,实现HASH JOIN运算,侧重于内存消耗。
SORT MERGE JOIN主要适合<,>之类的大数据量运算,需要排序,侧重于内存消耗。
Q2:收集统计信息用analyze还是dbms_stats?
A2:很显然收集统计信息要用DBMS_STATS,ANALYZE有些功能DBMS_STATS没有,比如validate structure等。
Q3:SQL第一次快,之后执行慢大概什么原因?
A3:这种问题需要具体分析了,如果是11g,大多是执行计划频繁变化导致的,11g有cardinality feedback和adaptive cursor sharing,BUG较多,经常会导致SQL忽快忽慢,可以通过执行计划来进行分析,如果是这样的原因,可以关闭此特性。如果不是新特性导致的,可以通过分析物理读,逻辑读,或者10046跟踪来找出原因加以解决。
下载链接
1、分享PPT下载:
点击文末【阅读原文】或登录云盘:http://pan.baidu.com/s/1kVSLFlt,即可下载本次分享PPT。
2、直播链接:
https://m.qlchat.com/topic/220000485078915.htm?preview=Y&intoPreview=Y
密码:006
好书相送
在本文微信订阅号(dbaplus)评论区留下足以引起共鸣的真知灼见,并在本文发布后的隔天中午12点成为点赞数最多的1名,可获得绝版译著《Oracle核心技术》一本~

精选专题(官网:dbaplus.cn)
◆ 近期活动 ◆
DAMS中国数据资产管理峰会上海站
峰会官网:www.dams.org.cn返回搜狐,查看更多















 215
215











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









