








产生的原因:网络不可达问题。
网络超时之后我们可以做的只有两件事,1 停止(回滚,但对于系统来说影响特别大) 2 继续(另发送到别的服务消费端)
一般我们采用第二种处理方式,但是要经过网络,必然会出现消息重复问题。
最好的解决方法是:
恰好不需要——幂等操作
S * S = S (某个操作不管重复多少次,结果都一样)。
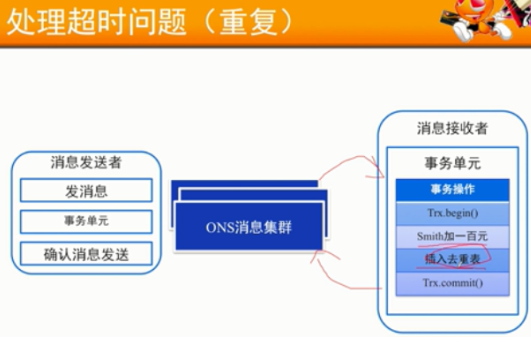
幂等消息去重:
- 保证有个唯一ID标记每一条消息
- 保证消息处理成功与去重表日志同事出现
代价:去重代价是去重日志的写入,数据校验,多台机器对去重表的维护。
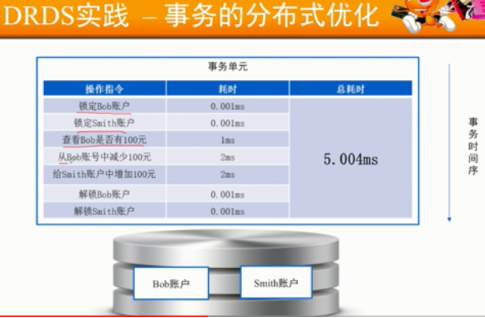
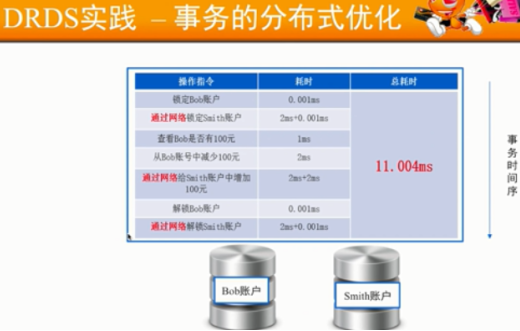
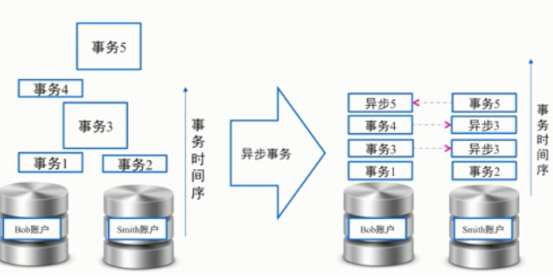
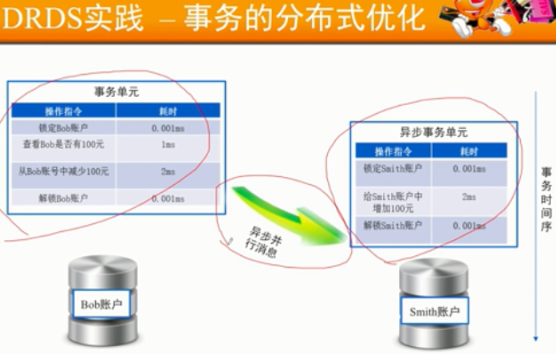
- ONS消息与事物转账设计难点:
- 如何保证消息发送与Bob账户减钱同时成功或同时失败?
- 消息处理超时的解决?
- 消息处理失败如何解决?
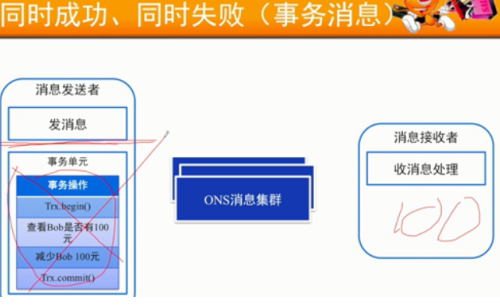
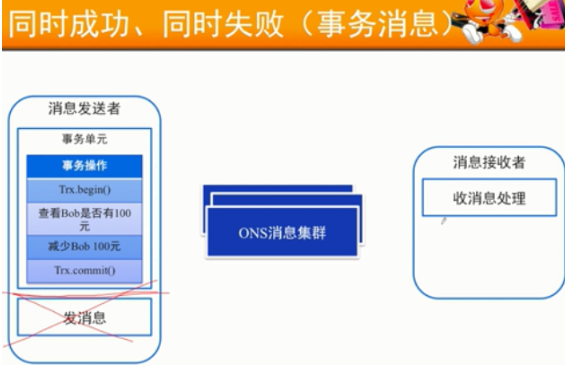
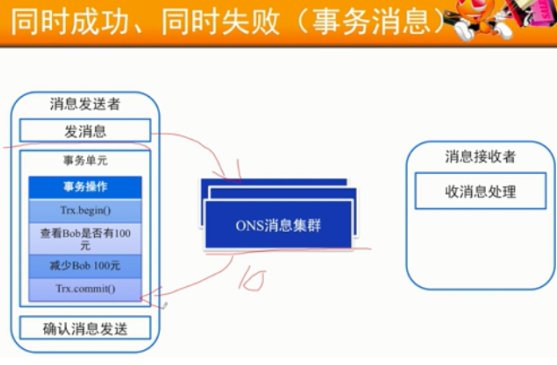
尽量保持消息接受者的幂等性
但是对于非幂等的消息消费端:要记录日志表,内次执行时进行日志校验。
- 当消息接收者处理失败时,能挽回失败的方法之一是系统,但是系统回滚的开销往往是很大的。
- 还有一种方式是人工处理,当事件发生的概率 比 写代码挽回失败Bug的概率还要小,这样我们就需要考虑是否使用人工处理了。
- 利用努力送达模型,失败后再重新发往mq中,重新进行消费,尽量保证数据处理成功。努力送达模型是系统希望来进行这样的设计的。
小结:
- 消息系统:解耦 异步 最终一致性 并行
- ONS 和其他消息系统不一样的部分:高吞吐量 高并发。
- 面向于失败的系统: 消息安全性, 消息堆积能力 消息吞吐量 和 延迟 (crash崩溃)
- 系统的关键特性: topic、tag、消息组(订阅组:动态将消息通过一个配置文件配置组的名字,动态的归属到某一个组内,能保证消息发送者 和 消息订阅者可以自动的扩展 或 减容)
- 代价:消息重复问题,消息乱序问题。
- 支持事物的消息模式















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









